

黄东旭解析 TiDB 的核心优势
1079
2023-03-28
对于数据库产品而言,基于时间点的恢复是非常重要的基础能力,它允许用户根据需要,将数据库恢复到特定时间点,以帮助客户的数据库免受意外损坏或错误操作的影响。例如,数据库在某个时间点之后的数据遭受了意外的删除或损坏,则可以使用 PiTR 功能将数据库恢复到该时间点之前的状态,从而避免丢失重要数据。
由于 TiDB 数据库,每一次的数据改变都会产生对应的分布式日志,其中记录了数据库每一次变更的信息,包括事务 ID、时间戳和变更的具体内容。
当用户启用 PiTR 功能后,TiDB 会定期将分布式变更日志保存到外部存储(例如:AWS S3,Azure BloB 或 NFS 等)。如果在某个时间点之后的数据被意外删除或遭受了损坏,则可以使用 BR 工具将之前的数据库备份恢复回来,通过应用保存在外部存储上的数据改变到用户指定的时间点,从而达到定点恢复的目的。
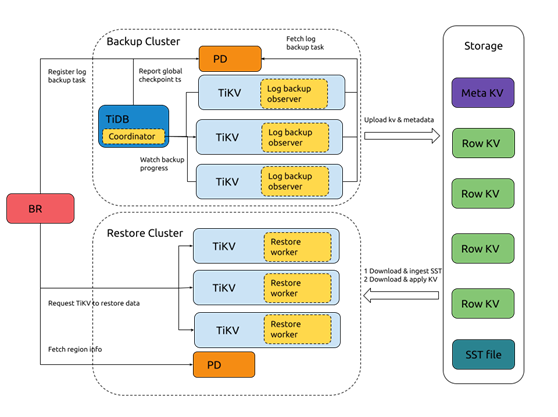
上面的图示描述了 PiTR 特性的架构:当用户启动了日志备份之后,BR 工具会向 PD 注册一个备份任务。同时,某个 TiDB 节点会被选择成为日志备份的协调者,定期与 PD 进行交互,以便计算全局备份 checkpoint ts。同时,每个 TiKV 节点会运行定期向 PD 上报本节点的备份任务状态,并将数据变更日志发送到指定的外部存储上。
对于恢复过程,当用户发起了基于时间点的恢复命令之后,BR 工具会读取备份的元数据信息,并通知所有的 TiKV 节点启动恢复工作,TiKV 节点上的 Restore worker 会读取定点之前的变更日志并将其应用集群中,就可以得到指定时间点的 TiDB 集群。
接下来,我们进一步看一下日志备份和恢复过程的工作机制。
下面的流程图说明了日志备份的主要工作机制
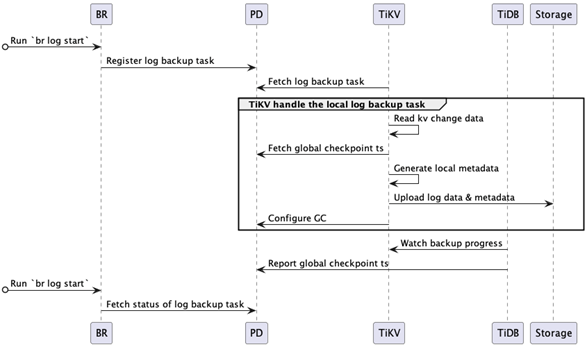
其中主要的交互流程如下:
1.BR 接收备份命令 br log start
解析日志备份任务的日志备份起始时间点和备份存储地址,并向 PD 注册日志备份任务 (log backup task)。
2.TiKV 定期监测新建/更新的日志备份任务
每个 TiKV 节点的日志备份 observer 监听 PD 中创建与更新日志备份任务,然后备份该节点上在备份时间范围内的变更数据日志。
3.TiKV 节点备份 KV 变更日志,并将本地备份进度上报到 TiDB
TiKV 节点中 observer 服务会持续地备份 KV 变更日志,联合从 PD 查询到的 global-checkpoint-ts 来生成备份元数据信息,并定期将日志备份数据和元信息上传到存储中,同时 observer 服务还会防止未备份完成的 MVCC 数据被 PD 回收。
4.TiDB 节点计算并持久化全局备份进度。
TiDB 协调者节点轮询所有 TiKV 节点,获取各个 Region 的备份进度 ,并根据各个节点的备份进度计算出整体日志备份的进度,然后上报给 PD。
对于恢复的过程,可以参考下面的流程图了解其工作机制
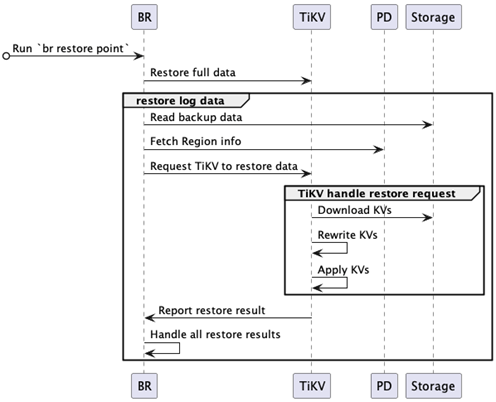
当用户发起“br restore
从上面的工作机制可以看到, 无论是日志备份还是恢复,其过程都是比较复杂的,所以 TiDB 在PiTR 发布之后,一直对这个特性进行优化,不断的提升 PiTR 的技术指标,稳定性和性能。
例如, 在最初的版本中日志备份会产生大量的小文件,给用户在使用期间带来很多的问题。在最新版本中,我们将日志备份文件聚合成为多个大小至少为128M的文件,很好的解决了这个问题。
对于大规模的 TiDB 集群,其全量备份往往需要运行很长时间,如果不支持断点续传功能的话,当备份过程中出现一些异常情况,导致备份任务中断的话,对用户来说是非常令人绝望的。在 6.5.0 版本中,我们支持了备份的断点续传能力,并且优化了备份的性能,目前单个 TiKV 的数据备份性能可以达到 100MB/s,日志备份对源集群的性能影响可以控制在 5% 左右,这些优化都极大的提升了大规模集群备份的用户体验和备份的成功率。
由于备份恢复通常都会被用户作为数据安全的最后一道防线,PiTR 的 RPO 和 RTO 指标也是很多用户所关心的。 我们在 PiTR 的稳定性上也做了很多的优化,其中包括:
通过优化 BR 与 PD 和 TiKV 的通信机制,在绝大多数 TiDB 集群异常场景和 TiKV 滚动重启场景,PiTR 都可以保证 RPO 小于 5 分钟
通过优化恢复性能,让 PiTR 在应用日志阶段的性能达到30 GB/h,从而降低降低 RTO 时间。
接下来,我们会对 PiTR 这个特性进行更多的优化,不断的提升这个特性的稳定性和性能。并探索备份恢复的更多可能性,将 TiDB 的备份恢复特性打造成稳定可靠的高性能备份恢复解决方案。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

