
黄东旭解析 TiDB 的核心优势
413
2020-02-27
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247490929&idx=1&sn=5f033c18a67fb347b4f3689e7c13040a&chksm=eb163a1bdc61b30dccfcf068eb7a8902e48f38a8516f3f25be3660ab9d194e93f9c4b517ad62#rd
数据库作为基础设施,其安全性不言而明,因此数据安全备份和恢复功能是在严肃使用场景下的标配。TiDB 作为一款分布式数据库,目前可以满足超大集群的备份恢复的需求,经过测试,10T 数据的备份恢复速度可以达到 GB/s 级别。这得益于我们研发的分布式备份恢复工具 Backup&Restore That Scales(以下简称 BR)。
如果你业务产生海量数据,并极度重视数据安全、备份恢复的效率,那么 TiDB + BR 值得一试,从此再也不怕“删库跑路、恢复缓慢”。
一个 10T 集群的测试
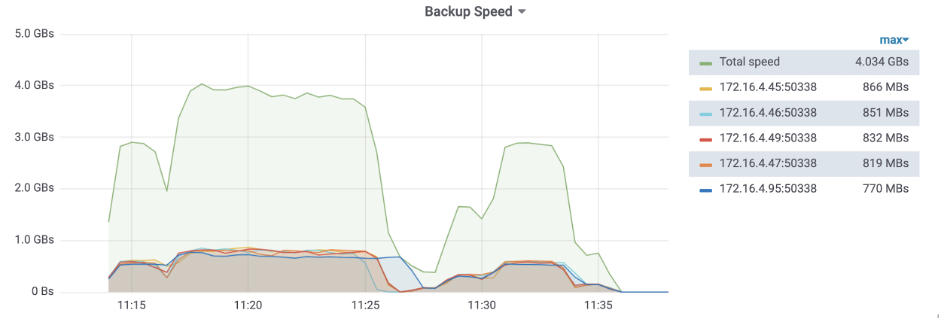
备份速度:548MB/s * TiKV 节点数;
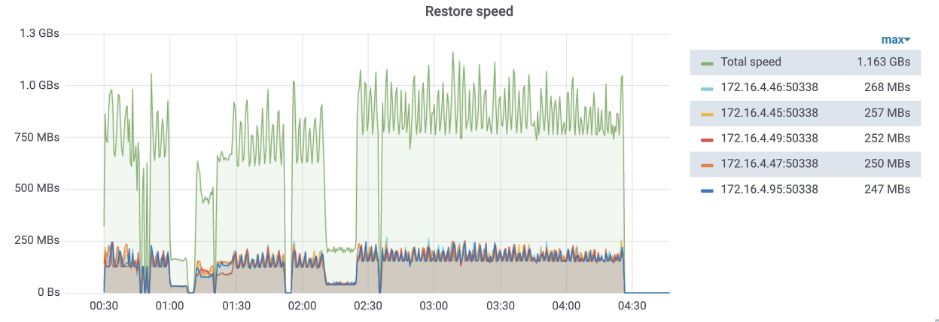
恢复速度:150MB/s * TiKV 节点数。
备份
图片说明:
恢复
图片说明:
分布式数据库备份恢复的难点
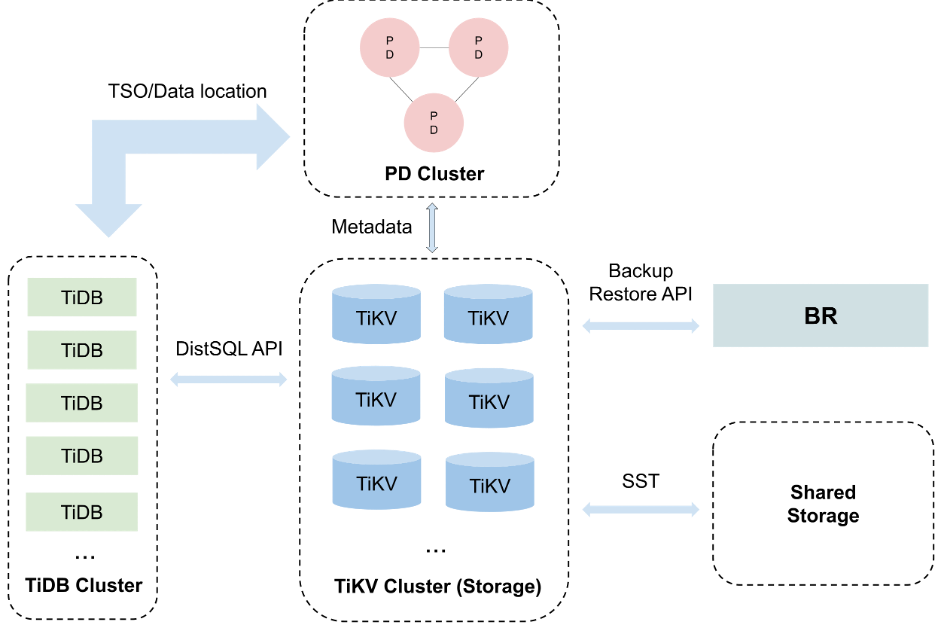
BR 设计与实现
水平扩展
强一致性
体验一下?
BR 使用手册:
https://pingcap.com/docs-cn/v3.1/reference/tools/br/br/
BR 备份与恢复场景示例:
https://pingcap.com/docs-cn/v3.1/reference/tools/br/use-cases/
更多令人期待的新功能
Backup to common cloud storage
https://github.com/pingcap/br/issues/89
在云的时代,怎么能缺少对云存储的支持?BR 已经支持将备份保存到 AWS S3 上,不久也将支持备份到 Google Cloud Storage。
Online restore
https://github.com/pingcap/br/issues/87
最初,BR 恢复的定位和 TiDB Lightning 一样,只支持离线恢复到全新的集群。通过这个功能,BR 即将支持在线恢复,这对 OLAP 场景中的导入数据阶段非常有帮助。
附:
[1] 五台 Intel® E5-2630v4, Intel® *** P4510 4TB 物理机,每台部署一个 TiKV,使用本地模式进行备份恢复。备份数据库逻辑大小 3.34T,三副本物理大小 10.1T。备份并发参数 16,恢复并发参数 128。恢复速度受 Region 调度影响比较大,不包含调度,速度为 279MB/s。
[2] loader 工具的 load 模块性能测试数据:
https://pingcap.com/docs-cn/stable/benchmark/dm-v1.0-ga/#在-load-处理单元使用不同-pool-size-的性能测试对比

版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

