

黄东旭解析 TiDB 的核心优势
595
2019-12-06
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247490403&idx=1&sn=71b66c0acf6a57b79e1a465b4bf72cf2&chksm=eb163c09dc61b51f3483fdd000c064209af119d532441c4a8a84f617558e43598e9604f0a658#rd
作者介绍
代晓磊,现 360 商业化数据库运维专家,负责整个智能商业业务线数据库运维,解决各种数据库疑难问题,推广 TiDB 等新开源数据库应用。目前是 TiDB User Group Ambassador。
业务简介以及数据库选型
360 智能商业业务线广告主实时报表业务简介

数据库选型:MySQL or TiDB?
说到 TiDB 不得不提其架构。下面结合架构图简单介绍一下 TiDB 对于我们来说最有吸引力的特性。

1. 可在线扩展:TiDB Server/PD/TiKV 这 3 大核心模块各司其职,并且支持在线扩容,region 自动 balance,迁移过程对业务无感知。
监控:基于 Prometheus + Grafana 的丰富监控模板;
运维工具:TiDB Ansible 部署+运维;
TiDB Data Migration(DM):将数据从 MySQL 迁移+同步的工具;
TiDB Lightning:可以从 CSV 文件或者第三方数据源将数据直接导入到 TiKV;
TiDB Binlog:备份工具,也可以重放到 Kafka/MySQL/TiDB 等数据库。
系统配置及部署架构

写热点问题优化实践
热点现象描述
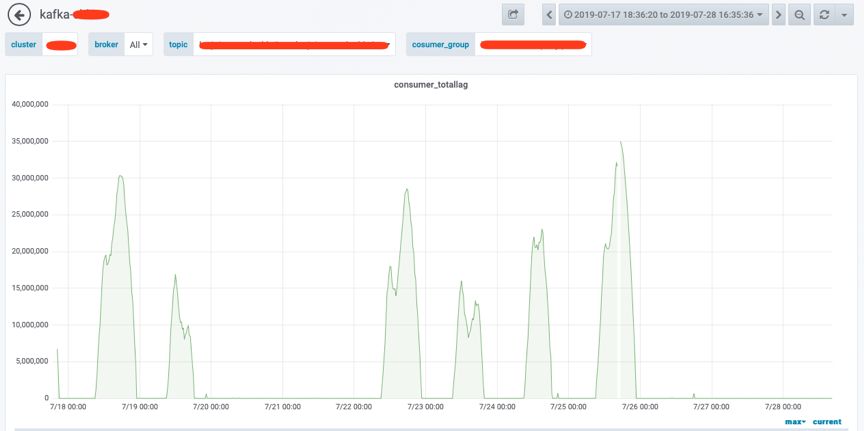


解决方案
SHARD_ROW_ID_BITS 来打散热点,如果业务表可以新建的话(比如我们的报表业务是按天分表),可以结合 pre-split-regions 属性一起在建表阶段就将 Region 打散。如果不满足上面的表结构(比如就是以自增 ID 为主键的表),可以使用手动 split region 功能。上面的两种方法都需要 PD 的参数调整来加快热点 Region 的调度。python table-regions.py --host=tidb_host –port=10080 db_name tb_name
[RECORD – db_name.tb_name] - Leaders Distribution:
total leader count: 282
store: 1, num_leaders: 1, percentage: 0.35%
store: 4, num_leaders: 13, percentage: 4.61%
store: 5, num_leaders: 16, percentage: 5.67%
store: 7, num_leaders: 252, percentage: 89.36%
~~~~~~~~~~~~~~~~~~~~~~~~~~~
curl http:// ${tidb_host}:10080/tables/db_name/tb_name/regions > regions.log
pd-ctl -u http:// ${pd_host}:2379 operator add split-region region_id
grep -B 3 ": 7" regions.log |grep "region_id"|awk -F': ' '{print $2}'|awk -F',' '{print "pd-ctl -u http://pd_host:2379 operator add split-region",$1}' > split_region.sh
sh split_region.sh
pd-ctl -u http://pd_host:2379 config set 参数值
"hot-region-schedule-limit": 8
"leader-schedule-limit": 8,
"region-schedule-limit": 16
innodb_flush_log_at_trx_commit(0,1,2) 类似,TiDB 也有一个 sync-log 参数,该参数控制数据、log 落盘是否 sync。注意:如果是非金融安全级别的业务场景,可以考虑设置成 false,以便获得更高的性能,但可能会丢数据。ansible-playbook rolling_update.yml --tags=tikv
注:本次优化保持默认 true。
pd-ctl -u http:// ${pd_host}:2379 operator show leader

SHARD_ROW_ID_BITS 结合 PRE_SPLIT_REGION 的方式来打散热点。SHARD_ROW_ID_BITS 来适度分解 Region 分片,以达到打散 Region 热点的效果。使用方式:ALTER TABLE t SHARD_ROW_ID_BITS = 4; #值为 4 表示 16 个分片
PRE_SPLIT_REGIONS 建表预切分功能,通过配置可以预切分 2^(pre_split_regions-1) 个 Region。SHARD_ROW_ID_BITS 结合 PRE_SPLIT_REGION 配置。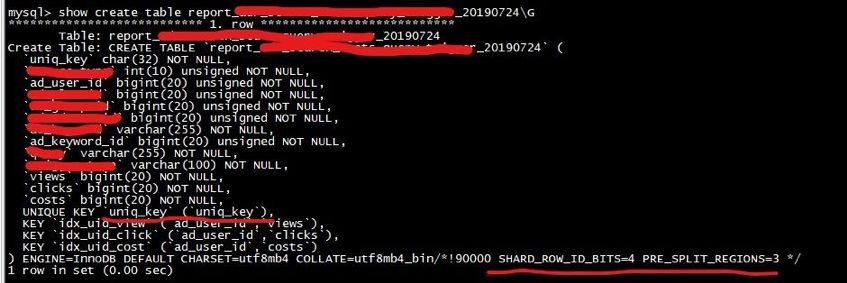
SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGION 这 2 个参数使用详情参见官方文档:https://pingcap.com/docs-cn/v3.0/faq/tidb/#6-1-2-如何打散热点
Auto_Random。这个属性类似于 Auto_Increment,可以定义在整型主键上,由 TiDB 自动分配一个保证不重复的随机 ID。有了这个特性后,上面的例子可以做到不删除主键 ID,同时避免写入热点。最终优化效果

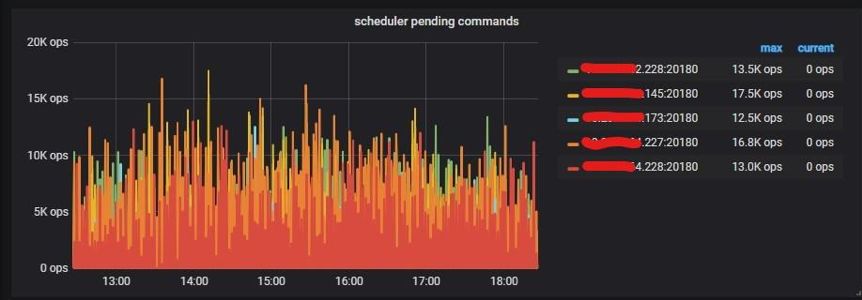
总结
典型实践
知乎 | 万亿量级业务数据下的实践和挑战
平安科技 | 核心系统的引入及应用
微众银行 | 数据库架构演进及 TiDB 实践经验
华泰证券 | TiDB 在华泰证券的探索与实践
丰巢 | 支付平台百亿级数据
美团点评 | 深度实践之旅
贝壳金服 | 在线跨机房迁移实践
易果生鲜 | 实时数仓
小红书 | 从 0 到 200+ 节点的探索和应用
小米 | TiDB 在小米的应用实践
58 集团 | 应用与实践
爱奇艺 | 边控中心/视频转码/用户登录信息系统
Shopee | 东南亚领先电商 Shopee 业务升级
转转二手交易网 | TiDB 在转转的应用实践
同程艺龙 | 1. 票务项目 2.自研 TiDB 运维工具 Thor
今日头条 | 核心 OLTP 系统
更多:https://pingcap.com/cases-cn/

版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

