

黄东旭解析 TiDB 的核心优势
599
2019-09-09
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247489676&idx=1&sn=c27466ec6ff86b98d426f3e0173de75c&chksm=eb163fe6dc61b6f0019415bd35ee94cf0f62a8ae88b040bd1a8cd40594711b6e138f42262158#rd
作者介绍
李坤,PingCAP 互联网架构师,TUG Ambassador,前美团、去哪儿数据库专家。
一、概述
二、监控架构
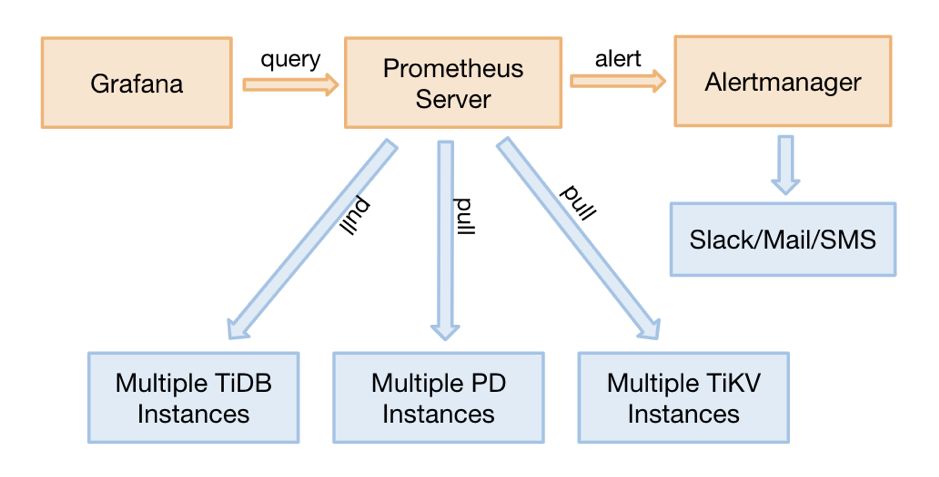
之前如果 Prometheus 需要迁移,需要重启整个集群,因为组件要调整 push 的目标地址。
现在可以部署 2 套 Prometheus,防止监控的单点,因为 pull 的 source 端是可以多个。
去掉了 PushGateWay 这个单点组件。
三、监控数据的来源与展示
| 组件 | 端口 |
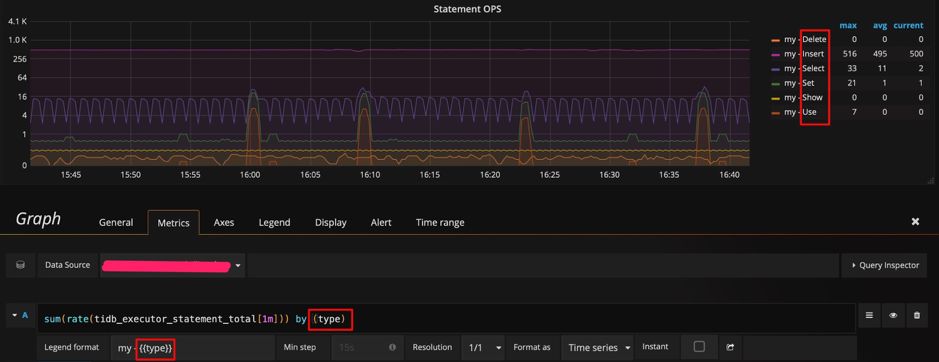
# 可以看到实时 qps 的数据,区分不同的 type,value 是 counter 类型的累计值(科学计数法)
curl http://__tidb_ip__:10080/metrics |grep tidb_executor_statement_total
tidb_executor_statement_total{type="Delete"} 520197
tidb_executor_statement_total{type="Explain"} 1
tidb_executor_statement_total{type="Insert"} 7.20799402e+08
tidb_executor_statement_total{type="Select"} 2.64983586e+08
tidb_executor_statement_total{type="Set"} 2.399075e+06
tidb_executor_statement_total{type="Show"} 500531
tidb_executor_statement_total{type="Use"} 466016
Edit 按钮(或直接按 e),如下图所示:
Metric 面板上,看到利用该 metric 的 query 表达式。rate[1m]:表示 1 分钟的增长速率,只能用于 counter 类型的数据。
sum:表示 value 求和。
by type:表示将求和后的数据按 metric 的原始值中的 type 进行分组。
Legend format:表示指标名称的格式。
Resolution:默认打点步长是 15s,Resolution 表示是否分解。
四、Grafana 使用技巧
instance、job、type)。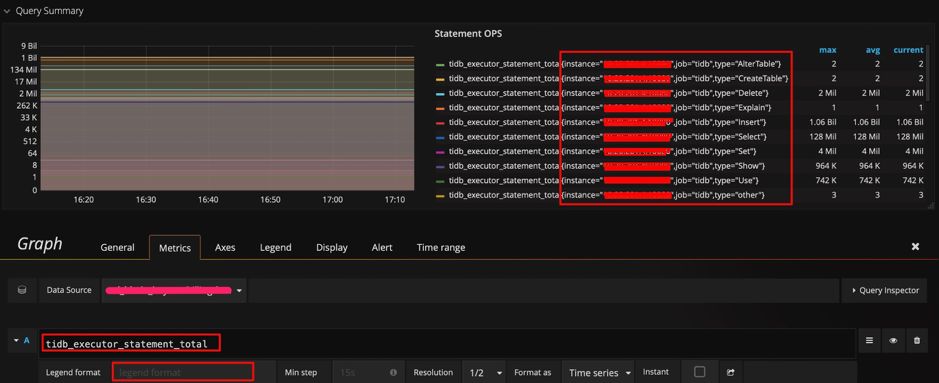
instance 这个维度后,我们调整表达式,在原有的 type 后面加上 instance 这个维度,调整 legend format 格式增加 {{instance}},就可以看到每个 tidb-server 上执行的不同类型 SQL 的 QPS 了。如下图: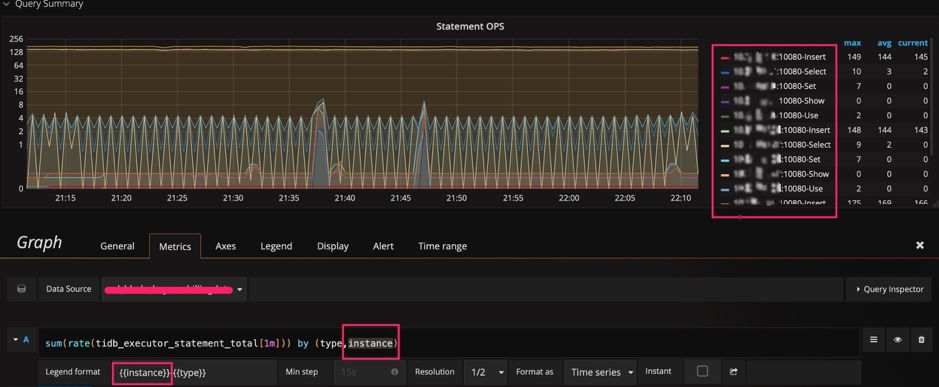
query duration 指标为例,默认的比例尺采用 2 的对数计算,显示上会将差距缩小。为了观察明显的变化,可以将比例尺改为线性,通过下面两张图,可以看到显示上的区别,明显的发现那个时刻有个 SQL 运行较慢。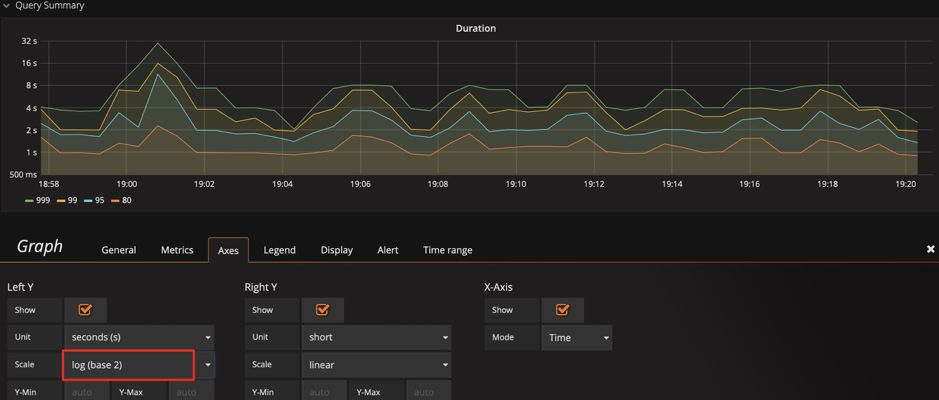
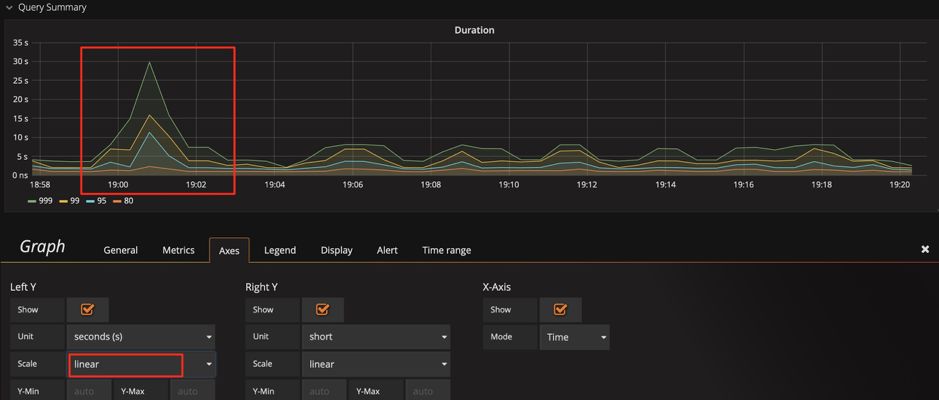
提示:我们可以结合技巧 1,发现这里还有一个 sql_type的维度,可以立刻分析出是 select 慢还是 update 慢,并且可以分析出是在哪个 instance 上慢。
Store size 的实时变化效果,由于基数较大,微弱的变化观察不到。这时我们可以将 Y 轴最小值从 0 改为 auto,将上部放大,观察下面两张图的区别,可以观察到数据已开始迁移了。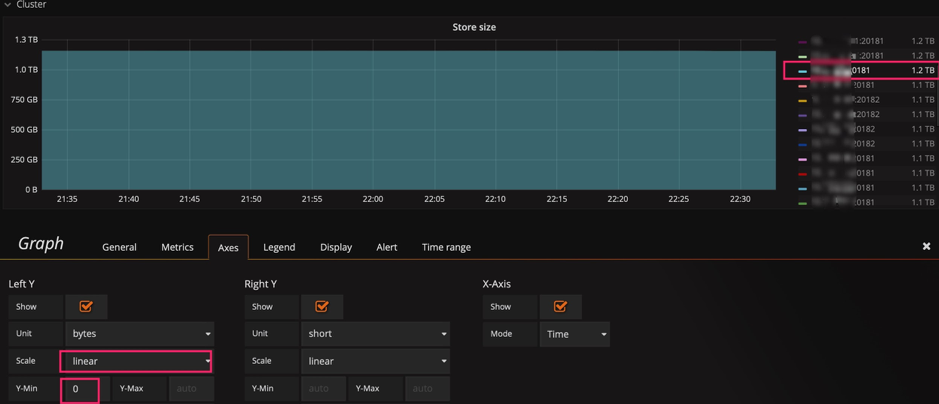

Graph Tooltip 的设置,默认使用 Default。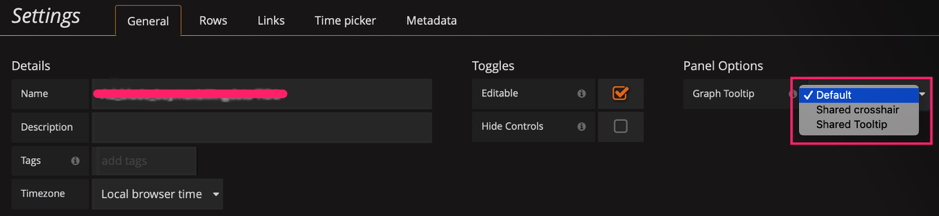
Shared crosshair 和 Shared Tooltip 分别试一下效果:可以看到标尺可以联动展示了,方便排查问题时,确认 2 个指标的关联性。

ip:2379 来看到当时的数据。通常默认图例中只有 Max 和 Current,但有时指标波动较大时,我们可以增加 Avg 等其他汇总函数的图例,可以看一段时间的整体趋势。
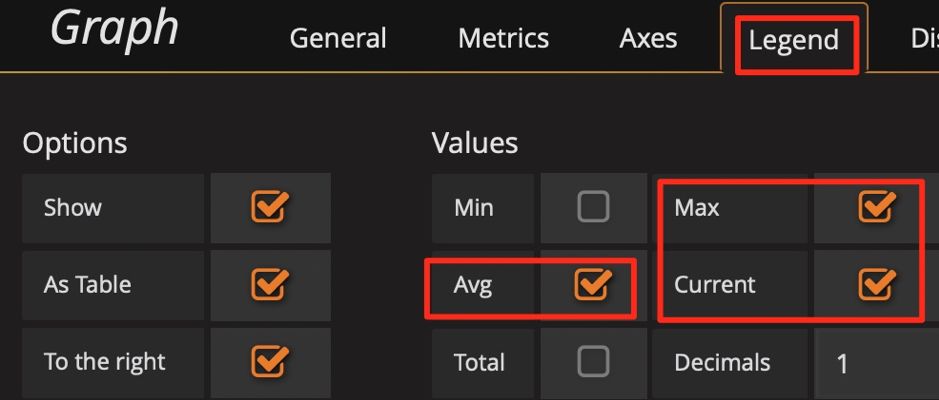
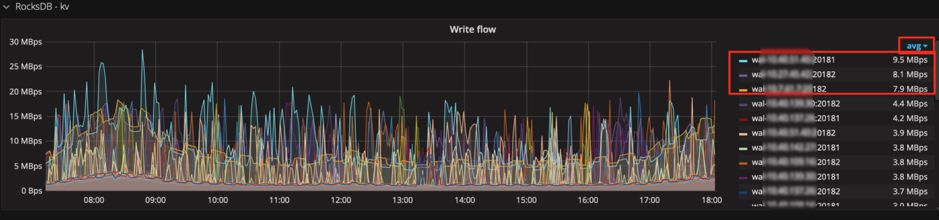
图 15 增加 Avg 函数
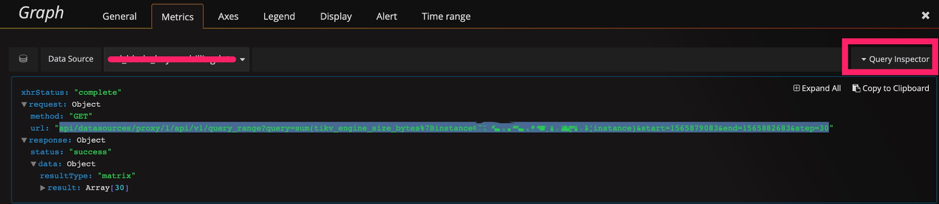
curl -u user:pass 'http://__grafana_ip__:3000/api/datasources/proxy/1/api/v1/query_range?query=sum(tikv_engine_size_bytes%7Binstancexxxxxxxxx20181%22%7D)%20by%20(instance)&start=1565879269&end=1565882869&step=30' |python -m json.tool
{
"data": {
"result": [
{
"metric": {
"instance": "xxxxxxxxxx:20181"
},
"values": [
[
1565879269,
"1006046235280"
],
[
1565879299,
"1006057877794"
],
[
1565879329,
"1006021550039"
],
[
1565879359,
"1006021550039"
],
[
1565882869,
"1006132630123"
]
]
}
],
"resultType": "matrix"
},
"status": "success"
}
五、总结
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

