


黄东旭解析 TiDB 的核心优势
587
2018-10-22
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247486956&idx=2&sn=4a9207aa58df09e1ea28ce36d0b881f5&chksm=eb162a86dc61a390406041ab6e5a215096f1145e8b40aa6710330f4452671fce353313173ee3#rd
有时候,在跟一些同学讨论 TiKV 事务模型的时候,我都提到了 Linearizability,也提到了 Snapshot Isolation,以及需要手动 lock 来保证 Serializable Snapshot Isolation,很多时候,当我嘴里面蹦出来这些名词的时候,有些同学就一脸懵逼了。所以我觉得有必要仔细来解释一下,顺带让我自己将所有的 isolation 以及 consistency 这些情况都归纳总结一遍,让自己也理解透彻一点。
幸运的是,业内已经有很多人做了这个事情,譬如在 Highly Available Transactions: Virtues and Limitations 这篇论文里面,作者就总结了不同模型是否能满足 Highly Available Transactions(HATs)。
图中,红色圆圈里面的模型属于 Unavailable,蓝色的属于 Sticky Available,其余的就是 Highly Available。这里解释下相关的含义:
Unavailable:当出现网络隔离等问题的时候,为了保证数据的一致性,不提供服务。熟悉 CAP 理论的同学应该清楚,这就是典型的 CP 系统了。
Sticky Available:即使一些节点出现问题,在一些还没出现故障的节点,仍然保证可用,但需要保证 client 的操作是一致的。
Highly Available:就是网络全挂掉,在没有出现问题的节点上面,仍然可用。
Unavailable 比较容易理解,这里在讨论下 Sticky 和 Highly,对于 Highly Available 来说,如果一个 server 挂掉了,client 可以去连接任意的其他 server,如果这时候仍然能获取到结果,那么就是 Highly Available 的。但对于 Sticky 来说,还需要保证 client 操作的一致性,譬如 client 现在 server 1 上面进行了很多操作,这时候 server 1 挂掉了,client 切换到 server 2,但在 server 2 上面看不到 client 之前的操作结果,那么这个系统就不是 Sticky 的。所有能在 Highly Available 系统上面保证的事情一定也能在 Sticky Available 系统上面保证,但反过来就不一定了。
Jepsen 在官网上面有一个简化但更好看一点的图
下面,我会按照 Jepsen 里面的图,对不同的 model 进行解释一下。至于为啥选择 Jepsen 里面的例子,一个是因为 Jepsen 现在是一款主流的测试不同分布式系统一致性的工具,它的测试用例就是测试的是上图提到的模型,我们自然也会关心这些模型。另外一个就是这个模型已经覆盖了大多数场景了,理解了这些,大部分都能游刃有余处理了。
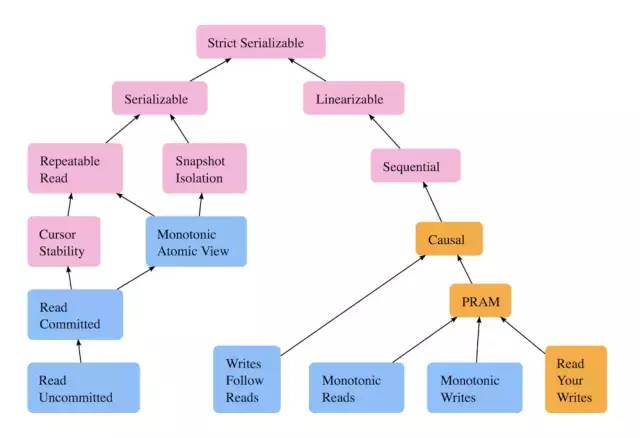
如果大家仔细观察,可以发现,从根节点 Strict Serializable,其实是有两个分支的,一个对应的就是数据库里面的 Isolation(ACID 里面的 I),另一个其实对应的是分布式系统的 Consistency(CAP 里面的 C),在 HATs 里面,叫做 Session Guarantees。
Isolation
要对 Isolation 有个快速的理解,其实只需要看 A Critique of ANSI SQL Isolation Levels 这篇论文就足够了,里面详细的介绍了数据库实现中遇到的各种各样的 isolation 问题,以及不同的 isolation level 到底能不能解决。
在论文里面,作者详细的列举了多种异常现象,这里大概介绍一下。
P0 - Dirty Write
Dirty Write 就是一个事务,覆盖了另一个之前还未提交事务写入的值。假设现在我们有两个事务,一个事务写入 x = y = 1,而另一个事务写入 x = y = 2,那么最终的结果,我们是希望看到 x 和 y 要不全等于 1,要不全等于 2。但在 Dirty Write 情况下面,可能会出现如下情况:

可以看到,最终的值是 x = 2 而 y = 1,已经破坏了数据的一致性了。
P1 - Dirty Read
Dirty Read 出现在一个事务读取到了另一个还未提交事务的修改数据。假设现在我们有一个两个账户,x 和 y,各自有 50 块钱,x 需要给 y 转 40 元钱,那么无论怎样,x + y = 100 这个约束是不能打破的,但在 Dirty Read 下面,可能出现:

在事务 T2,读取到的 x + y = 60,已经打破了约束条件了。
P2 - Fuzzy Read
Fuzzy Read 也叫做 Non-Repeatable Read,也就是一个还在执行的事务读取到了另一个事务的更新操作,仍然是上面的转账例子:

在 T1 还在运行的过程中,T2 已经完成了转账,但 T1 这时候能读到最新的值,也就是 x + y = 140 了,破坏了约束条件。
P3 - Phantom
Phantom 通常发生在一个事务首先进行了一次按照某个条件的 read 操作,譬如 SQL 里面的 SELECT WHERE P,然后在这个事务还没结束的时候,另外的事务写入了一个新的满足这个条件的数据,这时候这个新写入的数据就是 Phantom 的了。
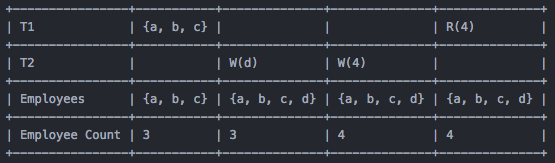
假设现在 T1 按照某个条件读取到了所有雇员 a,b,c,这时候 count 是 3,然后 T2 插入了一个新的雇员 d,同时更新了 count 为 4,但这时候 T1 在读取 count 的时候会得到 4,已经跟之前读取到的 a,b,c 冲突了。
P4 - Lost Update
我们有时候也会遇到一种 Lost Update 的问题,如下:

在上面的例子中,我们没有任何 dirty write,因为 T2 在 T1 更新之前已经提交成功,也没有任何 dirty read,因为我们在 write 之后没有任何 read 操作,但是,当整个事务结束之后,T2 的更新其实丢失了。
P4C - Cursor Lost Update
Cursor Lost Update 是上面 Lost Update 的一个变种,跟 SQL 的 cursor 相关。在下面的例子中,RC(x) 表明在 cursor 下面 read x,而 WC(x) 则表明在 cursor 下面写入 x。

如果我们允许 T2 在 T1 RC 和 WC 之间写入数据,那么 T2 的更新也会丢失。
A5A - Read Skew
Read Skew 发生在两个或者多个有完整性约束的数据上面,还是传统的转账例子,需要保证 x + y = 100,那么 T1 就会看到不一致的数据了。
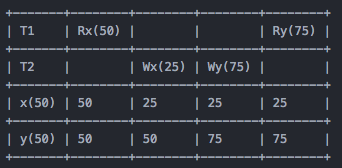
A5B - Write Skew
Write Skew 跟 Read Skew 比较类似,假设 x + y <= 100,T1 和 T2 在执行的时候都发现满足约束,然后 T1 更新了 y,而 T2 更新了 x,然后最终结果打破了约束,如下:

Isolation Levels
上面我们介绍了不同的异常情况,下面的表格说明了,在不同的隔离级别下面,那些异常情况可能发生:

NP - Not Possible,在该隔离级别下面不可能发生
SP - Sometimes Possible,在该隔离级别下面有时候可能发生
P - Possible,在该隔离级别下面会发生
鉴于网上已经对不同的 Isolation Level,尤其是 MySQL 的解释的太多了,这里就简单的解释一下。
Read Uncommitted - 能读到另外事务未提交的修改。
Read Committed - 能读到另外事务已经提交的修改。
Cursor Stability - 使用 cursor 在事务里面引用特定的数据,当一个事务用 cursor 来读取某个数据的时候,这个数据不可能被其他事务更改,除非 cursor 被释放,或者事务提交。
Monotonic Atomic View - 这个级别是 read committed 的增强,提供了一个原子性的约束,当一个在 T1 里面的 write 被另外事务 T2 观察到的时候,T1 里面所有的修改都会被 T2 给观察到。
Repeatable Read - 可重复读,也就是对于某一个数据,即使另外的事务有修改,也会读取到一样的值。
Snapshot - 每个事务都会在各自独立,一致的 snapshot 上面对数据库进行操作。所有修改只有在提交的时候才会对外可见。如果 T1 修改了某个数据,在提交之前另外的事务 T2 修改并提交了,那么 T1 会回滚。
Serializable - 事务按照一定顺序执行。
另外需要注意,上面提到的 isolation level 都不保证实时约束,如果一个进程 A 完成了一次写入 w,然后另外的进程 B 开始了一次读取 r,r 并不能保证观察到 w 的结果。另外,在不同事务之间,这些 isolation level 也不保证不同进程的顺序。一个进程可能在一次事务里面看到一次写入 w,但可能在后面的事务上面没看到同样的 w。事实上,一个进程甚至可能看不到在这个进程上面之前的写入,如果这些写入都是发生在不同的事务里面。有时候,他们还可能会对事务进行排序,譬如将 write-only 的事务放到所有的 read 事务的后面。
要解决这些问题,我们需要引入顺序约束,这也就是下面 Session Guarantee 要干的事情。
Session Guarantee
在 HATs 论文里面,相关的概念叫做 Session Guarantee,主要是用来保证在一个 session 里面的实时性约束以及客户端的操作顺序。
Writes Follow Reads
如果某个进程读到了一次写入 w1 写入的值 v,然后进行了一次新的写入 w2,那么 w2 写入的值将会在 w1 之后可见。
Monotonic Reads
如果一个进程开始了一次读取 r1,然后在开始另一次读取 r2,那么 r2 不可能看到 r1 之前数据。
Monotonic Writes
如果一个进程先进行了一次写入 w1,然后在进行了一次写入 w2,那么所有其他的进程都会观察到 w1 在 w2 之前发生。
Read Your Writes
如果一个进程先进行了一次写入 w,然后后面执行了一次读取 r,那么 r 一定会看到 w 的改动。
PRAM
PRAM 就是 Pipeline Random Access Memory,对于单个进程的写操作都被观察到是顺序的,但不同的进程写会观察到不同的顺序。譬如下面这个操作是满足 PRAM 的,但不满足后面说的 Causal。

Causal
Causal 确定了有因果关系的操作在所有进程间的一致顺序。譬如下面这个:

对于 P3 和 P4 来说,无论是先读到 2,还是先读到 1, 都是没问题的,因为 P1 和 P2 里面的 write 操作并没有因果性,是并行的。但是下面这个:
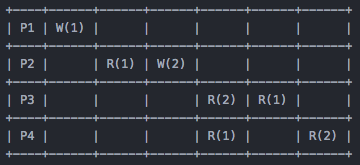
就不满足 Cansal 的一致性要求了,因为对于 P2 来说,在 Write 2 之前,进行了一次 Read 1 的操作,已经确定了 Write 1 会在 Write 2 之前发生,也就是确定了因果关系,所以 P3 打破了这个关系。
Sequential
Sequential 会保证操作按照一定顺序发生,并且这个顺序会在不同的进程上面都是一致的。一个进程会比另外的进程超前,或者落后,譬如这个进程可能读到了已经是陈旧的数据,但是,如果一个进程 A 从进程 B 读到了某个状态,那么它就不可能在读到 B 之前的状态了。
譬如下面的操作就是满足 Sequential 的:

对于 P3 来说,它仍然能读到之前的 stale 状态 1。但下面的就不对了:
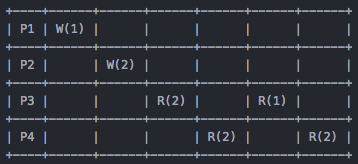
对于 P3 来说,它已经读到了最新的状态 2,就不可能在读到之前的状态 1 了。
Linearizable
Linearizability 要求所有的操作都是按照一定的顺序原子的发生,而这个顺序可以认为就是跟操作发生的时间一致的。也就是说,如果一个操作 A 在 B 开始之前就结束了,那么 B 只可能在 A 之后才能产生作用。
譬如下面的操作:

对于 P3 和 P4 来说,因为之前已经有新的写入,所以他们只能读到 2,不可能读到 1。
Strict Serializable
终于来到了 Strict Serializable,大家可以看到,它结合了 serializable 以及 linearizable,也就是说,它会让所有操作按照实时的顺序依次操作,也就是所有的进程会观察到完全一致的顺序,这也是最强的一致性模型了。
TiKV
好了,最后再来聊聊 TiKV,TiKV 是一个支持分布式事务的 key-value database。对于某个事务,TiKV 会通过 PD 这个服务在事务开始的时候分配一个 start timestamp,以及事务提交的时候分配一个 commit timestamp。因为我们的授时是通过 PD 这个单点服务进行的,所以时间是一定能保证单调递增的,也就是说,我们所有的操作都能跟保证实时有序,也就是满足 Linearizable。
TiKV 采用的是常用的 MVCC 模型,也就是每个 key-value 实际存储的时候,会在 key 上面带一个 timestamp,我们就可以用 timestamp 来生成整个数据库的 snapshot 了,所以 TiKV 是 snapshot isolation 的。既然是 snapshot isolation,那么就会遇到 write skew 问题,所以 TiKV 额外提供了 serializable snapshot isolation,用户需要显示的对要操作的数据进行 lock 操作。
但现在 TiKV 并不支持对 range 加 lock,所以不能完全的防止 phantom,譬如假设最多允许 8 个任务,现在已经有 7 个任务了,我们还可以添加一个任务,但这时候另外一个事务也做了同样的事情,但添加的是不同的任务,这时候就会变成 9 个任务,另外的事务在 scan 的时候就会发现打破了约束。这个也就是 A Critique of ANSI SQL Isolation Levels 里面提到的 sometimes possible。
所以,TiKV 是 snapshot isolation + linearizable。虽然 TiKV 也可以支持 Read Committed,但通常不建议在生产环境中使用,因为 TiKV 的 Read Committed 跟传统的还不太一样,可能会出现能读到一个事务提交到某个节点的数据,但这时候在另外的节点还读不到这个事务提交的数据,毕竟在分布式系统下面,不同节点的事务提交也是有网络延迟的,不可能同时执行。
小结
在分布式系统里面,一致性是非常重要的一个概念,理解了它,在自己设计分布式系统的时候,就能充分的考虑到底系统应该提供怎样的一致性模型。譬如对于 TP 数据库来说,就需要有一个比较 strong 的一致性模型,而对于一些不重要的系统,譬如 cache 这些,就可以使用一些比较 weak 的模型。对 TiKV 来说,我们在 Percolator 基础上面,也一直在致力于分布式事务的优化,如果你对这方面感兴趣,欢迎联系我 tl@pingcap.com。
💡文中划线部分均有跳转,点击【阅读原文】查看原版
延展阅读

版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

