


黄东旭解析 TiDB 的核心优势
657
2018-05-29
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247486134&idx=1&sn=e3b894ba22d7352c102f0a6d8016ebe9&chksm=eb162ddcdc61a4ca0de7d90f19455e9d20166df9b69a08dc2163fce74c97decfbae691120310#rd
作者:孙玄,转转公司首席架构师;陈东,转转公司资深工程师;冀浩东,转转公司资深 DBA。
公司及业务架构介绍
转转二手交易网 —— 把家里不用的东西卖了变成钱,一个帮你赚钱的网站。由***与 58 集团共同投资。为海量用户提供一个有担保、便捷的二手交易平台。转转是 2015 年 11 月 12 日正式推出的 APP,遵循“用户第一”的核心价值观,以“让资源重新配置,让人与人更信任”为企业愿景,提倡真实个人交易。
转转二手交易涵盖手机、3C 数码、母婴用品等三十余个品类。在系统设计上,转转整体架构采用微服务架构,首先按照业务领域模型垂直拆分成用户、商品、交易、搜索、推荐微服务。对每一个功能单元(商品等),继续进行水平拆分,分为商品网关层、商品业务逻辑层、商品数据访问层、商品 DB / Cache,如下图所示:
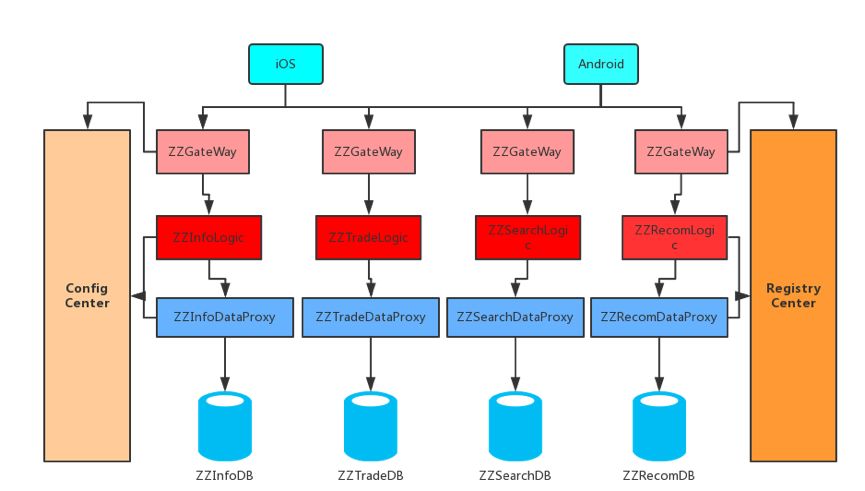
项目背景
1
面临的问题
转转后端业务现阶段主要使用 MySQL 数据库存储数据,还有少部分业务使用 ***。虽然目前情况下使用这两种存储基本可以满足我们的需求,但随着业务的增长,公司的数据规模逐渐变大,为了应对大数据量下业务服务访问的性能问题,MySQL 数据库常用的分库、分表方案会随着 MySQL Sharding(分片)的增多,业务访问数据库逻辑会越来越复杂。而且对于某些有多维度查询需求的表,我们总需要引入额外的存储或牺牲性能来满足我们的查询需求,这样会使业务逻辑越来越重,不利于产品的快速迭代。
从数据库运维角度讲,大数据量的情况下,MySQL 数据库在每次 DDL 都会对运维人员造成很大的工作量,当节点故障后,由于数据量较大,恢复时间较长。但这种 M - S 架构只能通过主从切换并且需要额外的高可用组件来保障高可用,同时在切换过程由于需要确定主库状态、新主库选举、新路由下发等原因,还是会存在短暂的业务访问中断的情况。
综上所述,我们面临的主要问题可归纳为:
数据量大,如何快速水平扩展存储;
大数据量下,如何快速 DDL;
分库分表造成业务逻辑非常复杂;
常规 MySQL 主从故障转移会导致业务访问短暂不可用。
2
为什么选择 TiDB
针对上章提到的问题,转转基础架构部和 DBA 团队考虑转转业务数据增速,定位简化业务团队数据库使用方案,更好的助力业务发展,决定启动新型存储服务(NewSQL)的选型调研工作。
TiDB 数据库,结合了关系库与 KV 存储的优点,对于使用方,完全可以当做 MySQL 来用,而且不用考虑数据量大了后的分库分表以及为了支持分库分表后的多维度查询而建立的 Mapping 表,可以把精力全部放在业务需求上。所以我们把 TiDB 作为选型的首选对象展开了测试和试用。
TiDB 测试
1
功能测试
TiDB 支持绝大多数 MySQL 语法,业务可以将基于 MySQL 的开发,无缝迁移至 TiDB。不过目前 TiDB 不支持部分 MySQL 特性,如:存储过程、自定义函数、触发器等。
2
TiDB 压力测试
通过测试工具模拟不同的场景的请求,对 TiDB 数据库进行压力测试,通过压力测试结果的对比,可以提供 RD 使用 TiDB 的合适业务场景以及 TiDB 的使用建议。
此次压力测试,总共使用 6 台物理服务器,其中 3 台 CPU 密集型服务器,用于启动 TiDB - Server、PD 服务;另外 3 台为 IO / CPU 密集型的PCIE 服务器,用于启动 TiKV 服务。
使用 sysbench - 1.0.11 测试数据大小为 200G 的 TiDB 集群,在不同场景下 TiDB 的响应时间(95th per):
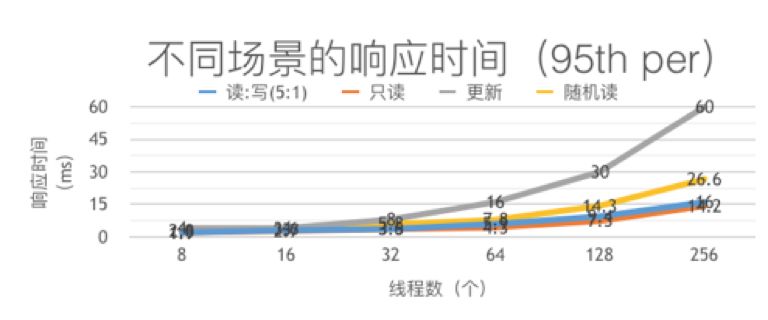
3
结果整理
顺序扫描的效率是比较高的,连续的行大概率会存储在同一台机器的邻近位置,每次批量的读取和写入的效率会高;
控制并发运行的线程数,会减少请求响应时间,提高数据库的处理性能。
4
场景建议
适合线上业务混合读写场景;
适合顺序写的场景,比如:数据归档、操作日志、摊销流水。
5
TiDB 预上线
将 TiDB 挂载到线上 MySQL,作为 MySQL 从库同步线上数据,然后业务将部分线上读流量切换到 TiDB,可以对 TiDB 集群是否满足业务访问做好预判。
业务接入
1
迁移过程
我们第一个接入 TiDB 的业务线是转转消息服务。消息作为转转最重要的基础服务之一,是保证平台上买卖双方有效沟通、促进交易达成的重要组件,其数据量和访问量都非常大。起初我们使用的是 MySQL 数据库,对其所有的业务都做了库的垂直拆分以及表的水平拆分。目前线上有几十 TB 的数据,记录数据达到了几百亿。虽对 MySQL 做了分库分表,但实例已经开始又有偶发的性能问题,需要马上对数据进行二次拆分,而二次拆分的执行成本也比较高,这也是我们首先迁移消息数据库的原因之一。
消息服务有几个核心业务表:联系人列表、消息表、系统消息表等等。联系人列表作为整个消息系统的枢纽,承载着巨大的访问压力。业务场景相对其他表最复杂的,也是这个表的实例出现了性能问题,所以我们决定先迁移联系人列表。
整个迁移过程分三步:测试(判断 TiDB 是否满足业务场景,性能是否 OK)、同步数据、切流量。
(1)测试:首先我们模拟线上的数据和请求对“联系人列表”做了大量功能和性能的验证,而且还将线上的数据和流量引到线下,对数据库做了真实流量的验证,测试结果证明 TiDB 完全满足消息业务的需求。引流工作,我们是通过转转自研的消息队列,将线上数据库的流量引一份到测试环境。测试环境消费消息队列的数据,转换成数据库访问请求发送到 TiDB 测试集群。通过分析线上和测试环境两个数据访问模块的日志可以初步判断 TiDB 数据库是否可以正常处理业务请求。当然仅仅这样是不够的,DBA 同学还需要校验 TiDB 数据的正确性(是否与线上 MySQL 库一致)。验证思路是抽样验证 MySQL 库表记录和 TiDB 的记录 Checksum 值是否一致。
(2)同步数据:DBA 同学部署 TiDB 集群作为 MySQL 实例的从库,将 MySQL 实例中的联系人列表(单实例分了 1024 个表)的数据同步到 TiDB 的一张大表中。
(3)切流量:切流量分为三步,每两步之间都有一周左右的观察期。
第一步将读流量灰度切到 TiDB 上;
第二步断开 TiDB 与 MySQL 的主从同步,业务开双写(同时写 MySQL 和 TiDB,保证两库数据一致)确保业务流量可以随时回滚到 MySQL;
第三步停止 MySQL 写入,到此业务流量完全切换到 TiDB 数据库上。
迁移过程中最重要的点就是确保两个数据库数据一致,这样读写流量随时可以切回 MySQL,业务逻辑不受任何影响。数据库双写的方案与上文提到的引流测试类似,使用消息队列引一份写入流量,TiDB 访问模块消费消息队列数据,写库。但仅仅这样是不能保证两个库数据一致的,因为这个方案无法保证两个写库操作的原子性。所以我们需要一个更严谨的方案,转转的消息队列还提供了事务消息的支持,可以保证本地操作和发送消息的原子性。利用这一特性再加上异步补偿策略(离线扫描日志,如果有失败的写入请求,修正数据)保证每个消息都被成功消费且两个库每次写入结果都是一致的,从而保证了 MySQL 与 TiDB 两个库的数据一致。
2
遇到问题
按照上述的方案,我们已经将消息所有的业务都切到 TiDB 数据库上。迁移过程中也不都是顺风顺水,也遇到了问题,过程中也得到了 TiDB 官方团队的大力支持。这里主要介绍两个问题:
(1)TiDB 作为分布式存储,其锁机制和 MySQL 有很大不同。我们有一个并发量很大,可能同时更新一条记录的场景,我们用了 MySQL 的唯一索引保证了某个 Key 值的唯一性,但如果业务请求使用默认值就会大量命中唯一索引,会造成 N 多请求都去更新统一同一条记录。在 MySQL 场景下,没有性能问题,所以业务上也没做优化。但当我们用这个场景测试 TiDB 时,发现 TiDB 处理不太好,由于其使用的乐观锁,数据库输出大量的重试的日志。业务出现几十秒的请求延迟,造成队列中大量请求被抛弃。PingCAP 的同学建议调整 retry_limit 但也没有完全生效(该 BUG 已经在 2.0 RC 5 已经修复),最后业务进行优化(过滤使用默认值的请求)后问题得到解决。
(2)第二个问题是运维方面的,DBA 同学按照使用 MySQL 的运维经验,对一个上近 T 的表做了 Truncate操作,操作后,起初数据库表现正常,但几分钟后,开始出现超时,TiKV 负载变高。最后请教 PingCAP 同学分析,定位是操作触发了频繁回收 Region 的 BUG(该 BUG TiDB 2.0 版本已经修复)。
线上效果对比
1
队列等待情况对比
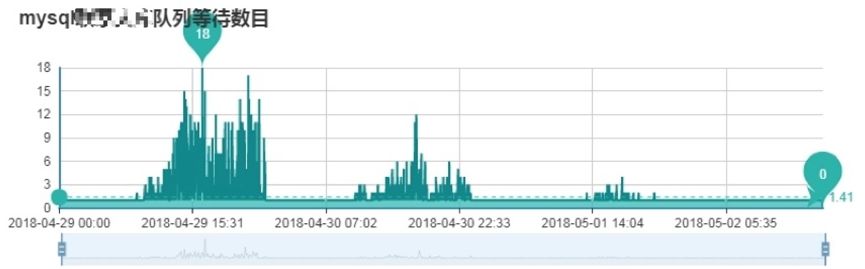
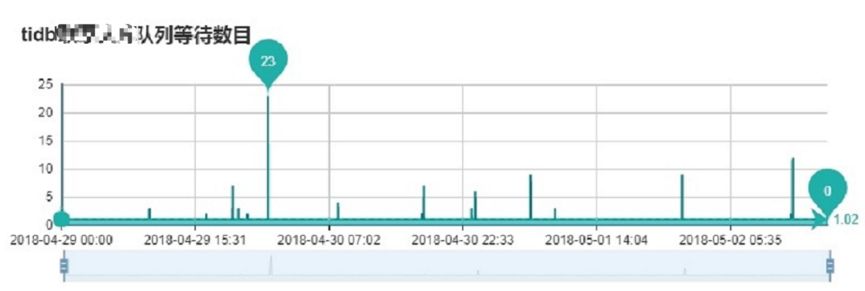
使用 TiDB 数据库,业务模块队列请求数基本保持 1 个,MySQL 会有较大抖动。
2
请求延迟情况对比
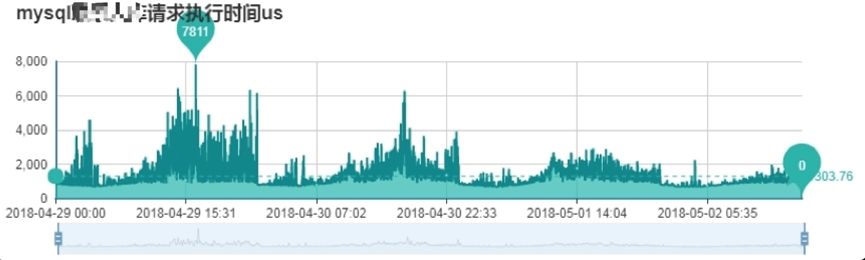
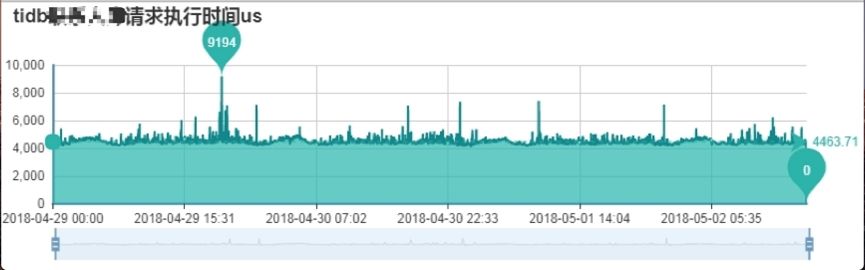
使用 TiDB 数据库,整体响应延时非常稳定,不受业务流量高峰影响,但 MySQL 波动很大。 另外在扩展性方面,我们可以通过无缝扩展 TiDB 和 TiKV 实例提升系统的吞吐量,这个特性 MySQL 是不具备的。
3
业务延迟和错误量对比

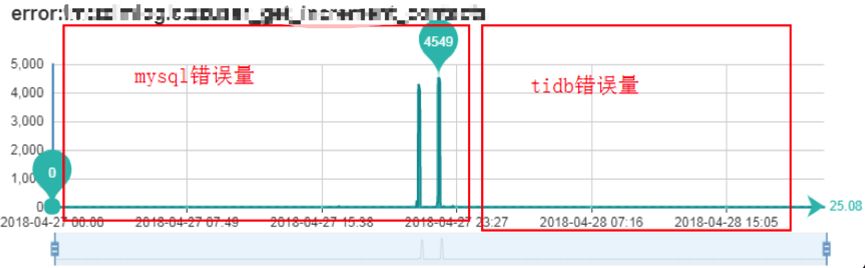
接入 TiDB 数据库后业务逻辑层服务接口耗时稳定无抖动,且没有发生丢弃的情况(上图错误大多由数据访问层服务队列堆积发生请求丢弃造成)。
TiDB 线上规模及后续规划
目前转转线上已经接入消息、风控两套 OLTP 以及一套风控 OLAP 集群。
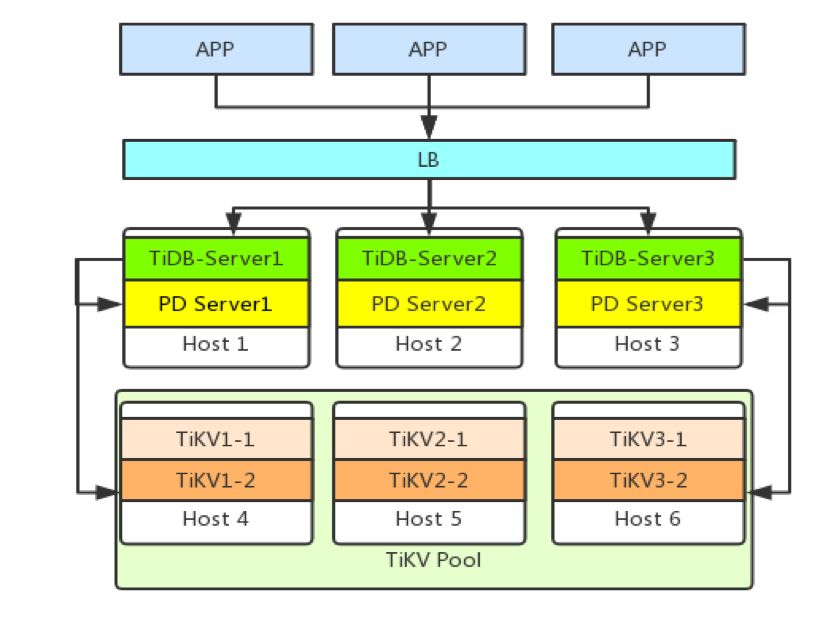
集群架构如下:目前转转线上 TiDB 集群的总容量几百 TB,线上 TiDB 表现很稳定,我们会继续接入更多的业务(留言,评论、搜索、商品、交易等等)。
1
后续规划
多个正在开发的新业务在开发和测试环境中使用 TiDB,线上会直接使用 TiDB;
转转核心的留言、评论、搜索、商品、交易订单库计划迁移到 TiDB,已经开始梳理业务,准备展开测试;
计划在后续 TiDB 的使用中,TiKV 服务器池化,按需分配 TiKV 节点。
2
TiDB 使用成果
利用 TiDB 水平扩展特性,避免分库分表带来的问题,使得业务快速迭代;
TiDB 兼容 MySQL 语法和协议,按照目前线上 MySQL 使用规范,可以无缝的迁移过去,无需 RD 做调整,符合预期;
在数据量较大的情况下,TiDB 响应较快,优于 MySQL;
集群出现故障对用户无感知;
TiDB 自带了完善的监控系统,使得运维成本大大降低。
延展阅读
TiDB 在威锐达 WindRDS 远程诊断及运维中心的应用
长按关注
新型分布式 NewSQL 数据库
微信号:pingcap2015
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

