



 微信ID:pingcap2015
微信ID:pingcap2015 长按左侧二维码关注
长按左侧二维码关注

黄东旭解析 TiDB 的核心优势
643
2017-05-03
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247484780&idx=2&sn=88cec55b38452c1a38a1946be41ad4bb&chksm=eb162206dc61ab106853adbd929673ae2c8f15fdcc9eec933e14156ec7b6ec56f8cdce02ee4c#rd
在由七牛云和 PingCAP 联合主办的架构师实践日上,我司最可爱的妹子,李霞同学做了题为《TiDB 原理与实战》的演讲,介绍了目前分布式数据库行业的现状,分享了 TiDB 作为新型分布式关系型数据库所能解决的痛点问题,并且讲解了 TiDB 的一些实现原理。以下是演讲实录~
1.数据库的现状
目前大家熟知的数据库大致可以分为 RDBMS、NoSQL 和 NewSQL 等。
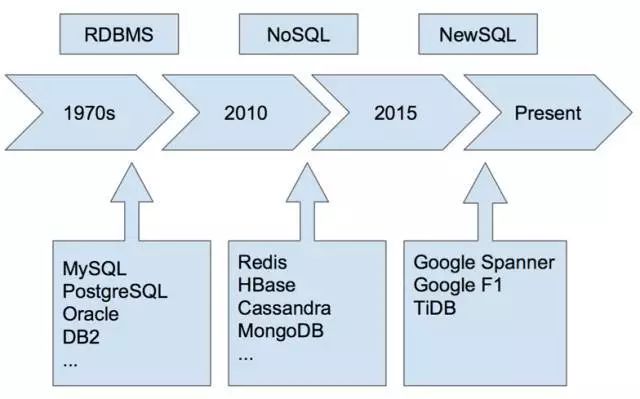
图 1
如图 1 所示是一个数据库解决方案的变迁史,这里做一些简单的介绍。以 MySQL 为例刚开始时,它是一个单机模式,但是随着数据库的数据量的增加及用户对性能要求的提高,它的存储容量和性能都遇到了瓶颈。这些需求催生了新的解决方案,那就是 MySQL 主从模式,进而将读写分离,减轻了读写系统的负担。虽然可以是多从,但是主是单点的。接下来就发展到了中间件的解决方案,这个方案优点是能够在一些限制条件下实现相对扩容,但它是由一种手动的、静态路由的方式来实现的扩容。那么对 DBA 在处理扩容操作时的要求就会比较高。之后诞生了 NoSQL 的解决方案,这里以 *** 为例:它支持强一致,多版本等,最重要是它在扩容和性能方面都做的比较好。但是它不支持 SQL 语法,对复杂查询没有怎么支持,还有它的分布式事务不支持跨行。从而引入了 NewSQL 的概念。那么怎么理解 NewSQL 呢?NewSQL 可以浅显地理解为 SQL + NoSQL 的概念,它支持 SQL 语法和分布式事务。
图 2 是 TiDB 和 TiKV 的架构,具体结构如图。这边带过一下 Coprocessor,它是一个灵活和通用框架扩展,将分布式计算直接放入 TiKV 进行特定处理的功能,这也是我额外介绍它的原因。
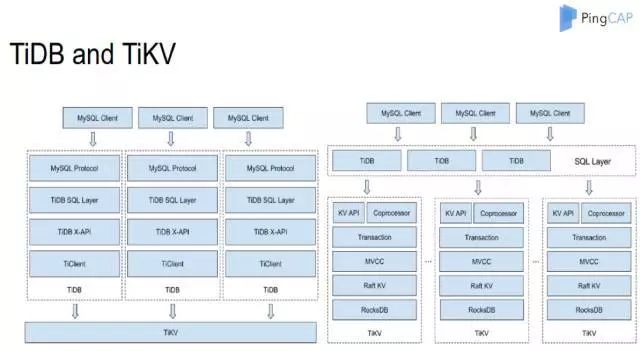
图 2
2.TiDB 简介
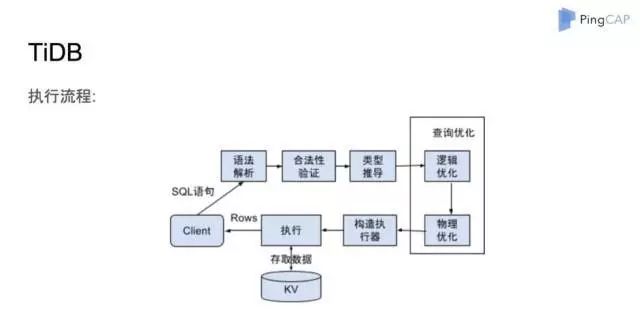
图 3
TiDB 处理用户请求的主要流程如图 3 所示。首先,请求从 Client 端进来后进入语法解析层,然后对语句进行合法性验证和类型推导,接着做查询优化——这里我们分了逻辑优化和物理优化。优化之后会构建一个执行器,最后执行——把数据从 TiKV 取出来进行计算,最后反馈结果。
3.Plan 优化
我们主要分两个层次来做优化。首先是逻辑层优化,它主要是依据关系代数的等价变换规则做优化。接着就是一个物理层优化,它主要根据数据的直方图分布,表连接顺序重排序等技术对查询进行优化。在逻辑优化的时候,我们会做一些基于规则的优化,然后再进入物理优化,物理优化是基于计算代价的一个优化,需要通过统计信息进行优化,最后执行。

图 4
对于 TP 型的数据库来说,这两个优化之后基本上满足了 TP 的大部分需求。当然我们也不止步于只支持 TP 型的请求,目前针对一些 AP 型的请求也在优化中。
3.1 逻辑优化
目前我们主要做了如下图的 5 个优化。其中 Prune column 和 Eliminate aggregation 的优化,大家可以看一下图 5 中优化前后的语句变化。这两个变化相对简单就不多解释了,还有几个优化会在下面做具体解释。

图 5
3.1.1 去关联化
Decorrelation,也叫子查询去关联化,比如有如下语句:
select * from t where t.id in (select id+1 as c2 from s where s.c1 < 10 and s.n = t.n)
那么我们看一下上面语句的变化过程。如图 6 所示,首先看如何将它变成一个图。SQL 的最外层是 from t ,因此左边 Plan 有一个 t 的 Data Scan。右边的子查询也是同样的从下往上构建,先是 s 的 Data Scan, 然后根据 Where 语句构建出条件为 s.c1 < 10 and s.n = t.n 的 Selection 算子,注意这里 t.n 是 s 表中不存在的,所以我们需要将它标记为关联列。再往上它有一个 Select 是 id+1 as c2,这在 TiDB 中对应 Projection 投影算子。中间的 Apply 代表从左边取一条数据,替换掉右边 Plan 的关联列,然后进行 Semi Join ,这里之所以选择 Semi Join 是根据 t.id in … 决定的。构建出查询图之后进行去关联化的优化,先是把 s 一侧的 Projection 上推,将 c2 替换为 s.id + 1 ,然后把 Selection 往上放到了 Semi Join 的连接条件下。这里的正确性有一些严格的论证过程,因为太复杂了,我就不跟大家解释了,就简单介绍一下最后的结果。到了这里之后,这两个 Plan 没有了关联列,于是可以将 Apply 算子直接改为 Semi Join 。
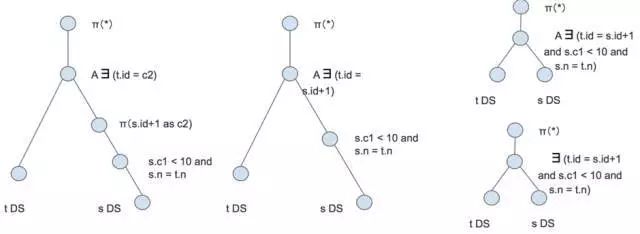
图 6
3.1.2 谓词下推
select * from t join s on t.id = s.id where t.c < 1 and s.c < 1
这个语句可以表示成图 7 左边的图。优化就是想把条件 t.c < 1 and s.c < 1 下推到两边的执行计划中。这样的话,我再计算 Join 的时候输入的数据会比原来小很多,因为条件的存在,t 和 s 扫表的代价也会减小。推到 T 的时候,直接过滤掉了大于等于 1 的数据再进行 Join。如果把 Join 改一下变成 Left Outer Join,右边是不能下推的。因为大家知道在 Left Outer Join 里面,如果左边找不到可以匹配的行,需要补 NULL 。如果我把右边的条件下推了,那么可能会出现很多补 NULL 的行,这些行没有了过滤条件,会全部返回。但是下推的这个条件实际上是可以把 NULL 过滤掉的,这样就会出现优化前后数据不一致的情况,造成正确性问题。所以优化的一个重要前提是前后都要等价,就是说结果是相等的。
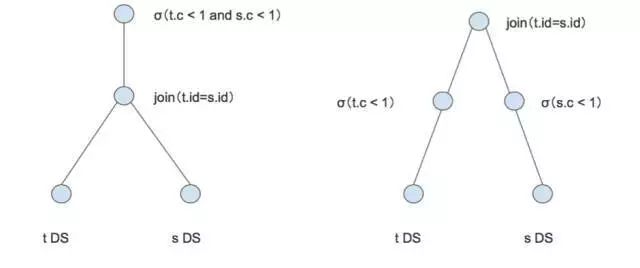
图 7
3.1.3 聚合下推
select sum(grade.scores) from stu join grade on stu.id = grade.stu_id and stu.name=“xwz”
如图 8 所示,这个 SQL 是计算某个人的成绩总和,stu 是记录所有学生信息的表,grade 是记录所有成绩的表。这里如果我们不做任何优化,这个语句的执行流程是先去做一个Join,然后拿 Join 的结果去做聚合。这里可以做优化是因为 grade 表的 stu_id 显然是 stu 的外键,它可能冗余了很多 stu_id 的信息,所以我们可以优先做一个预聚合。整个过程就相当于是把 sum 下推了。注意我们这里本来是没有 Group By 列的,下推之后一定要将 Join 条件所有和 grade 相关的列作为聚合列,以保证正确性。
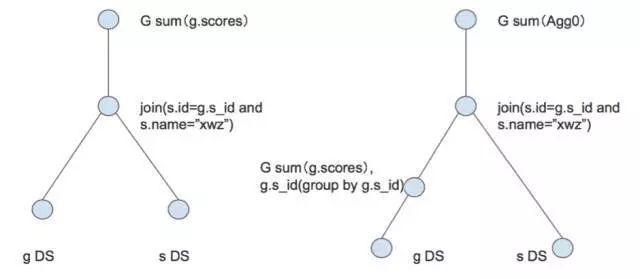
图 8
上面介绍的是逻辑优化,接下来我跟大家介绍一下物理优化.
3.2 物理优化
同一个逻辑算子可以对应不同的物理算子,物理优化是指基于统计信息和动态规划算法计算出不同物理计划的代价,从而选择最优计划的优化。这里主要分享统计信息是怎么构建的。首先我们采用了等深直方图,因为如果使用等宽直方图会有一些数据倾斜的问题造成较大误差。统计信息的收集算法大概是这样,因为直方图本质上是描述频率分布,所以我们要求统计的数据是有序的。对于普通 Column 来说,它在 TiKV 中是无序的,我们不可能对整个表的每个 Column 进行排序,这样开销太大。这里我们采用了一个采样算法,对于一个表随机选取一万到十万行,这样我们就可以用一个很小的代价来构建每个列的直方图。不过这个方法的副作用也很明显,就是不管对于多大的表,我们的采样数据都是很有限的,需要保证数据量足够小到能进行内存排序,这样会对直方图的准确性造成一定影响。而对于索引列来说,它在 TiKV 中的组织本身就是有序的,那么我们设计了一些算法利用这些索引列的有序性质,可以在不采样的前提下,建立准确的直方图。
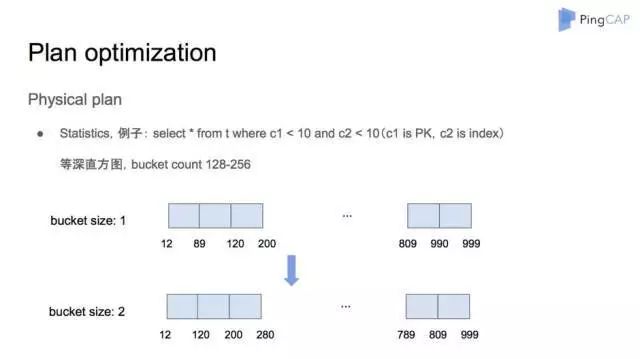
图 9
具体的做法是,我们先将 Bucket 的个数限制在 128 到 255,然后每个 Bucket 统计的行数,称为 Bucket Size, 不超过 1 个。当我们读取数据,第一次 Bucket 数量达到 256 的时候,我们会选择将相邻的 Bucket 两两合并,然后 BucketSize 乘以 2,流程见图 9。在合并结束后,Bucket 的数量又会回到 128 的合法值,BucketSize 变为 2。这样如果有 N 条数据,我们可以用 N*logN 的代价去构建等深直方图。这样既可以避免采样带来的精度损失,又不会为构建直方图带来过多的开销。
构建直方图的一个最重要的用途是选择索引。举个例子,比如说 select * from t where c1<10 and c2<10 就是会看用哪一个索引代价小,假如说 c1<10,输出是 10000 个,而 c2<10 输出是 100 个。使用那个索引直接影响了数据扫描的行数。而利用统计信息就可以很精准的进行估计。
4.MPP 的计算框架
首先对大数据的 SQL 计算,基本上用的是 MPP 式的框架,即是分布式又是并行的计算,大概的架构如图 10 所示。分布式计算的主要优点就是减少计算成本和网络开销。比如计算Count(*),TiDB 会做出对应的物理计划并将它发送到不同的 TiKV 节点上。然后每个 TiKV 节点会计算他自己的 Count(*) 结果,之后汇总给 TiDB 。TiDB 会将每一个聚合结果全部加起来做一个大和,也就是 sum 操作,得到最终的结果。这样的话,TiDB 和 TiKV 之间交换的数据量是很少的。因为 TiKV 不需要返回所有的行,每个节点只要返回一条 count(*) 的计算结果即可。
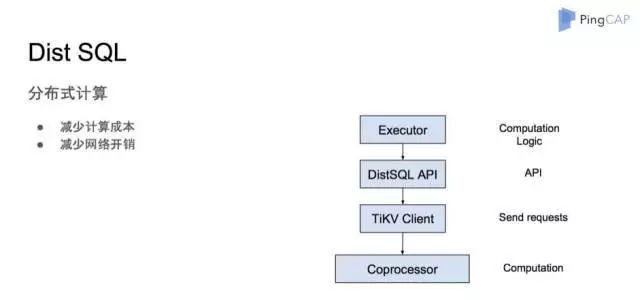
图 10
简单介绍对谓词条件的处理流程。比如图 11 这个语句查询年龄大于 20 小于 30 的所有行,首先 TiDB 会检查 age 是否是索引列。如果是索引列,那么说明在 TiKV 中 age 列是按照顺序排列的。比如 Region 1 存放的是 age 10-20 ,Region 2 存放的是 age 20-30,Region 3 存放的是 age 30-40。那么 TiDB 可以直接向 Region 2 发送计算请求。如果 age 是无序列,那么我们就需要向每个 Region 发送计算请求,最后将计算汇总。相对于上面的算法,这种方式会多很多数据扫描的开销。而谓词下推之后,如果语句类似图 11 的第二个语句,它依然是可以继续将聚合计算 Count(*) 下推的,过程和之前讲的一致。
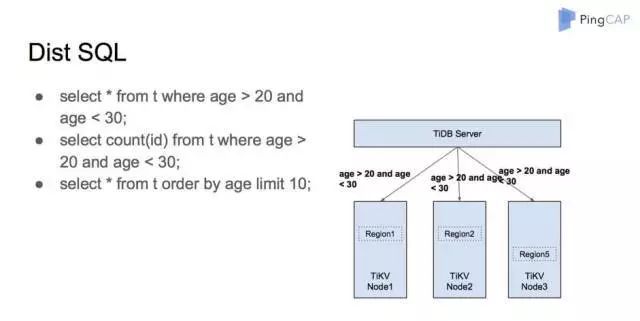
图 11
我们的 TopN 也是可以下推的,拿图 11 的第三个 SQL 举例。如果 age 是无序列,它可以发到每个 Region 计算出每个节点 age 列的前10行,在 TiDB 那边汇总的数据量是 30 行,再拿 30 行的前 10 行反馈给客户端,这样数据量的计算量就很小了。如果 age 是有序的,计算可以更加简单,直接从按照 Region1 -> Region5 的顺序去读取数据,读到满足 10 条时停止即可。
刚刚讲到的是分布式计算,我们还有并行优化。比如说我们的 Hash Join 。根据统计信息,我们会判断 Join 的左右表哪一个是小表,哪一个是大表。然后计算出来把小表放到内存里,并根据等值条件的 Key 建立哈希表,大表通过多 goroutine 分批取值,匹配哈希表。之后也会支持 Sort Merge Join 等其他 Join 算法,整个就是这样一个逻辑。
5.Online DDL 实现与优化
之前讲到的是 TiDB 和 TiKV 的分布式计算优化过程,之后会讲一下我们的 Online DDL 的实现。一般数据库在进行 DDL 操作时都会锁表,导致线上对此表的 DML 操作全部进入等待状态(有些数据支持读操作,但是也以消耗大量内存为代价),即很多涉及此表的业务都处于阻塞状态,表越大,影响时间越久。这使得 DBA 在做此类操作前要做足准备,然后挑个天时地利人和的时间段执行。为此,架构师们在设计整个系统的时候都会很慎重的考虑表结构,希望将来不用再修改。但是未来的业务需求往往是不可预估的,所以 DDL 操作无法完全避免。由此可见原先的机制处理 DDL 操作是令许多人都头疼的事情。接下来会介绍 TiDB 是如何解决此问题的。
TiDB 的解决方案根据 Google F1 的异步 schema 变更算法实现,并做了一些简单优化。此方案分为两个部分,一是租约。schema 信息在每台服务的内存中会存储一份,另外还会持久化到 TiKV。为了保证整个集群中的同一时刻最多只有前后两个 schema 版本,约定了一个租约时间,所有服务器在租约到期后都需加载 schema 信息。如果节点无法重新完成续租,它将会自动终止服务并等待被集群管理设施重启。目前的实现不会终止服务,但是超时的操作会失败,具体实现这里不作展开。另一个是中间状态。假设从无到有的话,当中部分服务在无的状态,部分服务在有的状态,那用户到不同的服务上,能对此数据进行的操作是不同的。那么我们就拆解成多个中间状态,比如有 Delete Only、Write Only。拆分状态时,希望在同一时间里的两种状态不管是哪个状态,对数据的一致性还有完整性都没有影响,这就是论文的主要思想,具体论证可以阅读论文。这里简单举个例子,在某表中新添加一列,一开始是从 None 状态转换到 Delete Only 状态。那么这个集群中的服务在同一时刻,有一些处于 None 状态,另一些处于 Delete Only 状态,处于前者的不能访问到此列,处于后者的只能对此列的数据进行删除,但是此时此列里面还没有数据。那么从用户角度看,将请求发到这个集群中同时存在的这两个状态的不同服务器,可以认为其操作结果相同。之后的状态变更情况类似就不多解释了,有兴趣的人可以去看论文或者我们在 Github 上分享的从零开始写分布式数据库。
5.1 Online DDL 实现

图 12
5.1.1 一般的 DDL 请求
目前的方案是是串行执行,虽然并行处理也可以做,但是相对复杂,且收益没有那么明显,等将来我们再做对应的优化。
Online DDL 的主要执行流程如图 12 。这里详细介绍图中的两个流程:
1.获取执行 DDL 语句的权利。
每台 Server 都有一个 Worker,这个 Worker 用于处理 DDL 语句,但是 Worker 只有成为了 Owner 角色才能真正的执行这个 DDL,这样才能保证串行化执行。如图 12 可以看到 Owner 信息存在 TiKV,它有两个字段,唯一的标识和最近更新此信息的时间戳(LastUpdateTS)。那么 Server 具体的竞选是分两种情况:
a.Owner 的 id 与此 Server id 一致,那么用当前时间更新 Owner 的 LastUpdateTS。
b.Owner 的 id 与此 Server id 不一致,且当前的时间与 Owner 的 LastUpdateTS 的差大于 4 * lease,认为原来获取到 Owner 角色的 Server 出让了此角色,此 Server 可竞选 Owner。
针对多个 Server 竞选 Owner 时,通过下层的分布式事务确保只有一台 Server 能竞选成功。
2. 更新最新的 schema 信息。
每个 Server 定期(0.5*lease)加载 schema。在 Server 上的每个事务在提交时会检查 schema version 是否超时,如果超时此事务不会提交。
5.1.2 特殊的 DDL 请求
包括 Drop Table、Drop Database 和 Truncate Table,这些操作是将 job 放于后台异步处理的。假如说有个 drop table 的请求,且 table 中有上亿行的数据,那么这个操作需要处理很久,而且这个操作以后,此 table 里面的数据其实都不再使用。所以我们对这类 DDL 操作做了特殊处理,将此操作换成两部分:
1.跟原先逻辑一样,进行状态转换。到清理数据那步,只清理元数据(没有元数据,访问不到此 table,且 table id 保证全局唯一,所以不会有数据不一致问题),并将此元信息存储到 background job 中,最后返回版本变更完成。
2.后台的 Worker 从 background queue 中拿到 job 后会真正地进行数据删除。
5.2 Online DDL 优化

图 13
因为 DDL 一般操作都是串行化的,有一些操作涉及的数据量比较大。不管是上千万条还是上亿条,做一个操作就要等几个小时,或者以天计算。虽然是 Online DDL,但是有一些对数据一致性要求很高的客户,在一开始接入 TiDB 时,为了能保证安全性,可能还是会选择等,所以我们做了一些优化。
5.2.1 Add index 优化
原先 add index 最后填充数据就是通过批量处理。这样做是为了防止此操作的事务与其他在操作此 index 的事务发生冲突,导致整个 add index backfill 的操作重试从而进行分批处理。但是这个批量不是并发处理,只是为了减少冲突域做的。优化前串行逻辑是先扫一批 key,扫完之后对这批 key 的值进行修改。优化分两部分,一是减少对 TiKV 的访问,二是对一些操作进行并发处理。接下来主要介绍下第二部分的优化,此处的并发处理比一般的略微复杂,即真正的并发是在扫完一批 key 后对其进行的解析及真正修改 key 的值的处理。虽然每个 key 区间的长度可控, 但是这个区间的具体值由于一些删除操作不可预计, 所以需要串行地获取一批 key。这个优化用 go 处理还是特别方便易懂。通过一个小集群进行一定数量的对比测试后,请求执行时间大约是优化前的 ⅓ (具体需考虑表中数据行数,这些测试中表行数最少也是上万行)。其中并发个数是通过优化效果和冲突域两个参考值权衡下调整的。
5.2.2 Add Column 优化
这个优化效果会更加显著,因为事实上我们最后没有存那个数据。那么整个操作就不关心表的数据行数,整个操作只需要进行 5 个状态的变更即可。从图 13 上看出来,此操作前后做了两个优化:
1.新加列的 Default Value 是一个空值,那么就不需要实际的去填充。之后对此列的读取时,从 TiKV 返回的列值为空时,查看此列的元信息,如果它是 NULL 约束则可直接返回空值。
2.新加列的 Default Value 的值非空的情况下,也不用将 Default Value 存储到 TiKV,这优化是最近做的。只用将此默认值存到一个字段(Original Default Value)中,在之后做读取操作时,如果发现 TiKV 返回一个空值,且这个字段中的值非空,那么将此字段中的值填充给它,然后返回。
除了这两个优化外,我们还针对性地做了一些其他优化,这边就不多介绍了。
我们目前比较常用的 DDL 语句基本上都支持了,具体与 MySQL 的兼容情况可以看我们在 github 上的文档。至于那些还不支持的,我们会根据用户实际需求进行处理。因为目前开发人员比较有限,所以很欢迎大家给我们提一些 PR,非常感谢。
6.TiKV 简介

图 14
如图 14,TiKV 对于 TiDB 是做了很多非常重要的支持。开始分享时介绍的分布式数据解决方案中,很多不支持的特性,TiDB 已经支持。图中所示的特性基本上是通过 TiKV 层实现。比如我们分布式事务是通过 2PC 实现,MVCC 的具体原理在之前的一次分享中已经介绍过了,这里我就不赘述了。底层引擎用了 RocksDB,集群自动伸缩是通过 PD 和 Raft 协议实现,其中的 PD 用于 TiKV 的集群管理。
感想
简单介绍一下平常程序员不太看重,但我们团队还是很重视的几个方面。首先是代码风格方面。贵司有很多社区经验很丰富的且代码能力很强的同事,他们就对代码简明性要求很高。这不只是我原来认为的代码的简洁,还包括代码命名的规范和风格统一。在同事的代码风格出现分歧的时候, 一般借鉴 go 源码或者一些 GitHub 上面知名项目的代码风格作为参照。其中代码命名方面在我几个处女座同事的挑(指)剔(点)下进步很大。
接着就是注释,大家都说代码简洁了就不需要注释了,但是对一些特殊的复杂功能,注释还是必须的。这不仅有助于其他人理解你的代码,而且也让自己之后阅读此代码时能更快速理解。如果 review 这段代码的同事(对这功能有一定了解)有疑问,说明你的代码已经略微复杂,那么能简化就简化代码,不能则加注释。特别是做开源社区,这方面要求就更高了。
然后就是测试,特别是数据库这种对准确性的要求非常高的服务,测试是很重要的。我们目前就已经通过了 800 多万测试,其中包括一些 MySQL Drivers 的测试,一些常用的 ORM 和一些常用服务的测试。目前还在引入一些其他的测试类型和测试场景的支持。此外就是提高单元测试的覆盖率,我们的要求是单元测试覆盖率达到 85% 以上。
以上是我今天的分享,谢谢大家!
作者简介:李霞
PingCAP 开发工程师,TiDB committer , Go 语言狂热粉,主要研究方向为分布式系统,坚信分布式系统才是未来。2012 年底到 2015 年中在京东工作,期间参与建设京东分布式消息推送系统、分布式块存储系统、京东云存储系统。后来通过阅读 Google Spanner 和 Google F1 的论文开始进入分布式数据库领域,2015 年至今一直在 PingCAP 工作从事大规模分布式数据库 TiDB 的开发,主要参与模块为 TiDB 的 online DDL , SQL 优化器,以及功能改进和性能提升。对分布式消息系统、分布式存储和分布式数据库有些心得,对 Go 内存调度、GC 和调优有丰富的实战经验。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

