


 微信ID:pingcap2015
微信ID:pingcap2015 长按左侧二维码关注
长按左侧二维码关注

黄东旭解析 TiDB 的核心优势
677
2016-11-23
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247484229&idx=2&sn=379095c3f59c9a4c285a59e02ff7ea12&chksm=eb16242fdc61ad391839cb6643e1034106961c1bed7d47ffd241142a6b00edf1ce3cc02e4207#rd
在 第 28 期 pingcap NewSQL Meetup 中,TalkingData 数据经理时延军分享了《Spark 架构设计要点剖析》。为了让大家更好地理解分享内容,日前,我们的讲师亲自操刀,整理了一篇博文,共享给大家 enjoy :-D
Apache Spark 是一个开源的通用集群计算系统,它提供了 High-level 编程 API,支持 Scala、Java 和 Python 三种编程语言。Spark 内核使用 Scala 语言编写,通过基于 Scala 的函数式编程特性,在不同的计算层面进行抽象,代码设计非常优秀。
RDD抽象
RDD(Resilient Distributed Datasets),弹性分布式数据集,它是对分布式数据集的一种内存抽象,通过受限的共享内存方式来提供容错性,同时这种内存模型使得计算比传统的数据流模型要高效。RDD 具有 5 个重要的特性,如下图所示:
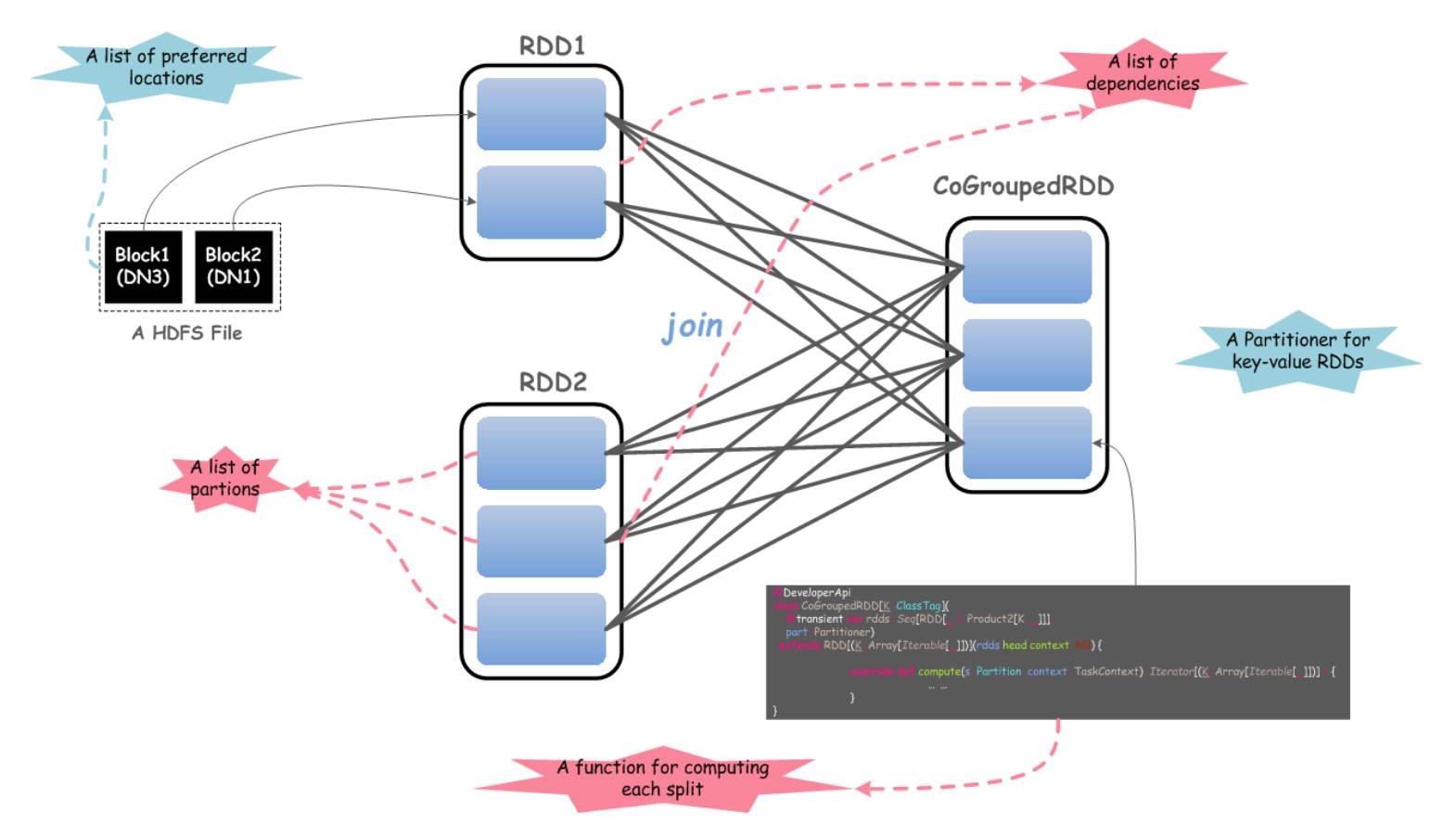
上图展示了 2 个 RDD 进行 JOIN 操作,体现了 RDD 所具备的 5 个主要特性,如下所示:
一组分区
计算每一个数据分片的函数
RDD 上的一组依赖
可选,对于键值对 RDD,有一个 Partitioner(通常是 HashPartitioner)
可选,一组 Preferred location 信息(例如,HDFS 文件的 Block 所在 location 信息)
有了上述特性,能够非常好地通过 RDD 来表达分布式数据集,并作为构建 DAG 图的基础:首先抽象一次分布式计算任务的逻辑表示,最终将任务在实际的物理计算环境中进行处理执行。
计算抽象
在描述 Spark 中的计算抽象,我们首先需要了解如下几个概念:
Application
用户编写的 Spark 程序,完成一个计算任务的处理。它是由一个 Driver 程序和一组运行于 Spark 集群上的 Executor 组成。
Job
用户程序中,每次调用 Action 时,逻辑上会生成一个 Job,一个 Job 包含了多个 Stage。
Stage
Stage 包括两类:ShuffleMapStage 和 ResultStage,如果用户程序中调用了需要进行 Shuffle 计算的 Operator,如 groupByKey 等,就会以 Shuffle 为边界分成 ShuffleMapStage 和 ResultStage。
TaskSet
基于 Stage 可以直接映射为 TaskSet,一个 TaskSet 封装了一次需要运算的、具有相同处理逻辑的 Task,这些 Task 可以并行计算,粗粒度的调度是以 TaskSet 为单位的。
Task
Task 是在物理节点上运行的基本单位,Task 包含两类:ShuffleMapTask 和 ResultTask,分别对应于 Stage 中 ShuffleMapStage 和 ResultStage 中的一个执行基本单元。
下面,我们看一下,上面这些基本概念之间的关系,如下图所示:
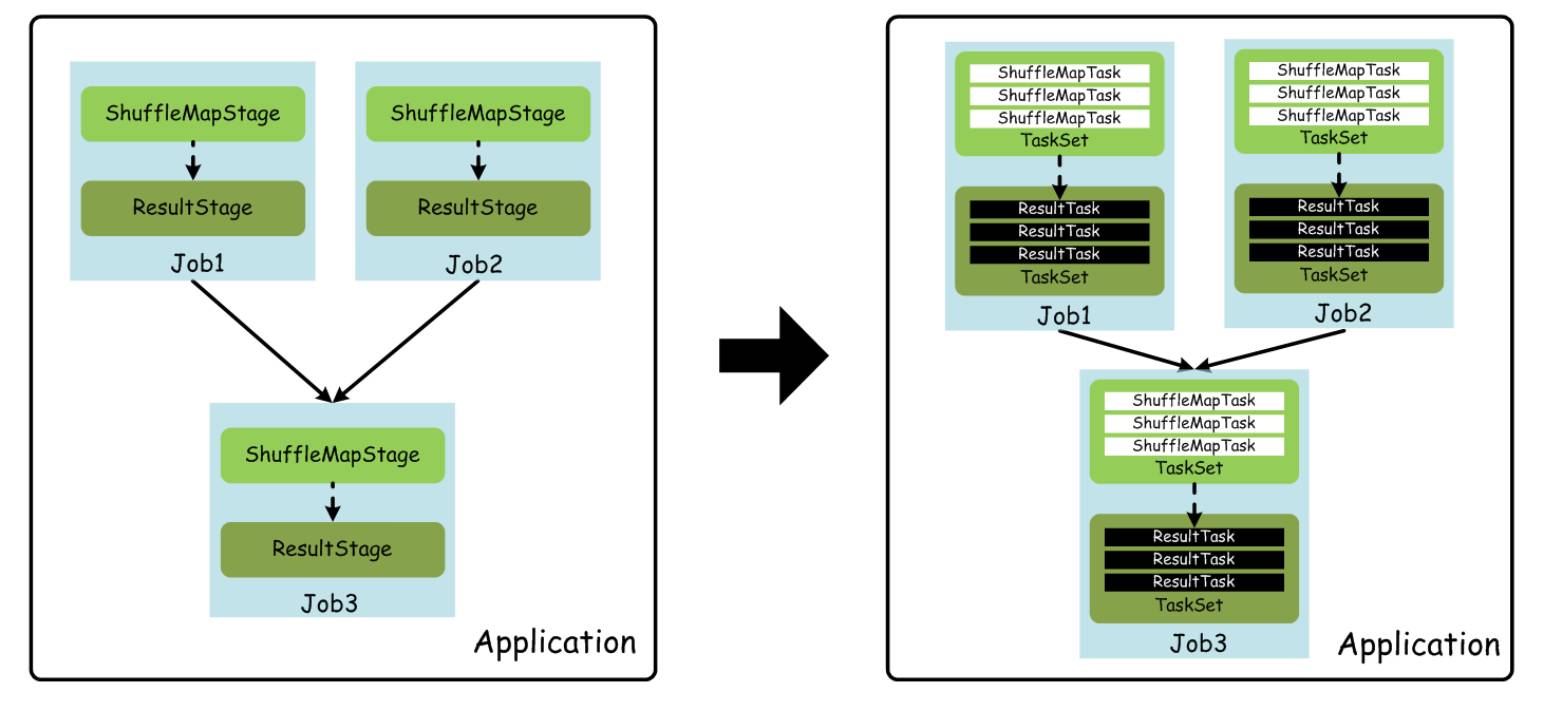
上图,为了简单,每个 Job 假设都很简单,并且只需要进行一次 Shuffle 处理,所以都对应 2 个 Stage。实际应用中,一个 Job 可能包含若干个 Stage,或者是一个相对复杂的 Stage DAG。
在 Standalone 模式下,默认使用的是 FIFO 这种简单的调度策略,在进行调度的过程中,大概流程如下图所示:
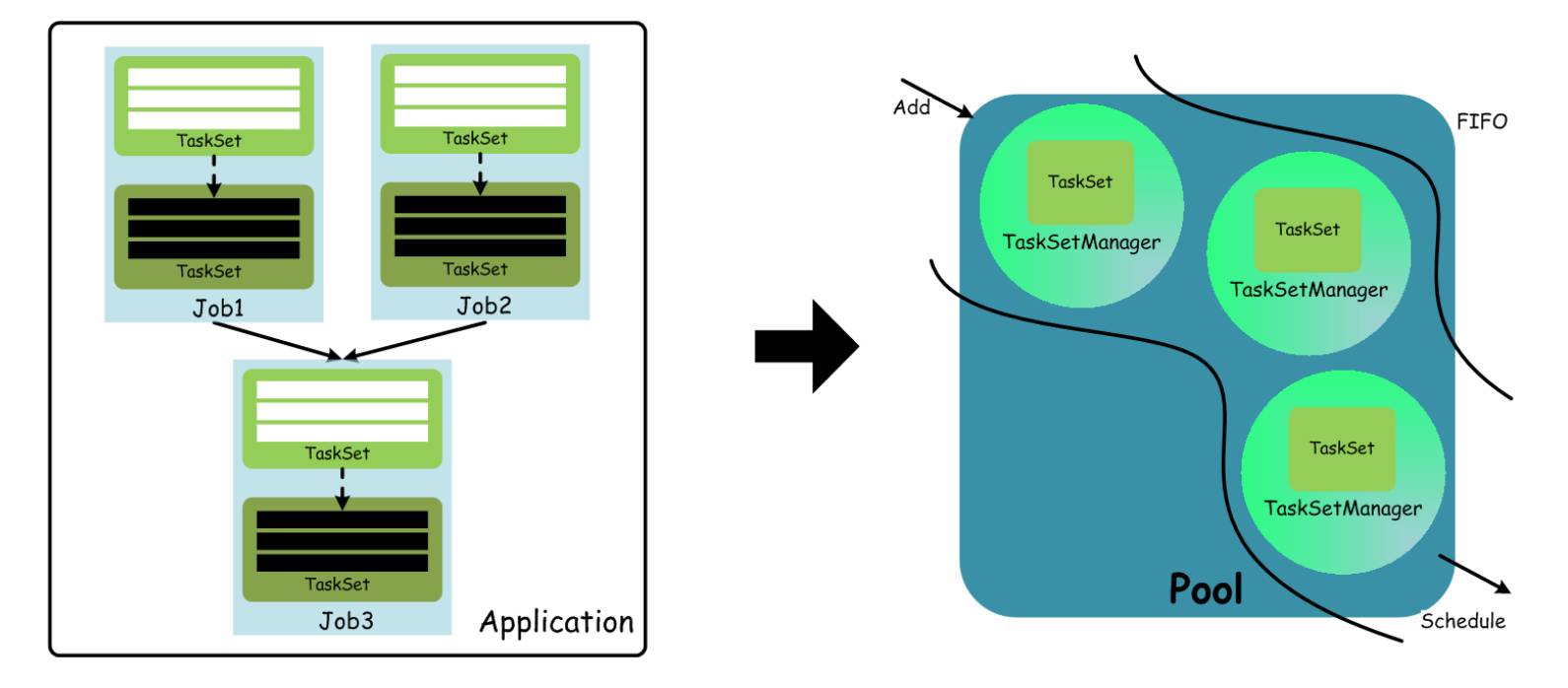
从用户提交 Spark 程序,最终生成 TaskSet,而在调度时,通过 TaskSetManager 来管理一个 TaskSet(包含一组可在物理节点上执行的 Task),这里面 TaskSet 必须要按照顺序执行才能保证计算结果的正确性,因为 TaskSet 之间是有序依赖的(上溯到 ShuffleMapStage 和 ResultStage),只有一个 TaskSet 中的所有 Task 都运行完成后,才能调度下一个 TaskSet 中的 Task 去执行。
集群模式
Spark 集群在设计的时候,并没有在资源管理的设计上对外封闭,而是充分考虑了未来对接一些更强大的资源管理系统,如 YARN、Mesos 等,所以 Spark 架构设计将资源管理单独抽象出一层,通过这种抽象能够构建一种适合企业当前技术栈的插件式资源管理模块,从而为不同的计算场景提供不同的资源分配与调度策略。Spark 集群模式架构,如下图所示:
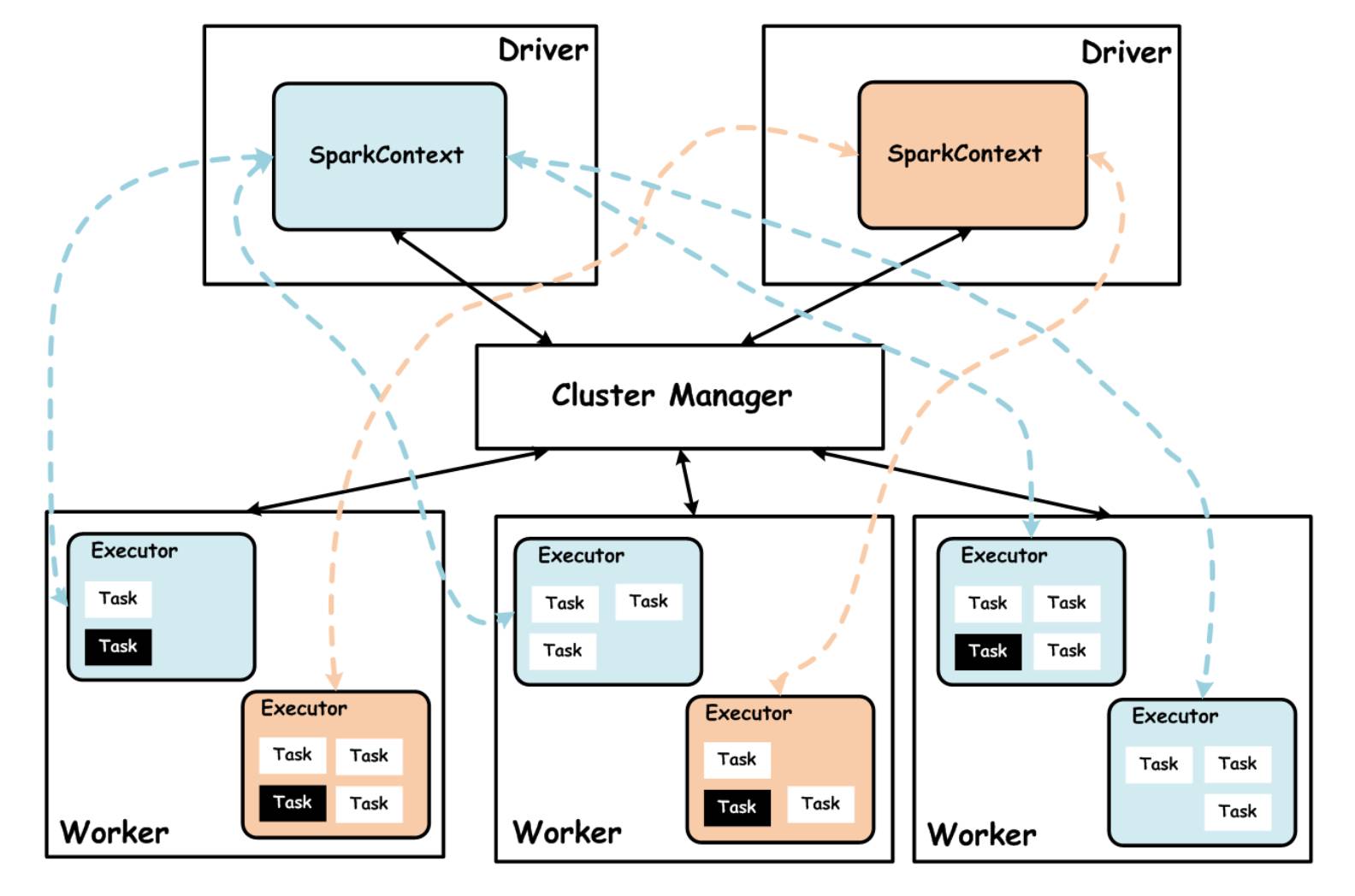
上图中,Spark 集群 Cluster Manager 目前支持如下三种模式:
Standalone 模式
Standalone 模式是 Spark 内部默认实现的一种集群管理模式,这种模式是通过集群中的 Master 来统一管理资源,而与 Master 进行资源请求协商的是 Driver 内部的 StandaloneSchedulerBackend(实际上是其内部的 StandaloneAppClient 真正与 Master 通信),后面会详细说明。
YARN 模式
YARN 模式下,可以将资源的管理统一交给 YARN 集群的 ResourceManager 去管理,选择这种模式,可以更大限度的适应企业内部已有的技术栈,如果企业内部已经在使用 Hadoop 技术构建大数据处理平台。
Mesos 模式
随着 Apache Mesos 的不断成熟,一些企业已经在尝试使用 Mesos 构建数据中心的操作系统(DCOS),Spark 构建在 Mesos 之上,能够支持细粒度、粗粒度的资源调度策略(Mesos 的优势),也可以更好地适应企业内部已有技术栈。
那么,Spark 中是怎么考虑满足这一重要的设计决策的呢?也就是说,如何能够保证 Spark 非常容易的让第三方资源管理系统轻松地接入进来。我们深入到类设计的层面看一下,如下图类图所示:
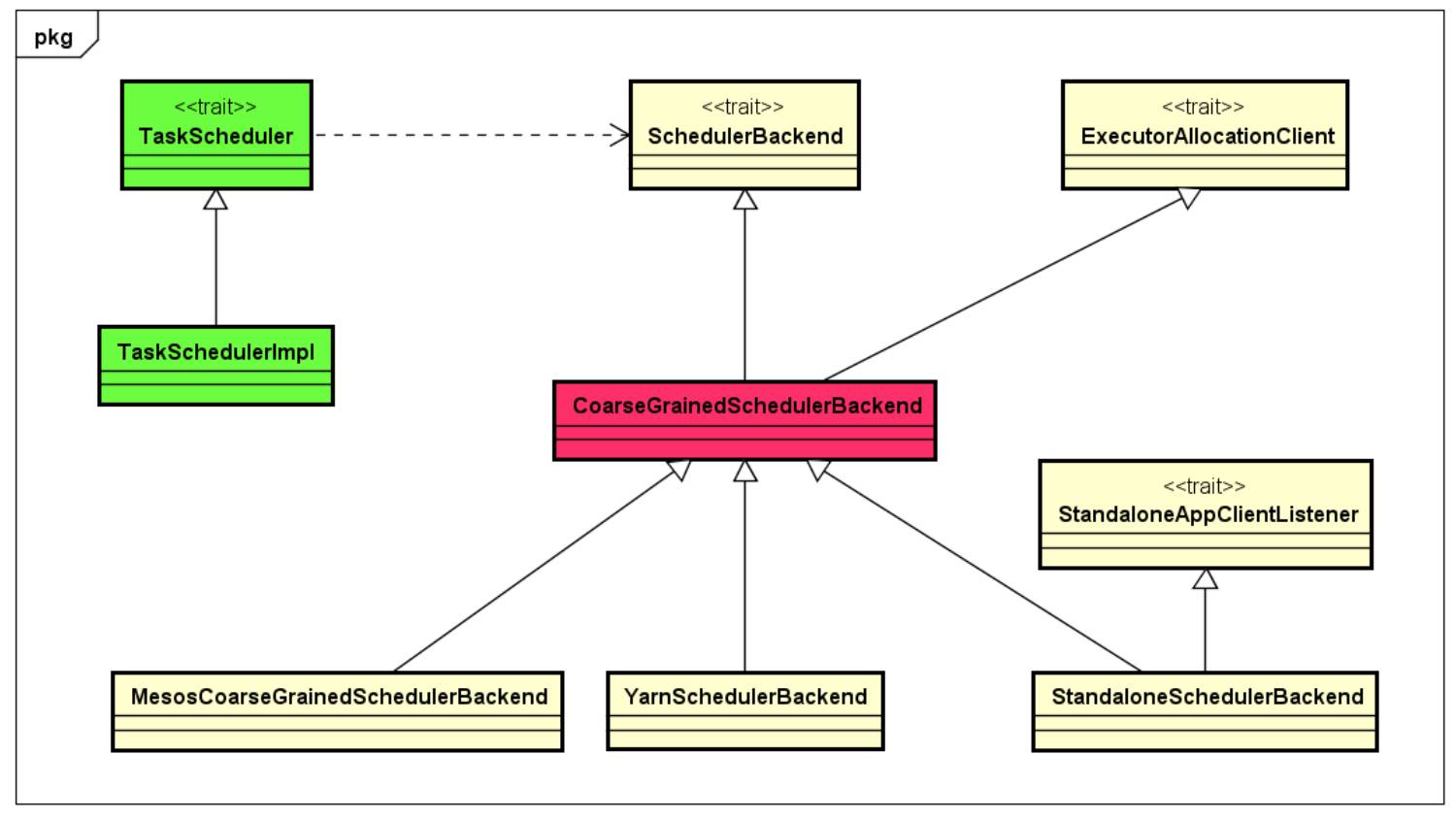
可以看出,Task 调度直接依赖 SchedulerBackend,SchedulerBackend 与实际资源管理模块交互实现资源请求。这里面,CoarseGrainedSchedulerBackend 是 Spark 中与资源调度相关的最重要的抽象,它需要抽象出与 TaskScheduler 通信的逻辑,同时还要能够与各种不同的第三方资源管理系统无缝地交互。实际上,CoarseGrainedSchedulerBackend 内部采用了一种 ResourceOffer 的方式来处理资源请求。
RPC网络通信抽象
Spark RPC 层是基于优秀的网络通信框架 Netty 设计开发的,但是 Spark 提供了一种很好地抽象方式,将底层的通信细节屏蔽起来,而且也能够基于此来设计满足扩展性,比如,如果有其他不基于 Netty 的网络通信框架的新的 RPC 接入需求,可以很好地扩展而不影响上层的设计。RPC 层设计,如下图类图所示:
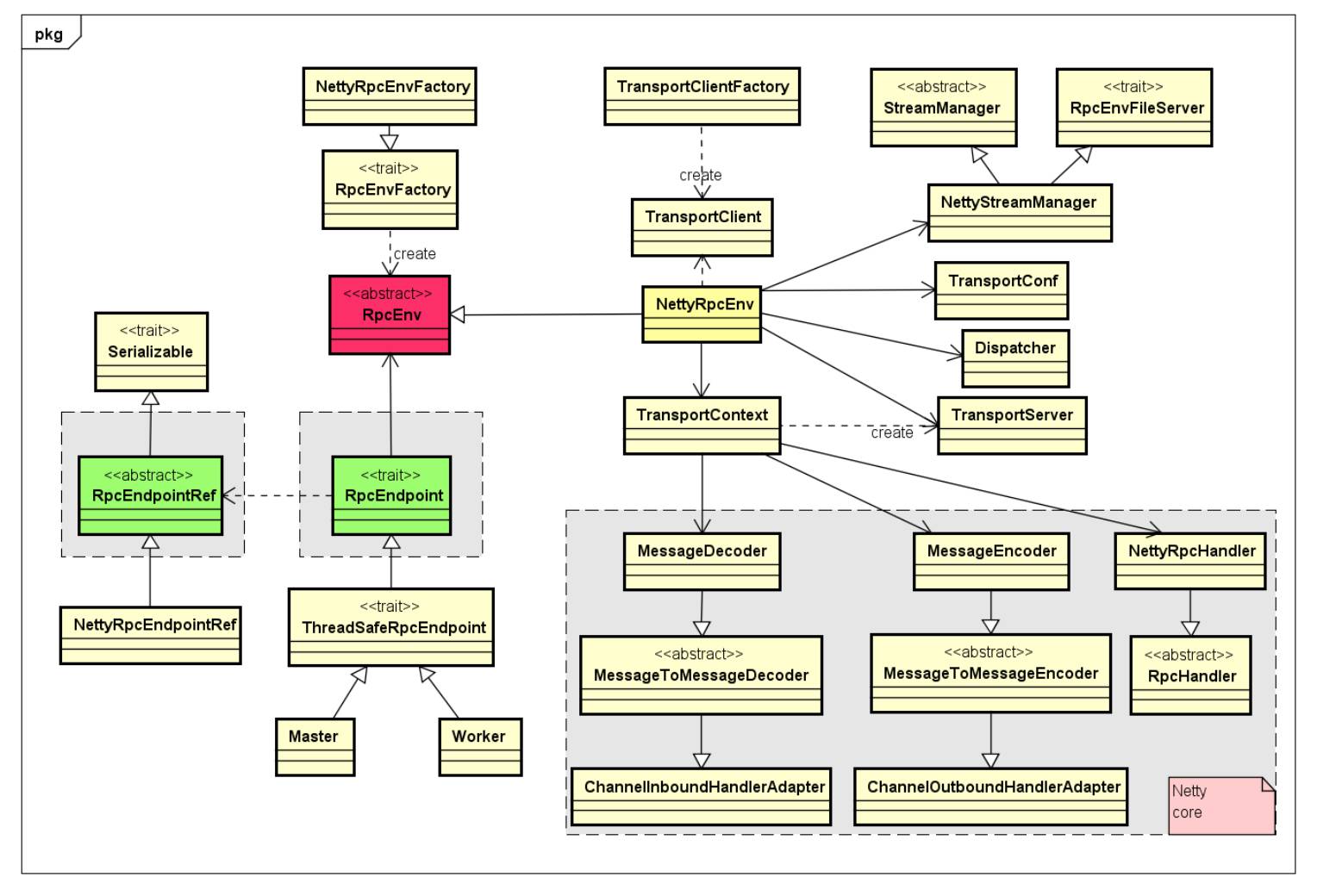
任何两个 Endpoint 只能通过消息进行通信,可以实现一个 RpcEndpoint 和一个 RpcEndpointRef:想要与 RpcEndpoint 通信,需要获取到该 RpcEndpoint 对应的 RpcEndpointRef 即可,而且管理 RpcEndpoint 和 RpcEndpointRef 创建及其通信的逻辑,统一在 RpcEnv 对象中管理。
启动 Standalone 集群
Standalone 模式下,Spark 集群采用了简单的 Master-Slave 架构模式,Master 统一管理所有的 Worker,这种模式很常见,我们简单地看下 Spark Standalone 集群启动的基本流程,如下图所示:
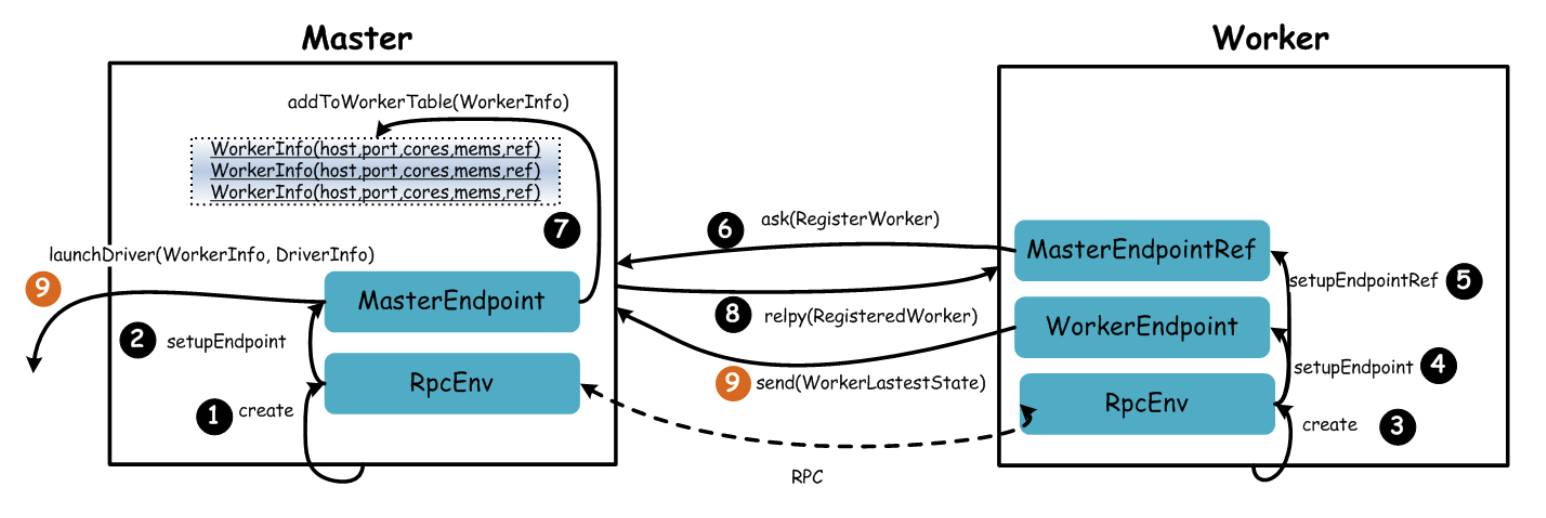
可以看到,Spark 集群采用的消息的模式进行通信,也就是 EDA 架构模式,借助于 RPC 层的优雅设计,任何两个 Endpoint 想要通信,发送消息并携带数据即可。上图的流程描述如下所示:
Master 启动时首先创一个 RpcEnv 对象,负责管理所有通信逻辑
Master 通过 RpcEnv 对象创建一个 Endpoint,Master 就是一个 Endpoint,Worker 可以与其进行通信
Worker 启动时也是创一个 RpcEnv 对象
Worker 通过 RpcEnv 对象创建一个 Endpoint
Worker 通过 RpcEnv 对,建立到 Master 的连接,获取到一个 RpcEndpointRef 对象,通过该对象可以与 Master 通信
Worker 向 Master 注册,注册内容包括主机名、端口、CPU Core 数量、内存数量
Master 接收到 Worker 的注册,将注册信息维护在内存中的 Table 中,其中还包含了一个到 Worker 的 RpcEndpointRef 对象引用
Master 回复 Worker 已经接收到注册,告知 Worker 已经注册成功
此时如果有用户提交 Spark 程序,Master 需要协调启动 Driver;而 Worker 端收到成功注册响应后,开始周期性向 Master 发送心跳
核心组件
集群处理计算任务的运行时(用户提交了 Spark 程序),最核心的顶层组件就是 Driver 和 Executor,它们内部管理很多重要的组件来协同完成计算任务,核心组件栈如下图所示:
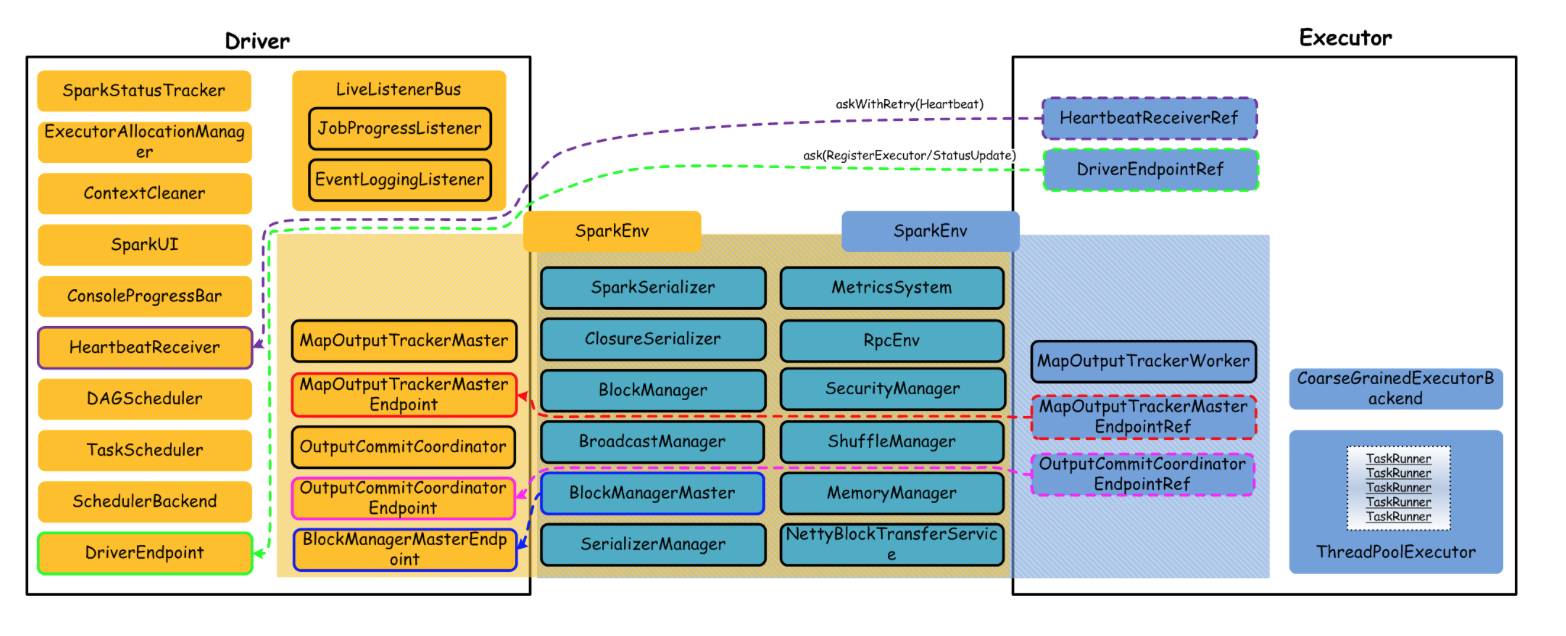
Driver 和 Executor 都是运行时创建的组件,一旦用户程序运行结束,他们都会释放资源,等待下一个用户程序提交到集群而进行后续调度。上图,我们列出了大多数组件,其中 SparkEnv 是一个重量级组件,他们内部包含计算过程中需要的主要组件,而且,Driver 和 Executor 共同需要的组件在 SparkEnv 中也包含了很多。这里,我们不做过多详述,后面交互流程等处会说明大部分组件负责的功能。
核心组件交互流程
在 Standalone 模式下,Spark 中各个组件之间交互还是比较复杂的,但是对于一个通用的分布式计算系统来说,这些都是非常重要而且比较基础的交互。首先,为了理解组件之间的主要交互流程,我们给出一些基本要点:
一个 Application 会启动一个 Driver
一个 Driver 负责跟踪管理该 Application 运行过程中所有的资源状态和任务状态
一个 Driver 会管理一组 Executor
一个 Executor 只执行属于一个 Driver 的 Task
核心组件之间的主要交互流程,如下图所示:
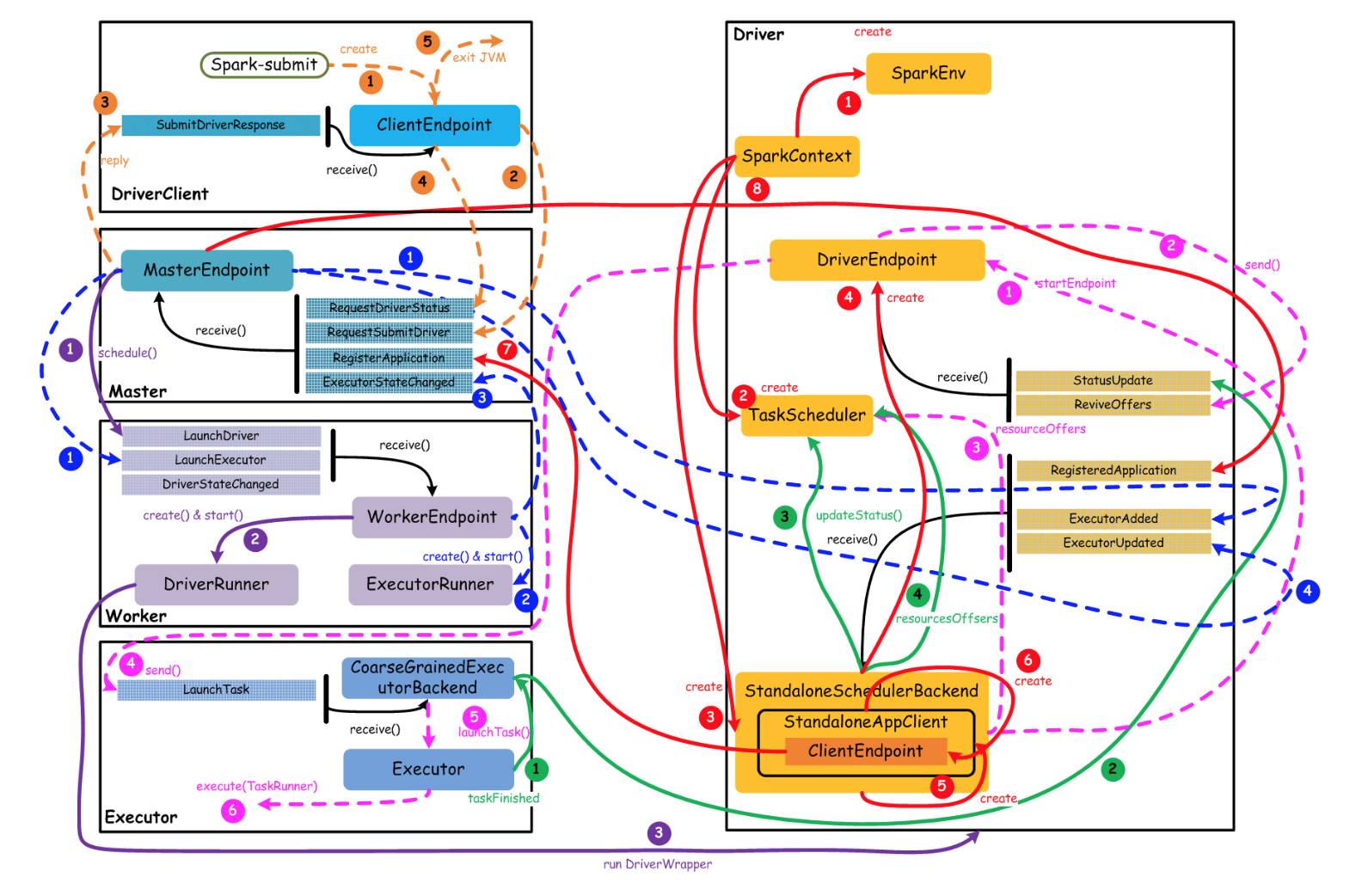
上图中,通过不同颜色或类型的线条,给出了如下 6 个核心的交互流程,我们会详细说明:
橙色:提交用户 Spark 程序
用户提交一个 Spark 程序,主要的流程如下所示:
用户 spark-submit 脚本提交一个 Spark 程序,会创建一个 ClientEndpoint 对象,该对象负责与 Master 通信交互
ClientEndpoint 向 Master 发送一个 RequestSubmitDriver 消息,表示提交用户程序
Master 收到 RequestSubmitDriver 消息,向 ClientEndpoint 回复 SubmitDriverResponse,表示用户程序已经完成注册
ClientEndpoint 向 Master 发送 RequestDriverStatus 消息,请求 Driver 状态
如果当前用户程序对应的 Driver 已经启动,则 ClientEndpoint 直接退出,完成提交用户程序
紫色:启动 Driver 进程
当用户提交用户 Spark 程序后,需要启动 Driver 来处理用户程序的计算逻辑,完成计算任务,这时 Master 协调需要启动一个 Driver,具体流程如下所示:
Maser 内存中维护着用户提交计算的任务 Application,每次内存结构变更都会触发调度,向 Worker 发送 LaunchDriver 请求
Worker 收到 LaunchDriver 消息,会启动一个 DriverRunner 线程去执行 LaunchDriver 的任务
DriverRunner 线程在 Worker 上启动一个新的 JVM 实例,该 JVM 实例内运行一个 Driver进程,该 Driver 会创建 SparkContext 对象
红色:注册 Application
Dirver 启动以后,它会创建 SparkContext 对象,初始化计算过程中必需的基本组件,并向 Master 注册 Application,流程描述如下:
创建 SparkEnv 对象,创建并管理一些数基本组件
创建 TaskScheduler,负责 Task 调度
创建 StandaloneSchedulerBackend,负责与 ClusterManager 进行资源协商
创建 DriverEndpoint,其它组件可以与 Driver 进行通信
在 StandaloneSchedulerBackend 内部创建一个 StandaloneAppClient,负责处理与 Master 的通信交互
StandaloneAppClient 创建一个 ClientEndpoint,实际负责与 Master 通信
ClientEndpoint 向 Master 发送 RegisterApplication 消息,注册 Application
Master 收到 RegisterApplication 请求后,回复 ClientEndpoint 一个 RegisteredApplication 消息,表示已经注册成功
蓝色:启动 Executor 进程
Master 向 Worker 发送 LaunchExecutor 消息,请求启动 Executor;同时 Master 会向 Driver 发送 ExecutorAdded 消息,表示 Master 已经新增了一个 Executor(此时还未启动)
Worker 收到 LaunchExecutor 消息,会启动一个 ExecutorRunner 线程去执行 LaunchExecutor 的任务
Worker 向 Master 发送 ExecutorStageChanged 消息,通知 Executor 状态已发生变化
Master 向 Driver 发送 ExecutorUpdated 消息,此时 Executor 已经启动
粉色:启动 Task 执行
StandaloneSchedulerBackend 启动一个 DriverEndpoint
DriverEndpoint 启动后,会周期性地检查 Driver 维护的 Executor 的状态,如果有空闲的 Executor 便会调度任务执行
DriverEndpoint 向 TaskScheduler 发送 Resource Offer 请求
如果有可用资源启动 Task,则 DriverEndpoint 向 Executor 发送 LaunchTask 请求
Executor 进程内部的 CoarseGrainedExecutorBackend 调用内部的 Executor 线程的 launchTask 方法启动 Task
Executor 线程内部维护一个线程池,创建一个 TaskRunner 线程并提交到线程池执行
绿色:Task 运行完成
Executor 进程内部的 Executor 线程通知 CoarseGrainedExecutorBackend,Task 运行完成
CoarseGrainedExecutorBackend 向 DriverEndpoint 发送 StatusUpdated 消息,通知 Driver 运行的 Task 状态发生变更
StandaloneSchedulerBackend 调用 TaskScheduler 的 updateStatus 方法更新 Task 状态
StandaloneSchedulerBackend 继续调用 TaskScheduler 的 resourceOffers 方法,调度其他任务运行
Block管理
Block 管理,主要是为 Spark 提供的 Broadcast 机制提供服务支撑的。Spark 中内置采用 TorrentBroadcast 实现,该 Broadcast 变量对应的数据(Task 数据)或数据集(如 RDD),默认会被切分成若干 4M 大小的 Block,Task 运行过程中读取到该 Broadcast 变量,会以 4M 为单位的 Block 为拉取数据的最小单位,最后将所有的 Block 合并成 Broadcast 变量对应的完整数据或数据集。将数据切分成 4M 大小的 Block,Task 从多个 Executor 拉取 Block,可以非常好地均衡网络传输负载,提高整个计算集群的稳定性。
通常,用户程序在编写过程中,会对某个变量进行 Broadcast,该变量称为 Broadcast 变量。在实际物理节点的 Executor 上执行 Task 时,需要读取 Broadcast 变量对应的数据集,那么此时会根据需要拉取 DAG 执行流上游已经生成的数据集。采用 Broadcast 机制,可以有效地降低数据在计算集群环境中传输的开销。具体地,如果一个用户对应的程序中的 Broadcast 变量,对应着一个数据集,它在计算过程中需要拉取对应的数据,如果在同一个物理节点上运行着多个 Task,多个 Task 都需要该数据,有了 Broadcast 机制,只需要拉取一份存储在本地物理机磁盘即可,供多个 Task 计算共享。
另外,用户程序在进行调度过程中,会根据调度策略将 Task 计算逻辑数据(代码)移动到对应的 Worker 节点上,最优情况是对本地数据进行处理,那么代码(序列化格式)也需要在网络上传输,也是通过 Broadcast 机制进行传输,不过这种方式是首先将代码序列化到 Driver 所在 Worker 节点,后续如果 Task 在其他 Worker 中执行,需要读取对应代码的 Broadcast 变量,首先就是从 Driver 上拉取代码数据,接着其他晚一些被调度的 Task 可能直接从其他 Worker 上的 Executor 中拉取代码数据。
我们通过以 Broadcast 变量 taskBinary 为例,说明 Block 是如何管理的,如下图所示:
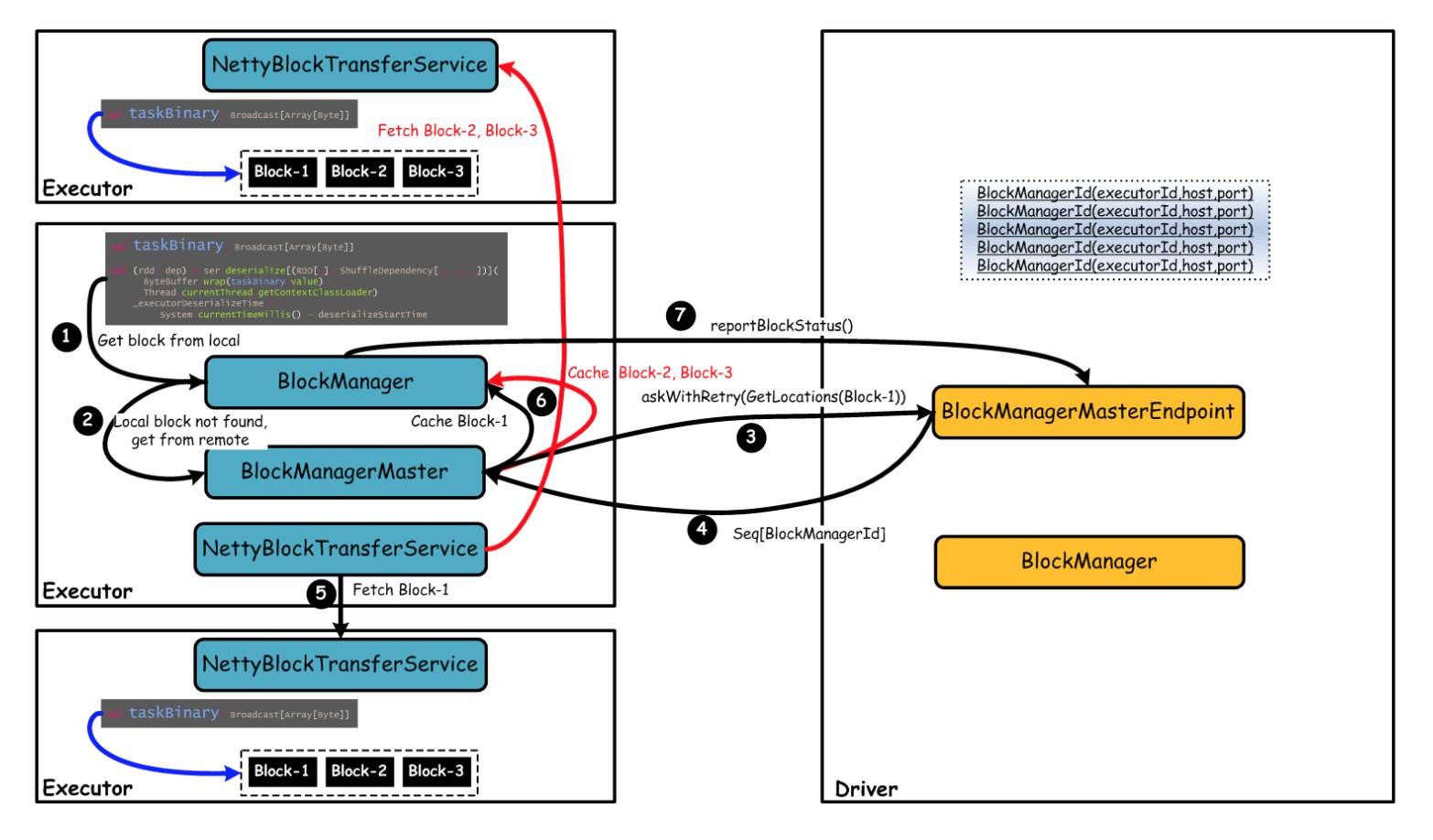
上图中,Driver负 责管理所有的 Broadcast 变量对应的数据所在的 Executor,即一个 Executor 维护一个 Block 列表。在 Executor 中运行一个 Task 时,执行到对应的 Broadcast 变量 taskBinary,如果本地没有对应的数据,则会向 Driver 请求获取 Broadcast 变量对应的数据,包括一个或多个 Block 所在的 Executor 列表,然后该 Executor 根据 Driver 返回的 Executor 列表,直接通过底层的 BlockTransferService 组件向对应 Executor 请求拉取 Block。Executor 拉取到的 Block 会缓存到本地,同时向 Driver 报告该 Executor 上存在的 Block 信息,以供其他 Executor 执行 Task 时获取 Broadcast 变量对应的数据。
参考内容
Spark-2.0.0 源码
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

