

 微信ID:pingcap
微信ID:pingcap 长按左侧二维码关注
长按左侧二维码关注

黄东旭解析 TiDB 的核心优势
615
2016-09-24
内容来源:http://mp.weixin.qq.com/s?__biz=MzI3NDIxNTQyOQ==&mid=2247484031&idx=2&sn=cdaa13566f10be52e90581e7a33354eb&chksm=eb162515dc61ac0384fa1f8295420ad4f7606406f89abccbafeb68ea178d7659913a0b9b932a#rd
近年来,随着移动互联网、物联网、人工智能等技术的兴起,我们已经进入了一个信息爆炸的大数据时代,需要处理和分析的数据越来越多,与此同时,PC Server 的造价不断降低,促使 Hadoop、Spark 等分布式分析计算框架得到广泛的使用,可以肯定的是,在未来,分布式一定是主流的数据处理技术。TiDB 是 PingCAP 团队开发的一款开源的 NewSQL 数据库,整个设计参考 Google Spanner 和 F1,目标是构建一个面向高并发、高吞吐的在线海量数据存储的关系型数据库,提供透明的跨行事务及兼容 MySQL 的 SQL 语法支持,支持无缝的水平伸缩以及跨数据中心多活等特性。目前项目社区相当活跃(5000+ Stars),已经成为在国际上有影响力的顶级开源项目。
为什么要做这么一个数据库?现在的方案有什么问题吗?其实一直以来,在关系型数据库这一层几乎没有一种优雅的分布式方案。但是作为存储架构的核心,关系型数据库的水平扩展是不可避免的,目前大多数方案基本都需要对业务层有很强的侵入性,比如采用 NoSQL 替换原有关系型数据库,但是这样就需要涉及大规模的业务重构,相当于将数据库层的复杂度转嫁给业务层;另外一种方案是通过中间件,或者分库分表,但是这种方案仍然很难做到透明和数据的均匀分布,也无法支持一致性的跨节点事务和 JOIN 操作,而且随着集群规模的增大,维护和扩展的复杂度呈指数级上升。另外经常被人忽略的是,两种方案都没有很好的解决高可用的问题,跨机房多活、故障恢复、扩容经常都需要繁重的人工介入。直到 Google 发布 Spanner 和 F1 ,这才出现了一个真正在 Google 这样的业务规模上验证过的分布式关系型数据库。作为 Google Spanner 和 F1 的开源实现,TiDB 和 TiKV 完美地解决了现有的这些问题。下面简单介绍一下我们是如何解决这些问题的。
TiDB 包含三个子项目:一个是 TiDB,一个是 TiKV,还有 PD (placement driver)。TiDB 是一个无状态的 SQL 层,客户端可以任意连接到一个 TiDB Server 实例上,看到的存储层是完全一致的。TiDB 负责解析用户的 SQL 请求,生成查询计划,交给底层的 TiKV 去执行,TiDB 和 TiKV 通过 Protobuf RPC 进行通信;而 TiKV 负责实际的数据存储,支持全局分布式事务,提供对上层透明的水平扩展。另外一个组件 PD 负责存储元信息,如 Region 具体分布在哪台物理节点上,每个 TiKV Node 每隔一定的时间会将自己的状态信息和本机的 Region 分布情况上报给 PD,PD 会根据需要进行 Region 数据的移动和发起添加副本指令等操作,可以说是集群的大脑,整个 TiDB 项目的架构大致就是如此。
水平扩展
我们先来看看 TiKV 是如何实现无缝的水平扩展的。
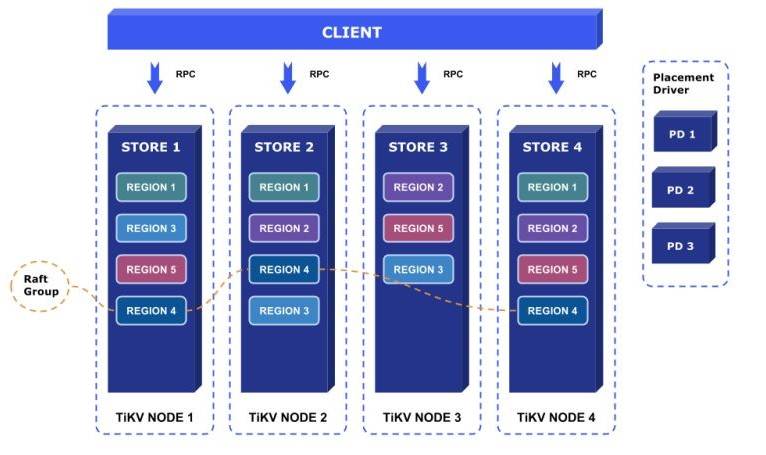
从以上 TiKV 的架构图中可以看出,TiKV 将数据逻辑上分为很多小的 Region,每一个 Region 是一系列连续按照字节排序的 Key-value 对。和很多传统的中间件方案不同的是,TiKV 并不关心上层的 Schema 结构,也不知道上层每个 Column 的类型,就是一个很纯粹的 Key-value 数据库。 数据移动的单位是 Region,每个 Region 都会在不同的机器上维护副本(默认 3 副本)。当一个 Region 的数据增长到一定程度的时候,这个 Region 就会像细胞分裂一样会分裂成两个新的 Region,然后新的 Region 可能会被移动到不同的机器上,用这种方式来进行负载均衡以及容量的扩展。
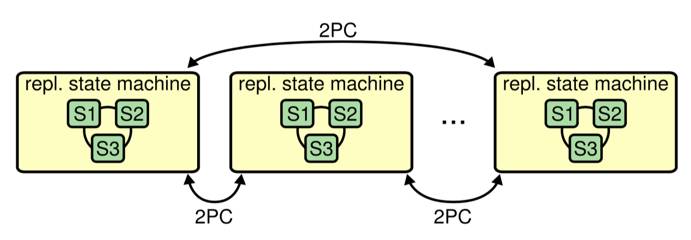
在 TiKV 中,每个 Region 的不同副本之间通过 Raft 协议进行强一致保证,我们在 TiKV 的上层实现了两阶段提交(2PC)来支持跨 Region 的透明分布式事务。整个模型正是 Raft 的作者 Diego Ongaro 博士于 2014 年其博士论文中描述的理想的 Large-scale storagesystem 的模型:
高可用与跨数据中心多活
其实如果抛开数据库层面来谈高可用并不是太复杂,因为业务逻辑服务是比较容易设计成无状态的(一般来说,状态都会持久化到存储层)。现在很多比较前卫的互联网公司,已经在业务的最上层通过动态 DNS + LVS 、F5、HAProxy 等负载均衡工具配合 Docker 以及调度器(K8S 或者 Mesos)实现按需的动态伸缩。如果不考虑存储层,即使整个数据中心宕机,业务层也能做到透明的 Failover,也就是多起几个容器的事情,难点无非是控制好瞬时流量等问题,这从整个模型看是比较完善的。
但是到数据库这层就不那么美好了,传统的关系型数据库的容灾主要依赖主从(master-slave)模型,比如 MySQL 的半同步复制,*** 的 DataGuard 都属于主从复制的范畴。但是主从模型有两个很大的问题,即数据的一致性和故障的自动切换。在主从模型中,即使是热备,在极端情况下也并不能保证 Failover 时数据的一致性。网络环境错综复杂,比如出现集群脑裂的状态(网络部分隔离),监控程序自动的将副本提升 master,但是原来的 master 可能仍然在处理部分客户端的请求,这种情况下,数据就可能发生不一致。这也就是为什么很多一致性敏感的业务即使主库挂掉了,宁可暂停服务也不敢自动切换热备,这样业务的中断时间就不可控了。再者,如果面对一个非常庞大的集群,可能上百个物理节点甚至更多,机器故障是常态,如果每一次故障都需要人工介入,整个系统的维护代价是非常惊人的。
那有没有办法能在强一致的前提下做到安全的故障恢复和故障转移呢?答案是有的。Spanner 的做法是利用 Multi-Paxos 进行同步,这类分布式选举算法拥有很强的容错能力,即使发生节点宕机,网络隔离,整个系统都不会发生数据丢失或者不一致的状态。而且在保证安全的同时,所有的 Failover 工作都是自动的。自动化是一个能弹性水平扩展的系统的重要条件,因为一切需要人工介入的工作都是无法弹性水平扩展的。但是长期以来,由于 Paxos 的实现极其复杂,社区并没有可以在生产环境中使用的实现。
在 TiKV 中我们采用了 Raft 算法来作为和 Spanner 中的 Multi-Paxos。Raft 是 Diego Ongaro 在 2014 年发布的一个全新的先进的分布式一致性算法,在正确性和性能上和 Multi-Paxos 等价,但是对工程实现的复杂度控制很好。目前 TiKV 的 Raft 实现是和 CoreOS 一起合作开发的。CoreOS 是知名的 Raft 项目 etcd 背后的公司。抛弃传统的主从模型,而选用 Raft 这样的分布式一致性算法为 TiDB 在稳定性和健壮性带来了质的飞跃。可以说,整个 TiDB 系统都是构建在 Raft 这个基石之上的。
另外,得益于 Raft 算法的特性,TiDB 可以在保证延迟处于可接受范围内的情况下,能够真正支持跨数据中心多活,这也是 TiDB 的一个重要特点。现在很多对于强一致性要求极端严格的业务,比如金融、支付、计费等,两地三中心的部署渐渐成为共识,但是在多数据中心容灾这个事情上很难找到一个很好的方案。在传统的方案中,如果要做到强一致的热备,需要所有数据中心的副本同步写成功,一个写入的延迟取决于所有数据中心尤其是最远的数据中心的延迟。而在 TiDB 上,由于 Raft 协议只需要同步复制到「大多数」的数据中心即可保证数据的强一致性,所以写入的延迟取决于「大多数」数据中心的延迟。一般来说,对于两地三中心的部署,一定会有一个同城双机房,这时候的延迟较于异地机房的延迟就会小很多了。
完整的面向分布式存储的 SQL Layer
TiDB 实现了完整的 SQL 解析器和优化器。传统的中间件方案只做简单的路由和转发到底层的数据库上,并不能很好地支持 JOIN 或者透明的事务,也就很难完整地兼容原有的业务,对业务层有比较大的侵入性。另外传统的单机数据库的查询优化器并没有考虑到底层存储可能是一个分布式存储,很多优化技巧和手段都难以利用分布式的计算能力和优势。出于以上几点原因,TiDB 选择了重新实现完整的 SQL 解析和 MPP SQL 优化器等组件以支持客户端透明的复杂查询,以及分布式事务。
另外 TiDB 支持完整的 MySQL 语法和网络协议兼容。这样,TiDB 可以直接使用 MySQL 社区的海量测试用例,大量的已有 DBA 工具,更使得那些使用 MySQL 的客户的迁移和兼容的工作成本降到最低。这很好的替代了传统的分库分表和中间件等过渡方案。而且 TiDB 还能完美兼容 MySQL 的 binlog, 可以和现有的 MySQL 互为备份,进一步降低了早期的测试成本。
分布式执行引擎
TiDB 目前内置一个分布式执行框架,采用和 *** Coprocessor 类似的方案。这套框架可以利用多台 TiKV 并行处理数据,再将结果汇集到单台 TiDB 来做最终的处理。在处理 OLTP 请求以及中小规模的 OLAP 请求时,这套框架用起来得心应手。但是当处理大型的 OLAP 请求(例如超大表之间的 Join)时,就显得力不从心了。后续我们计划引入一套新的分布式执行引擎,来专门处理复杂 Query。
Spark 是当前最火的大数据分析工具,在业界得到广泛的应用。TiDB 可以通过 JDBC 接口和 Spark 对接,原有的基于 MySQL 的 Spark 作业可以无缝迁移到 TiDB 上。这样用户可以同时享有 TiDB 海量存储的能力以及 Spark 强大的通用计算能力,从数据中挖掘出更大的价值。这也让 TiDB 同时支持了 OLTP 和 OLAP 两种生态。
另外一个很重要的事情就是将 TiDB 的整个部署与 Kubernetes 整合。我们认为未来的数据库一定会和云深度结合以提供无缝的扩展及部署体验,而第一步就是和容器调度器的深度整合,我们在内部的测试版本中已经成功的将 TiDB 的部署和扩展在 Kubernetes 上实现,相信很快就会在社区中亮相。
社区情况 / 如何进行贡献
TiDB 从第一天开始就是一个完全开源的项目,所有的提交,所有的问题讨论,所有的 Roadmap 都在 Github 上开源。 TiDB 已经发布了 Beta 2 的版本,目前已经有不少用户在生产环境中使用起来,最大的在线上的集群规模超过 200 台物理节点。
目前 TiDB 项目的社区贡献者达近百人,其中包括京东和***的大量代码及 Use case 贡献;作为一个国际化开源项目,CoreOS 及 Facebook 等公司也加入进来一起合作开发,因此也非常感谢 Facebook 的 RocksDB team 和 CoreOS 的 etcd team 的大力支持。同时,TiKV 作为 Rust 社区的顶级项目,得到了 Rust 语言官方的大力支持,项目被收录到 Rust Weekly 作为常驻栏目向 Rust 社区通报每周进展。TiDB 作为一个开放的开源项目,欢迎一切感兴趣的开发者的加入,在 Github 的 TiDB 项目首页有 How to contribute 的文档,Welcome aboard and happy hacking!
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

