
黄东旭解析 TiDB 的核心优势
582
2023-12-26
本文作者李文杰,网易游戏计费 TiDB 负责人
在使用或运维管理 TiDB 的过程中,大家几乎都遇到过 SQL 变慢的问题,尤其是查询相关的读变慢问题。读变慢的问题大部分情况下都遵循一定的规律,通过经验的积累可以快速的定位和优化,不好排查的问题需要从读 TiDB 的每个过程一一排查和分析处理。
本文针对读 TiDB 集群的场景,总结业务 SQL 在查询突然变慢时的分析和排查思路,旨在沉淀经验、共享与社区。
业务 SQL 从客户端发送到 TiDB 集群后,主要经历解析、生成执行计划、执行查询、返回查询结果这几个流程。如下所示是 TiDB 读过程的架构简图:
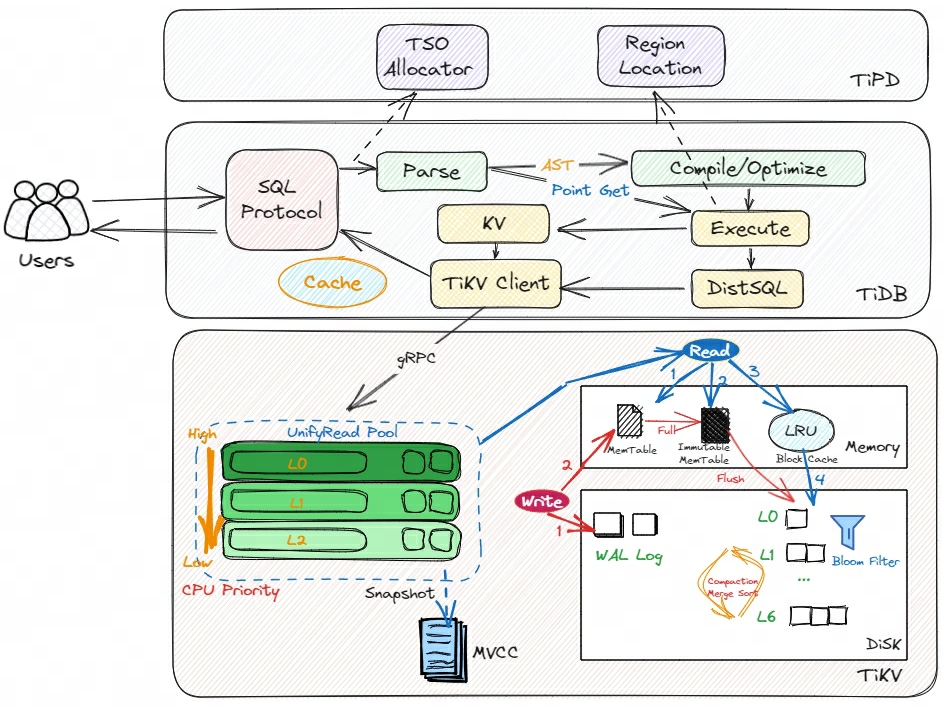
来自客户端的每个读取数据的操作,TiDB 也会将其封装为读事务,通常情况下事务在执行的过程分别会与 TiDB Server、TiPD Server 和 TiKV Server 进行交互。
TiDB Server
用户提交的业务 SQL 经过 Protocol Layer 进行 SQL 协议转换后,内部 PD Client 向 TiPD Server 申请到一个 TSO,此 TSO 即为读事务的开始时间 txn_start_tso,同时也是该读事务在全局的唯一 ID。 TiDB Server 在解析前会将 SQL 做分类,分为 KV 点查询(唯一键查询,Point Get)和 DistSQL 复杂查询(非点查,Copprocessor )。 KV 点查询跳过执行计划优化阶段,直接到查询层,对于在线交易相关的 TP 场景,会大大降低响应延迟。 复杂的 SQL 查询会被解析、转为抽象语法树 AST、编译、基于 RBO/CBO 等优化,会生成真正可以执行的计划。最终生成一个个对单个表访问的数据请求。 TiKV Client 模块负责和存储层进行交互,查询请求经过 gRPC 调用,会优先进入 Unified Read Pool 线程池。TiKV Server
Unified Read Pool 线程池负责确认查询的数据 Snapshot 和统一调度查询优先级。 新来的查询请求其优先级是最高的,落在 L0 队列里。随着查询时间越久,为了保证系统整体吞吐量,慢查询的优先级会不断降低,即会从 L0 调低到 L1、L2 等,随着优先级调低其分配到的 CPU 会减少。 也就是说,一个大查询它越慢,它的优先级就会不断调低,优先级不断调低其执行的时间可能会更久。所以,尽可能减少大查询事务。 查询请求读取 RocksDB 数据 先去 LSM Tree 的 MemTable 查找,最新的数据会写在这里,如果命中则返回。 如果没找到,继续到 Immutable Memory Table 查找,找到则返回。 如果再找不到,则搜查 SST 文件的缓存 Block Cache,找到则返回。 如果还没找到,则会开始读取磁盘 SST 文件,会依次搜索 L0 至 L6 各个层级的内容。每一层的文件都会配备一个布隆过滤器。 过滤器对一个 Key 如果判断不存在,那么它一定不存在这个 SST 文件内,此时可以跳过这个文件; 如果判断在文件内则它可能在可能不在,无法判断准确,此时会直接去查文件内容,由于 SST 文件严格有序,所以在文件内是效率较高的二分查找。 直到找到数据后,通过 gRPC 调用返回查询结果。上面描述的过程,大致就是一个查询请求在 TiDB 集群内部的流转步骤,这也是我们在遇到读慢时的分析步骤。
业务的 SQL 变慢后,我们在 TiDB Server 的 Grafana 面板可以看到整体的或者某一百分位的请求延迟会升高,我们根据现象先确认方向性的问题:是整体变慢,还是某个 SQL 变慢。
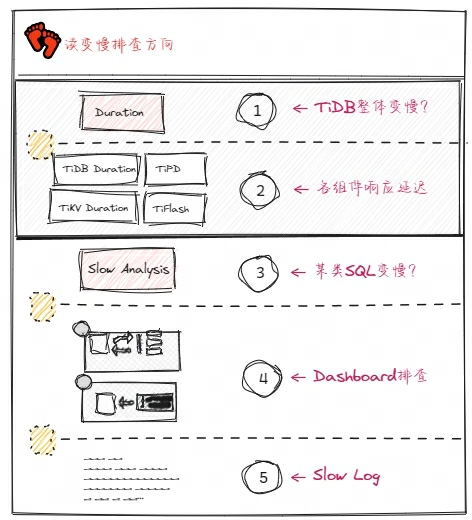 是否整体变慢
分析各个组件 TiDB、TiKV、TiPD 的响应延迟情况
整体如果是正常的,继续分析是不是某类 SQL 变慢
到 Dashboard 查一查慢查询,看一看集群热力图,分析一下 Top SQL
是否整体变慢
分析各个组件 TiDB、TiKV、TiPD 的响应延迟情况
整体如果是正常的,继续分析是不是某类 SQL 变慢
到 Dashboard 查一查慢查询,看一看集群热力图,分析一下 Top SQL
根据上面的思路,通常就可以对读变慢的问题有一个整体的把握。
接着,和写入变慢的分析一样,我们可以依次排查物理硬件环境、是否有业务变更操作等情况,直到定位清楚问题。如下图所示,业务读 SQL 变慢的分析思路可以有下面步骤:
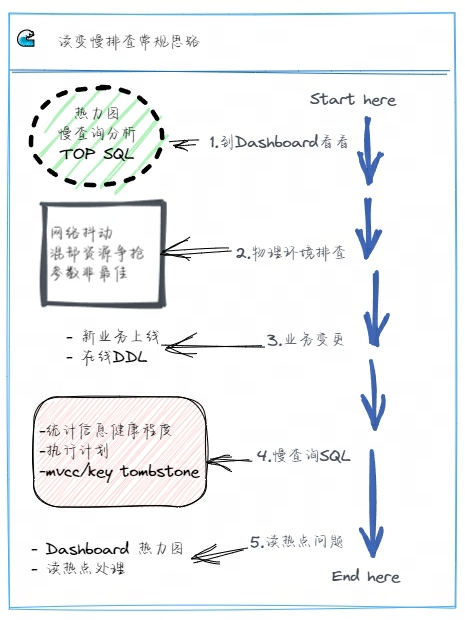 遇到问题我们应该养成习惯,要先到 Dashboard 看看,对集群运行状况有个整体的把握
查看集群热力图,关注集群高亮的区域,分析是否有读热点出现,如果有则确认对应的库表、Region 等信息。热点问题处理
排查慢 SQL 情况,查看集群慢查询结果,分析 SQL 慢查询原因
查看 TOP SQL 面板,分析集群的 CPU 消耗与 SQL 关联的情况
物理硬件排查
排查客户端与集群之间、集群内部 TiDB 、TiPD、TiKV 各组件之间的网络问题
排查集群的内存、CPU、磁盘 IO 等情况,尤其是混合部署的集群,确认是否存在资源相互竞争、挤兑的场景出现
排查操作系统的内核操作是否与官方建议的最佳实践值是否一致,确认 TiDB 集群运行在最优的系统环境内
业务变更
确认是否是新上线业务
查看集群的 DDL Jobs,确认是否由于在线 DDL 导致的问题,特别是大表加索引的场景,会消耗集群较多的资源,从而干扰集群正常的访问请求
遇到问题我们应该养成习惯,要先到 Dashboard 看看,对集群运行状况有个整体的把握
查看集群热力图,关注集群高亮的区域,分析是否有读热点出现,如果有则确认对应的库表、Region 等信息。热点问题处理
排查慢 SQL 情况,查看集群慢查询结果,分析 SQL 慢查询原因
查看 TOP SQL 面板,分析集群的 CPU 消耗与 SQL 关联的情况
物理硬件排查
排查客户端与集群之间、集群内部 TiDB 、TiPD、TiKV 各组件之间的网络问题
排查集群的内存、CPU、磁盘 IO 等情况,尤其是混合部署的集群,确认是否存在资源相互竞争、挤兑的场景出现
排查操作系统的内核操作是否与官方建议的最佳实践值是否一致,确认 TiDB 集群运行在最优的系统环境内
业务变更
确认是否是新上线业务
查看集群的 DDL Jobs,确认是否由于在线 DDL 导致的问题,特别是大表加索引的场景,会消耗集群较多的资源,从而干扰集群正常的访问请求
常规分析思路可以解决绝大部分的问题,对于剩下那些无法确认的或较为复杂业务的问题,这时候可以分析读请求从 TiDB Server 到 TiKV Server 、到读 RocksDB 的整个过程,对全部查询的链路逐一进行排查,从而确认查询慢所在的节点,定位到原因后再进行优化即可,这一过程大致如下图所示。
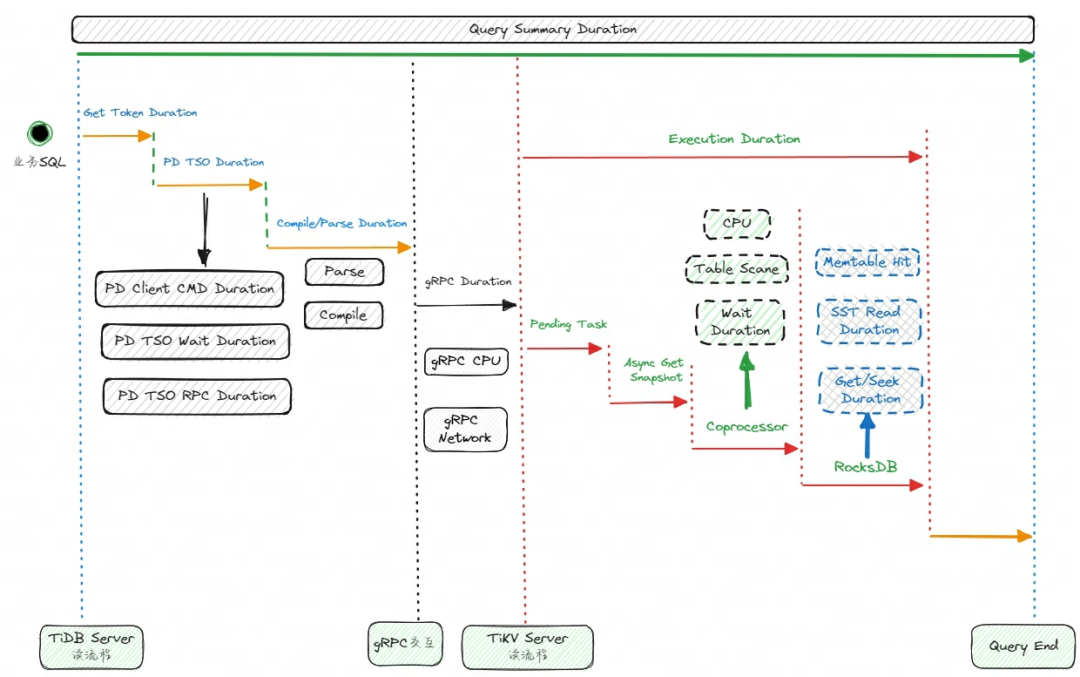
同样地,这个是一个兜底的排查思路,适用范围较广、通用性较强,但是排查起来要花费更多的时间和精力,也要求管理员对数据库本身的运行原理有一定的掌握。上面的排查步骤还是很复杂的,对用户很不友好。
但是,目前官方已经推出的 Dashboard 慢查询分析功能,已经帮我们集成和记录了各个环节的延迟,再也不用一个一个去查找 Grafana 面板来确认和分析了,极大地降低排查难度和缩短问题解决时长,是 TiDB 用户的一大福音。
下面是一个慢查询执行时长分析的例子,可以看到慢查询是因为 TiKV 执行 Coprocessor 任务的累计处理时间比较久,所以导致整个查询较慢, 我们再继续针对性分析和优化 Coprocessor 算子即可。

版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

