

黄东旭解析 TiDB 的核心优势
877
2023-04-21
参加 Hackathon 可以接触到内核、工具、生态各个领域中志同道合的小伙伴,通过他们的项目学习到非常好的创意。大家的想法都很奇妙,充满了创新力,在平时的研发过程中,很少能接触到这些,Hackathon 能够帮助我们打开思维,让我们知道原来 TiDB 还可以这么玩。
—— He3 团队
TiDB 在使用过程中,随着用户数据量的持续增长,存储成本在数据库总成本中的占比将会越来越高。如何有效降低数据库存储成本摆在了许多用户面前。
在众多解决方案中,有一种方法是将冷热数据实现分层存储。在绝大部分场景中,数据其实都可以分为 “冷数据” 和 “热数据”。数据划分的原则,可以根据时间远近、热点/非热点用户等等。用户通常只访问一段时间之内的数据,例如近一周或一个月。如果数据不做划分,必然会导致一定程度上的性能、成本损耗。
在刚刚收官的 TiDB Hackathon 2021 中, He3 团队就选择了冷热数据分层存储来降低 TiDB 的存储成本。他们在设计中将热数据存放在 TiKV 上,将查询和分析几率比较少的冷数据存放到便宜通用的云存储 S3,同时使 S3 存储引擎支持 TiDB 部分算子下推,实现 TiDB 基于 S3 冷数据的分析查询。项目获得了评委的一致好评,力夺本届赛事的一等奖。
这个项目为后面 TiDB 与 S3 的整合打下不错的基础,在这次 Hackathon 验证了可行性。它的原理其实很简单,将冷的数据放到 S3,将算子尽量下推到 S3,通过 S3 原生的 select 功能加速查询。当然,如果数据已经在 S3,还可以通过 Cloud 上其他的服务,譬如 Athena, 来做更多的查询聚合操作,加速查询。这次大家都是在通过 partition 做文章,毕竟根据时间片来分的 partition 是非常常用的一种操作。我们内部现在也在通过 LSM 做一些跟 S3 整合的研究,我还是很期待这些都能在今年看到不少的成果产出。譬如 TiDB Cloud dev tier 集群就可以完全用这套机制来验证。
—— 评委唐刘点评
He3 团队的队长薛港,队员时丕显、沈政,都是来自移动云数据库团队的研发工程师,三人平时的工作就是从事云数据库服务的开发,降低用户在云上使用数据库的成本是他们一直追求的目标。
在去年 7 月份的 Hacking Camp 中,He3 就曾基于 TiDB 实现了提供 Serverlessdb 服务的 Serverlessdb for HTAP 项目。用户在使用 TiDB 时可以按使用量付费,不用再像传统 RDS 需要包年包月,大大降低了用户使用 TiDB 的成本。该项目也因此获得了 Hacking Camp 优秀毕业生和最佳应用奖。
随着产品在移动云上的落地,很多用户在使用了一段时间后发现随着数据量的增加,存储成本越来越高。薛港解释道,在公有云上,块存储收费比 S3 对象存储要高很多,用户部分场景的数据其实很多是冷数据,完全可以存放在 S3 上。于是在去年 12 月份时,他们就开始思考如何降低 TiDB 的存储成本。恰好这时 TiDB Hackathon 2021 启动了,薛港和时丕显、沈政一商量,就决定将冷热数据分层存储作为今年的比赛项目。在答辩时,他们专门用了一页 PPT 分析了运用该项目后的成本变化:
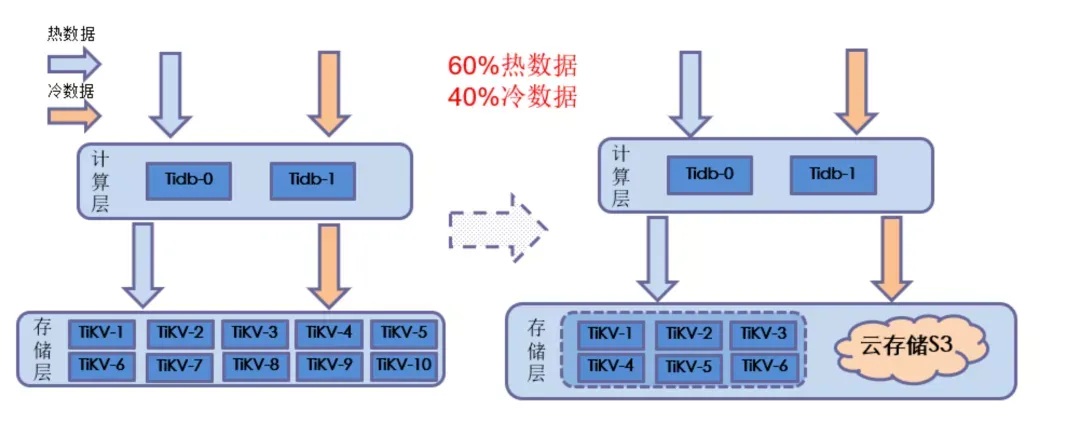

项目方向定了,接下来就该报名了。队长薛港在看电视的时候对氦 -3 这种元素产生了兴趣,经过了解,发现它可以用作核聚变燃料,比现有的核燃料能量更大,并且只有很少的放射性,是一种清洁高效安全的发电燃料。这种特性和他们对分布式云数据库的期望完全一致 —— 安全、高性能、易用、价格便宜,于是 He3 便成了队名。
在接下来不到一个月的时间中,薛港作为队长负责整体需求的确认、架构设计、方案验证以及具体框架的开发。其他队员主要负责功能开发,时丕显负责算子下推与数据类型支持,沈政重点在性能优化以及 TPC-H 测试。
He3 开发的 TiDB 冷热数据分层存储项目,能够以极简的方式实现冷热数据分离:
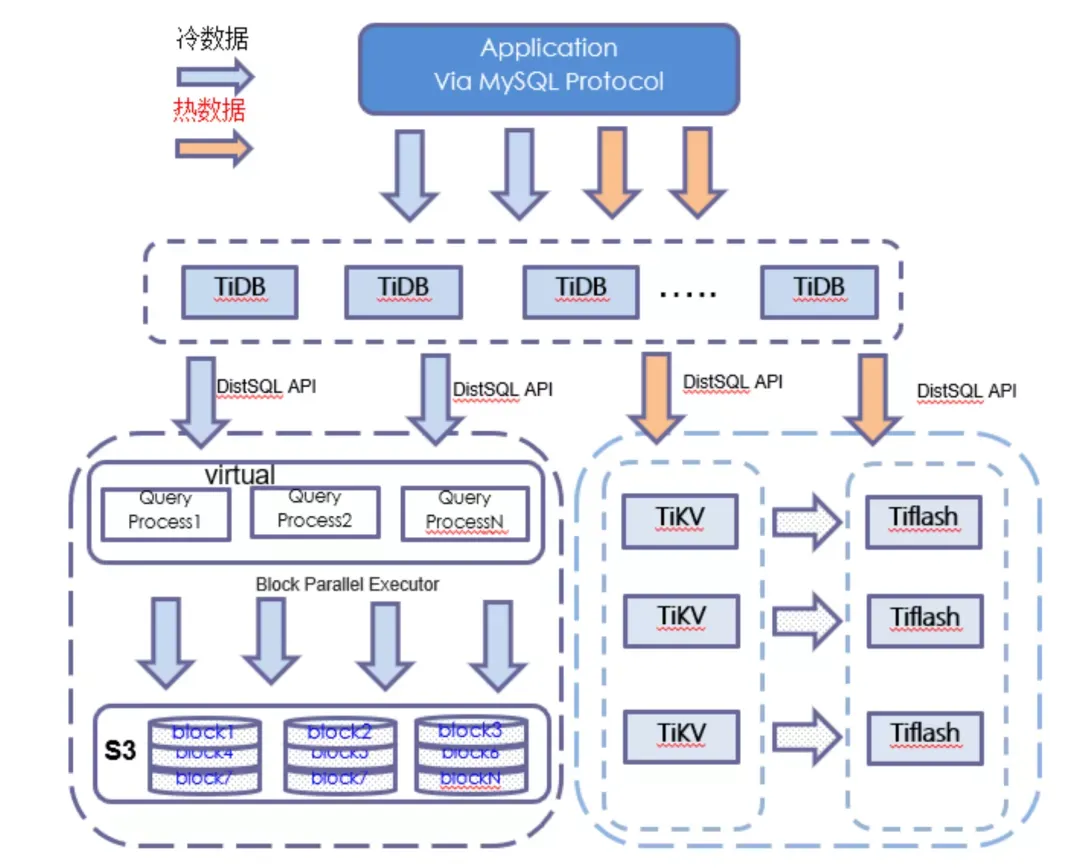
针对普通表:实现 insert into select 的方式完成冷热数据分离:
支持创建 S3 外部表; 支持通过 insert into s3_table select from tikv_table where ... ,把 TiKV 内部表的数据转储到 S3 对象存储上; 支持通过 insert into tikv_table select from s3_table where ... ,把 S3 外部表的数据转储到 TiKV 内部表。针对分区表:自动完成分片表转化成 S3 外部表,保留主表和 S3 外部表的主从关系。
支持通过 Alter 分区表操作,把 TiKV 内部分区表的数据自动转储到对应的 S3 外部表中,自动完成以下几件事:
内部 TiKV 分区表数据转存到 S3 对象存储中; 更改分区表元数据,把 TiKV 内部分区表转化成 S3 外部表,核心要点保留 S3 外部表和主表的分区关系; 删除 TiKV 内部分区表数据。转换后 S3 外部分区表对用户完全透明,对用户来说,S3 外部表就是主表的一个分片表。例如针对主表的查询结果包含部分 TiKV 内部分片表以及部分 S3 外部表对应的分片表数据,那么返回的结果就会来自两部分:TiKV 内部分片表,以及 S3 外部表。
保证用户使用 S3 外部表和 TiKV 内部表没有任何区别:
S3 外部表支持所有的数据类型; S3 外部表支持所有的算子; 优化 S3 外部表操作性能在用户可接受的范围内。通过支持谓词(逻辑运算、比较运算、数值运算),聚合函数、Limit 等算子下推到 S3 节点,利用 S3 的计算能力提升查询性能。
为了达到期望所有效果,He3 在此次 Hackathon 中开发修改了 TiDB 一些模块:
Alter table employees alter partition employees_01 s3options s3object
少量无法下推 S3 的算子,He3 修改了优化器阻止这部分算子下推。当前不支持的算子,主要就是包含 TopN 算子。
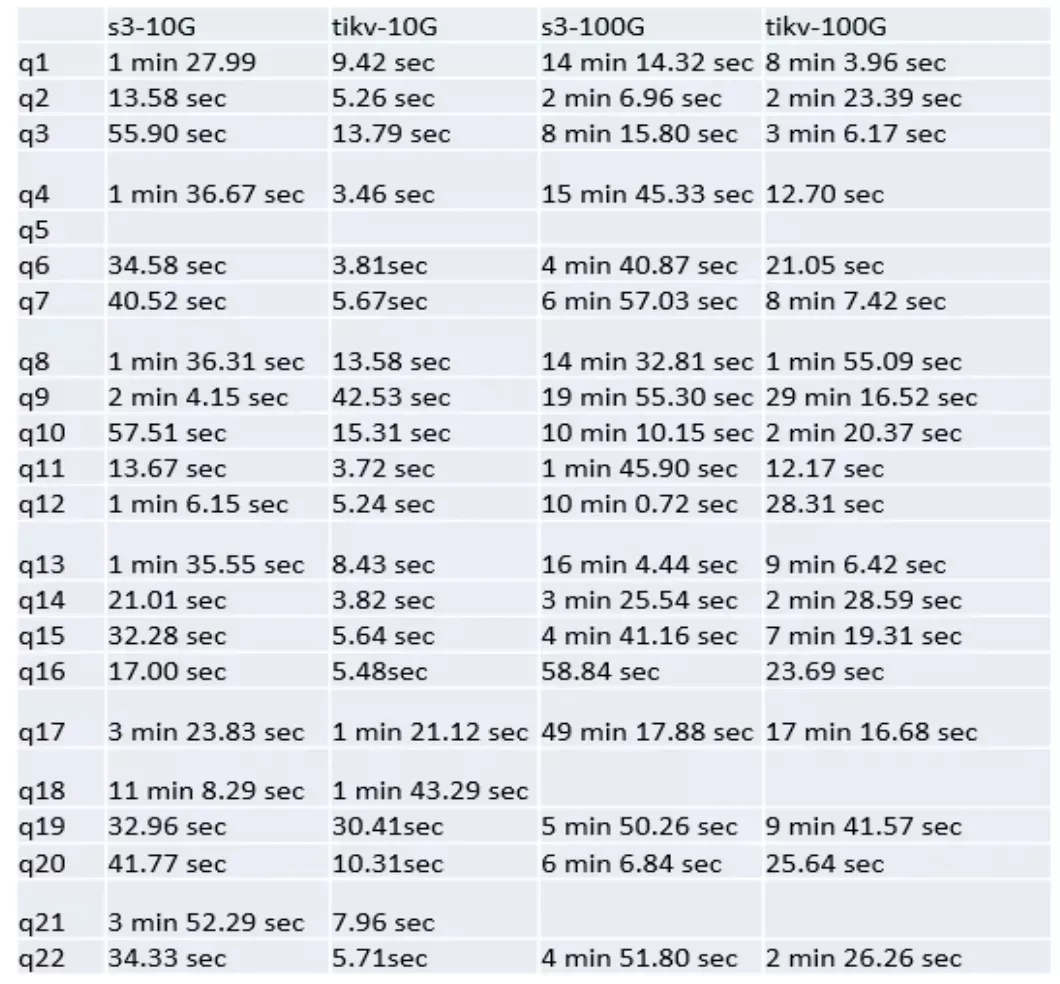
He3 最初设定的目标有两个:一是希望数据能够以比较简单的方式直接实现冷热数据分离;二是希望冷数据分离到 S3 后,它的查询性能能够在合理的时间范围内。所以一开始就把跑通 TPC-H 作为目标。
项目的冷热数据分离功能很快就完成了开发,但是接下来他们遇到了一个最大的问题——性能总是无法达标。一开始的方案设计是将全部数据都读取到 TiDB 上集中处理,但在测试中发现即使只有 10GB 的数据,TPC-H 也跑不出来。三名队员通过讨论、调研、分析,发现 S3 其实也具备一定的计算能力,是否可以把部分计算下推到 S3 ,让 S3 和 TiKV 一样能够承载部分计算?
改变方案后通过几个场景算子下推,He3 发现性能提升非常明显,在之后的开发中就将能下推的算子全部下推,项目的整个性能优化每天都会以 20% 的幅度在提升。最终在比赛日上,他们跑通了整个 TPC-H 测试。
此次 Hackathon 中,其实还有另一支赛队 Interstellar 也选择了分层存储,这也给 He3 队员们留下了一个有趣的画面:在 Interstellar 开始答辩时,He3 以为是自己在投屏,手忙脚乱地到处找关闭投屏按钮,直到对方开始答辩了,他们才意识到原来是两个队伍的题目撞衫了。
He3 队员们其实在去年也参加了 TiDB Hackathon,因为刚接触 TiDB ,并没有碰内核。当时心中就埋下一个想法,下次参赛一定要做够硬的项目。这也是薛港在毕业后就给自己树立的目标 —— 做数据库内核,并认为这是一件很酷的事情。于是在今年比赛中, He3 选择了最硬核的赛道 —— 内核组。
过去一年的工作对他们帮助非常大,由于三人平时的工作和 TiDB 结合非常多,在碰到问题的时候就会去想有什么解决方案,这个过程中很容易产生各种好的 idea。例如这次如何降低 TiDB 存储成本的问题,他们当时就想出了至少三种方案:第一种是将 TiDB 底层的编码方式做一些改变,让 TiDB 的整个压缩比能够再下降 50% - 60%;第二种也是一种冷热数据分离方案,将 LSM-tree 和 S3 集成;第三种就是现在的冷热数据存储分层方案。但前两种方案在 Hackathon 如此短的周期内很难完成,于是他们就采用了第三种方案。
未来, He3 还会从三个方向将该项目持续演进、迭代:
通过新的编码方式以及加速算法,降低数据在 S3 的存储容量,基于本次比赛中实现的效果再降低 50% 的存储容量; 持续优化 TiDB 对接 S3 的存储差异性能,在这次比赛的后期,这块性能每天都有 20% 的性能提升,He3 认为这里其实还有很大的提升空间; 进一步简化用户的冷热数据分离方式。对这次项目的最终实现, He3 其实还有一些遗憾,一开始设计的时候他们想过现在冷热数据分离还需要 DBA 来做一些操作,如果能将这个工作进一步实现自动化操作,就可以让冷热数据分离应用性再上一个台阶,不过由于时间比较有限的原因没能实现。此外,除了项目本身继续完善外,He3 还希望在迭代到一定程度后就将整个产品的代码提交给社区,用开源的方式回馈社区,大家一起共创。
延展阅读:点击查看更多 TiDB Hackathon 2021 优秀项目分享
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

