

黄东旭解析 TiDB 的核心优势
850
2023-04-21
数据湖是大数据领域近年来非常火热的技术,传统数仓无法实现增量数据的实时更新,也无法支持灵活的元数据格式,数据湖技术便在这一背景下诞生了。数据库的增量变更是数据湖中增量数据的主要来源,但目前 TiDB 的入湖路径还比较割裂,全量变更用 Dumpling 组件,增量变更用 TiCDC 组件。两者处于割裂的链路, TiDB 也无法通过实时物化视图完成数据入湖的实时清洗和加工。
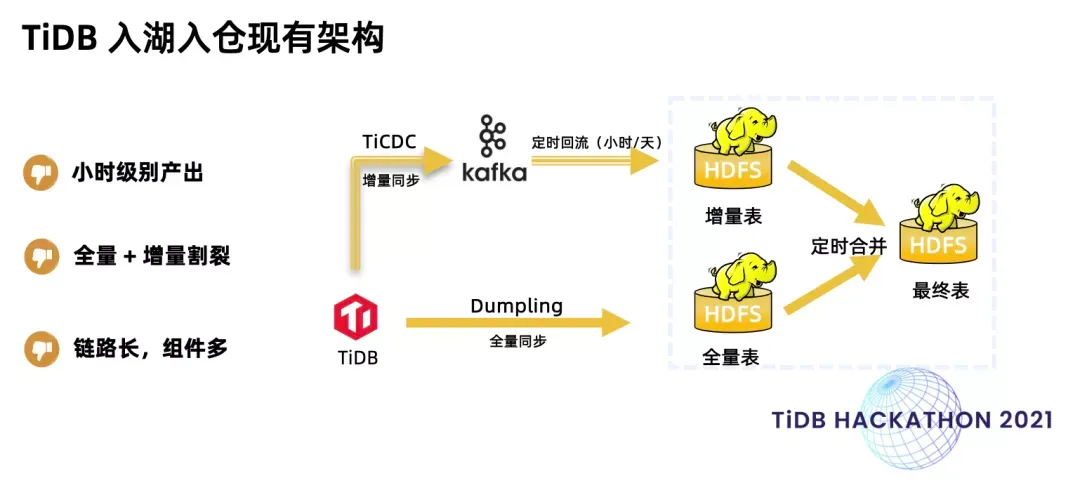
在 TiDB Hackathon 2021 赛事中,TiLaker 团队的项目解决了 TiDB 数据入湖的问题。通过 TiLaker 可以帮助用户简化 TiDB 数据到数据湖的流程,充分消化使用 TiDB 上存储的数据。TiLaker 团队也凭借这一项目一举斩获了“二等奖”、“华创资本特别赞助最佳市场潜力奖”、“最佳人气奖”三项大奖。
“去年 Hackathon 其实有不少跟 Flink 整合的项目,今年决赛就看到一个,我还是有点小失望的。但今年 TiLaker 做的还是挺完备的,有 Flink committer 的参与,给 Flink 实现了一个 CDC Connector,这样能让 Flink 直接读取 TiDB 的增量数据,同步到下游。借助 Flink 的能力,让 TiDB 更好地与下游生态进行打通,后面也希望有更多的应用案例能出来。”
——评委唐刘
在过去的一年中, TiDB 非常重视生态建设,在生态中最重要的就是 TiDB 作为一个分布式数据库和大数据生态之间的融合互操作。TiLaker 通过 Flink CDC 建立了一个快速、高效、简化的通道,解决了高效入湖的问题,将两个生态进行了更好地融合。本篇文章就将通过对 TiLaker 团队与华创资本合伙人谢佳的对话,揭秘 TiLaker 赛前幕后的精彩故事,也希望给开发者和用户们如何将数据入湖带来一些启示。
TiLaker 团队成员由四位来自 TiDB 社区和 Flink 社区的资深贡献者和开源软件爱好者组成,下面先来认识下他们:
吴雪莲:TiDB 同学可能对我比较熟,我一直在 TiDB 做内核,也是 TiDB Committer & TiKV Committer。有个爱好就是喜欢去撩 Flink 的同学,我爱人就在 Flink 团队做数据湖,这次也因为这个渊源与 Flink 的小伙伴走到了一起。
徐榜江(雪尽):我之前在阿里网络团队一直做实时监控系统,后来觉得实时计算是一个很好的方向,就跑来 Flink 社区,大概做了两三年时间。前两年专注在 Flink SQL 上,后面慢慢在数据集成方向发现了一些很大的空间。很多时候 Flink 被人们拿来当成一个数据管道,但数据管道是非常薄的一层,不像数据库、数据湖有着数据的强依赖性。所以我们就有了 Flink CDC 这个项目,它相当于给 Flink 这个管道增加了一个集成能力,可以支持更多的数据源、更多的上下游。我最近这大半年都在做 Flink CDC ,现在也是 Flink CDC Maintainer & Apache Flink Committer。
蒋晓峰(子懿):我叫蒋晓峰,阿里的花名叫子懿,和雪尽都来自 Flink 团队。我是 Apache ShardingSphere & Apache RocketMQ Commttier,现在主要负责 Apache Flink AI 相关的工作。算上本次比赛一共参加了三届 TiDB Hackathon 。
蒋泳波:我目前是在 TiDB 调度团队做研发,和雪莲是同一个组的同事。我其实是最近才加入 TiDB 的,之前在阿里网络部门做数据开发,和雪尽老师都在一个网络大团队。不过我加入阿里的时候,雪尽好像已经离开了当时的团队,我维护的一些 SQL 就是雪尽留下来的。
从个人介绍不难看出,TiLaker 的四位成员之间其实非常有渊源,TiLaker 的故事也缘起于此:
时间回到 Hackathon 开启报名时——
有一天吴雪莲回家,她爱人对她说:我有个同事想找你组队。
蒋泳波:这个人就是我,当时我在参赛群里看见了雪尽,虽然以前和他并没有直接交流过,但还是去私聊了下,问要不要一起组队玩?之后雪尽又联系了子懿,我又联系了雪莲。
就这样,TiLaker 团队正式组成了。
比赛中,TiLaker 团队给投资人评委华创资本合伙人谢佳留下了深刻的印象,他一直对这类 Infra 的项目非常感兴趣。
谢佳:在这次整个参赛的选手和项目中,TiLaker 的项目是非常具有代表性的。两个非常受开发者喜爱的顶级社区之间,相互放大彼此的生态,进行互联互通。数据入湖来自于产业界非常广泛、实际的需求,对于 Flink 的同学来说,可能这个事情他们或早或迟都会去做,本次 Hackathon 活动恰恰加速了 Flink 和 TiDB 社区的迭代。从团队方面来说,大家都是开源社区中的各种好手,都能独当一面。这几方面合在一起,就是非常能吸引我的点。
雪尽:两个社区的人做一个集成类的项目,相当于一个交叉学科,我们的团队拥有 Flink 与 TiDB 两个社区的同学,对于做这样的集成类项目或生态类项目是很有帮助的。比如,有一些 TiDB 技术的细节,我可以很快地问一下雪莲老师、泳波老师,他们可以快速地给我答案,我就不用去 GitHub 上去看代码和文档了。
我和子懿对 TP 类型的数据库其实是没有多少经验的,我对 MySQL 、PG 、*** 有一定了解,但对 TiKV 底层的更新机制、集群其实不是很了解,这些都是通过这次 Hackathon 了解的。所以刚开始我们对 TiDB 的一些逻辑不是很清楚,刷了两次夜才解决。后来在雪莲和泳波进来后,有一些代码看不懂的时候,我们就会在群里直接交流,节省了很多时间和精力。
吴雪莲:项目的名字是才华横溢的子懿老师起的,包括我们的战队宣言,还有答辩 PPT ,以及团队介绍视频都是他想的。项目的实现机制主要由雪尽老师提出,他平时就一直在做 Flink CDC 的工作,上游接了很多数据库,有很多 TiDB 用户就找过来问能不能支持一下 TiDB 。恰好这时,我们看到 TiDB Hackathon 2021 开启报名,于是就决定带着这个项目参赛了。
雪尽:Flink CDC 在数据源方面, 其实主流的 DB 都支持了,即使没有支持,社区的 PR 也都开出来了,只是我这边没有精力来得及给大家 review 。像 MySQL 、*** 、PG 、 *** 、TiDB 的 PR 都在整理中,阿里的 *** 和 *** 的同学看到我们来 TiDB Hackathon 比赛也过来开了 PR,最近也在催着 review。
其实 Flink 这个管道有着很强的集成能力,它可以连接到很多下游。当数据到了一定规模时,数据库的存储始终要比廉价的数据湖存储更贵。很多历史数据并不需要那么贵的存储,也不需要去分析。让它直接往数据湖里导入,做历史存储就够了。而且数据湖也有更新的能力, Flink 结合数据湖甚至能够做到分钟级的更新。数据库接 Flink 再接数据湖,就是看中了数据湖既便宜又可以更新这两大核心优势。
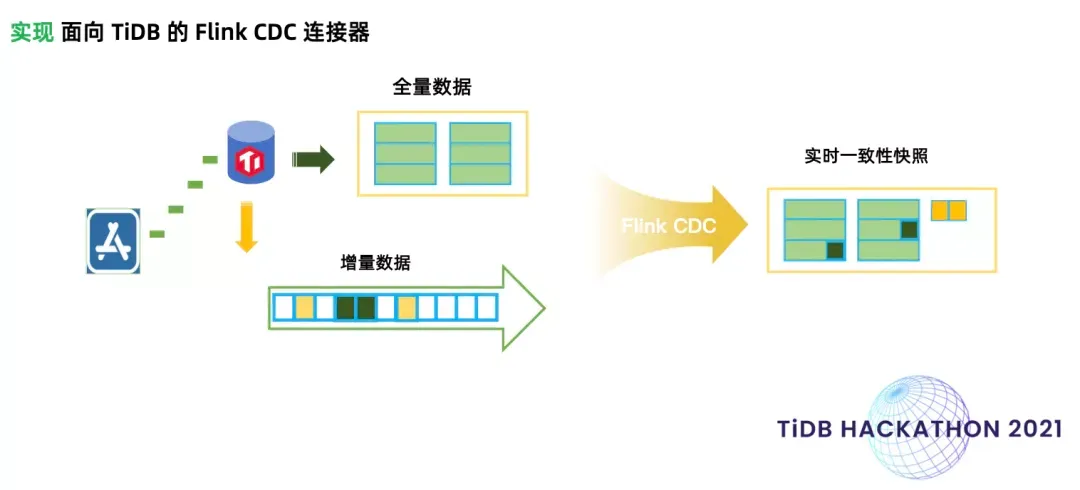
TiLaker 基于 TiCDC 组件开发了面向 TiDB 的 Flink CDC Connector, TiDB CDC Connector 提供全量读取历史数据和实时读取增量数据的能力,在全量和增量数据切换时,保证一条不丢,一条不多的 eactly-once 语义;同时,TiLaker 提供了 SQL API,用户只需要几行 Flink SQL 就能捕获 TiDB 中全量的历史数据和增量数据。得益于 Flink SQL 的 c hangelog 机制,Flink SQL 可以和数据库的变更数据无缝衔接,通过 Flink SQL 定义的 tidb-cdc 表就是 TiDB 中对应表的实时物化视图,每次数据库中的变更都会让 tidb-cdc 表自动更新;
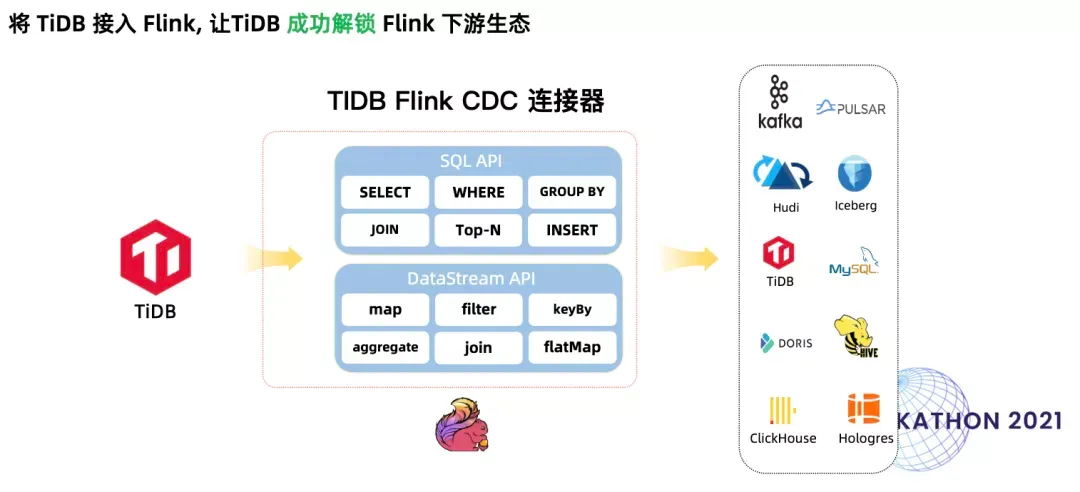
Flink CDC 项目还提供了 MySQL、MariaDB、Postgres、***、Mongo 等数据库的支持,这意味着在支持 TiDB 后,用户可以实现异构数据源的融合,比如部分表在 MySQL 中,部分表在 TiDB 中,可以做实时的 Join、Union 等 Streaming 加工;此外,作为一个优秀的计算引擎,Flink 可以提供强大的计算能力和优秀的 pipeline 能力,支持业界多种数据湖产品(Hudi,Iceberg),并且提供 SQL API 支持。这让 TiDB 的用户只需要使用 SQL 就可以方便地将数据实时写入数据湖,轻松实现数据湖的构建。
正如评委唐刘评价所言,TiLaker 团队在 Hackathon 中实现的项目已经非常完备,对于比赛他们已经完成了一大半,接下来摆在大家面前的难题,就是如何在比赛中让评委对项目的亮点更有体感?
吴雪莲:主代码和 Flink CDC 主要是雪尽老师和子懿老师在弄,我跟泳波是打酱油的,主要精力放在做 demo 上。当时一直在想怎么才能突出这个项目的亮点呢?我们当时就想到了网约车实时智能调度系统。 它基本上模拟了网约车是怎么调度的。实时的数据写 TP 的时候都会写到 TiDB,但是像一些推荐的数据,比方说一个乘客要打车,最简单可能就是推荐一下他附近的车辆。在这个大数据的情况下, TiDB 可能就不太够用。我们借助 Flink CDC 将数据导入到 Flink 来计算,实现实时推荐业务。另外在数据入湖后,还做了一个报表,就是那个车跑来跑去的报表,这些数据都是我们从湖里面拿过来的,相当于一个离线的分析。
蒋泳波:当时想做这个 demo 主要就是觉得网约车是一个比较典型的互联网架构,它会有一些订单交易的核心系统,这个系统需要数据,这一定是要跑在 TP 数据库上面的。然后它也会有一些实时计算的要求,但是一般 TP 系统是很难去做流式计算的,同时对运营同学来说也会有一些实时大屏的需求,需要方便他们去做一些业务分析。
雪尽:从我的经验来看,一个项目真的要上生产的话,还有蛮多事情要做的。特别是在测试方面要花很大的精力,以我最近对各个数据库的了解,不同版本之间各种兼容性的坑其实是特别多的,如果要为银行这样的客户提供服务,还有蛮多的路要走。
蒋晓峰:在实时机器学习场景里,我们这一套 TiLaker 方案对用户来说是非常友好的。现在机器学习更加实时化了,它会带来很多实时特征的存储。现在大部分公司的实时特征存储都用的是 KV, 比如 Redis ,它就要把每个时间点的特征都存下来。但如果用了 TiDB + TiLaker 这一套解决方案,客户就可以减少特征存储成本。我平时主要是负责实时风控和实时推荐解决方案的,也会对接很多客户,如喜马拉雅,他们都会有这方面需求,而且需求很大。这个项目如果可以落地,是可以作为一个商业化解决方案的。
评委谢佳从投资人的角度也给出了自己的看法:“坦白讲,其实这类产品在商业化方面会有一些挑战。这类产品会比较偏向于解决中间某个环节的问题,但凡做中间层都会面临一个商业上的悖论和挑战——你解决的确实是大家普遍遇到的问题,但还不是一个完整的商业问题。它会带来一定程度上的效率提升,但是对于商业的价值提升不是很直接。如果你能从中间环节往整个业务角度看的话,它的价值链上下游就能够延展得更多。客户拿到这个产品,就是一个完整产品,他用这个完整产品可以解决更多的问题。从商业化的角度来说,就更容易创造更多的客户价值。另外,很多企业都会有一些特定需求、非标化的场景,你很难用一个产品来满足全部需求。但未来如果大家都上云了,更加标准化了,就会扫除很多商业化的障碍。”
吴雪莲:我之前当过导师,也当过围观家属,但今年确实是真正意义上第一次参加 TiDB Hackathon 。我其实一直挺想对 Flink 与 TiDB 生态接触的东西了解一下,就趁这个机会去了。通过 TiLaker 这个项目,我对 Flink 以及 Flink 下游的一些生态更加了解了,这对我在 TiDB 的工作有很大帮助。另外,通过参加 Hackathon ,我在杭州现场和很多搞开源的同学都交流了一下,还是挺开心的。
雪尽:我也是第一次参加 TiDB Hackathon。虽然 Flink 社区之前也有举办过,但其实跟 TiDB 早期举办的 Hackathon 应该差不多,就是两天的极限编程。这次组委会给我们留了比较充沛的时间,也是我们最终能把这个项目的完成度做得比较好的一个原因。
本届 Hackathon 真的就是高手如云,我觉得很多参赛选手的 idea 和实际效果都非常厉害。我们本来都没期待能够拿二等奖,感觉最多就是三等奖。我记得有一个做性能增强的团队,他们的 Benchmark 测出来最低提升 18%,最高 40%,那种项目的确很有技术含量。另外,在杭州这边还有一个最佳创意奖,和游戏做结合的,给我的印象也很深刻。参加 TiDB Hackathon,能够认识社区的各个同学,我觉得这个收获更大。
蒋晓峰:我已经想好了下一界 Hackathon 比赛的 idea。Flink Forward Asia 2021 提出了 Streamhouse 概念,其中引入了 Dynamic Table Storage 。我想用 TiFlash 作为 Dynamic Table Storage 底层的实现,这样可以更加强 Flink 生态和 TiDB 生态之间的整合。这不仅仅是在数据集成方面做对接合作,也可以在其他模块上面做一些创新。 关于 Hackathon 我期待之后的 Hackathon 能在线 PK 写代码 。这次可以看到很多参赛项目的工作量不仅仅只有两天能做完,其实从 Hackathon 比赛的意义来说就不那么符合要求。
谢佳:我是第二次参加 TiDB Hackathon 了。第一次参加的时候大家总会说 PingCAP 是一家 Hackathon 驱动的公司,我当时没有特别强烈的感受,但这次我觉得这种感受还蛮强的。在国内做基础软件的企业中,PingCAP 应该是第一家拥抱开源,同时把商业化也做得不错的。很多人平时可能偶然会产生一些 idea ,但因为工作例行安排平时做不了,通过 Hackathon 就能把这些 idea 释放出来,变成另外一种 driven。
延展阅读:点击查看更多 TiDB Hackathon 2021 优秀项目分享
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

