
黄东旭解析 TiDB 的核心优势
626
2023-04-18
TiDB 有一些功能和其它功能不一样,这类功能可以作为构建其它功能的基础,组合出新的特性,这类功能称之为:Meta Feature。
《关于基础软件产品价值的思考方式》 - 黄东旭
对一款分布式数据库而言,数据如何分散存储在不同节点永远是个有趣的话题。你是否有时会期望能具体控制数据具体存储在哪些节点?
当你在同一个 TiDB 集群上支持多套业务以降低成本,但又担心混合存储后业务压力互相干扰
当你希望增加重要数据的副本数,提升关键业务的可用性和数据可靠性
当你希望把热点数据的 leader 放到高性能的 TiKV 实例上,提升 OLTP 性能
当你希望实现热冷数据分离(热数据存放在高性能介质,冷数据反之),降低存储成本
当你希望在多中心部署下,将数据按照实际地域归属和数据中心位置来存放,以减少远距离访问和传输
你也许已经知道,TiDB 使用 Placement Driver 组件来控制副本的调度,它拥有基于热点,存储容量等多种调度策略。但这些逻辑以往对于用户都是近似不可控的存在,你无法控制数据具体如何放置。而这种控制能力就是 TiDB 6.0 的 Placement Rules in SQL 数据放置框架希望赋予用户的。
TiDB 6.0 版本正式提供了基于 SQL 接口的数据放置框架(Placement Rules in SQL)。它支持针对任意数据提供副本数、角色类型、放置位置等维度的灵活调度管理能力,这使得在多业务共享集群、跨 AZ 部署等场景下,TiDB 得以提供更灵活的数据管理能力,满足多样的业务诉求。
让我们来看几个具体的例子。
想象下你是一个服务供应商,业务遍布全球,早期架构为中心化设计,随着业务跨地域开展后,业务拆分全球化部署,中心数据访问延迟高,跨地域流量成本高。随着业务演进,你着手推动数据跨地域部署,以贴近本地业务。你的数据架构有两种形式,本地管理的区域数据和全局访问的全局配置数据。本地数据更新频次高,数据量大,但是几乎没有跨地域访问的情况。全局配置数据,数据量少,更新频率低,但是全局唯一,需要支持任意地区的访问,传统的单机数据库或单地区部署数据库无法满足以上业务诉求。
以下图为例,用户将 TiDB 以跨中心的方式部署在三个数据中心,分别覆盖华北,华东和华南的用户群,让不同区域的用户可以就近访问本地数据。在以往的版本中,用户的确可以将以跨中心的方式部署 TiDB 集群,但无法将归属不同用户群的数据存放在不同的数据中心,只能按照热点和数据量均匀分布的逻辑将数据分散在不同中心。在高频访问的情况下,用户访问很可能会频繁跨越地域承受较高的延迟。
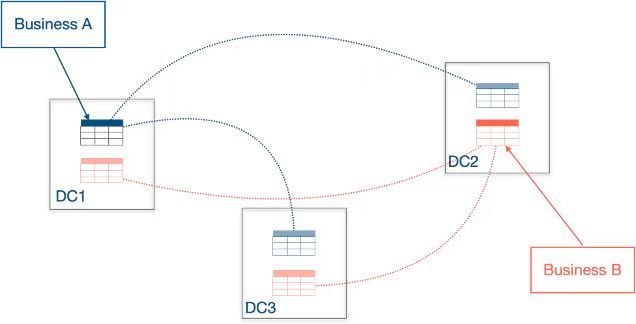
通过 Placement Rules In SQL 能力,你设置放置策略将区域数据的所有副本指定到特定区域的特定机房内,所有的数据存储,管理在本地区内完成,减少了数据跨地区复制延迟,降低流量成本。你需要做的仅仅是,为不同数据中心的节点打上标签,并创建对应的放置规则:
CREATE PLACEMENT POLICY east_cn CONSTRAINTS = "[+region=east_cn]"; CREATE PLACEMENT POLICY north_cn CONSTRAINTS = "[+region=north_cn]";并通过 SQL 语句控制数据的放置,这里以不同城市分区为例:
ALTER TABLE orders PARTITION p_hangzhou PLACEMENT POLICY = east_cn; ALTER TABLE orders PARTITION p_beijing PLACEMENT POLICY = north_cn;这样,归属不同城市的订单数据副本将会被「固定」在对应的数据中心。
假设你负责大型互联网企业的数据平台,内部业务有 2000 多种,相关业务采用一套或多套 MySQL 来管理,但是因为业务数量太多,MySQL 实例数接近 1000 个,日常的监控、诊断、版本升级、安全防护等工作对运维团队造成了巨大的压力,且随着业务规模越来越大,运维成本逐年上升。你希望通过减少数据库实例数量来减少运维管理成本,但是业务间的数据隔离、访问安全、数据调度的灵活性和管理成本成为你面临的严峻挑战。
借助 TiDB 6.0,通过数据放置规则的配置,你可以很容易灵活的集群共享规则,例如业务 A,B 共享资源,降低存储和管理成本,而业务 C 和 D 独占资源,提供最高的隔离性。由于多个业务共享一套 TiDB 集群,升级、打补丁、备份计划、扩缩容等日常运维管理频率可以大幅缩减,降低管理负担提升效率。
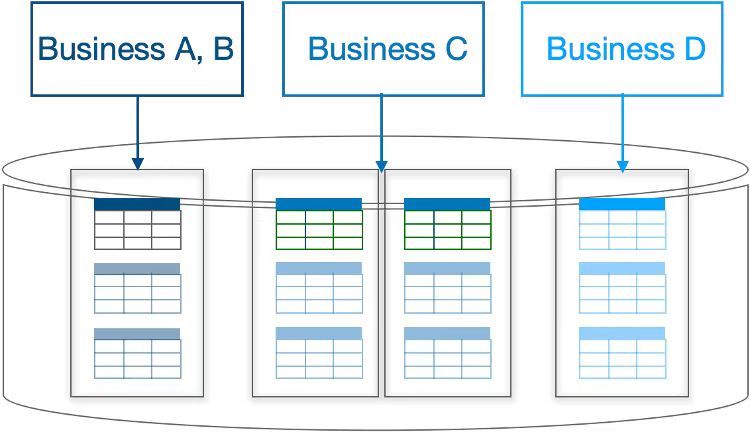
基于 SQL 接口的数据放置规则,你仅仅使用少数 TiDB 集群管理大量的 MySQL 实例,不同业务的数据放置到不同的 DB,并通过放置规则管理将不同 DB 下的数据调度到不同的硬件节点上,实现业务间数据的物理资源隔离,避免因资源争抢,硬件故障等问题造成的相互干扰。通过账号权限管理避免跨业务数据访问,提升数据质量和数据安全。在这种部署方式下,集群数量大大减小,原本的升级,监控告警设置等日常运维工作将大幅缩减,在资源隔离和性价比上达到平衡,大幅减少日常的 DBA 运维管理成本。
现在你是一个互联网架构师,希望通过 TiDB 构建本地多数据中心架构。通过数据放置规则管理,你得以将 Follower 副本调度到备中心,实现同城高可用。
CREATE PLACEMENT POLICY eastnwest PRIMARY_REGION="us-east-1" REGIONS="us-east-1,us-east-2,us-west-1" SCHEDULE="MAJORITY_IN_PRIMARY" FOLLOWERS=4; CREATE TABLE orders (order_id BIGINT PRIMARY KEY, cust_id BIGINT, prod_id BIGINT) PLACEMENT POLICY=eastnwest;与此同时,你让对于一致性和新鲜度不高的历史查询通过基于时间戳的方式读取( Stale Read ),这样避免了跨中心数据同步造成的访问延迟,同时也提高对从机房的硬件利用率。
SELECT * FROM orders WHERE order_id = 14325 AS OF TIMESTAMP 2022-03-01 16:45:26;TiDB 6.0 的 Placement Rules In SQL 是一个很有趣的功能:它暴露了以往用户无法控制的内部调度能力,并提供了方便的 SQL 接口。你可以通过它对分区 / 表 / 库不同级别的数据进行基于标签的自由放置,这开启了诸多以往不可能实现的场景。除了上述可能性,我们也期望和你一起探索更多有趣的应用。
查看 TiDB 6.0.0 Release Notes ,立即 下载试用 ,开启 TiDB 6.0.0 企业级云数据库之旅。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

