
黄东旭解析 TiDB 的核心优势
706
2023-04-18
TiDB 的一键水平伸缩特性,帮助用户告别了分库分表查询和运维带来的复杂度,但是在从分库分表方案切换到 TiDB 的过程中,这个复杂度转移到了数据迁移流程里。TiDB DM 工具为用户提供了分库分表合并迁移功能。
本篇文章将介绍 DM 核心处理单元 Sync,内容包含 binlog 读取、过滤、路由、转换,优化以及执行等逻辑。本文仅描述 DML 的处理逻辑,DDL 相关内容可参考 《DM 分库分表 DDL “乐观协调” 模式介绍》 、 《DM 分库分表 DDL “悲观协调” 模式介绍》 。
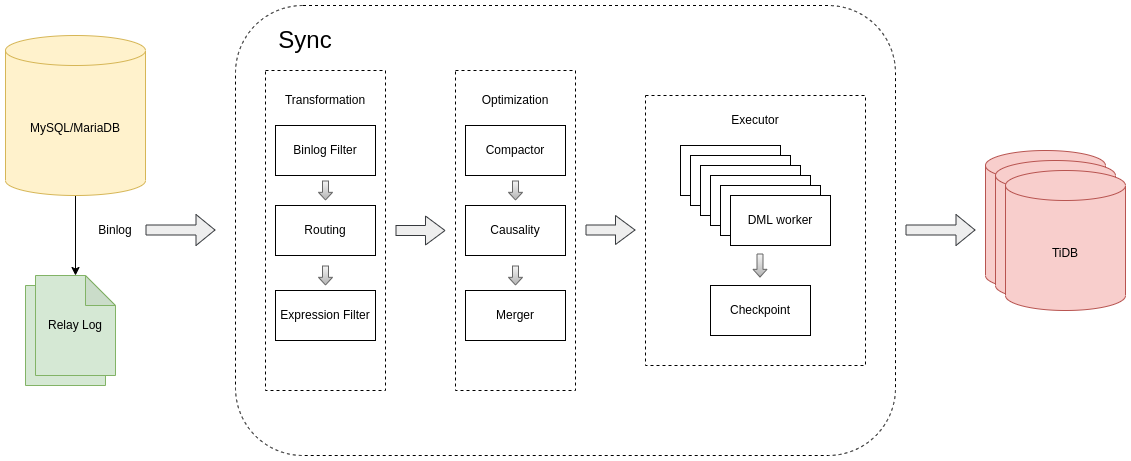
从上图可以大致了解到 Binlog replication 的逻辑处理流程
1.从 MySQL/MariaDB 或者 relay log 读取 binlog events
2.对 binlog events 进行处理转换
Binlog Filter:根据 binlog 表达式过滤 binlog,通过 filters 配置 Routing:根据“库/表”路由规则对“库/表”名进行转换,通过 routes 配置 Expression Filter: 根据 SQL 表达式过滤 binlog,通过 expression-filter 配置3.对 DML 执行进行优化
Compactor:将对同一条记录(主键相同)的多个操作合并成一个操作,通过 syncer.compact 开启 Causality:将不同记录(主键不同)进行冲突检测,分发到不同的 group 并发处理 Merger:将多条 binlog 合并成一条 DML,通过 syncer.multiple-rows 开启4.将 DML 执行到下游
5.定期保存 binlog position/gtid 到 checkpoint
DM 根据上游 binlog 记录,捕获记录的变更并同步到下游,当上游对同一条记录短时间内做了多次变更时(insert/update/delete),DM 可以通过 Compactor 将这些变更压缩成一次变更,减少下游压力,提升吞吐,如
INSERT + UPDATE => INSERT INSERT + DELETE => DELETE UPDATE + UPDATE => UPDATE UPDATE + DELETE => DELETE DELETE + INSERT => UPDATEMySQL binlog 顺序同步模型要求按照 binlog 顺序一个一个来同步 binlog event,这样的顺序同步势必不能满足高 QPS 低同步延迟的同步需求,并且不是所有的 binlog 涉及到的操作都存在冲突。
DM 采用冲突检测机制,鉴别出来需要顺序执行的 binlog,在确保这些 binlog 的顺序执行的基础上,最大程度地保持其他 binlog 的并发执行来满足性能方面的要求。
Causality 采用一种类似并查集的算法,对每一个 DML 进行分类,将相互关联的 DML 分为一组。具体算法可参考 TiDB Binlog 源码阅读系列文章(八)Loader Package 介绍#并行执行DML
MySQL binlog 协议,每条 binlog 对应一行数据的变更操作,DM 可以通过 Merger 将多条 binlog 合并成一条 DML 执行到下游,减少网络的交互,如
INSERT tb(a,b) VALUES(1,1); + INSERT tb(a,b) VALUES(2,2); = INSERT tb(a,b) VALUES(1,1),(2,2); UPDATE tb SET a=1, b=1 WHERE a=1; + UPDATE tb SET a=2, b=2 WHERE a=2; = INSERT tb(a,b) VALUES(1,1),(2,2) ON DUPLICATE UPDATE a=VALUES(a), b=VALUES(b) DELETE tb WHERE a=1 + DELETE tb WHERE a=2 = DELETE tb WHERE (a) IN (1),(2);DM 内嵌一个 schema tracker,用于记录上下游 schema 信息。当收到 DDL 时,DM 更新内部 schema tracker 的表结构。当收到 DML 时,DM 根据 schema tracker 的表结构生成对应的 DML,具体逻辑如下:
当启动全量加增量任务时,Sync 使用上游全量同步时 dump 出来的表结构作为上游的初始表结构 当启动增量任务时,由于 MySQL binlog 没有记录表结构信息,Sync 使用下游对应的表的表结构作为上游的初始表结构 由于用户上下游表结构可能不一致,如下游比上游多了额外的列,或者上下游主键不一致,为了保证数据同步的正确性,DM 记录下游对应表的主键和唯一键信息 生成 DML 时,DM 使用 schema tracker 中记录的上游表结构生成 DML 语句的列,使用 binlog 中记录的列值生成 DML 语句的列值,使用 schema tracker 中记录的下游主键/唯一键生成 DML 语句中的 WHERE 条件。当表结构无唯一键时,DM 会使用 binlog 中记录的所有列值作为 WHERE 条件。上文中我们知道 Causality 可以通过冲突检测算法将 binlog 分成多个 group 并发地执行到下游,DM 通过设置 worker-count,控制并发的数量。当下游 TiDB 的 CPU 占用不高时,增大并发的数量可以有效的提高数据同步的吞吐量。通过 syncer.worker-count 配置
DM 将多条 DML 攒到一个事务中执行到下游,当 DML Worker 收到 DML 时,将其加入到缓存中,当缓存中 DML 数量达到预定阈值时,或者较长时间没有收到 DML 时,将缓存中的 DML 执行到下游。通过 syncer.batch 配置
从上面的流程图中,我们可以看到 DML 执行和 checkpoint 更新不是原子的。DM 中,checkpoint 默认每 30s 更新一次。同时,由于存在多个 DML worker 进程,checkpoint 进程计算所有 DML worker 同步进度最晚的 binlog 位点,将该位点作为当前同步的 checkpoint,所有早于此位点的 binlog,都已保证被成功地执行到下游。
从上面的描述我们可以看到,DM 实际上是按照“行级别”进行数据同步的,上游一个事务在 DM 中会被拆成多行,分发到不同的 DML Worker 中并发执行。当 DM 同步任务报错暂停,或者用户手动暂停任务时,下游可能停留在一个中间状态,即上游一个事务中的 DML 语句,可能一部分同步到下游,一部分没有,下游处于一个不一致的状态。为了尽可能使任务暂停时,下游处于一致状态,DM 在 v5.3.0 后,在任务暂停时会等待上游事务全部同步到下游后,才真正暂停任务,这个等待时间为 10s,如果上游一个事务在 10s 内还未全部同步到下游,那么下游仍然可能处于不一致的状态。
在上面的执行逻辑章节,我们可以发现 DML 执行 和写 checkpoint 操作并不是同步的,并且写 checkpoint 操作和写下游数据也并不能保证原子性,当 DM 因为某些原因异常退出时,checkpoint 可能只记录到退出时刻之前的一个恢复点,因此当同步任务重启时,DM 可能会重复写入部分数据,也就是说,DM 实际上提供的是“至少一次处理”的逻辑(At-least-once processing),相同的数据可能会被处理一次以上。为了保证数据是可重入的,DM 在异常重启时会进入 safemode 模式。具体逻辑如下:
1.当 DM 任务正常暂停时,会将内存中所有的 DML 全部同步到下游,并刷新 checkpoint 。任务正常暂停后重启不会进入 safemode,因为 checkpoint 之前的数据全部都被同步到下游,checkpoint 之后的数据还未同步过,没有数据会被重复处理
2.当任务异常暂停时,DM 会先尝试将内存中所有的 DML 全部同步到下游,此时可能会失败(如下游数据冲突等),然后,DM 记录当前内存中从上游拉取到的最新的 binlog 的位点,记作 safemode_exit_point,将这个位点和 checkpoint 一起刷新到下游。当任务恢复后,可能存在以下情形
checkpoint == safemode_exit_point,这意味着 DM 暂停时所有的 DML 全部同步到下游,我们可以按照任务正常暂停时的处理方法,不用进入 safemode checkpoint < safemode_exit_point,这意味着 DM 暂停时,内存中的部分 DML 执行到下游时失败,所以 checkpoint 仍是一个较“老”的位点,这时,从 checkpoint 到 safemode_exit_point 这一段 binlog,都会开启 safemode 模式,因为它们可能已经被同步过一次了 safemode_exit_point 不存在,这意味着 DM 暂停时刷新 safemode_exit_point 的操作失败了,或者 DM 进程被强制结束了。此时 DM 无法具体判断哪些数据可能被重复处理,因此会在任务恢复后的两个 checkpoint 间隔中(默认为一分钟),开启 safemode,之后会关闭 safemode 正常同步Safemode 期间,为了保证数据可重入,DM 会进行如下转换
将上游 insert 语句,转换成 replace 语句 将上游 update 语句,转换成 delete + replace 语句从上面的描述,我们可以发现 DM 这种拆事务然后并发同步的逻辑引发了一些问题,比如下游可能停在一个不一致的状态,比如数据的同步顺序与上游不一致,比如可能导致数据重入(safemode 期间 replace 语句会有一定的性能损失,如果下游需要捕获数据变更(如 cdc),那么重复处理也不可接受)。
综上,我们正在考虑实现“精确一次处理”的逻辑,如果有兴趣加入我们的,可以来到 https://internals.tidb.io ,一起讨论。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

