
黄东旭解析 TiDB 的核心优势
738
2023-04-03
在企业遭遇的 IT 故障中,约有 30% 与数据库相关。当这些故障涉及到应用系统、网络环境、硬件设备时,恢复时间可能达到数小时,对业务连续性造成破坏,影响用户体验甚至营收。在复杂分布式系统场景下,如何提高数据库的可观测性,帮助运维人员快速诊断问题,优化故障处理流程一直是困扰着企业的一大难题。
没有 continuous profiling 的客户故障排查案例
19:15 新节点上线
19:15 - 19:32 上线的节点由于 OOM 反复重启,导致其他节点上 Snapshot 文件积累,节点状态开始异常
19:32 收到响应时间过长业务报警
19:56 客户联系 PingCAP 技术支持,反映情况如下:
集群响应延迟很高,一个 TiKV 节点加入集群后发生掉量,而后删除该节点,但其他 TiKV 节点出现 Disconnect Store 现象,同时发生大量 Leader 调度,集群响应延迟高,服务挂掉
20:00 PingCAP 技术支持上线排查
20:04 - 21:08 技术支持对多种指标进行排查,从 metrics 的 iotop 发现 raftstore 线程读 io 很高,通过监控发现有大量的 rocksdb snapshot 堆积,怀疑是 region snapshot 的生成导致的,建议用户删掉之前故障 TiKV 节点上的 pending peer,并重启集群。
20:10 ~ 20:30 技术支持同时对 profiling 信息排查,抓取火焰图,但因为抓取过程中出问题的函数没有运行,没有看到有用的信息。
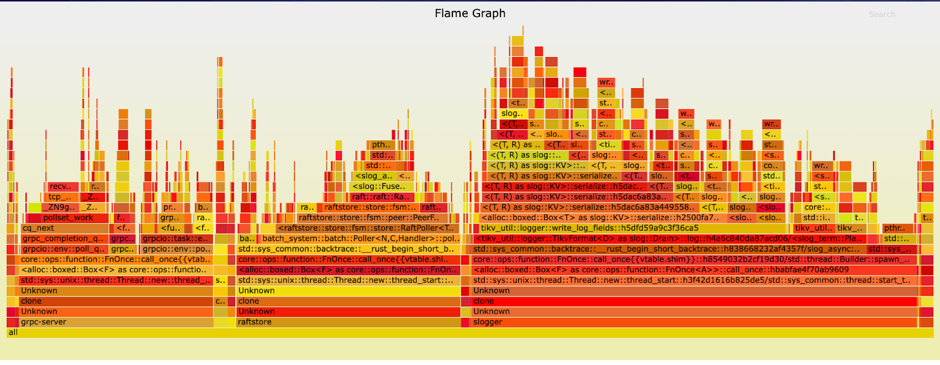
火焰图的查看方式:(源自: https://www.brendangregg.com/flamegraphs.html )
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。火焰图就是看顶层的哪个函数占据的宽度最大。只要有 **"平顶"**(plateaus),就表示该函数可能存在性能问题。颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
从以上查看方式可以发现,这次抓取到的火焰图并没有一个大的 “平顶”,所有函数的宽度(执行时间长)都是不会太大。在这个阶段,没能直接从火焰图发现性能瓶颈是令人失望的。这时候客户对于恢复业务已经比较着急。
21:10 通过删除 pod 的方式重启了某个 TiKV 节点之后,发现 io 并没有降下来。
21:10 - 21:50 客户继续尝试通过删除 pod 的方式重启 TiKV 节点。
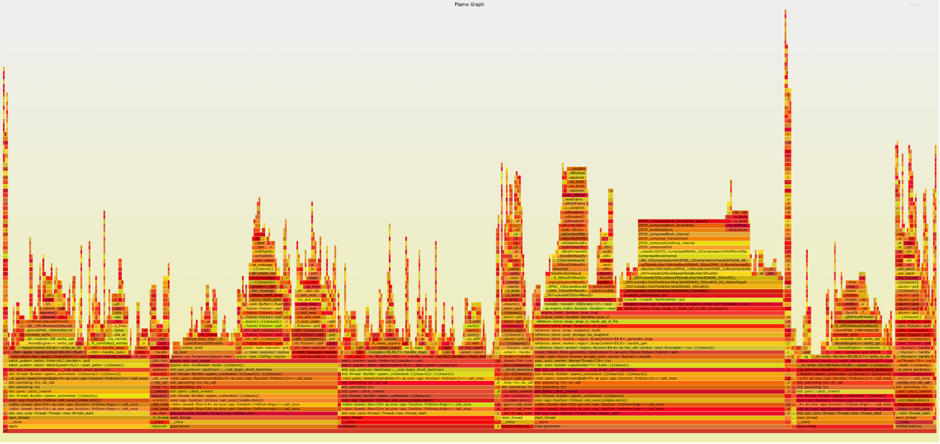
21:50 再次抓取火焰图,发现 raftstore :: store :: snap :: calc_checksum_and_size 函数处占用的大量的 CPU,确认根因。
 这次抓取到的火焰图发现一个明显的 “大平顶”,可以明显看到是 raftstore :: store :: snap :: calc_checksum_and_size 函数。这个函数占用了大量的 CPU 执行时长,可以确定整体性能瓶颈就在这里函数相关的功能。到这一步,我们确定了根因,并且也可以根据根因确定恢复方案。
这次抓取到的火焰图发现一个明显的 “大平顶”,可以明显看到是 raftstore :: store :: snap :: calc_checksum_and_size 函数。这个函数占用了大量的 CPU 执行时长,可以确定整体性能瓶颈就在这里函数相关的功能。到这一步,我们确定了根因,并且也可以根据根因确定恢复方案。
22:04 采取操作:停止 TiKV pod,删除流量大的 TiKV 节点 snap 文件夹下所有 gen 文件。目前逐渐恢复中。
22:25 业务放量,QPS 恢复原先水平,说明操作有效。
22:30 集群完全恢复
集群恢复耗时:19:56 - 22:30,共 2 小时 34 分(154 分)。 确认根因,提出有效操作耗时:19:56 - 22:04,共 2 小时 8 分(128 分)。
在这个案例中,如果我们能够有一个在故障前、中、后期,连续性地对集群进行性能分析的能力,我们就可以直接对比故障发生时刻和故障前的火焰图,快速发现占用 CPU 执行时间较多的函数,极大节约这个故障中发现问题根因的时间。因此,同样的案例,如果有 continuous profiling 功能:
19:15 新节点上线
19:15 - 19:32 上线的节点由于 OOM 反复重启,导致其他节点上 snapshot 文件积累,节点状态开始异常
19:32 收到响应时间过长业务报警
19:56 客户联系 PingCAP 技术支持,反映情况如下:
集群响应延迟很高,一个 TiKV 节点加入集群后发生掉量,而后删除该节点,但其他 TiKV 节点出现 Disconnect Store 现象,同时发生大量 Leader 调度,集群响应延迟高,服务挂掉
20:00 PingCAP 技术支持上线排查
20:04 - 20:40 技术支持对多种指标进行排查,从 metrics 的 iotop 发现 raftstore 线程读 io 很高,通过监控发现有大量的 rocksdb snapshot 堆积,怀疑是 region snapshot 的生成导致的
20:10 ~ 20:40 技术支持同时对 continuous profiling 信息排查,查看故障发生时刻的多个火焰图,与未发生故障的正常火焰图对比,发现 raftstore :: store :: snap :: calc_checksum_and_size 函数占用的大量的 CPU,确认根因
20:55 采取操作:停止 TiKV pod,删除流量大的 TiKV 节点 snap 文件夹下所有 gen 文件。目前逐渐恢复中
21:16 业务放量,QPS 恢复原先水平,说明操作有效
21:21 集群完全恢复
集群恢复(预期)耗时:19:56 ~ 21:21,共 1 小时 25 分(85 分),相比下降 44.8 %。 确认根因,提出有效操作(预期)耗时:19:56~20:55,共 59 分,相比下降 53.9 %。
可以看到该功能可以极大缩短确定根因时间,尽可能帮助客户挽回因性能故障造成的业务停摆损失。
在刚刚发布的 TiDB 5.3 版本中,PingCAP 率先在数据库领域推出 “持续性能分析”(Continuous Profiling)功能(目前为实验特性),跨越分布式系统可观测性的鸿沟,为用户带来数据库源码水平的性能洞察,彻底解答每一个数据库问题。
“持续性能分析” 是一种从系统调用层面解读资源开销的方法。引入该方法后,TiDB 提供了数据库源码水平的性能洞察,通过火焰图的形式帮助研发、运维人员定位性能问题的根因,无论过去现在皆可回溯。
持续性能分析以低于 0.5% 的性能损耗实现了对数据库内部运行状态持续打快照(类似 CT 扫描),以火焰图的形式从系统调用层面解读资源开销,让原本黑盒的数据库变成白盒。在 TiDB Dashboard 上一键开启持续性能分析后,运维人员可以方便快速地定位性能问题的根因。
当数据库意外宕机时,可降低至少 50% 诊断时间
在互联网行业的一个案例中,当客户集群出现报警业务受影响时,因缺少数据库连续性能分析结果,运维人员难以发现故障根因,耗费 3 小时才定位问题恢复集群。如果使用 TiDB 的持续性能分析功能,运维人员可比对日常和故障时刻的分析结果,仅需 20 分钟就可恢复业务,极大减少损失。
在日常运行中,可提供集群巡检和性能分析服务,保障集群持续稳定运行
持续性能分析是 TiDB 集群巡检服务的关键,为商业客户提供了集群巡检和巡检结果数据上报。客户可以自行发现和定位潜在风险,执行优化建议,保证每个集群持续稳定运行。
在数据库选型时,提供更高效的业务匹配
在进行数据库选型时,企业往往需要在短时间内完成功能验证、性能验证的流程。持续性能分析功能能够协助企业更直观地发现性能瓶颈,快速进行多轮优化,确保数据库与企业的业务特征适配,提高数据库的选型效率。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

