

黄东旭解析 TiDB 的核心优势
876
2023-04-03
DM 支持在线执行分库分表的 DDL 语句(通称 Sharding DDL),我们介绍了悲观模式,即当上游一个分表执行某一 DDL 后,这个分表的迁移会暂停,等待其他所有分表都执行了同样的 DDL 才在下游执行该 DDL 并继续数据迁移。
悲观协调模式的优点是可以保证迁移到下游的数据不会出错,并且能兼容大部分的 DDL 语句,缺点是会暂停数据迁移而不利于对上游进行灰度变更、并显著地增加增量数据复制的延迟。有些客户可能会花数个月在单一分片执行 DDL,满意后才会更改其他分片的结构。在悲观同步的设定下,用来测试的分片的 DML 事件会大量积压,在恢复同步后无法正常运作。与此同时,悲观模式还要求所有分片必须以相同的顺序执行 DDL,否则会导致任务报错暂停。
为此,DM 提供新的乐观协调模式,在一个分表上执行的 DDL,自动修改成兼容其他分表的 DDL 语句后立即应用到下游,不会阻挡任何分表执行的 DML 的迁移。乐观协调模式适用于上游灰度更新、发布的场景,或者是对上游数据库表结构变更过程中同步延迟比较敏感的场景。
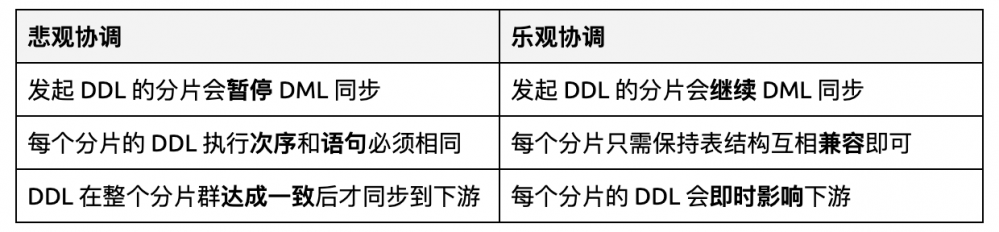
DM worker 的所有 DML 会直接同步到下游(出错时例外)。
DM worker 内嵌了一个小型 TiDB(通称 schema tracker),用来记录各个上游分表的表结构,当接收到来自上游的 DDL 后,会根据 schema tracker 里 DDL 的执行结果,把更新后的表结构转送给 DM master。DM master 将收到的不同分片的表结构合并成可兼容所有分片的 DML 的合成结构,即不同分片表结构的并集(此过程类似于 SQL 语句中的 JOIN 语句),然后根据合成的表结构和 DM worker 发来的表结构的不同处得到对应的 DDL 语句(即合成的表结构与原表结构的差集),同步到下游。
乐观 DDL 表结构合并的规则简单来说就是对列属性定义了一个偏序关系,对不同表的同一列进行排序,选择该偏序关系中的极大元。对于不可比较的列,则返回错误
null < not null
no default < default(x)
varchar(x) < varchar(y), where x< y
utf8 < utf8mb4
char < varchar
tinyint < smallint < mediumint < bigint
…
对于被不存在或者被删除的列,我们把它定为最小的列
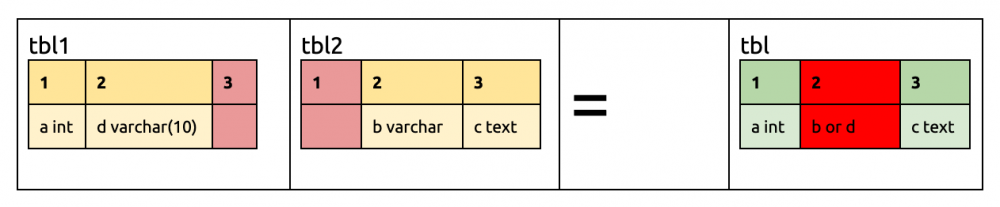
如初始时表结构是相同的。
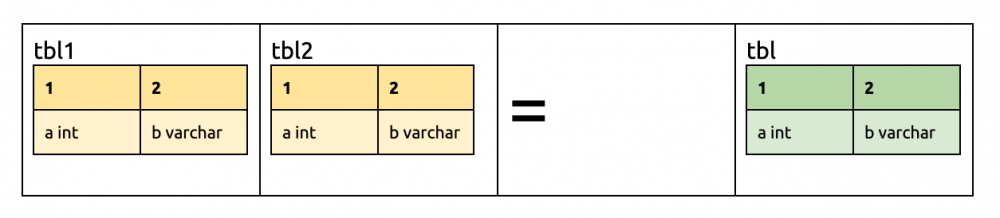
tbl2 添加第三列。前两列相同;tbl1 的第三列为空,所以保留 tbl2 的第三列。
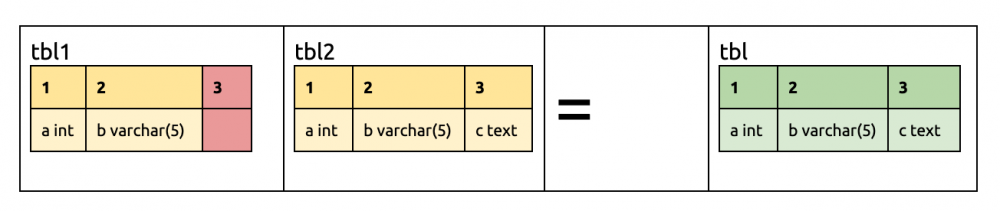
tbl2 删除第一列。第二列相同;tbl2 的第一列为空,所以保留 tbl1 的第一列。tbl1 的第三列为空,所以保留 tbl2 的第三列

tbl1 将第二列改为 varchar(10),由于 varchar(5) < varchar(10),所以保留 tbl1 的第二列

tbl1 重命名第二列。现在 tbl1 和 tbl2 的第二列名字不一样,无法比较,DM 无法确定最终的表结构,所以任务会报错
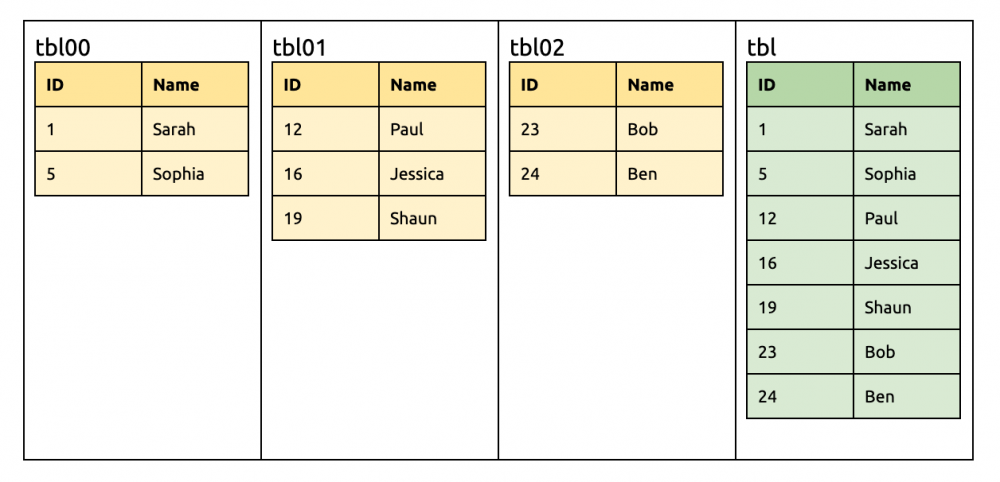
三个分片合并同步到 TiDB
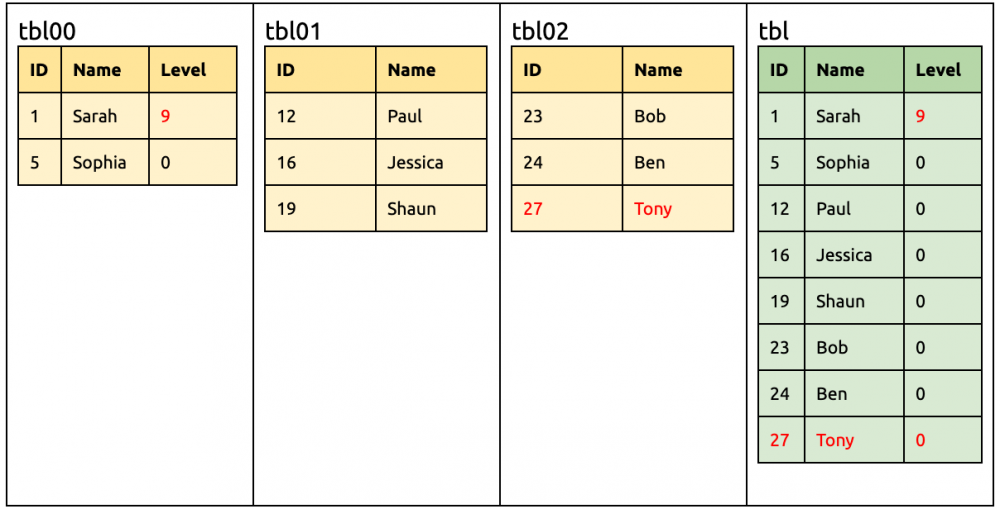
① 在上游增加一列 Level。 alter table tbl00add column Levelint unsigned not null;
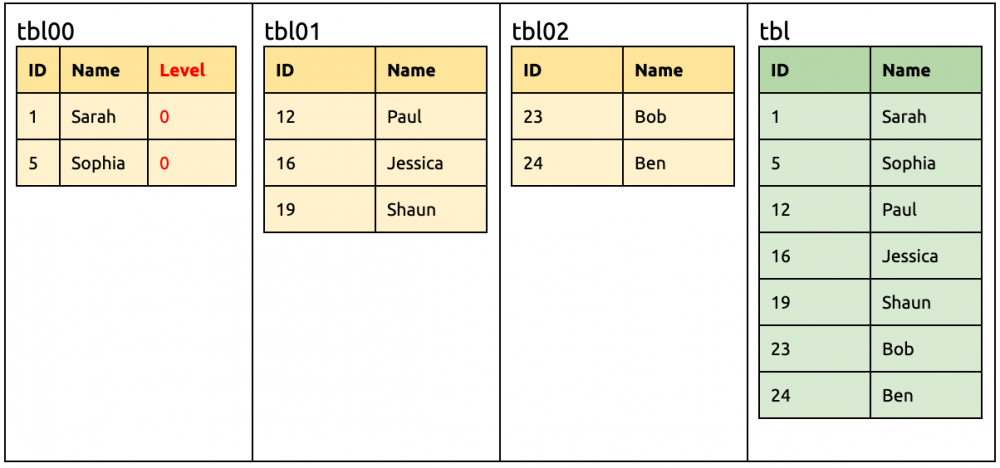
tbl00, tbl01, tbl02 的并集 tblMerge 是 {ID,NAME,Level} tblMerge 和 tbl 的差集是 {Level},所以 DDL 是 add column Level
此时下游 TiDB 要准备接受来自 tbl00 有 Level 的 DML、以及来自 tbl01 和 tbl02 没有 Level 的 DML,所以同步到下游时,自动改写成指定默认值的形式。 alter table tbladd column Levelint unsigned not null default 0;
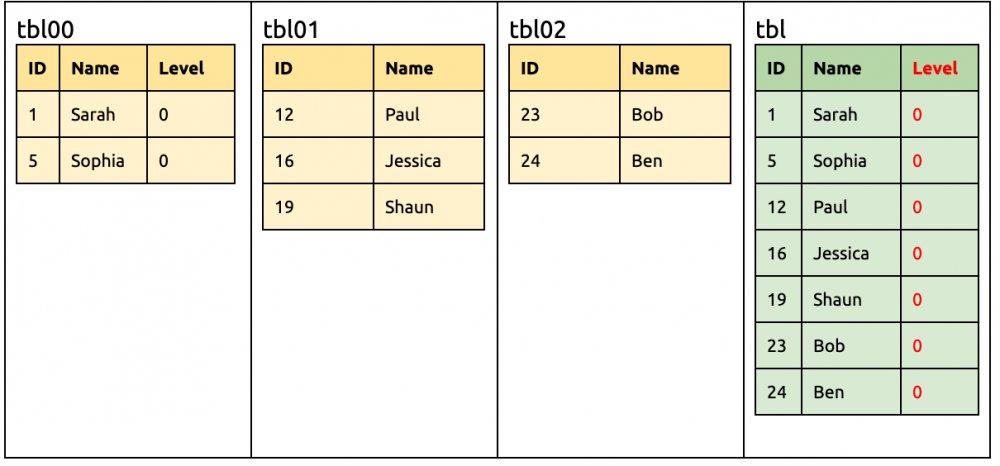
这时候各种 DML 毋需修改都可以同步到下游。 update tbl00set Level= 9 where ID= 1; insert into tbl02(ID, Name) values (27, 'Tony');
② 在 tbl01 同样增加一列 Level。 alter table tbl01add column Levelint unsigned not null;
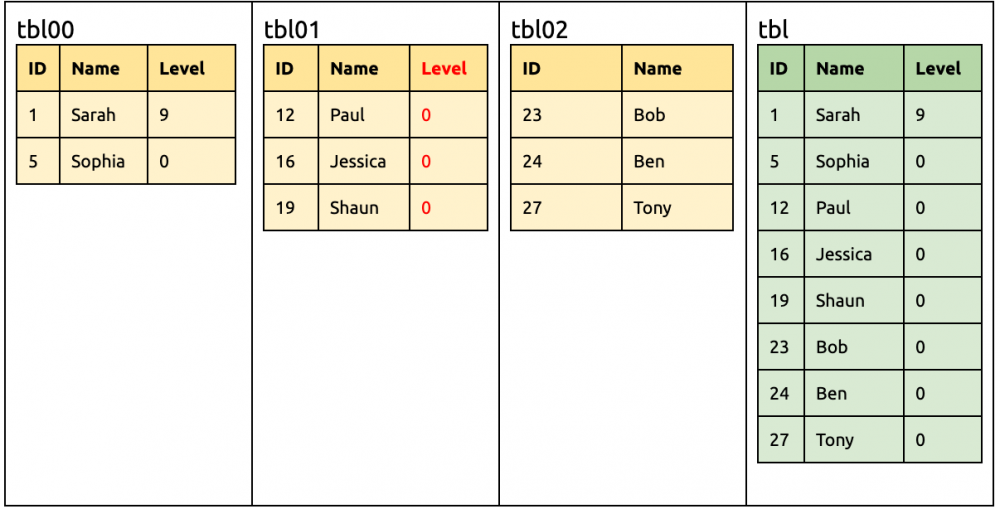
tbl00, tbl01, tbl02 的并集 tblMerge 是 {ID,NAME,Level} tblMerge 和 tbl 的差集是 {},所以 DDL 为空
此时下游已经有相同的 Level 列了,所以 DM master 比较之后不做任何动作。
③ 在 tbl01 刪除一列 Name。 alter table tbl01drop column Name;
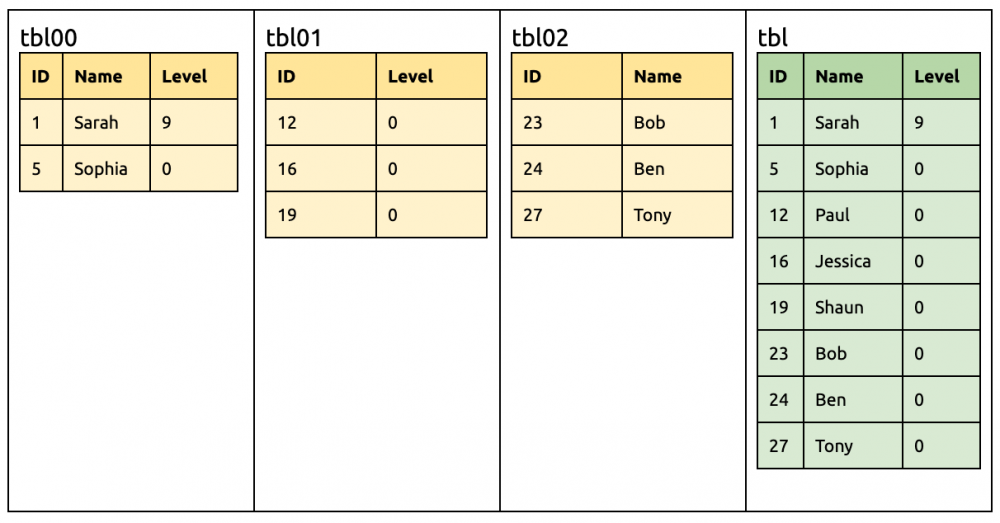
tbl00, tbl01, tbl02 的并集 tblMerge 是 {ID,NAME,Level} tblMerge 和 tbl 的差集是 {Level},所以 DDL 为空
此时下游仍需要接收来自 tbl00 和 tbl02 含 Name 的 DMLs,故不立删之,而是为这列也补上一个默认值。 alter table tblalter column Nameset default “”;
同样,各种 DML 仍可直接同步到下游。 insert into tbl01(ID, Level) values (15, 7); update tbl00set Level= 5 where ID= 5;
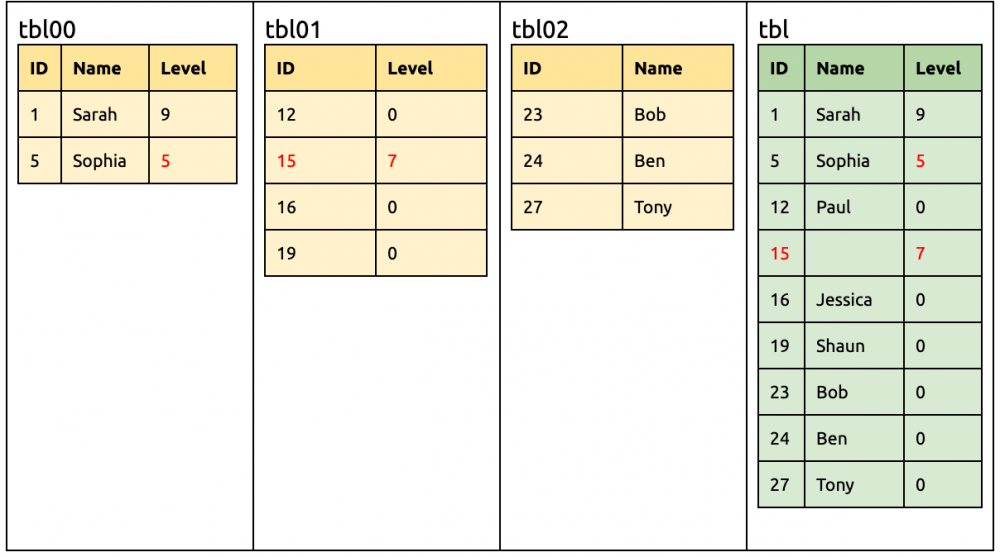
④ 在 tbl02 增加一列 Level。 tbl00, tbl01, tbl02 的并集 tblMerge 是 {ID,NAME,Level} tblMerge 和 tbl 的差集是 {Level},所以 DDL 为空 alter table tbl02add column Levelint unsigned not null;
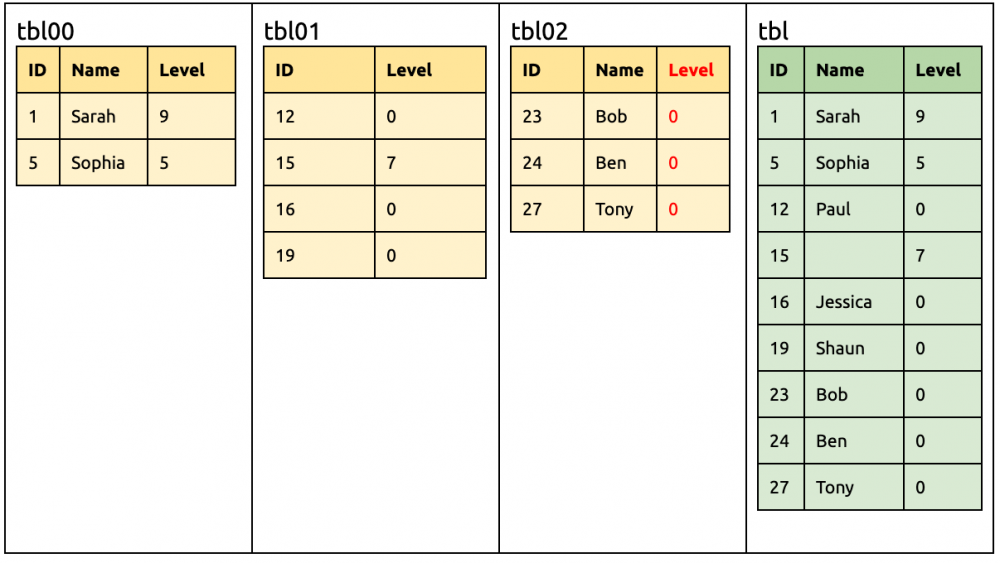
此时所有分片都已有 Level 列,所以可以把作为兼容的默认值去掉。 alter table tblalter column Leveldrop default;
⑤⑥ 在 tbl00 和 tbl02 各刪除一列 Name。 alter table tbl00drop column Name; alter table tbl02drop column Name;
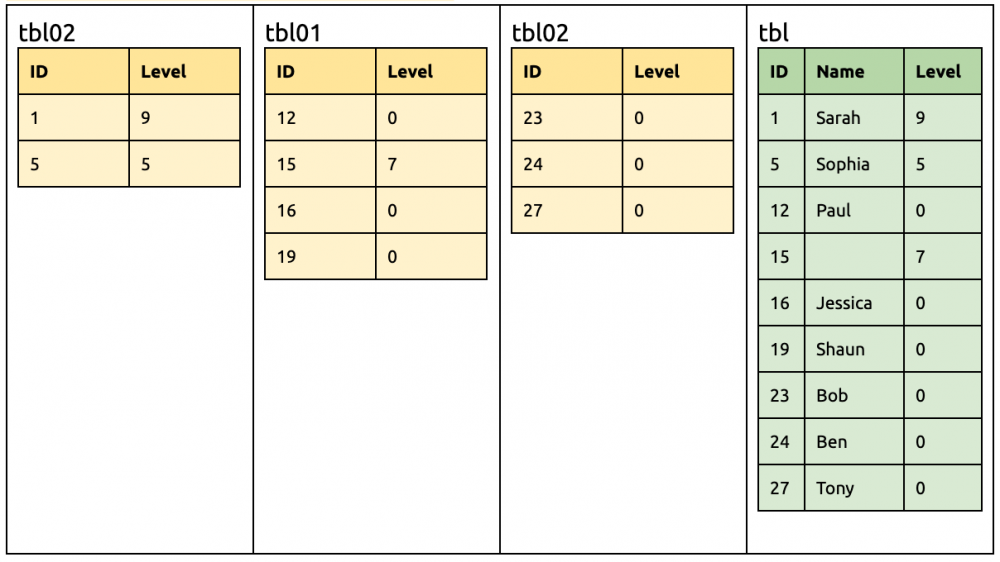
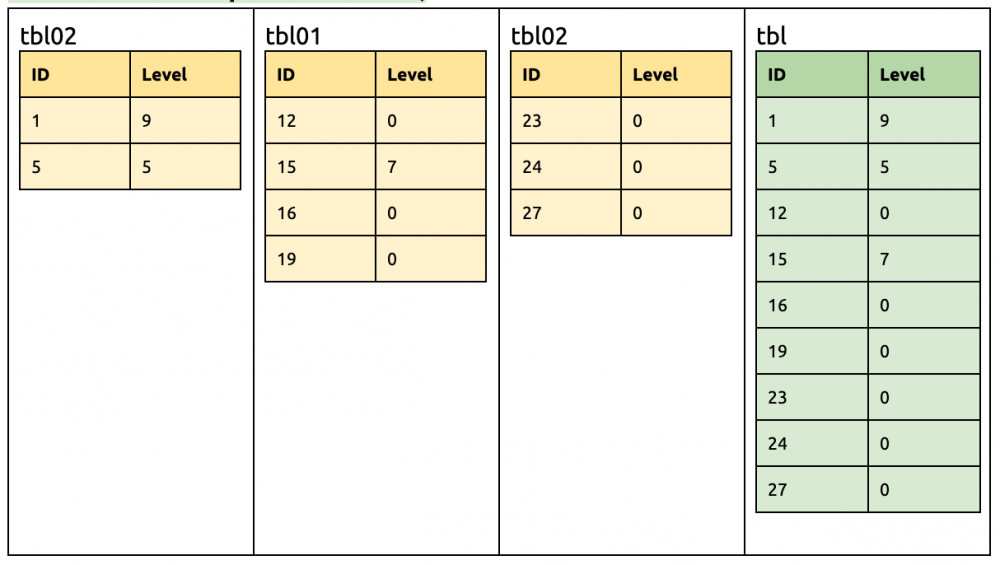
tbl00, tbl01, tbl02 的并集 tblMerge 是 {ID,Level} tblMerge 和 tbl 的差集是 -{Name},此差集是有符号的,所以 DDL 是 drop column Name
到此步 Name 列也从所有分片消失了,所以可以安全从下游移除。 alter table tbldrop column Name;
使用“乐观协调”模式有一定的风险,需要严格遵照以下方针:
执行每个批次的 DDL 前和后,要确保每个分表的结构达成一致。
进行灰度 DDL 时,最好只集中在一个分表上测试。
灰度完成后,在其他分表上尽量以最简单直接的 DDL 迁移到最终的 schema,而不要重新执行灰度测试中对或错的每一步。
例如:在分表执行过 ADD COLUMN A INT; DROP COLUMN A; ADD COLUMN A FLOAT;,在其他分表直接执行 ADD COLUMN A FLOAT 即可,不需要三条 DDL 都执行一遍。
执行 DDL 时要注意观察 DM 迁移状态。当迁移报错时,需要判断这个批次的 DDL 是否会造成数据不一致。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

