
黄东旭解析 TiDB 的核心优势
755
2023-10-30
一、集群节点的弹性扩缩
弹性伸缩主要有三个维度:
HPA,根据利用率,自动伸缩 Pod 数量
VPA,根据历史数据,自动设置 Pod 的 Request、Limit
CA,根据使用率,自动伸缩 Node 数量
本篇主要讨论的是节点扩缩容部分。
1. 自动扩缩容组件 autoscaler
autoscaler 是 Kubernetes 社区维护的项目。目前 autoscaler 组件已经提供有 VPA、CA 的伸缩能力。EKS、CCE、ACK、TKE 等主流厂商,都是依赖此组件进行 CA 弹性扩容。没有找到官方数据,但和同事交流时反馈,大约都需要 2-3 分钟完成 CA 扩容。
1.1 VPA 垂直扩缩容
与 HPA 类似,需要为 Deployment 创建一个 VPA 对象。
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1" kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"1.2.3.4.5.6.7.8.9.10.11.
VPA 与 HPA 都依赖于 Metrics-server 获取监控指标数据。autoscaler 的 VPA 内置了多种资源设置推荐器,同时对资源设置也可以进行约束。
值得注意的是 VPA 设置的资源值可能会超过命名空间下 limit ranges 的约束。
另外,VPA 与 HPA 不要同时使用。这两种方式有冲突,Pod 数量水平扩缩容和 Pod Limit 垂直扩缩容可能被同时触发。
1.2 CA 节点扩缩容
触发条件:
扩容,节点无法满足 Pod Request 要求而处于 Pending 状态
缩容,节点低负载,并且节点上的 Pod 能移到其他节点
支持厂商:
alicloud
aws
azure
baiducloud
gce
huaweicloud
linode
tencentcloud
...
很多厂商都提供 Provider 给组件,autoscaler 采用定期检测的方式,触发厂商扩缩容的接口动作。另外,CA 与厂商提供的 Node 垂直扩缩容不要同时使用。水平伸缩和垂直伸缩,需要找到一个平衡点,才能协同工作。
2. 云厂托管集群的弹性伸缩EKS、CCE、ACK、TKE 无一例外都是采用 autoscaler 组件结合自身 IaaS 服务实现节点的弹性伸缩。
由于底层都是采用 autoscaler 组件,在产品层面的呈现也会有所体现。以 EKS 为例,如下图:![WKBK{4GZHK%]7[]H$WFZL@4.png](https://cn.pingcap.com/article/zb_users/upload/2023/10/202310301698646257589200.png)
EKS 集群,具有若干节点组,每个节点组构成一个弹性伸缩的单元。如下图,节点组最少有 1 个节点,最多有 7 个节点:
![G{DX]K{P}ZNXHRCGV70)IGY.png](https://cn.pingcap.com/article/zb_users/upload/2023/10/202310301698646301445845.png)
EKS 的节点弹性是针对节点组的,同一个节点组下的节点具有相同的机器配置、污点、标签、主机启动模板。当 EKS 判断需要进行节点扩容时,会结合节点组允许的最大节点数,进行扩容。这样也保障扩容出来的节点已经打上正确的污点和标签,能够直接被 Kubernetes 调度器使用。
另外,节点组的概念,在产品和使用层面还可以包装成超级节点。只要节点数量的上限足够大,一个节点组就能提供超大的计算和内存资源池。
3. 节点储备策略
根据使用云厂的程度,可以将集群分为三类:
完全托管,无法直接管理集群内的任一主机,只能使用
半托管,无法管理 master 节点,云厂维护控制面
非托管,基于云厂 IaaS 自己部署的集群,完全自主控制
完全托管的集群,云厂会提供扩缩容的功能。下面主要讨论的是半托管和非托管的集群。
3.1 冷备
需要新节点时,再申请全新机器,初始化配置。
优势:
成本低,按需申请新节点
适配性好,不用考虑集群版本,按需安装依赖
操作简单,使用安装工具提供的能力,通常能够顺利完整扩容
不用考虑可用区、防火墙等问题
缺点:
速度慢,通常得 10 分钟以上,如果依赖源慢,可能需要更长时间
无法标准化,维护的集群不是使用一个工具安装的,或者需要自行封装 Kubeadm
3.2 热备
创建一个热资源池,保持一定的资源数。当需要主机资源时,直接添加到集群。
优势:
速度快
缺点:
成本高,每个集群版本都需要储备节点,1.16、1.20、1.21 等
热备池复杂,不同 IDC、不同 Region、不同 AZ 的节点,网络、防火墙可能不通,导致热备池复杂化
3.3 半热备
创建一个区域化的热备池,开启机器,仅安装 containerd、chrony、conntrack 等基础依赖包,但不要安装 Kubelet 等与集群版本相关的依赖。同时,提前放开储备区域对资源池的防火墙,还需要一个控制器维护热备池的主机数量。
优点:
成本、效率折中
缺点:
防火墙会比较开放,可能引入安全问题。如果考虑安全问题,成本又上升了
二、***-X Operator 之弹性扩缩容
背景
分布式系统通常都比较关注高可用和扩展性,云上的系统都以能提供良好的弹性扩缩能力著称。作为云原生分布式关系型数据库系统,***-X 同样提供了极致的弹性扩缩容能力。当用户使用 ***-X 集群遇到业务高峰、计算能力瓶颈、存储限制时,可以通过弹性扩容快速解决;当业务高峰过去,多余的计算资源可以通过快速缩容来进行释放。
在公有云上,我们已经可以在控制台上使用这项能力。控制台的操作背后涉及到了复杂的云上资源调度、数据迁移、计费变更等工作,细节之处不为旁人所知,现在我们将这项能力完整地迁移到了 ***-X Operator之上。本文将主要介绍如何在 Kubernetes 上,通过 ***-X Operator 实现 ***-X 数据库集群的弹性扩缩容。
弹性扩缩容
数据库集群结构
在介绍弹性扩缩容的原理之前,我们先回顾一下 ***-X 集群的整体结构,如下所示:
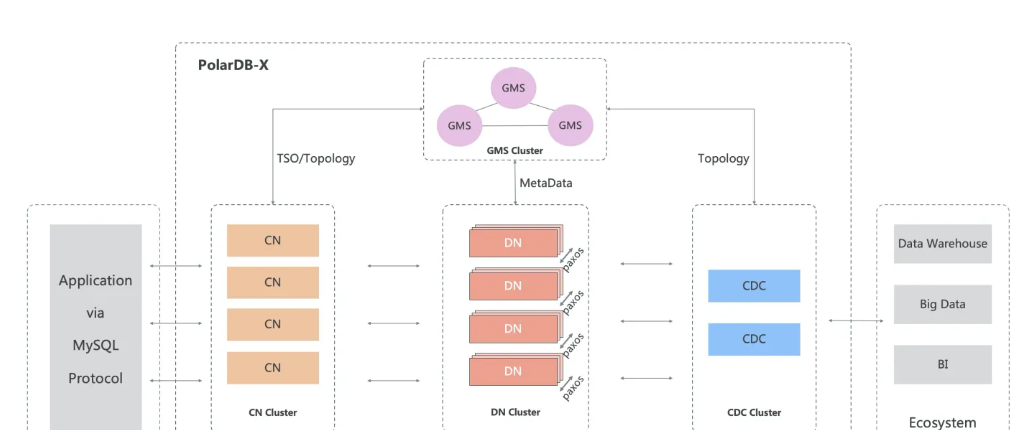
其中数据库集群核心结构有 4 个主要组件:
GMS (Global Meta Service),全局元数据服务,负责存放集群的所有元数据
CN(Compute Node),计算节点,负责处理用户流量(SQL)
DN(Data Node),数据节点,负责数据的存储和本地数据的部分计算
CDC(Change Data Capture Node),日志节点,负责消费并整合所有数据节点的 binlog 并生成全局的 binlog
由此可知,GMS 和 DN 是有状态的服务,而 CN 和 CDC 是无状态的服务。因此在 Kubernetes(***-X Operator)中,CN 和 CDC 的容器(Pod)都是组织在一组 Deployment 之下,而 GMS 和 DN 的则是在自定义资源 XStore 之下。整体结构如下图所示:
![BSR6HRCP[@1YEH8EMC90P]D.png](https://cn.pingcap.com/article/zb_users/upload/2023/10/202310301698646568186504.png)
扩缩容原理
从组件上,我们可以将 ***-X 集群的扩缩容能力简单拆分为以下 3 种:
增加、减少 CN 的节点,以增加或缩减计算能力
增加、减少 DN 的节点,以增加或缩减存储能力
增加、减少 CDC 的节点,以增加或缩减日志处理能力
这里我们暂时不考虑规格的变更(升降配),只考虑节点数量的变更。结合上文对集群结构的描述,实际上我们可以更进一步分类为对无状态节点的扩缩容和对存储节点的扩缩容,我们在下文会依次进行讨论。不过首先我们需要让 operator 知道,什么时候进行扩缩容?
扩缩容操作和检测
Kubernetes 提供的交互方式是所谓声明式 API,也就是用户声明一个期望的状态,让 Kubernetes 内部系统去创建并维护这样的状态,因此 ***-X Operator 在设计的时候也遵循了这种规范。通过将 ***-X 集群的期望状态定义为自定义资源 ***XCluster 的 spec,我们就可以向 Kubernetes 声明一个分布式数据库集群:
# test.yamlapiVersion: polardbx.aliyun.com/v1kind: ***XClustermetadata: name: testspec: topology: nodes: cn: replicas: 2 dn: replicas: 2 cdc: replicas: 2
上面这样一个 yaml 声明了一个名为 test 的 ***-X 数据库集群,它拥有 2 个 CN 节点、2 个 DN 节点和 2 个 CDC 节点。当用户使用 kubectl 将该 yaml 应用到 Kubernetes 集群时,operator 会接收到通知并进行创建和维护工作,这个过程称为 reconcile loop。Operator 的工作模式也被称为 Operator Pattern,它的过程是通过观测 - 调整 -观测的循环来不断逼近或达成用户描述的期望状态。
# 创建 test 集群$ kubectl apply -f test.yaml
polardbxcluster.polardbx.aliyun.com/test created
// controller-runtime 提供的 reconcile loop 框架type Reconciler interface {
// Reconciler performs a full reconciliation for the object referred to by the Request.
// The Controller will requeue the Request to be processed again if an error is non-nil or
// Result.Requeue is true, otherwise upon completion it will remove the work from the queue.
Reconcile(context.Context, Request) (Result, error)}
假如用户此时想要增加 1 个上述 ***-X 集群的 CN 节点,显然在声明式 API 的逻辑下,我们只需要修改期望的状态 -- 把 CN 的 replicas 改成 3。
$ kubectl patch polardbxcluster test --type merge --patch '{"spec":{"topology":{"nodes":{"cn":{"replicas":3}}}}}'polardbxcluster.polardbx.aliyun.com/test patched
此时 operator 会收到通知说 ***XCluster 资源下有个名为 test 的对象有变化,需要看看。因为 reconcilation 的不仅仅是由上述扩缩容的 spec 变化带来的,还有可能是因为 status 的变化或是类似 Deployment 这样的子资源的变化触发的,所以 operator 需要判断当前需要做什么。回到扩缩容的变化,它一定是由 .spec.topology 中的变化引起的,所以我们可以对比前后的 topology 是否变更来判断。***-X Operator 选择将之前确认的 topology 存放到对象的 status 字段下,从而进行拓扑变更(升降配、扩缩容、静态配置变更)的检测。
可以想到,不是每一次 reconcile 都需要进行检测的,例如用户只是修改了下 label 或者加了个 annotation。Kubernetes 已经考虑到了这个事情:每一个对象都有 .metadata.generation 字段,它是一个单调递增的字段。每当对象的 .spec 段发生变化时,.metadata.generation 都会加 1。因此 operator 可以记录当前观察到的对象的 generation,并记录到 status 中,从而判断当前已经看到的 spec 是否已经有变化。Generation 的应用在 Kubernetes 中非常常见,例如 Deployment 的控制器就使用 generation 作为是否需要 rollout 的依据之一。
至此我们已经有一个完整的扩缩容变更的检测方法:
func ShouldScale(pxc *polardbxv1.***XCluster) bool {
// If generation not changed, then there's no spec change. observedGeneration := pxc.Status.ObservedGeneration
currentGeneration := pxc.Generation
if currentGeneration == observedGeneration {
return false
}
// If topology changes and indicates there're differences on replicas, // then scaling is going to happen. topologySnapshot := pxc.Status.Snapshot.Topology
topology := &pxc.Spec.Topology
return IsReplicasChanged(topology, topologySnapshot)}
不过,实现中 ***-X Operator 将升降配和扩缩容的判断和流程放在一起了。本文还是主要关注在扩缩容之上。
无状态组件 CN、CDC
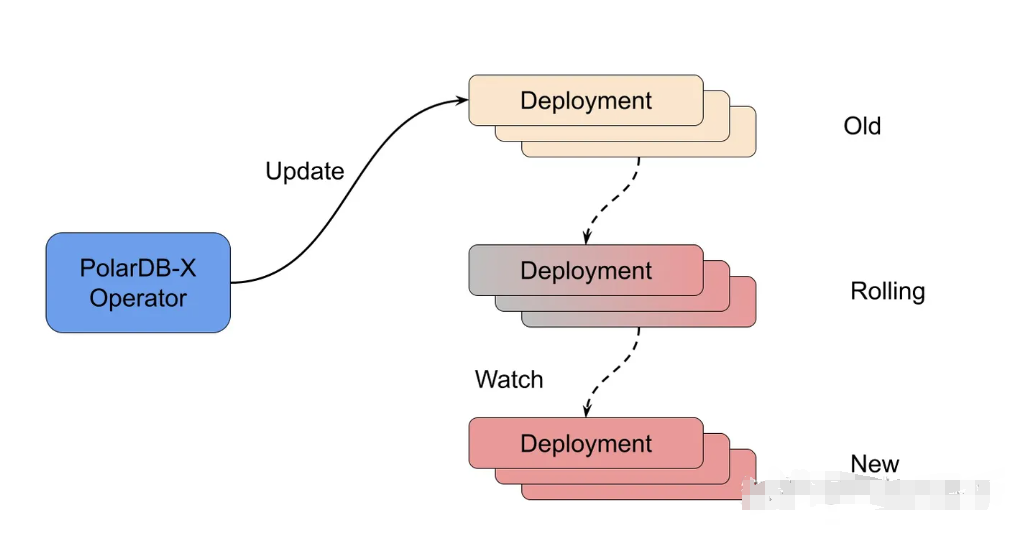
首先介绍如何对无状态组件进行扩缩容。Kubernetes 提供的 Deployment 本身是对多副本无状态应用的非常好的一个封装,***-X Operator 的相关能力也是基于它实现的。
当检测到需要进行 CN、CDC 组件的扩缩容时,operator 会根据当前 ***XCluster 对 CN、CDC 的描述重新构建相应的 Deployment 组,并将其应用到 Kubernetes 中,剩下的工作交给 Deployment 的控制器完成就可以,operator 只需要等待它们完成(rolled out)。
无状态组件的变更不会带来存储迁移的问题,因此 operator 可以放心地进行。扩缩容中需要考虑到服务的可用性,尤其是 CN 节点,相关的控制策略可以在 ***XCluster 中定义,并由 operator 进行控制。与 Deployment 一样,***XCluster 目前支持自定义的 UpgradeStrategy 和 Recreate 两种策略,方便在不同的场景下选择。
有状态组件 DN
接下来是比较难啃的骨头 -- 有状态的数据节点的扩缩容。与上述无状态服务扩缩容不同,有状态应用的扩缩容涉及到状态(存储)的迁移,因此更为复杂。Kubernetes 中提供了 StatefulSet 用于管理有状态应用,但我们的场景并不适用 -- 每个 DN 都可能是一个小集群。虽然如此,StatefulSet 的控制逻辑还是起到了巨大的参考意义。
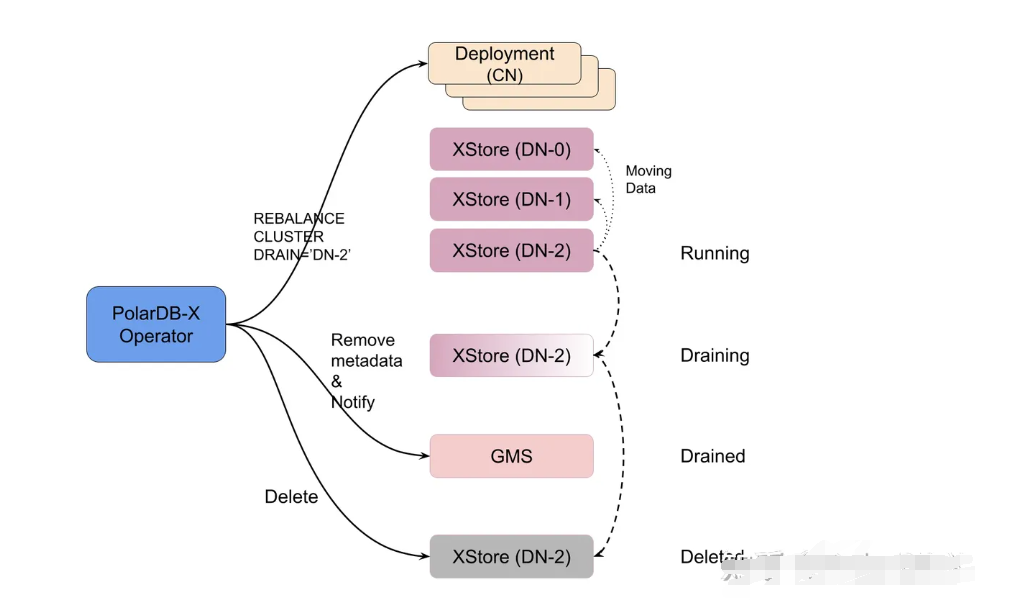
在 ***-X Operator 中,存储节点扩容和缩容是分别对待的。扩容(增加)存储节点实际上只需要新建数个存储节点,然后将这些存储节点的元数据写到 GMS 中,并通知集群存储节点 ready 就可以了。在扩容的场景下,旧的数据可以不迁移,新增的数据(通过新建的表、自动分区)自动会分布到新的 DN 之上。参考 StatefulSet,我们对 DN 进行了编号,例如 DN-0、DN-1、DN-2 等等。扩容操作永远是在编号的最后新增编号连续的 DN,例如从 2 个 DN 扩容到 3 个 DN,则在 DN-1 后新增 DN-2。
在缩容的场景中,operator 也是挑选编号最大的那几个 DN,将它们删除。等等,那数据怎么办?缩容场景下,这些 DN 上的数据一定要先搬迁到剩余的 DN 之上。***-X Operator 通过调用 CN 提供的接口来进行 DN 的下线(逻辑删除):
-- 需要 root 权限,不要在生产环境手动尝试REBALANCE CLUSTER DRAIN_NODE='DN-2';
关于数据是如何迁移的,可以参考我们之前的知乎文章 谈谈 ***-X 的水平扩展。考虑这样一个问题:是否搬迁了分区中的数据就已经足够了呢?我们忘记了 CDC 服务,它是需要消费 DN 上的 binlog 进行工作的。如果在 binlog 还没完全消费之前就删除了对应的 DN,那会导致 CDC 无法产生一个正确的全局 binlog。因此除了分区数据的迁移之外,还需要保证 CDC 已经消费完了所有将要删除 DN 的 binlog。万幸这个操作已经被封装在了上述的指令中,operator 可以放心地调用 -- 只需要最后再做一把校验就好。
数据自均衡
虽然说扩容的时候加完存储节点就可以收工了,但我们希望能够更进一步 -- 将已有的数据均衡到新增的 DN 上。 因此 ***-X Operator 在扩容的时候也集成了数据均衡的能力,原理同缩容是一样的。在数据节点创建完成之后,operator 通过下述方式去完成数据均衡:
-- 需要 root 权限,不要在生产环境手动尝试REBALANCE CLUSTER;
同时 operator 会观测数据均衡进度,并更新到 ***XCluster 的状态中。集成了数据自均衡的 ***-X Operator 可以提供一个更加完整、易用、可观测的扩缩容能力。
混合扩缩容
实际场景中,计算能力、存储能力、日志处理能力的扩缩容和升降配是混合在一起进行的。在遵循 operator pattern 的情况下,***-X Operator 需要制定一套可行的计划来完成这一系列操作。思考一下,有状态应用的扩缩容是否可以在进行到一半的时候中断?例如首先将 2 个 DN 扩容到 3 个,在还没完成时再缩容回到 2 个,或者是反过来?
显然,这取决于扩缩容的阶段:当进行到节点上已经有数据(扩容)、节点已经下线完毕(缩容)、节点已经删除时,中断会引入很大的代价或是根本不能完成。此时不如将之前进行中的操作完成,再重新执行一个新的扩缩容操作。***-X Operator 将混合扩缩容、升降配任务分为了 5 个阶段:
进行 CN、CDC 的 Deployment 更新,以及 GMS 的升降配、DN 的升降配和扩容(在 spec 没有变更时,更新是幂等的,不会产生效果),进入阶段 2
等待 GMS、CN、DN、CDC 都进入稳定状态,如果失败回到阶段 1 重新执行,如果成功进入阶段 3
探测是否需要进行数据迁移(扩容 rebalance 或者 缩容 drain),是则执行对应操作,进入阶段 4
观察并汇报数据迁移任务进度,并探测是否缩容节点下线完毕,如果都是则进入阶段 5
删除缩容的数据节点,重置任务上下文,将集群状态置为运行中
在进入到数据迁移(阶段 3)之后,任务就不可再打断了,这期间发生的修改将留到下一次重新启动一个流程。Operator Pattern 带来的循环导致了上述阶段的每一个步骤都要做到幂等,因此阶段是记录在 ***XCluster 的 status 字段中的,以形成一个状态机。其中,operator 还通过将 ***XCluster 的 observedGeneration 标记到 Deployment、XStore 等子资源上来快速跳过无需更新的对象,从而提高循环的效率。具体的实现细节可以参考我们开源的代码 polardbxcluster_controller.go。
总结
弹性能力是分布式系统的基础能力之一,本文主要介绍了基于 Kubernetes 的 ***-X Operator 中 ***-X 集群的弹性扩缩容的实现原理和细节。文中对数据迁移原理、CDC 全局 binlog 等技术细节没有一一展开,感兴趣的读者可以翻阅我们之前的文章进行了解。
![]()
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

