大家可能知道我是 PingCAP CEO,但是不知道的是,我也是 PingCAP 的产品经理,应该也是最大的产品经理,是对于产品重大特性具有一票否决权的人。中国有一类产品经理是这样的,别人有的功能我们统统都要有,别人没有的功能,我们也统统都要有,所以大家看到传统的国内好多产品就是一个超级巨无霸,功能巨多、巨难用。所以我在 PingCAP 的一个重要职责是排除掉“看起来应该需要但实际上不需要”的那些功能,保证我们的产品足够的专注、足够聚焦,同时又具有足够的弹性。
一、最初的三个基本信念
本次分享题目是《TiDB 的架构演进哲学》,既然讲哲学那肯定有故事和教训,否则哲学从哪儿来呢?但从另外的角度来说,一般大家来讲哲学就先得有信念。有一个内容特别扯的美剧叫做《美国众神》,里面核心的一条思路是“你相信什么你就是什么”。其实人类这么多年来,基本上也是朝这条线路在走的,人类对于未知的东西很难做一个很精确的推导,这时信念就变得非常重要了。

实际上,我们开始做 TiDB 这个产品的时候,第一个信念就是相信云是未来。当年 K8s 还没火,我们就坚定的拥抱了 K8s。第二是不依赖特定硬件、特定的云厂商,也就是说 TiDB 的设计方向是希望可以 Run 在所有环境上面,包括公有云私有云等等。第三是能支持多种硬件,大家都知道我们支持 X86、AMD64、ARM 等等,可能大家不清楚的是 MIPS,MIPS 典型代表是龙芯,除此之外,TiDB 未来还可以在 GPU 上跑(TiFlash 的后续工作会支持 GPU)。
二、早期用户故事
2.1 Make it work
有一句话大概是“眼睛里面写满了故事,脸上没有一点沧桑”,其实现实是残酷的,岁月一定会给你沧桑的。我们早期的时候,也有相对比较难的时候,这时候就有一些故事关于我们怎么去经历、怎么渡过的。
首先大家做产品之前肯定先做用户调研,这是通用的流程,我们当初也做过这个事,跟用户聊。我们通常会说:“我们要做一个分布式数据库,自动弹性伸缩,能解决分库分表的问题,你会用吗?”用户说“那肯定啊,现在的分库分表太痛苦了。”这是最初我们获取需求最普通的方式,也是我们最容易掉入陷阱的方式,就好像“我有一百万,你要不要?肯定要。”“我有一瓶水,喝了之后就健康无比,延年益寿你要不要?肯定要。”很容易就得到类似的结论。
所以这个一句话结论的代价是我们进行了长达两年的开发。在这两年的时间里,我们确定了很多的技术方向,比如最初 TiDB 就决定是分层的。很显然一个复杂的系统如果没有分层,基本上没有办法很好的控制规模和复杂度。TiDB 分两层,一层是 SQL 层,一层是 key-value 层,那么到底先从哪一个层开始写呢?其实从哪层开始都可以,但是总要有一个先后,如何选择?
这里就涉及到 TiDB 的第一条哲学。我们做一个产品的时候会不断面临选择,那每次选择的时候核心指导思想是什么?核心思想是能一直指导我们持续往前去迭代,所以我们第一条哲学就是:永远站在离用户更近的地方去考虑问题。
为什么我们会定义这样一条哲学?因为离用户越近越能更快的得到用户的反馈,更快的验证你的想法是不是可行的。显然 SQL 层离用户更近,所以我们选择从 SQL 层写起。其实一直到现在,绝大多数用户用 TiDB 的时候根本感受不到 KV 层的存在,用户写的都是 SQL,至于底层存储引擎换成了别的,或者底层的 RocksDB 做了很多优化和改进,这些变化对于用户关注的接口来说是不可见的。
选择从 SQL 层开始写之后,接下来面临的问题就是怎么做测试,怎么去更好的做验证,怎么让整个架构,先能够完整跑起来。
在软件开发领域有一条非常经典的哲学:「Make it work, make it right, make it fast」。我想大家每一个学软件开发的人,或者每一个学计算机的人可能都听过这样一句话。所以当时我们就做另外一个决定,先在已有的 KV 上面构建出一个原形,用最短的时间让整个系统能够先能 work。
我们在 2015 年的 9 月份开源了第一个版本,当时是没有存储层的,需要接在 HBase 上。当这个系统能跑起来之后,我们的第一想法是赶紧找到当初调研时说要用的那些用户,看看他们是什么想法,尽快的去验证我们的想法是不是可行的。因为很多人做产品思维属于自嗨型,“我做的东西最厉害,只要一推出去肯定一群人蜂拥而至。”抱有这种想法的人太多了,实际上,只有尽快去验证才是唯一的解决之道,避免产品走入误区。

然而当我跟用户讲,你需要先装一个 Hadoop,可能还要装一组 Zookeeper,但用户说:“我只想要一个更强大的 MySQL,但是让我装这一堆东西,你是解决问题还是引入问题?”
这个问题有什么解决办法呢?一个办法是你去解决用户,可以通过销售或者通过某些关系跟用户聊,显然这是一个不靠谱的思路。作为一个产品型的公司,我们很快就否了这个想法。用户的本质要求是:你不要给我装一堆的东西,要真正解决我的问题。所以我们马上开始启动分布式 KV 的开发工作,彻底解决掉这个问题,满足用户的要求。
开始开发 KV 层时候又会面临很多技术选择,我们有很多考量(如图 3)。
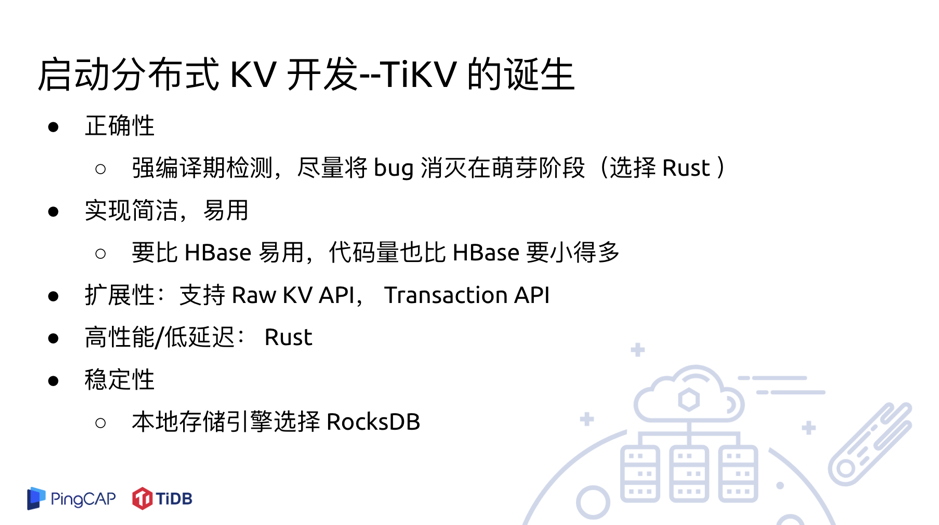
第一点,我们认为作为数据库最重要的是正确性。 假设这个数据库要用在金融行业,用在银行、保险、证券,和其他一些非常关键的场合的时候,正确性就是无比重要的东西。没有人会用一个不正确的数据库。
第二点是实现简洁、易用。 用户对于一个不简洁、不易用的东西是无法接受的,所以我们当时的一个想法是一定要做得比 HBase 更加易用,代码量也要比 HBase 小,所以时至今天 TiDB 代码量仍然是比 HBase 小得多,大约还不到 HBase 的十分之一。
第三点考虑是扩展性。 TiDB 不仅在整体上是分层的,在存储层 TiKV 内部也是分层的,所以有非常好的扩展性,也支持 Raw KV API、Transaction API,这个设计后来也收获了很多用户的支持,比如一点资讯的同学就是用的 Raw KV API。
第四点就是要求高性能低延迟。 大家对于数据库的性能和延迟的追求是没有止境的,但是我们当时并没有把太多精力花在高性能低延迟上。刚才说到我们有一条哲学是「Make it work, make it right, make it fast」,大家可以看到这句话里面 「Fast」是放最后的,这一点也是 TiDB 和其他产品有非常大的差异的地方。作为一个技术人员,通常大家看一个产品好不好,就会想:“来,不服跑个分,产品架构、易用性、技术文档、Community 这些指标都不看,先跑个分让大家看看行不行”。这个思路真正往市场上去推时是不对的。很多事情的选择是一个综合的过程。你可以让你的汽车跑的巨快无比,上面东西全拆了就留一个发动机和四个轮子,那肯定也是跑得巨快,重量轻,而且还是敞篷车,但没有一个人会在路上用的。同样的,选择 Rust 也是综合考量的结果。我们看中了 Rust 这个非常具有潜力的语言。当时 Rust 没有发布 1.0,还不是一个 stable 版本,但我们相信它会有 1.0。大概过了几个月,Rust 就发布了 1.0 版本,证明我们的选择还是非常正确的。
最后一点就是稳定性。 作为一个分布式数据库,每一层的稳定性都非常重要。最底下的一个存储引擎,我们选择了非常稳定的 RocksDB。不过后来我们也查到几个 RocksDB 掉数据的 Bug。这也是做数据库或者说做基础产品的残酷性,我们在做产品的过程中找到了 Rust 编译器的 Bug,XFS 掉数据的 Bug,RocksDB 掉数据的 Bug,好像几大基础组件的 Bug 都聚在这里开会。
接着我们辛辛苦苦干了三个月,然后就开源了 TiKV,所以这时候看起来没有那么多的组件了。我们也不忘初心,又去找了我们当初那个用户,说我们做了一些改进,你要不要试一试。

但是用户这时候给了一个让我们非常伤心非常难受的回答:没有,我们不敢上线,虽然你们的产品听起来挺好的,但是数据库后面有很大的责任,心理上的担心确实是过不去。于是我们回去开始加班加点写 TiDB Binlog,让用户可以把 binlog 同步给 MySQL。毕竟用户需要一个 Backup:万一 TiDB 挂了怎么办,我需要切回 MySQL,这样才放心,因为数据是核心资产。
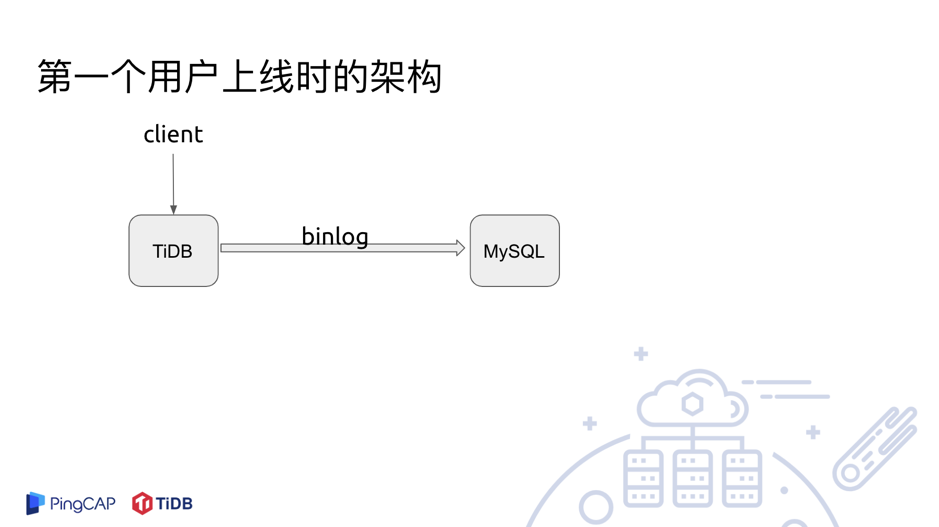
所以最终我们第一个用户上线的时候,整个 TiDB 的架构是这样的(如图 5)。用户通过 Client 连上 TiDB,然后 TiDB 后面就通过 Binlog 同步到 MySQL。后来过了一段时间,用户就把后面的 MySQL 撤了。我们当时挺好奇为什么撤了,用户说,第一个原因是后面 MySQL 撑不起一个集群给它回吐 Binlog,第二就是用了一段时间觉得 TiDB 挺稳定的,然后就不需要 Binlog 备份了。
其实第一个用户上线的时候,数据量并不算大,大概 800G 的数据,使用场景是 OLTP 为主,有少量的复杂分析和运算,但这少量的复杂分析运算是当时他们选择 TiDB 最重要的原因。因为当时他们需要每隔几分钟算一个图出来,如果是在 MySQL 上面跑,大约需要十几分钟,但他们需要每隔几分钟打一个点,后来突然发现第二天才能把前一天的点都打出来,这对于一个实时的系统来说就很不现实了。虽然这个应用实践只有少部分运算,但也是偏 OLAP,我记得 TiDB 也不算特别快,大概是十几秒钟,因为支持了一个并行的 Hash Join。
不管怎样,这个时候终于有第一个用户能证明我们做到了「Make it work」。
2.2 Make it right
接下来就是「Make it right」。大家可能想象不到做一个保证正确性的数据库这件事情有多么难,这是一个巨大的挑战,也有巨大的工作量,是从理论到实践的距离。

2.2.1 TLA+ 证明
大家可能会想写程序跟理论有什么关系?其实在分布式数据库领域是有一套方法论的。这个方法论要求先实现正确性,而实现正确的前提是有一个形式化的证明。为了保证整个系统的理论正确,我们把所有的核心算法都用 TLA+ 写了一遍证明,并且把这个证明 开源 出去了,如果大家感兴趣可以翻看一下。以前写程序的时候,大家很少想到先证明一下算法是对的,然后再把算法变成一个程序,其实今天还有很多数据库厂商没有做这件事。
2.2.2 千万级别测试用例
在理论上保证正确性之后,下一步是在现实中测试验证。这时只有一个办法就是用非常庞大的测试用例做测试。大家通常自己做测试的时候,测试用例应该很少能达到十万级的规模,而我们现在测试用例的规模是以千万为单位的。当然如果以千万为单位的测试用例靠纯手写不太现实,好在我们兼容了 MySQL 协议,可以直接从 MySQL 的测试用例里收集一些。这样就能很快验证整个系统是否具备正确性。
这些测试用例包括应用、框架、管理工具等等。比如有很多应用程序是依赖 MySQL,那直接拿这个应用程序在 TiDB 上跑一下,就知道 TiDB 跟 MySQL 的兼容没问题,如 WordPress、无数的 ORM 等等。还有一些 MySQL 的管理工具可以拿来测试,比如 Navicat、PHP admin 等。另外我们把公司内部在用的 Confluence、Jira 后面接的 MySQL 都换成了 TiDB,虽然说规模不大,但是我们是希望在应用这块有足够的测试,同时自己「Eat dog food」。
2.2.3 7*24 的错误注入测试用例
这些工作看起来已经挺多的了,但实际上还有一块工作比较消耗精力,叫 7*24 的错误注入测试。最早我们也不知道这个测试这么花钱,我们现在测试的集群已经是几百台服务器了。如果创业的时候就知道需要这么多服务器测试,我们可能就不创业了,好像天使轮的融资都不够买服务器的。不过好在这个事是一步一步买起来,刚开始我们也没有买这么多测试服务器,后来随着规模的扩大,不断的在增加这块的投入。
大家可能到这儿的时候还是没有一个直观的感受,说这么多测试用例,到底是一个什么样的感受。我们可以对比看一下行业巨头 Oracle 是怎么干的。

这是一篇 在 HackNews上面的讨论,讨论的问题是:你觉得这个最坏的、规模最大的代码是什么样子的?下面就有一个 Oracle 的前员工就介绍了 Oracle Database 12.2 这个版本的情况。他说这个整体的源代码接近 2500 万行 C 代码,可能大家维护 25 万行 C 代码的时候就会痛不欲生了,可以想想维护这么多代码的是一种什么样的感受。到现在为止,TiDB 的代码应该还不到 25 万行。当然 TiDB 的功能远远没有 Oracle 那么多,Oracle 的功能其实是很多的,历史积累一直往上加,加的很凶。
这位 Oracle 前员工介绍了自己在 Oracle 的开发工作的流程,如下图:

比如用户报了一个 Bug,然后他开始 fix。第一件事是花两周左右的时间去理解 20 个不同的 flag,看看有没有可能因为内部乱七八糟的原因来造成这个 Bug。大家可能不知道 MySQL 有多少变量,我刚做 TiDB 的时候也不知道,当时我觉得自己是懂数据库的,后来去看了一下 MySQL 的 flag 的变量数就惊呆了,但看到 Oracle 的 flag 变量数,那不是惊呆了,是绝望了。大家可能知道开启 1 个 flag 的时候会对什么东西有影响,但是要去理解 20 个 flag 开启时和另外几个 flag 组合的时候都有什么影响,可能会崩溃。所以其实精通 Oracle 这件事情,实际上可能比精通 C++ 这件事情更困难的。一个 Oracle 开发者在内部处理这件事情都这么复杂,更何况是外面的用户。但 Oracle 确实是功能很强大。
说回这位前 Oracle 员工的描述,他接着添加了更多的 flag 处理一个新的用户场景的问题,然后加强代码,最后改完以后会提交一个测试。先在 100 到 200 台机器上面把这个 Oracle 给 build 出来,然后再对这个 Oracle 去做新的测试。他应该对 Oracle 的测试用例的实际数量了解不深刻,我猜他可能不知道 Oracle 有多少个测试,所以写的是 “millions of tests”,这显然太低估了 Oracle 的测试数量。通常情况下,只会看到挂了的测试,看不到全部的测试数量。
下面的步骤更有意思了:Go home,因为整个测试需要 20-30 个小时,跑完之后测试系统反馈了一个报告:挂了 200 多个 test,更茫然的是这 200 tests 他以前都没见过,这也是 Oracle 非常强大的一个地方,如果一个开发者的代码提交过去挂掉一两百个测试,是很正常的事情,因为 Oracle 的测试能 Cover 东西非常多,是这么多年来非常强大的积累,不停的堆功能的同时就不停的堆测试,当然也不停的堆 flag。所以从另一个角度来看,限制一个系统的功能数量,对于维护来说是非常重要的。
总之,看完这个回复之后,我对行业前辈们充满了敬畏之情。
2.3 Make it fast
2.3.1 新问题
随着 TiDB 有用户开始上线,用户的数量和规模越来越大,这时候就出现了一个很有意思的事情,一部分用户把 TiDB 当成了可以支持事务、拥有良好实时性的数据仓库在用,和我们说:我们把公司 Hadoop 换了,数据量十几 T。
我们就一下开始陷入了深深的思考,因为 TiDB 本来设计的目的不是这个方向,我们想做一个分布式 OLTP 数据库,并没有想说我们要做一个 Data Warehouse。但是用户的理由让我们觉得也很有道理,无法反驳——TiDB 兼容 MySQL,会 MySQL 的人很多,更好招人,最重要的是 Hadoop 跑得还不够快。
虽然我们自己也很吃惊,但这体现了 TiDB 另一方面的价值,所以我们继续问用户还有什么痛点。用户表示还有一部分查询不够快,数据没办法做到 shuffle,而且以前用 Spark,TiDB 好像没有 Spark 的支持。
我们想了想,TiDB 直接连 Spark 也是可以的,但这样 Spark 对底下没有感知,事务跑得巨慢,就跟 Spark 接 MySQL 没什么差别。我们研究了一下,做出了一个新的东西——TiSpark。TiSpark 就开始能够同时在 TiDB 上去跑 OLAP 和 OLTP。

就在我们准备改进 TiDB 的数据分析能力的时候,突然又有一大批 TP 用户上线了,给我们报了一堆问题,比如执行计划不准确,选不到最优执行计划,数据热点分布不均匀,Raft store 单线程写入瓶颈,报表跑的慢等等……于是我们制定了 1.0 到 2.X 的计划,先把用户提的这些问题一一解决。
这里有另外一条哲学:将用户遇到的问题放在第一优先级。我们从产品最初设计和之后 Roadmap 计划永远是按照这个原则去做的。
首先,执行计划不准确的问题。 最简单有效的解决办法是加一个 Index Hint,就像是“你告诉我怎么执行,我就怎么执行,我自己不会自作聪明的选择”。但这不是长久之计,因为用户可能是在一个界面上选择各种条件、参数等等,最后拼成一个 SQL,他们自己没办法在里面加 Index Hint。我们不能决定用户的使用习惯,所以从这时开始,我们决定从 RBO(Rule Based Optimizer)演进到 CBO(Cost Based Optimizer),这条路也走了非常久,而且还在持续进行。
第二个是热点数据处理问题。 我们推出了一个热点调度器,这个可能大家在分布式数据库领域第一次听说,数据库领域应该是 PingCAP 首创。 热点调度器会统计、监控整个系统热点情况,再把这些热点做一个快速迁移和平衡,比如整个系统有 10 个热点,某一个机器上有 6 个热点,这台机器就会很卡,这时热点调度器会开始将热点打散,快速分散到集群的其他机器上去,从而让整个集群的机器都处于比较正常的负载状态。
第三个就是解决 Raft store 单线程瓶颈的问题。为了改变 Raft store 单线程,我们大概花了一年多的时间,目前已经在 TiDB 3.0 里实现了。我们将 Raft store 线程更多耗时的计算变成异步操作,offload 到其它线程。不知道有没有人会好奇为什么这个改进会花这么长时间?我们一直认为数据库的稳定性第一位的。分布式系统里面一致性协议本身也复杂,虽然说 Raft 是比 Paxos 要简单,但它实际做起来也很复杂,要在一个复杂系统里支持多线程,并且还要做优化,尽可能让这个 I/O 能 group 到一起,其实非常耗精力。
第四个就是解决报表跑得慢的问题,这个骨头特别硬,我们也是啃到今天还在继续。首先要大幅提升 TiDB 在分析场景下的能力。大家都可以看到我们在发布每一个版本的时候,都会给出与上一个版本的 TPC-H 性能对比(TPC-H 是一个有非常多的复杂查询、大量运算的场景)。其次就是高度并行化,充分利用多核,并提供参数控制,这个特性可能很多用户不知道,我们可以配一下参数,就让 TiDB 有多个并发在底层做 Scan。
解决完这些问题,我们终于觉得可以喘口气了,但喘气的时间就不到一个星期,很快又有很多用户的反馈开始把我们淹没了。因为随着用户规模的扩大,用户反馈问题的速度也变得越来越快,我们处理的速度不一定跟的上用户的增速。
2.3.4 新呼声
这时候我们也听到了用户的一些「新呼声」。
有用户说他们在跑复杂查询时 OLTP 的查询延迟变高了,跑一个报表的时候发现 OLTP 开始卡了。这个问题的原因是在跑复杂查询的时候,SQL 资源被抢占。我们又想有没有可能将 OLAP 和 OLTP 的 Workload 分开?于是我们搞了第一个实验版本,在 TiKV 里把请求分优先级,放到不同队列里面去,复杂 Query 放在第一优先级的队列, OLTP 放在高优先级。然后我们发现自己是对报表理解不够深刻,这个方案只能解决一部分用户的问题,因为有的报表跑起来需要几个小时,导致队列永远是满的,永远抢占着系统的资源。还有一部分用户的报表没有那么复杂,只是希望报表跑得更快、更加实时,比如一个做餐饮 SaaS 的用户,每天晚上需要看一下餐馆营收情况,统计一家餐馆时速度还行,如果统计所有餐馆的情况,那就另说了。
另外,报表有一些必需品,比如 View 和 Window Function,没有这些的话 SQL 写起来很痛苦,缺乏灵活度。
与此同时,用户关于兼容性和新特性的要求也开始变多,比如希望支持 MySQL 类似的 table partition,还有银行用户习惯用悲观锁,而 TiDB 是乐观锁,迁移过来会造成额外的改造成本(TiDB 3.0 已经支持了悲观锁)。
还有用户有 400T 的数据,没有一个快速导入的工具非常耗时(当然现在我们有快速导入工具TiDB Lightning),这个问题有一部分原因在于用户的硬件条件限制,比如说千兆网导入数据。
还有些用户的数据规模越来越大,到 100T 以上就开始发现十分钟已经跑不完 GC 了(TiDB 的 GC 是每十分钟一次),一个月下来 GC 已经整体落后了非常多。

我们当时非常头痛,收到了一堆意见和需求,压力特别大,然后赶紧汇总了一下,如图 10 所示。
面对这么多的需求,我们考虑了两个点:
- 哪些是共性需求?
- 什么是彻底解决之道?
把共性的需求都列在一块,提供一个在产品层面和技术层面真正的彻底的解决办法。
比如图 10 列举的那么多问题,其实真正要解决三个方面:性能、隔离和功能。性能和隔离兼得好像很困难,但是这个架构有非常独特的优势,也是可以做得到的。那可以进一步「三者兼得」,同时解决功能的问题吗?我们思考了一下,也是有办法的。TiDB 使用的 Raft 协议里有一个 Raft Learner 的角色,可以不断的从 Leader 那边复制数据,我们把数据同步存成了一个列存,刚才这三方面的问题都可以用一个方案去彻底解决了。
首先复杂查询的速度变快了,众所周知分析型的数据引擎基本上全部使用的是列存。第二就是强一致性,整个 Raft 协议可以保证从 Learner 读数据的时候可以选择一致性的读,可以从 Leader 那边拿到 Learner 当前的进度,判断是否可以对外提供请求。第三个是实时性可以保证,因为是通过 streaming 的方式复制的。
所以这些看上去非常复杂的问题用一个方案就可以解决,并且强化了原来的系统。这个「强化」怎么讲?从用户的角度看,他们不会考虑 Query 是 OLAP 还是 OLTP,只是想跑这条 Query,这很合理。用一套东西解决用户的所有问题,对用户来说就是「强化」的系统。
三、关于成本问题的思考

很多用户都跟我们反馈了成本问题,用户觉得全部部署到 SSD 成本有点高。一开始听到这个反馈,我们还不能理解,SSD 已经很便宜了呀,而且在整个系统来看,存储机器只是成本的一小部分。后来我们深刻思考了一下,其实用户说得对,很多系统都是有早晚高峰的,如果在几百 T 数据里跑报表,只在每天晚上收工时统计今天营业的状况,那为什么要求用户付出最高峰值的配置呢?这个要求是不合理的,合不合理是一回事,至于做不做得到、怎么做到是另外一回事。
于是我们开始面临全新的思考,这个问题本质上是用户的数据只有一部分是热的,但是付出的代价是要让机器 Handle 所有的数据,所以可以把问题转化成:我们能不能在系统里面做到冷热数据分离?能不能支持系统动态弹性的伸缩,伸展热点数据,用完就释放?
如果对一个系统来说,峰值时段和非峰值时段的差别在于峰值时段多了 5% 的热点。我们有必要去 Handle 所有的数据吗?所以彻底的解决办法是对系统进行合理的监控,检测出热点后,马上创建一个新的节点,这个新的节点只负责处理热点数据,而不是把所有的数据做动态的 rebalance,重新搬迁。在峰值时间过去之后就可以把复制出来的热点数据撤掉,占的这个机器可以直接停掉了,不需要长时间配备非常高配置的资源,而是动态弹性伸缩的。
TiDB 作为一个高度动态的系统,本身的架构就具有非常强的张力,像海绵一样,能够满足这个要求,而且能根据系统负载动态的做这件事。这跟传统数据库的架构有很大的区别。比如有一个 4T 的 MySQL 数据库,一主一从,如果主库很热,只能马上搞一个等配的机器重挂上去,然后复制全部数据,但实际上用户需要的只是 5% 的热数据。而在 TiDB 里,数据被切成 64MB 一个块,可以很精确的检测热数据,很方便的为热数据做伸展。这个特性预计在 TiDB 4.0 提供。
这也是一个良好的架构本身带来的强大的价值,再加上基于 K8s 和云的弹性架构,就可以得到非常多的不一样的东西。同样的思路,如果我要做数据分析,一定是扫全部数据吗?对于一个多租户的系统,我想统计某个餐馆今天的收入,数据库里有成千上万个餐馆,我需要运算的数据只是其中一小块。如果我要快速做列存计算时,需要把数据全部复制一份吗?也不需要,只复制我需要的这部分数据就行。这些事情只有一个具有弹性、高度张力的系统才能做到。这是 TiDB 相对于传统架构有非常不一样的地方。时至今天,我们才算是把整个系统的架构基本上稳定了,基于这个稳定的架构,我们还可以做更多非常具有张力的事情。
所以,用一句话总结我们解决成本问题的思路是:一定要解决真正的核心的问题,解决最本质的问题。
四、关于横向和纵向发展的哲学
TiDB 还有一条哲学是关于横向和纵向发展的选择。
通常业内会给创业公司的最佳建议是优先打“透”一个行业,因为行业内复制成本是最低的,可复制性也是最好的。但 TiDB 从第一天开始就选择了相反的一条路——「先往通用性发展」,这是一条非常艰难的路,意味着放弃了短时间的复制性,但其实我们换取的是更长时间的复制性,也就是通用性。
因为产品的整体价值取决于总的市场空间,产品的广泛程度会决定产品最终的价值。早期坚定不移的往通用性上面走,有利于尽早感知整个系统是否有结构性缺陷,验证自己对用户需求的理解是否具有足够的广度。如果只往一个行业去走,就无法知道这个产品在其他行业的适应性和通用性。如果我们变成了某个行业专用数据库,那么再往其他行业去发展时,面临的第一个问题是自己的恐惧。这恐惧怎么讲呢?Database 应该是一个通用型的东西,如果在一个行业里固定了,那么你要如何确定它在其他场景和行业是否具有适应性?
这个选择也意味着我们会面临非常大的挑战,一上来先做最厉害的、最有挑战的用户。 如果大家去关注整个 TiDB 发展的用户案例的情况,你会注意到 TiDB 有这样一个特点,TiDB 是先做百亿美金以上的互联网公司,这是一个非常难的选择。但大家应该知道,百亿美金以上的互联网公司,在选择一个数据库等技术产品的时候,是没有任何商业上的考量的,对这些公司来说,你的实力是第一位的,一定要能解决他们问题,才会认可你整个系统。但这个也不好做,因为这些公司的应用场景通常都压力巨大。数据量巨大,QPS 特别高,对稳定性的要求也非常高。我们先做了百亿美金的公司之后,去年我们有 80% 百亿美金以上的公司用 TiDB,除了把我们当成竞争对手的公司没有用,其他全部在用。然后再做 30 亿美金以上的公司,今年是 10 亿美金以上的用户,实际上现在是什么样规模的用户都有,甭管多少亿美金的,“反正这东西挺好用的,我就用了。”所以我们现在也有人专门负责在用户群里面回答大家的提问。
其实当初这么定那个目标主要是考虑数据量,因为 TiDB 作为一个分布式系统一定是要处理具有足够数据量的用户场景, 百亿美金以上的公司肯定有足够的数据,30 亿美金的公司也会有,因为他们的数据在高速增长,当我们完成了这些,然后再开始切入到传统行业,因为在这之前我们经过了稳定性的验证,经过了规模的验证,经过了场景的验证。

坚持全球化的技术视野也是一个以横向优先的发展哲学。 最厉害的产品一定是全球在用的。这个事情的最大差异在于视野和格局,而格局最终会反映到人才上,最终竞争不是在 PingCAP 这两百个员工,也不是现在 400 多个 Contributors,未来可能会有上千人参与整个系统的进化迭代,在不同的场景下对系统进行打磨,所以竞争本质上是人才和场景的竞争。基于这一条哲学,所以才有了现在 TiDB 在新一代分布式数据库领域的全面领先,无论是从 GitHub Star 数、 Contributor 数量来看,还是从用户数据的规模、用户分布的行业来看,都是领先的。同样是在做一个数据库,大家的指导哲学不一样会导致产品最终的表现和收获不一样,迭代过程也会完全不一样。我们在做的方向是「携全球的人才和全球的场景去竞争」。
关于横向和纵向发展,并不是我们只取了横向。
2019 年 TiDB 演进的指导思想是:稳定性排第一,易用性排第二,性能第三,新功能第四。 这是我在 2018 年经过思考后,把我们发展的优先级做了排序。上半年我们重点关注的是前两个,稳定性和易用性。下半年会关注纵向发展,「Make it fast」其实是纵向上精耕细作、释放潜力的事情。这个指导思想看起来好像又跟其他厂商想法不太一样。
我们前面讲的三条哲学里面,最后一条就是「Make it fast」,如果要修建五百层的摩天大楼,要做的不是搭完一层、装修一层,马上给第一层做营业,再去搭第二层。而一定要先把五百层的架构搭好,然后想装修哪一层都可以。TiDB 就是「摩天大楼先搭架构后装修」的思路,所以在 TiDB 3.0 发布之后,我们开始有足够的时间去做「装修」的事情。
五、总结与展望
说了这么多故事,如果要我总结一下 2015 - 2019 年外面的朋友对 TiDB 的感受,是下图这样的:

2015 年,当我们开始做 TiDB 的时候,大家说:啊?这事儿你们也敢干?因为写一个数据库本身非常难,写一个分布式数据库就是无比的难,然后还是国人自主研发。到 2016 年的时候,大家觉得你好像折腾了点东西,听到点声音,但也没啥。到 2017、2018 年,大家看到有越来越多用户在用。2019 年,能看到更多使用后点赞的朋友了。
我昨天翻了一下 2015 年 4 月 19 日发的一条微博。
当时我们正准备创业,意气风发发了一条这样微博。这一堆话其实不重要,大家看一下阅读量 47.3 万,有 101 条转发,44 条评论,然而我一封简历都没收到。当时大家看到我们都觉得,这事儿外国人都没搞,你行吗?折腾到今天,我想应该没有人再对这个问题有任何的怀疑。很多国人其实能力很强了,自信也可以同步跟上来,毕竟我们拥有全球最快的数据增速,很多厂家拥有最大的数据量,对产品有最佳的打磨场景。
想想当时我也挺绝望的,想着应该还有不少人血气方刚,还有很多技术人员是有非常强大的理想的,但是前面我也说了,总有一个从理想到现实的距离,这个距离很长,好在现在我们能收到很多简历。所以很多时候大家也很难想象我们刚开始做这件事情的时候有多么的困难,以及中间的每一个坚持。只要稍微有一丁点的松懈,就可能走了另外一条更容易走的路,但是那条更容易走的路,从长远上看是一条更加困难的路,甚至是一条没有出路的路。

最后再说一下 2020 年。在拥有行业复制能力的之后,在产品层面我们要开始向着更高的性能、更低的延迟、更多 Cloud 支持(不管是公有云还是私有云都可以很好的使用 TiDB)等方向纵向发展。同时也会支持我刚刚说的,热点根据 Workload 自动伸缩,用极小的成本去扛,仅仅需要处理部分热点的数据,而不是复制整个数据的传统主-从思路。
大家去想一想,如果整个系统会根据 Workload 自动伸缩,本质上是一个 self-driving 的事情。现在有越来越多的用户把 TiDB 当成一个数据中台来用,有了 TiDB 行列混存,并且 TiDB 对用户有足够透明度,就相当于是握有了 database 加上 ETL,加上 data warehouse,并且是保证了一致性、实时性的。
昨天我写完 slides 之后想起了以前看的一个电视剧《大秦帝国》。第一部第九集里有一段关于围棋的对话。商鞅执黑子先行,先下在了一个应该是叫天元位置,大约在棋盘的中间。大家知道一般下围棋的时候都是先从角落开始落子居多。商鞅的对手就说,我许你重下,意思就是你不要开玩笑,谁下这儿啊?于是商鞅说这样一句话,“中枢之地,辐射四极,雄视八荒”,这也是一个视野和格局的事情。然后对手说:“先生招招高位,步步悬空,全无根基实地”,就是看起来好像是都还挺厉害的,一点实际的基础都没有,商鞅说:“旦有高位,岂无实地?”,后来商鞅赢了这盘棋,他解释道:“棋道以围地为归宿,但必以取势为根本。势高,则围广”。
这跟我们做 TiDB 其实很像,我们一上来就是先做最难最有挑战的具有最高 QPS 和 TPS、最大数据量的场景,这就是一个「取势」的思路,因为「势高,则围广」。 所以我们更多时候是像我前面说的那样,站在哲学层面思考整个公司的运转和 TiDB 这个产品的演进的思路。这些思路很多时候是大家看不见的,因为不是一个纯粹的技术层面或者算法层面的事情。
我也听说有很多同学对 TiDB 3.0 特别感兴趣,不过今天没有足够的时间介绍,我们会在后续的 TechDay 上介绍 3.0 GA 的重大特性,因为从 2.0 到 3.0 产生了一个巨大的变化和提升,性能大幅提升,硬件成本也下降了一倍的样子,需要一天的时间为大家详细的拆解。

本文根据我司 CEO 刘奇在第 100 期 Infra Meetup 上的演讲整理。