2021 年 12 月 25 日,2021 中国大数据技术大会暨 CCF 大数据与计算智能大赛高峰论坛在中科院计算技术研究所隆重召开。PingCAP 高级副总裁范若晗受邀在主会场进行了以 “开源走向世界” 为主题的演讲,结合 PingCAP 的实践,从协作方式和技术演进两个角度,分享了 “开源”和“全球化” 之间相互关联,密不可分的关系。本文内容根据演讲内容整理而成。

开源构建全球化的舞台
“开源” 和 “全球化” 之间有着非常紧密的联系,二者并不是孤立的。2015 年,PingCAP 在成立的第一时间就用开源、做开源、投入开源,并对全球化做了布局。
实际上,PingCAP 从第一行代码的提交就是在 GitHub 上完成的,我们非常重视这一领地。社区的小伙伴基于 TiDB Cloud,实现了一个用于记录公共 GitHub 活动的公开数据存档在线工具:GitHub Archive。对原始日志数据(超过 40 亿条)进行分析对比,选取国内典型的企业[1],我们可以看到过去 10 年,中国开源像洪流一样发展,活跃仓库[2]数大幅提升。在这数千个活跃的仓库中,越来越多源自中国的开源项目受到国内外同行的认可与赞许,呈现出一种百花齐放的状态。而 PingCAP 创始人的认知和决心都来自于这个洪流的滋养,在过往的六年里也为这条曲线做出了小小的贡献。我们做的这个 GitHub 分析工具,很快也将提供给大家在线访问,根据自己的需求快速灵活的进行分析。
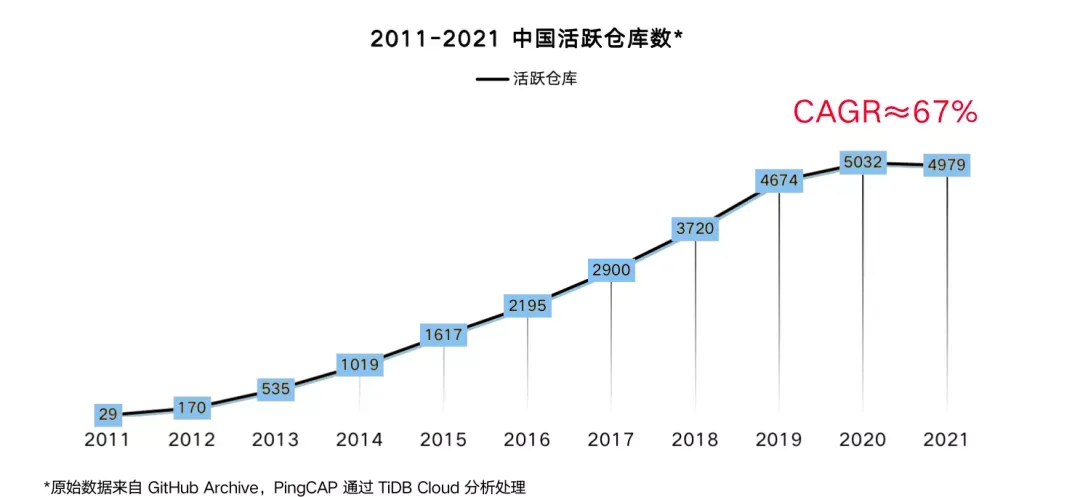
令人欣慰的是,基础软件这个赛道在开源这个舞台上真正做到了长足进步:11 月底刚发布的 “十四五” 软件和信息技术服务业发展规划,明确了“开源重塑软件发展新生态”,数据库、人工智能、操作系统领域的开源项目最为活跃。
中国目前处于开源高速发展的阶段,开源软件的发展从最底层的操作系统开始,已发展到数据库、中间件,并向应用领域逐渐延展,近年来开始主导信息技术领域的深度创新:如,大数据、云计算、人工智能、区块链、云原生等,加速了国家核心技术的自主发展。《2021 中国开源发展蓝皮书》对国内活跃开源社区进行了不完全统计,我们可以看到,在数据库、人工智能、操作系统领域的开源项目最为活跃,这跟中国互联网行业的市场特点和当前技术发展也息息相关。
一系列的政策指导以及全球开源市场的趋势变化,大大提升了资本市场对开源公司的认可度。而当我们研究近 3 年国内 ToB 技术行业,发现获得数千万乃至数十亿投融资的众多企业,在满满的科技范儿背后都有着一个共同的标签,那就是开源。另一方面,在赛道选择上也有着高度的匹配:操作系统、数据库和人工智能。
过去开源在商业化上的巨大能量是被严重低估的,现在大家对于真正利用好开源这个高杠杆的模式依然还在摸索阶段。开源是真正帮助 PingCAP 走向全球化的一扇门。今天,我将和大家分享 PingCAP 的一些探索和经验。
信任问题的解决是所有工作的前提
PingCAP 不仅代码开源开放、面向全球,文档也是一样的。最早的 TiDB 没有中文文档,所有的注释甚至每一个提交记录都必须是英文的,所有的设计文档都要放到 GitHub 上。早期用户有问题,有时会直接微信或者邮件联系,但我们也建议他们把问题放到 GitHub。甚至有专人会帮早期提出 issue 的人把 issue 从中文翻译成英文。之所以这样做,其实是从 TiDB 项目发起和早期阶段就立下了一个理念,我们要把项目的 why 和 how 都展示给全球社区的参与者。
大家看到的这个帅气的小伙,是来自多米尼加共和国的一位 TiDB 社区贡献者。开源天然地解决了彼此的信任问题,这也是开源的独特魅力,让全球社区的每个人都有机会来认识你、认可你、认同你。
在信任的基础上,开源产品可以在全球化的舞台上实现高效传播
TiDB 的相关技术文档,被技术爱好者自发地翻译成俄语、乌克兰语、日语、西班牙语和葡萄牙语等,极大推动了产品的全球化。PingCAP 编撰的 NewSQL 相关课程还入选了威斯康辛、普渡、卡内基梅隆大学数据库课程。
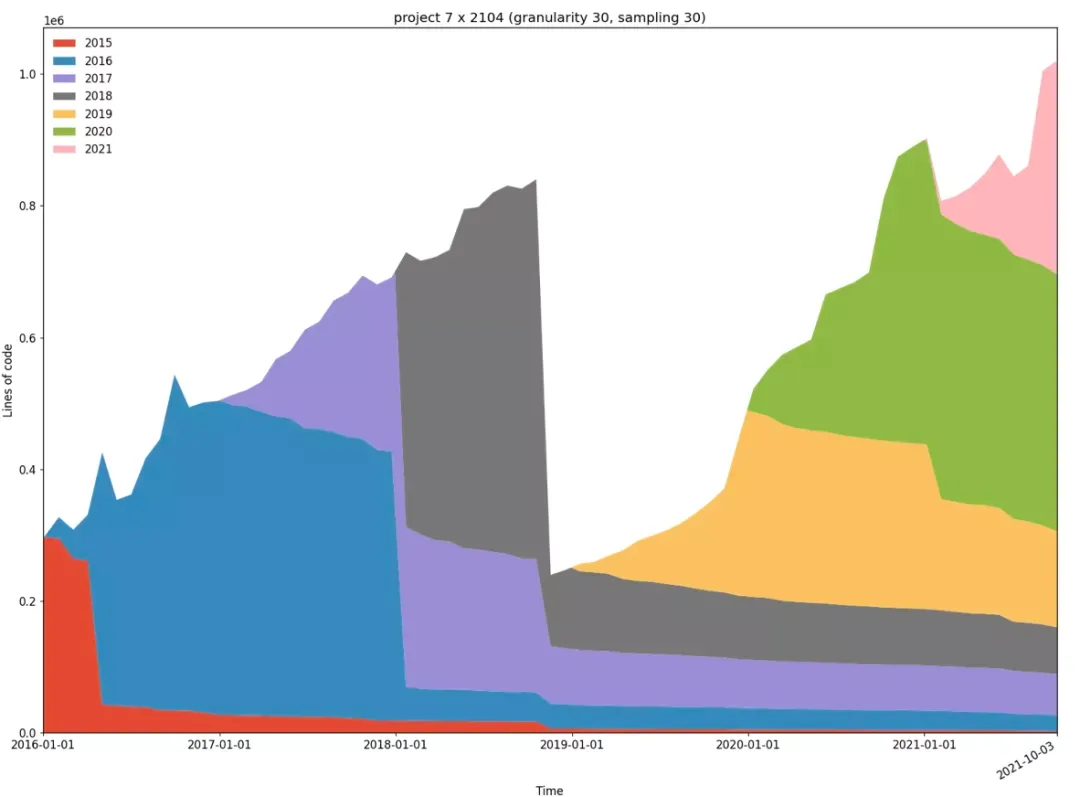
开源的生态大大加快了迭代速度
这张图是 TiDB 每年代码的变化情况。红色是 TiDB 2015 年的代码,蓝色是 2016 年的,大家可以看到,TiDB 每年会进行超过 40% 的代码更新,而这些代码的 40% 是由外部贡献者贡献的,产品的快速迭代才能保证其持续领先性。国内外多家机构共同参与开发 TiDB,既有国内的小米、美团、知乎、一点资讯等,也有国外的 Databricks、Facebook(现在的 Meta)、韩国三星研究院等等。
最厉害的产品一定是全球在用的。坚持全球化的技术视野、坚持开源这一战略,携全球的人才和全球的场景去竞争,让 TiDB 在新一代分布式数据库领域全面领先。接下来,我将给大家分享两个故事,让大家对开源带来的全球化社区共建有一个更深刻的体感。
第一个故事,是关于写书
在我们的印象中,通常的书籍编写是一个常年累月的细活,少则半年,多则数年,初稿完成后接着是多人的审阅然后再出版。但在技术发展瞬息万变的今天,产品迭代速度比较快,技术类的书籍能否有一个更快捷更高效的方式。在去年 TiDB 4.0 GA 版发布前夕, TiDB Master 分支社区一片热火朝天。为了给这个里程碑版本留下点不同的内容,我们的 CTO 产生了一个「疯狂」的念头,约一波 TiDB 社区伙伴,以 “分布式” 的方式,在 48 小时之内写完一本关于 TiDB 的技术书籍。希望系统且简要地介绍一下整个 TiDB 和周边工具生态,能手把手地指导用户 “把 TiDB 用起来且用好”。
说干就干,从 3 月 3 号在网上发布 TiDB Book Rush 这个创意,3 月 6 号周五晚 21:00 开始,历时 48 小时,共有 102 位来自社区的作者参与,截止周日 21:00,总计产生了 421 次 Commit,199 个 PR,最终开源电子书 《TiDB in Action》 第一版诞生,涵盖了 TiDB 基本架构原理,最佳实践及案例,TiDB 开源社区及周边生态发展历程等。

第二个故事是关于开源加速产品迭代的
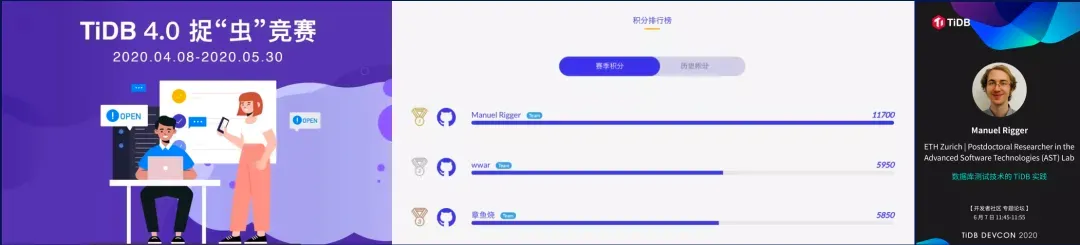
“4.0 捉虫竞赛”是由 TiDB 社区发起的挑战赛,选手可以通过为 TiDB 寻找 bug 或提交测试报告的方式获得相应积分,积分可以兑换奖品。这次竞赛共有 40 位社区小伙伴组成 23 支队伍进行参赛。通过大家共同不懈的努力,一共为 TiDB 4.0 GA 找出 51 个 P1 级别的 bug 和 8 个 P0 级别 bug。
本次捉 “虫” 竞赛第一名的获奖者 Manuel Rigger (还给自己起了个中文名字叫李曼努), 是一位专攻数据库测试方向的博士后,来自苏黎世联邦理工学院,他的测试框架也帮助 MySQL、PostgreSQL、MariaDB 等数据库找到了 400 多个 bug。
刚才的两个故事,让我们看到了一个开放的开源社区有多么大的吸引力,可以激发全球社区的众多贡献者共创共建,加速产品的快速迭代。
这样的贡献并不是单向的,开源通过激发工程师在社群中的创造力,也使得大量的开发者、机构和企业,无门槛地使用质量优良的软件产品,贡献巨大的社会价值,形成一个良好的循环。
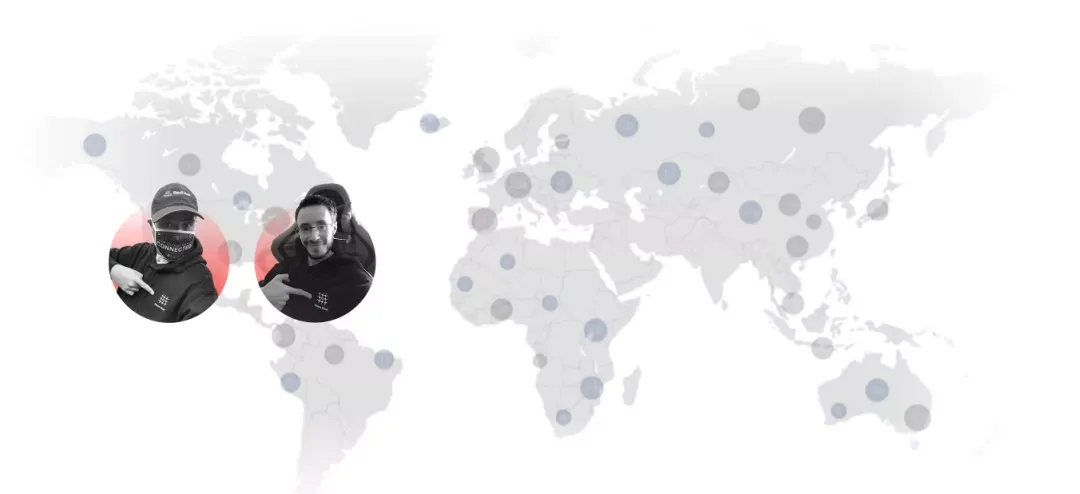
大家看到的这两位男士是来自于危地马拉一所大学的教授和学生,图上他们穿着 PingCAP 创立的一个开源混沌工程项目 Chaos Mesh 的卫衣,这个教授和学生在 GitHub 上面做了一个非常有意思的项目,通过构建一个分布式系统,来实时记录分析世界各地的新冠疫苗接种的信息。Chaos Mesh 保障了这个系统的稳定。在看到这个项目之前,我们可能完全无法想象,中国的一群工程师做的一个项目能被中美洲的一个国家关注到,同样我们也不知道自己创建的混沌测试工具还能以这种方式参与到全人类都关注到的新冠疫情的工作中。与此同时,我们的 TiDB 产品也在中国的疾病预防控制管理、群体免疫监测等领域默默地发光发热。这些真实的故事体现的正是 PingCAP 社区用户的全球性,这张世界地图上的一个个圆圈,代表了参与 PingCAP 开源项目的社区用户数。正是这些来自全球的开发者让我们能够第一时间接触到更多的用户,获得更多关注,打下早期的客户基础。
作为先进的生产模式,开源让 PingCAP 获取到了非常多来自社区的帮助,同时把开源的智慧贡献给全球,实现了巨大的社会价值。现在 PingCAP 在开源到商业的道路上越走越好,也是从这些社会价值的贡献中萃取出商业价值,帮助公司和项目茁壮成长,为企业和产品的成功形成源源不断的价值闭环。
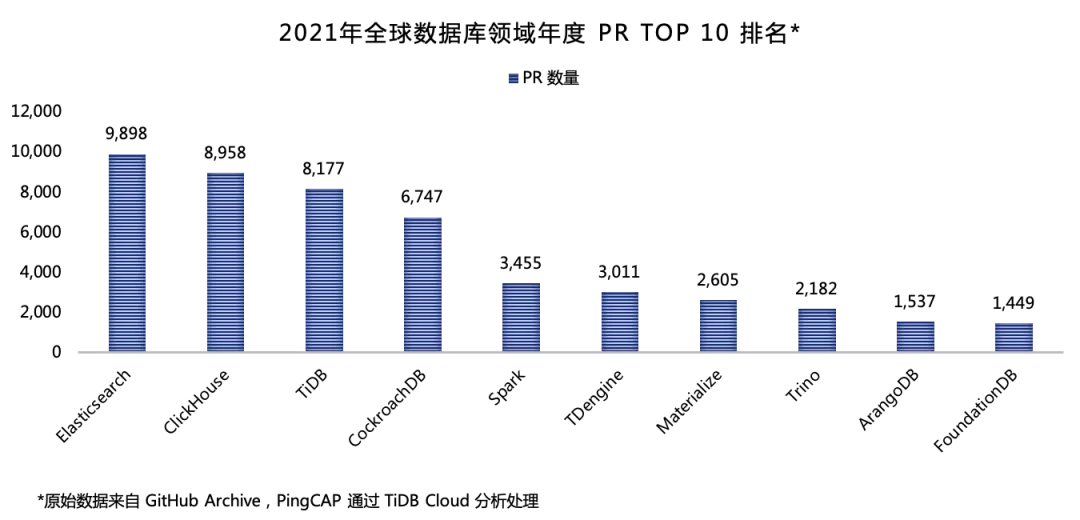
当我们从自己的产品跳脱出来,去看全球范围整个数据技术行业,会发现近十年涌现出来的数据技术创新, 95% 都是开源的。这张图显示的是截至 2021 年12 月初,我们的 GitHub Archive 数据分析得出的年度 PR Top 10 的数据技术项目,PR 即 Pull Request,就是用户修改了代码,希望合并到主干仓库中,它体现的是开源项目的创新迭代能力。
可以说最近十年数据技术创新进入了前所未有的蓬勃发展阶段,动力来源于哪里?选择困难该怎么办?接下来,我将与大家分享 PingCAP 从数据库近半个世纪的发展历程里,学到了什么,技术发展对 PingCAP 的架构选择和产品方向产生了什么影响。
从数据库技术演进看开源力量
我们认为,数据技术演进的驱动力总结起来,主要包括三个方面:理论基础推动软件创新、基础设施保障软件能力的实现、业务需求真正打磨了技术的不断工程化、产品化,是产品真正的 “用武之地”。
数据库演进历史——基础理论驱动
按照时间和功能维度,我们将数据生态做了划分,大致包括 SQL 生态,大数据生态,NoSQL 生态,NewSQL 生态,以及 SQL 的云化生态。每个生态的演进,离不开基础理论的发展。
1970 年 IBM 的关系型数据库理论 Relational Model 包括 System R 原型产品的问世,为 Oracle、DB2、MicroSoft SQL Server 这些商业数据库的诞生奠定了基础。而后 MySQL、PostgreSQL 以开源这一形态获得快速发展和全球最广泛的应用。
2003 年 - 2006 年,谷歌三驾马车 GFS,MapReduce,BigTable 论文的发表,奠定了业界大规模分布式存储系统的理论基础。现如今非常流行的 Hadoop、Spark、MongoDB、Hbase 等也都是建立在这些理论基础上的。大家可以发现,这些数据产品都是用开源模式发展壮大的。因为闭源的模式迭代速度慢,单位成本高,已经无法应对海量用户需求了。
2012 年 - 2014 年,还是 Google 发表的 Spanner 和 F1,以及斯坦福大学的 Raft 论文,推动了 NewSQL 数据库的发展。PingCAP 的 TiDB,也是对这些理论基础的产品化实现,并在此基础上不断创新。
数据库演进历史——业务创新驱动
再来看看怎么理解刚刚说的 “用武之地”,总体而言,业务需求体现在以下三个方面:
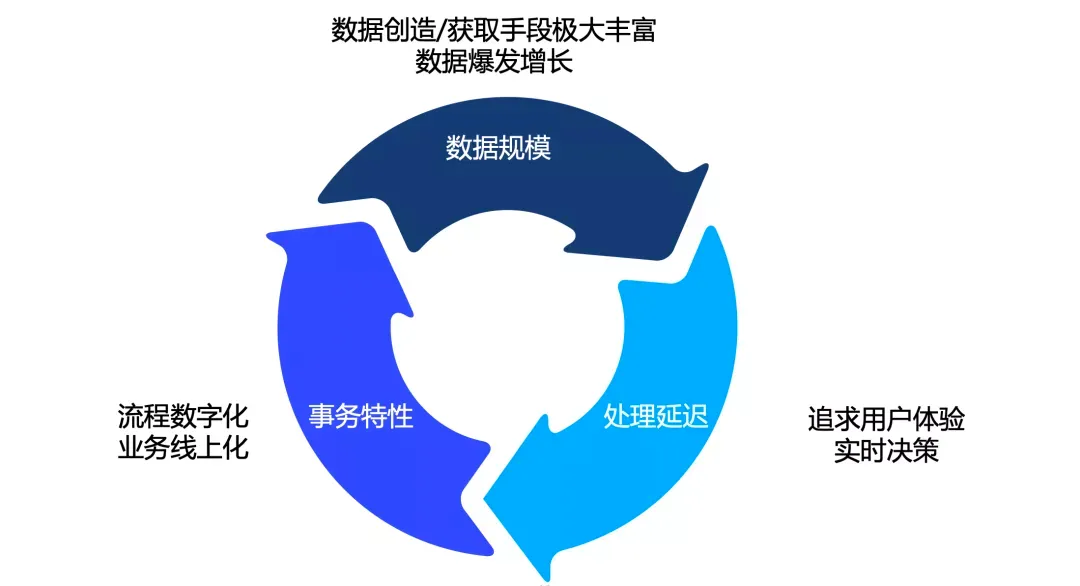
一是 “事务特性” ,也就是通常说的 ACID 原子性、一致性、隔离性、持久性。通俗来说,流程数字化、业务线上化都属于严肃业务,比如金融、电信等业务,以及企业级的 ERP、CRM,都要求可靠的事务特性。
二是 “数据规模” ,主要体现在互联网带来的海量数据爆发增长,不管是用户行为全面互联网化、或移动设备带来的数据采集极大丰富,还是内容本身的创造造成的数据海量暴涨,从文本到图片、动画、短视频、长视频、游戏再到最近很热的元宇宙,都是数据规模增长因素,在疫情的极致推动下,各个行业的数字化转型又催生了新一轮的数据增长。
三是 “处理延迟” ,在移动互联网及数字化的今天,对用户体验的追求水涨船高,ToC 业务希望更快地服务响应,从而争夺用户的碎片时间,争夺商业时机,ToB 业务对数据处理也需要更迅速的业务响应,更实时的数据分析和更敏捷的运营决策。
这三个因素在不同时期有不同的发展,还有不同的组合,不断催生并落地了数据技术的发展。不同的数据库生态,正是在业务驱动力的不同组合推进的结果。
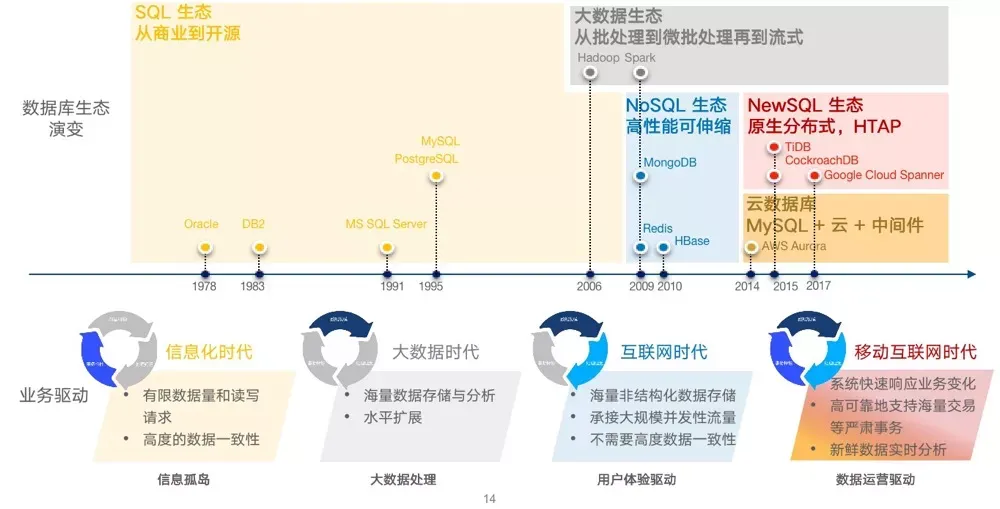
信息化时代数字基础弱,主要解决关键业务的准确性和效率问题,更多是小数据量的严肃业务,对数据有高度的事务特性要求,且数据结构稳定、规则清晰,数据量有限,这类需求关系型 SQL 单机数据库生态就能满足,要求的是效率和稳定。
2000 年左右进入大数据时代,经过信息化的长期发展,数据有了大量积累,新的数据也以前所未有的体量和速度增加,单机关系型数据库逐渐有了吃力和老态的迹象。为了对海量数据进行存储和分析,尤其是离线积累的数据,各类高效、可伸缩、可部署在低廉硬件上的大数据处理平台纷纷崭露头角。
而后的互联网时代初期,内容和用户线上行为都极大丰富,但当时主要是海量非结构化的数据存储(视频/音频/图文/社交关系等)、但数据规模庞大,要求并发性流量、同时争夺流量,快速响应用户访问、提供低延迟用户体验的需求驱动了 NoSQL 生态的发展。因为早期互联网业务不以盈利为目的,要处理的数据更多是用户在互联网上的浏览记录,社交关系等,所以对于事务特性上就没有那么高的要求。
进入移动互联网时代,随着数据量的迅猛增长,业务在保证良好用户体验的同时还要完成交易和变现,业务敏捷除了要求系统能快速响应业务变化和数据增长,还要求高可靠地支持海量交易、支付等严肃事务。可以看到,这时期业务驱动力的三要素都进入了视野。部分企业仍在通过 SQL 生态云化的过渡方式来满足,但我们也在实践中看到,当用户的数据量尤其数据更新超过一定范畴,原生分布式的 NewSQL 才是先进架构的选择。再加上数据技术都进入到全面云服务化的阶段,架构的差异就更加显露出来。
同时,实时洞察要求数据决策从 T+1 向 T+0 升级,甚至是秒级毫秒级的分析响应,实时汇聚多源数据、动态更新并灵活计算都是不断出现的需求,渐渐的事务性计算和分析性计算之间的分界越来越模糊,数据库和大数据的技术创新会不断融合。
数据库演进历史——基础设施驱动
最后,硬件是软件发挥作用的基石,数据技术的发展离不开基础设施的发展。
从大型机到 X86 服务器再到云计算,基础设施部署实现了从 “年” 到 “月”到“日”到“秒”的颠覆性变革,资源从专有、封闭到按需启动、弹性扩展。云原生时代再次把资源规模扩大,资源颗粒度缩小,API 化、微服务化进一步把业务上线、更新的速度推到秒级。
未来,资源分离的设计将在云上释放更大的威力。上面数据库发展的时间轴只画到了 NewSQL,实际上数据技术还在不断进化。相信在这个进程中,开源能够发挥的价值将越来越大。现在所有云的产品背后核心都来自于开源,创新源动力也是来自于开源。以下是在 2021 PingCAP DevCon 大会上,东旭提出的一个大胆假设:云原生的时代,所有能分离的都会分离,规模效应掌控一切。这个分离包括存储与计算的分离、更极致的是不同目的的存储与存储的分离,业务计算与分布式计算及事务性计算可以进一步分离。不断把规模效应和资源效率优化推向极致,而对于用户而言,只需要关注业务本身就好,其他的都交给云端的数据库来完成。
TiDB 产品迭代的启示
在这三个驱动力作用之下,我们可以总结下 TiDB 过去 6 年中产品的迭代来做个印证。
TiDB 产品最大的优势是技术开放性,架构开放就意味着能够产生更多的连接,更多连接意味着更快的迭代速度、更多的可能性。
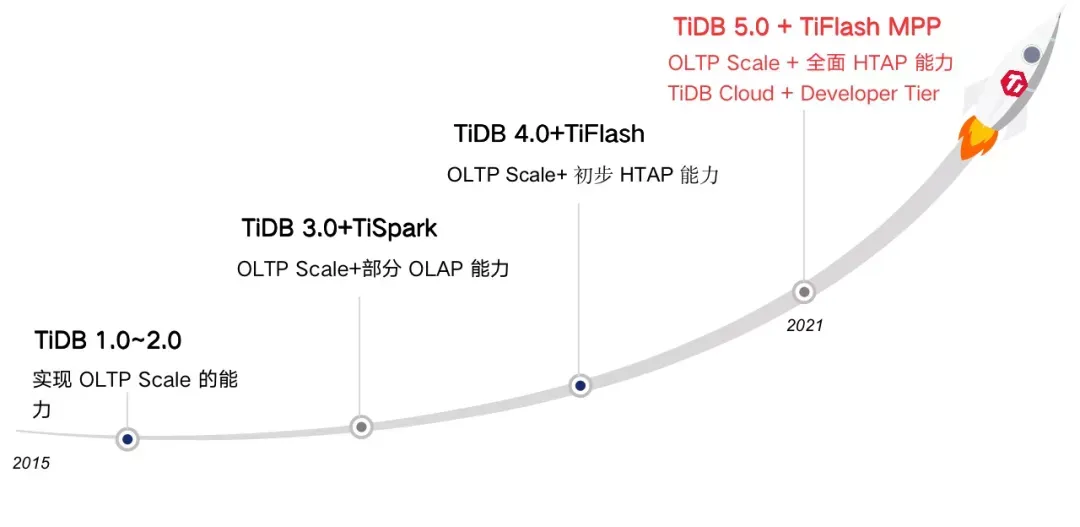
TiDB 的初心是希望提供一个原生分布式且良好支持 OLTP 事务的数据库,让我们的 DBA 不再因为海量数据的分库分表加班熬夜。TiDB 1.0 和 2.0 解决的就是这个问题。后来随着数字化带来的实时化诉求,一栈式 HTAP 成为我们的努力方向,伴随今年 TiFlash MPP 的发布,我们已实现全面的 HTAP 能力。
作为云原生的分布式数据库,我们在今年推出了 TiDB Cloud,以及免费开放给开发者试用的 Developer Tier,用户可以在 Amazon Web Services 上免费运行 TiDB 集群一年。TiDB Cloud 负责基础设施管理、集群部署、备份管理等所有后台数据库管理,让开发者可以专注于打造优秀的应用,实现秒级切换。所有这些都基于开源带给我们的迭代速度和创新源动力。
最后用 RedHat CEO Paul Cormier 最近在电视采访中说过的一句话作为总结:Open source software is the heart of the technology behind cloud computing。
是不是开源,是不是要去做开源,是不是要把开源作为公司持续创新的外在推动,我认为是每一家基础软件公司都可以去深度思考的一个问题。
[1] 国内典型的企业:包括阿里、百度、腾讯、字节、美团、滴滴、华为、京东、小米、网易、Bilibili、微众、携程、PingCAP 等 40 多家公司
[2] 活跃仓库:指在一年中有发生过至少一项事件的仓库,如 PushEvent、IssueCommentEvent、ReleaseEvent、PullRequestEvent等(总计有21 类事件)