
导读
从 v6.5.0 开始,TiCDC 支持将行变更事件保存至存储服务,这给 TiDB + 数据仓库带来了更多可能。本文由 TiDB 社区版主、数据架构师数据小黑撰写,结合生产中的实际需求和测试结果,分享了他对 TiDB + 数据仓库共建的构想。
背景
最近 TiDB V6.5.0 发版了,已经浸润在数据中多年,我对一个特性特别感兴趣:从 v6.5.0 开始,TiCDC 支持将行变更事件保存至存储服务,如 Amazon S3、Azure Blob Storage 和 NFS。
简言之,这个特性能够通过 TiCDC 这一个组件,就能保存 CDC 日志到对象存储中,这个特性满足了我对数据架构的一些想象,例如:
- 数据链路足够短
- 同步组件尽量少
结合这个特性,基于最近的一些实际需求和 POC 的成果,我想聊一聊与 TiDB 搭配的数据仓库应该是什么样的,是否能够有一个足够简单的架构,搭建一个适配大多数云的数据仓库。
何为数据仓库,何为数据库
数据仓库,英文名称为 Data Warehouse,可简写为 DW 或 DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。怎么理解上面这个解释,根据我们遇到的客户的诉求,数据仓库都是干这些事的:
- 大型企业内有各种各样的内部系统,一般情况下,这些业务系统建设时间不同,建设厂商不同,甚至于底层数据产品都有较大差异。领导要看全局,看大数,看趋势,需要一个架构把数据整合起来,这个架构叫做数据仓库
- 一个企业内的数据相对比较单一,企业通过各种渠道汇集了多种多样的数据放在一起进行分析,这时候需要一个架构来解决采集数据的存储、计算、服务等多种问题,这个架构叫做数据仓库
以上的需求整合的数据,在整合之前就可以被准确认知,知道整合的目的。
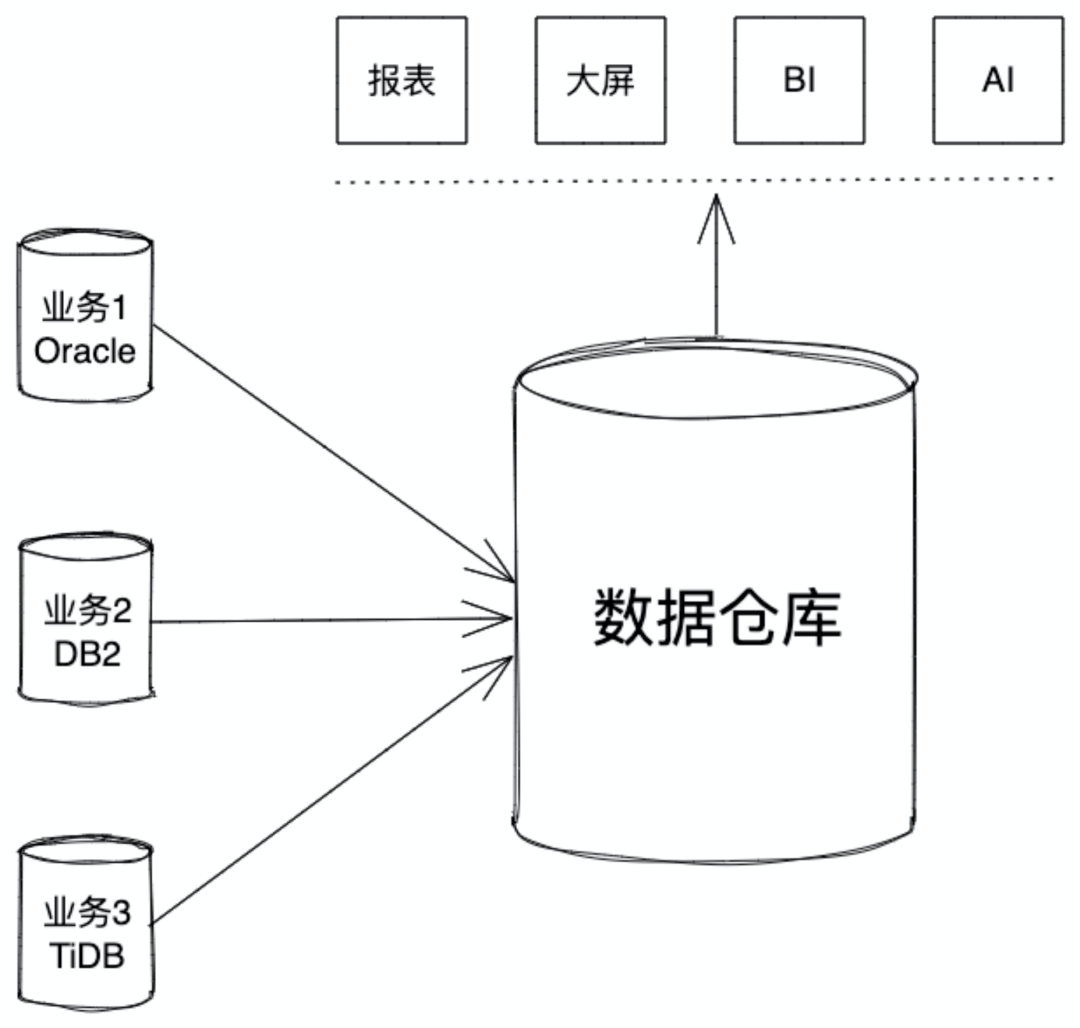
假如企业基于战略目的,先执行收集数据的动作,然后从收集的数据中挖掘价值,此时的架构应该叫做数据湖。
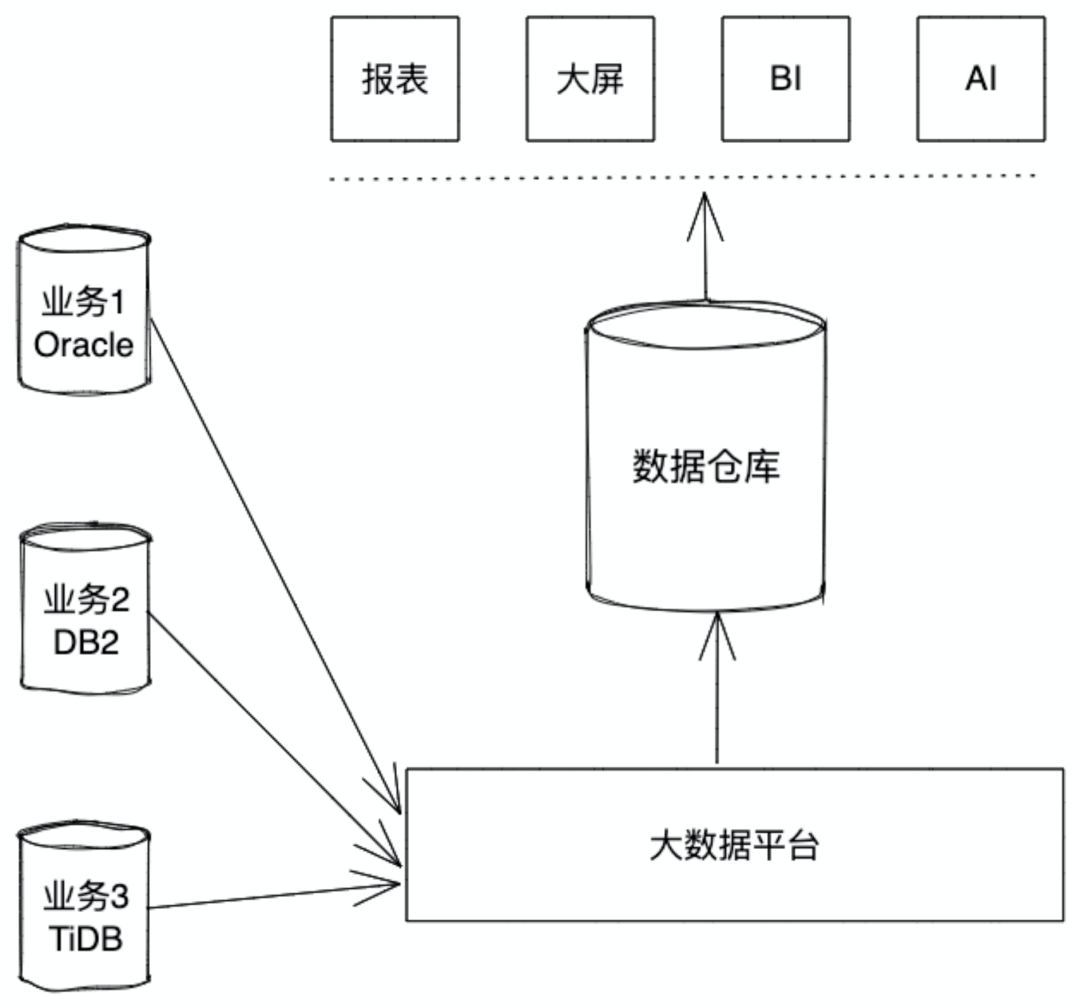
本篇文章不纠结这两个概念,只是想讨论一个场景:
- 业务应用的后端数据库是 TiDB
- 有分析较久远历史数据的需求
- 有接入第三方数据综合分析的需求
- 硬件投资有限,需要合理的架构充分发挥硬件性能
- 客户的部署环境不确定,需要适配大多数云
这是我们实际遇到的需求,我们也做了一些思考和 POC 测试。
TiDB 与数据仓库共建的必要性
对 TiDB 比较了解的人会知道 TiDB 有两个组件来解决 AP 侧的问题:
TiFlash
TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引配合 MVCC 的方式获得 Snapshot Isolation 的一致性隔离级别。这个架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题。
TiSpark
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。它借助 Spark 平台,同时融合 TiKV 分布式集群的优势,和 TiDB 一起为用户一站式解决 HTAP (Hybrid Transactional/Analytical Processing) 的需求。TiFlash 和 TiSpark 都允许使用多个主机在 OLTP 数据上执行 OLAP 查询。TiFlash 是列式存储,这提供了更高效的分析查询。TiFlash 和 TiSpark 可以同时使用。
我们已经在多个场景下,组合使用了 TiFlash 和 TiSpark,在我们的应用场景下,数据流转如下图:
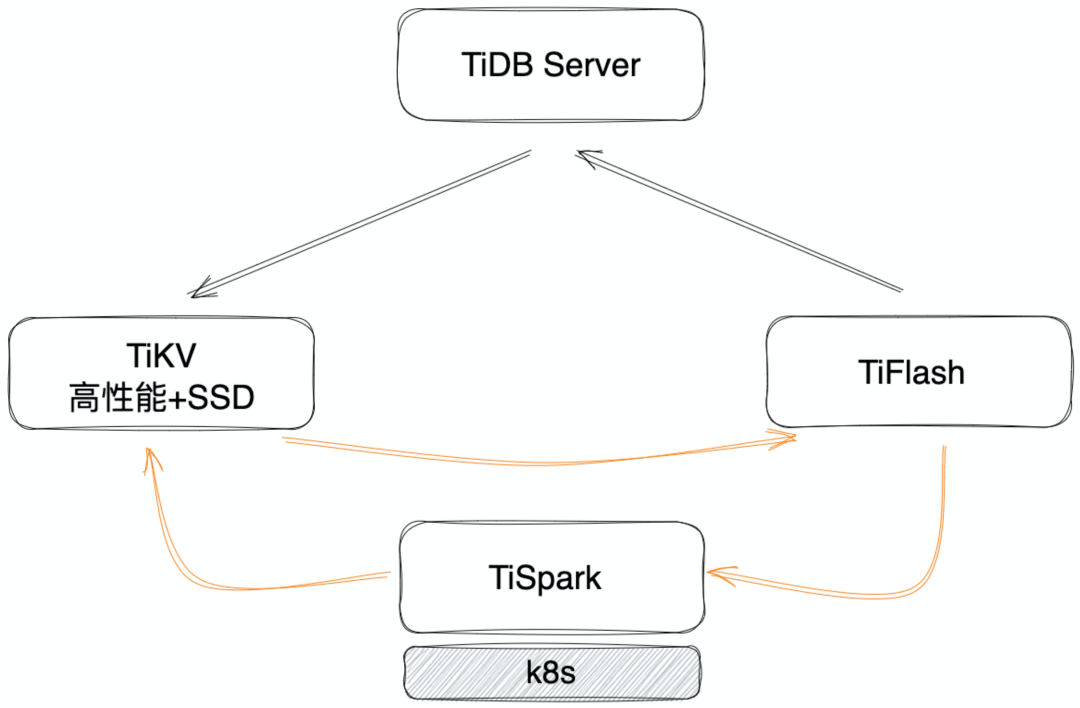
这个架构解决了我们的问题,但是有个小缺点,就是成本相对比较高。
- 从数据同步链路上讲:数据在计算完成之后,需要经过 TiKV 写到 TiFlash,这样的做法不是太经济
- 从硬件成本上讲:为了保证数据写入效率,TiKV 和 TiFlash 的硬件我们都给的比较好,因为各种因素影响,我们并没有在较差的硬件下测试,所以在较差硬件条件下效率差多少,我们没有实际数据,也没太有信心进行测试
- 从架构设计上来讲:假如要接入第三方数据,完全没必要从 TiKV 走一遍,这些数据仅仅作为分析的需求,没有必要占用 TP 的资源
随着我们客户的发展,我们现在遇到一些问题:
- 客户的分析需求爆发式增长,通常要求我们在有限的成本下,尽可能地提高效率
- 数据的采集方式复杂多样,一不小心就对 TP 侧产生影响,我们加了消息队列做消峰处理
基于以上分析,单纯的使用 TiFlash、TiSpark 并不能完全贴合我们的诉求,基于我们多年的技术积累,我们架构了一套跟 TiDB 打通的数据仓库架构,具有低成本、多云适配的特性,下一节做一些分析,给大家参考。
打通 TiDB 与数据仓库的建构设想
先来看看现在通用的大数据架构:
我们在设计数据架构的时候,因数据规模的原因采用了 hadoop 体系作为底座,理论上 TiDB 的数据可以直接接入这一套产品中。我们在推广项目的过程中发现了一些问题:
- 客户投资不多,hadoop 的云产品太贵,客户没有采购,我们无法迁移
- 客户投资充裕,被云厂商洗脑,只买了 hadoop serverless 版本,各厂商的 api 和 sql 规范都不一样,造成我们一个项目一套代码
- 有一些项目前期数据规模并不大,客户对先期投入一套大数据产品十分不理解,我们基于这一套架构也做不到伸缩自由
基于以上原因,我们打算研究了一套替代 hadoop 的架构,对于一些主要环节我们做了一些决策:
- 存储产品:基于 OSS 在云产品中的地位和性价比,存储采用 OSS
- 计算环境:我们并不想投入人力管理计算资源的调度,采用事实标准 k8s 做资源的调度
- api 形态:我们原来的计算流程需要编程,在这次架构设计中,我们打算提供 JDBC 接口,类似打造一个 serverless 的计算服务
我们设计的架构如下:
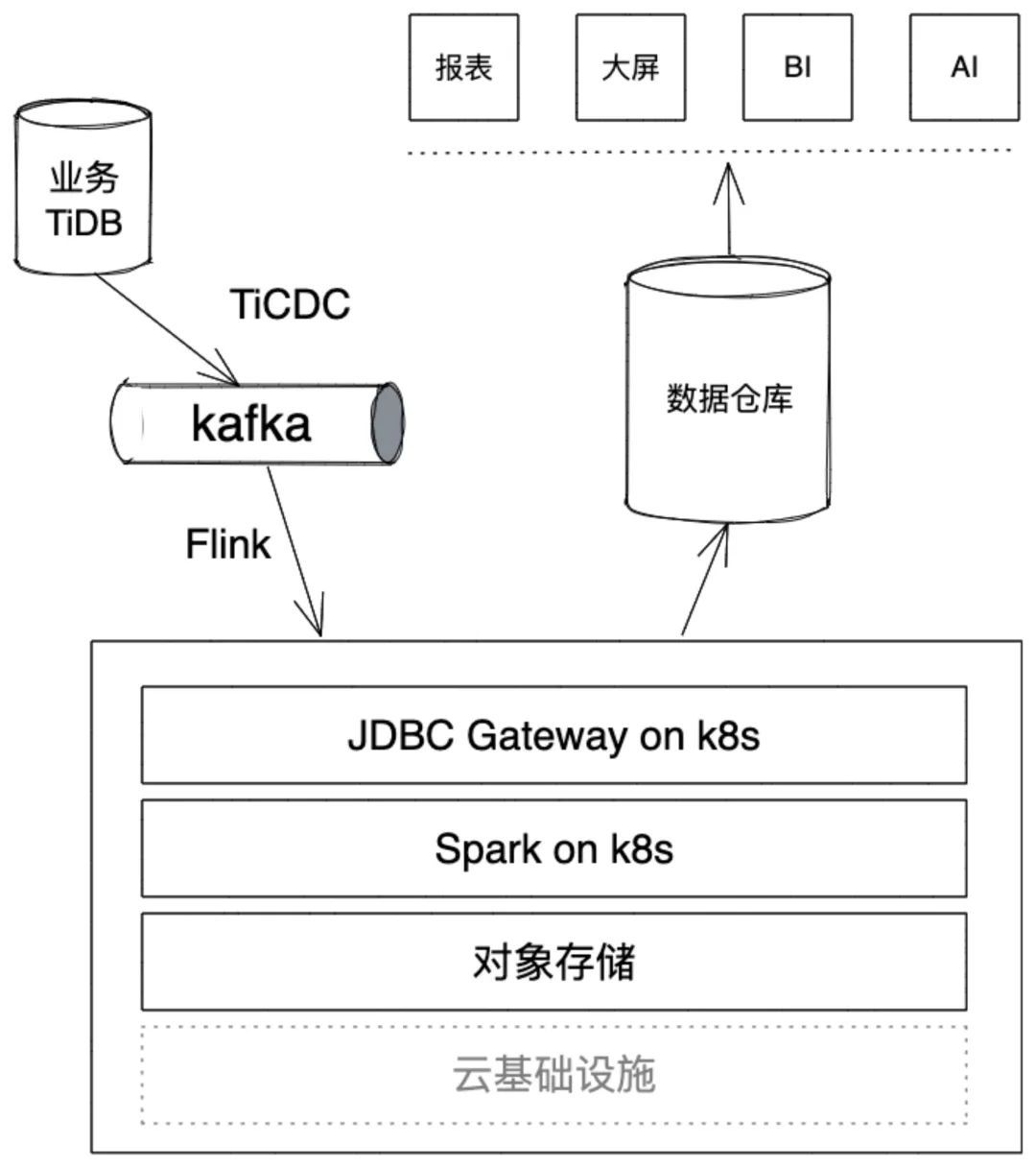
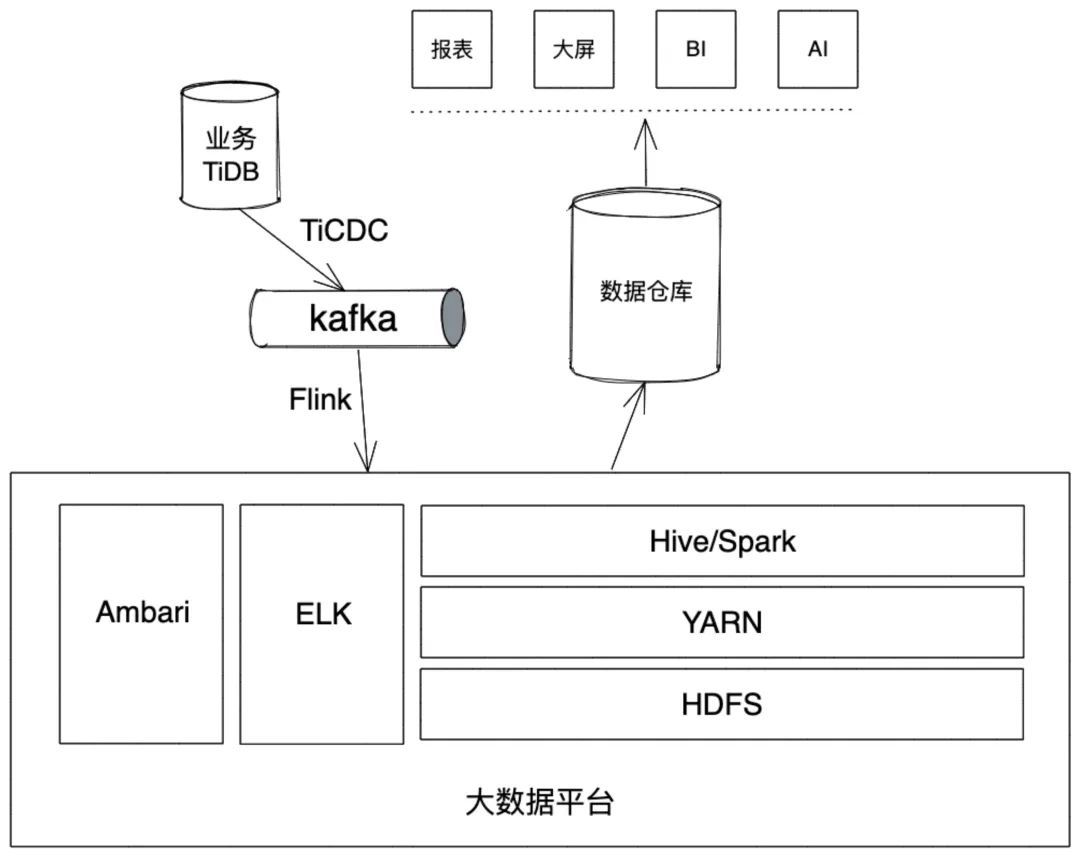
与前一个架构相比,我们没有部署任何组件,依托 k8s 实现了计算的调度和数据的访问,k8s 和对象存储也不需要我们管理维护,减掉我们大部分的运维工作。基于 k8s 和对象存储的通用性,我们这套架构在大部分云上都可以无缝迁移;运行时资源也具有较好的弹性,可以随着数据规模做资源规模的伸缩。这一套架构其实有点小缺点就是必须还要配套一个 kafka,我们把 TiDB 版本升级到 v6.5.0 之后,架构简化如下:
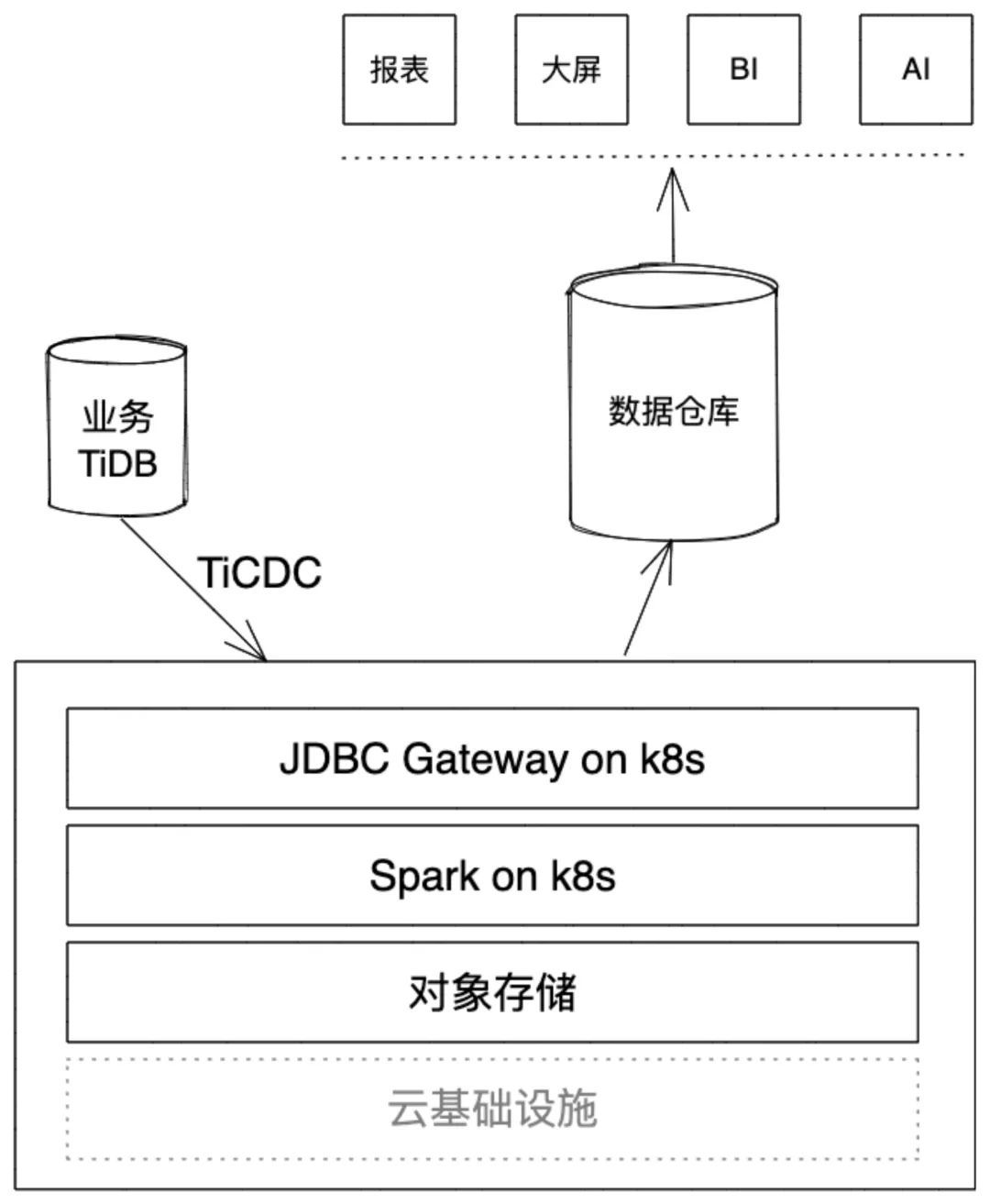
为什么我对存在 kafka 的数据链路叫做一个小缺点,而把直接写对象存储,更感兴趣,或者说 v6.5.0 这么多优秀特性,我却对这一点情有独钟。从长期的运维经验来看,我们有过一些不好的经验:
- 从部署的角度来讲,多一个组件,就多一套部署脚本、多一分管理成本。在人员充足的项目,可能是一个不大的问题,但我们很多项目只有一到两个运维人员,从这个角度看,其实组件越少越好,因为他们精力有限,很多组件不会管理,或者说根本不知道有这么多组件存在,这就很尴尬。长此以往,一线说二线不好,二线说一线不行,团队氛围很不好,事情也干不好。
- 从高可用的角度来讲,维护的环节越多,出错的可能性越大,可靠性越差。我们曾经在同步的源库和目标库之间设置了三个组件(具体原因不再详述),这样的设计有很高的数据吞吐能力,但是对于高频更新的表,总是感觉少数据。我们用 Otter+TiDB 的链路代替了原有链路之后,问题消失了。事后追查根本原因是我们的配置有问题,导致了同步过程中数据覆盖不全。组件越多,配置越多,即使在人员充足的情况下,也可能有疏漏。
所以,我目前的思路是同步链路越短、配置越简单,数据可靠性越高。
结语
综上所述,v6.5.0 发布了 TiCDC 支持将行变更事件保存至存储服务的特性,基于这个特性,同步链路的架构设计也有了改善。我们对上述架构做了很多 POC 测试,也将会在下一步实践中总结更多经验。希望我们的思考能够给大家更多启发。
目录