
数据库调优可以使数据库应用运行得更快,但对于很多人来说,对数据库内核进行调优是一项很有挑战的“技术活”,是只属于少部分内核研发们的“游戏”。但即使是他们,对数据库内核进行性能调优,也充满了不确定性,它需要综合考虑各种复杂因素,如硬件层面的 CPU、 I/O、 内存和网络,以及软件层面关于操作系统、中间件、数据库参数等配置,还有运行在数据库上的各种查询和命令等。在本次 Hackathon 2021 比赛中,TPC 战队就完成了这一项“挑战”,采用 bottom-up 的设计思路,更好地利用硬件资源,使用 TPC (thread-per-core) 线程模型优化了 TiKV 的写入性能、性能稳定性和自适应能力。TPC 战队也凭借这一硬核项目一举斩获了三等奖与技术潜力奖。
“该项目是本届 Hackathon 中最硬核的项目,我给了非常高的分数。 TPC 在其中做了非常多的工作,我预感到后续落地的难度,他们用了 io uring,不过貌似也遇到了不少的坑,后面也可以选择 AIO 或者单独的异步线程机制。因为用了新的 raft engine(这个会在 TiDB 5.4 GA),也很方便做 parallel log write,充分利用多队列 IO 特性。这个特性在 Cloud 上面也是很关键的,因为 EBS 这些盘单线程写入 IOPS 其实真不高。另外,我看他们后面还会去掉 KV RocksDB 的 WAL,这样几个线程池就真能合并,只做计算操作,IO 操作都完全变成异步了。”
——评委唐刘
TPC 战队由来自 TiDB 分布式事务研发团队的陈奕霖与赵磊组成,其中,陈奕霖从 2019 年就参加 TiDB Hackathon ,并凭借线程池项目拿了当年的一等奖,而彼时他还是一名刚刚进入 PingCAP 的实习生。如今已毕业的他,留在 PingCAP 继续做事务相关的研发工作,已经是一名 TiDB Hackathon 老选手了。
TiDB Hackathon 的魅力
陈奕霖:其实对于 PingCAPer 而言, Hackathon 是一个发现更多可能性的机会。我们平时工作中都有着很多紧迫的项目,没机会探索 TiDB 更多新的可能性,Hackathon 就给予这样的机会。在平时的工作场景中,我们经常会产生一些想法,但没机会去尝试。 在 Hackathon 中就可以将这些想法实践出来,并通过 DEMO 展示它的效果与潜力,如果实现得好,最后还有可能落地进入生产代码。
项目灵感来源
陈奕霖:赵磊非常渴望做这个项目,项目灵感也主要来源于他。平时在做内核开发以及解决一些用户问题时,我们发现 TiKV 的整体性能比较一般,并且有着很强的不确定性,难以调优。赵磊在研究另一款数据库产品的代码时,发现那个架构中的一些技术其实可以有效提升 TiKV 的性能。所以就想把该产品架构思路中用到的一些技术应用到 TiKV 来,看是否能提升 TiKV 的性能以及稳定性。
TPC 项目的首要目的在于性能提升,TiKV 对于资源的利用一直不是很好,如对 CPU 或 IO 资源利用不充分,通过该架构可以通过并发写 WAL 实现对 IO 资源的充分利用。线程池方面的新架构也可以比较合理地去规划 CPU 的资源使用,特别是在云环境下,可以让 TiKV 得到更稳定、更可预期的性能。
比赛中的异步协作
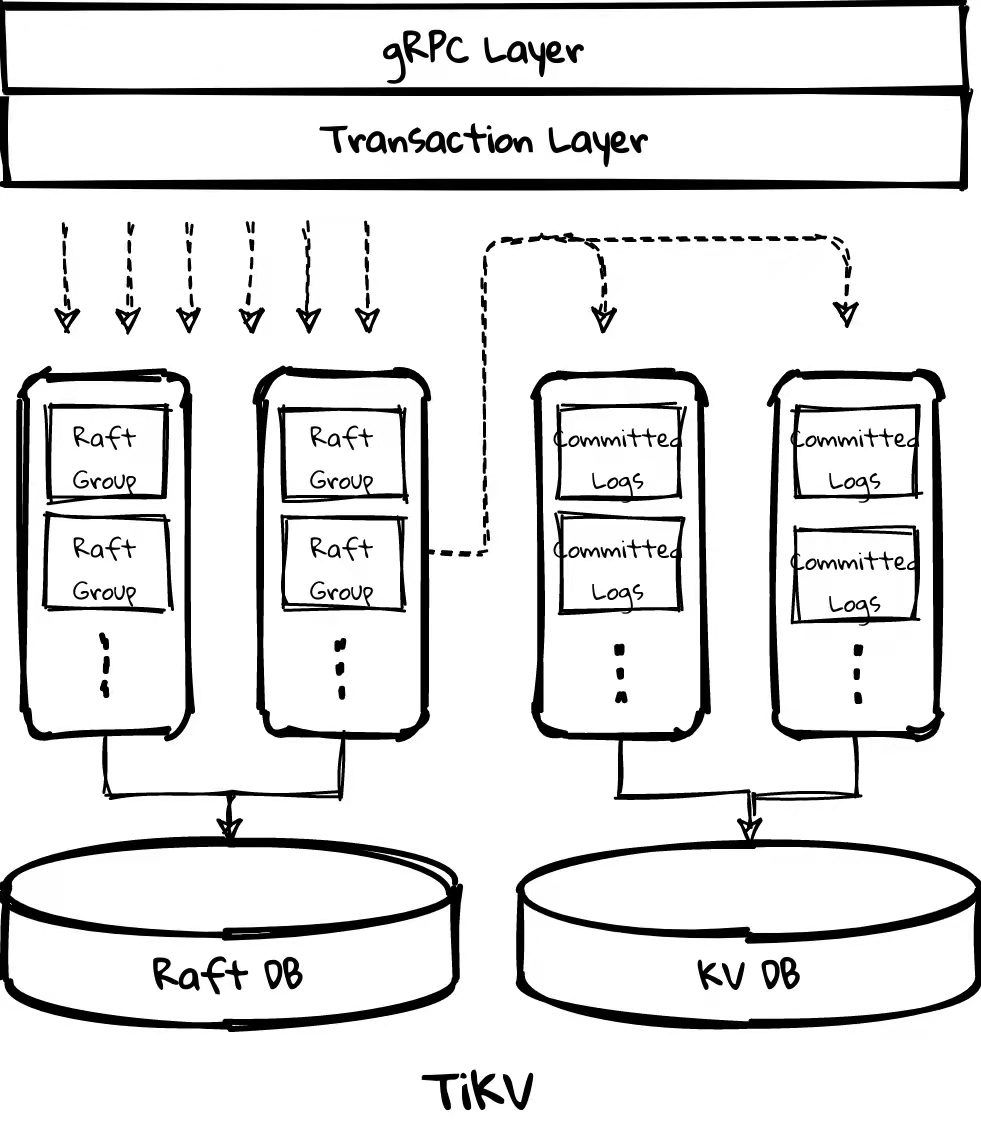
陈奕霖:我们差不多在元旦假期才开始做初步开发工作,与平常工作时差不多,我们大部分时间还是异步化的协作,我有什么进展就直接同步给赵磊,这个过程可能会通过邮件或 Github 通知进行。开发过程主要分为两大块:一方面是改 TiKV 本身的 raftstore ,这是赵磊做的。另一方面是关于 Raft engine, TiKV 用来存储 Raft 日志的一个组件,我来它的异步化以及写的并发化。
其中,Raftstore 包含两个 thread pool:
- store pool 用于处理 raft message、append log 等,raft log 会写入 raft db;
- apply pool 用于处理 committed log,数据会写入 kv db,目前 raft db 和 kv db 均使用 RocksDB,之后 raft db 会切换到 raft-engine。
RocksDB 无法很好利用现代高速硬盘,它的 foreground write (WAL) 只能提供 1 个 I/O depth 且 write group 间同步、排队的消耗很大,而 NMVe SSD 等高速硬盘需要高的 I/O depth 来打满 IOPS,或者大的 I/O size 加上不那么高的 I/O depth 来打满 bandwidth,但大的 I/O size 不适合 OLTP 系统,因为攒大 batch 通常意味着高延迟。
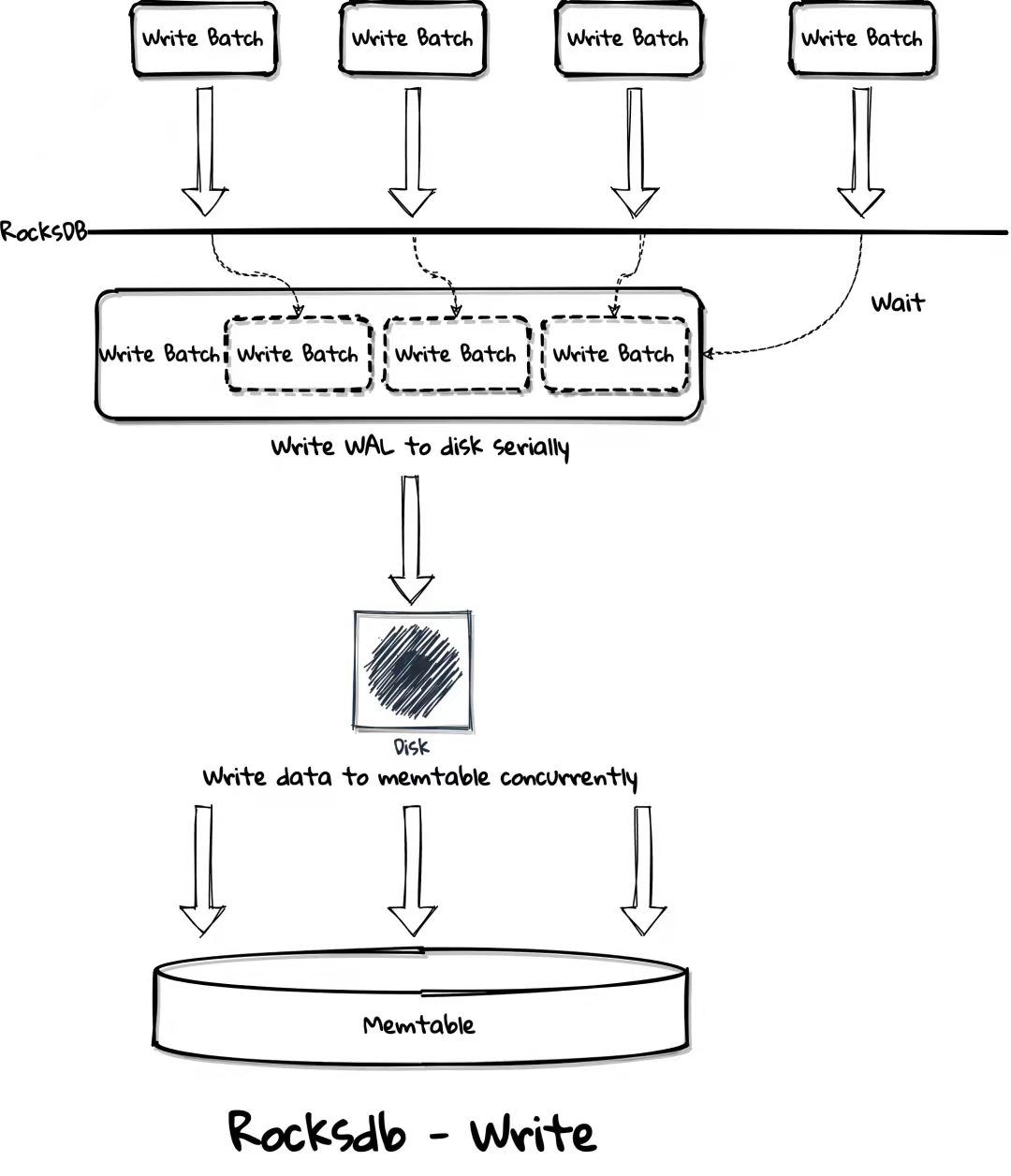
为了优化 TiKV 的 disk 使用,raft engine 需要支持并发写 WAL 或者拆分 raft db 来并行写多个 WAL 文件,为了更公平和 upstream TiKV 做性能对比,本次 Hackathon 没有对数据模型做很大改动,会实现并行写 WAL,不会拆分 raft db。而为了最大化 disk 压力、更好的 CPU 使用率以及更好的性能稳定性,TPC 选择使用 async I/O 来实现该功能。
Store pool 实现了上述功能后,它的性能应该会大幅优于 apply pool,但可能会消耗更多的资源从而影响整体的性能,如消耗了更多的 CPU 和 disk I/O 资源导致 apply pool 变慢、积攒太多 committed logs 导致 OOM 等,且整个 pipeline 的性能受限于最慢的一个阶段,需要根据最慢的阶段做 back pressure,如调整 store pool 和 apply pool 的线程数量从而保证速度匹配。但拆分多个线程池实在是不易用、不灵活,为了避免手动调优,我们将 store pool 和 apply pool 合并为单个线程池。为了实现这一目标,raft engine 使用 async I/O 也是必需的,kv db 同样需要使用 async I/O,但 kv db 理论上可以不写 WAL,因为数据可通过 raft log 回放且该功能已有方案,在 Hackathon 上会强行去掉 kv db 的 WAL。除了 async I/O 外,还需要实现 CPU scheduler 来保证当 CPU 成为瓶颈时,单个线程内不同任务成比例地使用资源,如原来 store pool 和 apply pool 的任务各使用 50% 的 CPU 资源。
有了 CPU scheduler 后可以把更多的线程池合并在一起从而实现真正的 unified thread pool,如 gRPC thread pool、scheduler worker pool、unified read pool、RocksDB background threads、backup thread pool 等,CPU scheduler 会给每个原先 thread pool 的任务分配一定比例的资源,且可动态调整,从而提升资源紧张时的性能稳定性,实现自适应,避免手动调参。
遇到的最大技术困难
陈奕霖:这一次我们用的各种技术都是特别激进和核心的技术,遇到了很多依赖库或者 Linux 内核的一些意外情况,编写时有一些东西并不符合预期。比如说我们用的 thread per core 库,当我们想要根据 latency 去做抢占的时候,它在绝大多数的内核上都不能工作。
此外,我们在 AWS 上尝试了很多种内核。当使用 AWS Linux 默认提供的内核配合 IO uring ,遇到很多问题。后来,我们辗转到一个更新的内核上终于可以使用了。另一方面是文件系统,我们常用的有 ext4 和 xfs 两种文件系统,它们在异步写的行为有一些区别,我们也是尝试多种内核以及换不同的文件系统后,才终于找到某一种组合,基本符合我们对于异步写的行为预期。我们整体过程中遇到的最大问题,就是用的的技术太不成熟了,遇到了很多内核方面的坑,这方面其实还挺痛苦的。
比赛过程中有什么遗憾?
陈奕霖:比较遗憾的是时间比较紧,对整个系统的调优还没有调到比较好的程度,最后效果比我们想象中的要差一点。在整个过程中,我们花了大量的时间让这个项目跑起来,让它基本符合我们的预期。
比赛中有一个有趣的事,我其实一直都不清楚队伍的宣言是什么,后来到现场才发现队旗下面的小字写的是“冠军被我内定 or 小丑竟是我自己”,结果在 Hackathon 的前几天,我突然发现赵磊把他的头像改成了小丑……
本次比赛体验
陈奕霖:之前赵磊跟我们分享其他技术架构时,还只是一个理念或者概念层面上的,实际运用到 TiDB 上会怎么样? TiKV 的问题究竟是不是在这里?其实我们也不是很清楚。通过这次 Hackathon ,我们证明了这个想法一定程度是对的,是确实有用的,TiKV 也因此得到了改进。我想这也是 TPC 这个项目给 TiKV 这个产品的进化验证了一条正确的路。
对项目未来有什么期待?
陈奕霖:我觉得如果直接把这次在 Hackathon 上使用的技术栈应用到 TiKV 上,可能还不是特别可行。就像唐刘老师在评价中提到的,我们用 io uring 遇到了很多问题,但是其实可以转而求其次去使用 Linux AIO 之类的。同时,像 Raft engine 这个东西,它的异步化未来也是可以推进的。这个项目比较大的作用就是指明了 TiKV 可能的演进方向。
延展阅读:点击查看更多 TiDB Hackathon 2021 优秀项目分享
目录