
本文为 TiKV 源码解析系列的第四篇,接上篇继续为大家介绍 rust-prometheus。《TiKV 源码解析系列文章(三)Prometheus(上)》 主要介绍了基础知识以及最基本的几个指标的内部工作机制,本篇会进一步介绍更多高级功能的实现原理。
与上篇一样,以下内部实现都基于本文发布时最新的 rust-prometheus 0.5 版本代码,目前我们正在开发 1.0 版本,API 设计上会进行一些简化,实现上出于效率考虑也会和这里讲解的略微有一些出入,因此请读者注意甄别。
指标向量(Metric Vector)
Metric Vector 用于支持带 Label 的指标。由于各种指标都可以带上 Label,因此 Metric Vector 本身实现为了一种泛型结构体,Counter、Gauge 和 Histogram 在这之上实现了 CounterVec、GaugeVec 和 HistogramVec。Metric Vector 主要实现位于 src/vec.rs。
以 HistogramVec 为例,调用 HistogramVec::with_label_values 可获得一个 Histogram 实例,而 HistogramVec 定义为:
pub type HistogramVec = MetricVec<HistogramVecBuilder>;
pub struct MetricVec<T: MetricVecBuilder> {
pub(crate) v: Arc<MetricVecCore<T>>,
}
impl<T: MetricVecBuilder> MetricVec<T> {
pub fn with_label_values(&self, vals: &[&str]) -> T::M {
self.get_metric_with_label_values(vals).unwrap()
}
}因此 HistogramVec::with_label_values 的核心逻辑其实在 MetricVecCore::get_metric_with_label_values。这么做的原因是为了让 MetricVec 是一个线程安全、可以被全局共享但又不会在共享的时候具有很大开销的结构,因此将内部逻辑实现在 MetricVecCore,外层(即在 MetricVec)套一个 Arc<T> 后再提供给用户。进一步可以观察 MetricVecCore 的实现,其核心逻辑如下:
pub trait MetricVecBuilder: Send + Sync + Clone {
type M: Metric;
type P: Describer + Sync + Send + Clone;
fn build(&self, &Self::P, &[&str]) -> Result<Self::M>;
}
pub(crate) struct MetricVecCore<T: MetricVecBuilder> {
pub children: RwLock<HashMap<u64, T::M>>,
// Some fields are omitted.
}
impl<T: MetricVecBuilder> MetricVecCore<T> {
// Some functions are omitted.
pub fn get_metric_with_label_values(&self, vals: &[&str]) -> Result<T::M> {
let h = self.hash_label_values(vals)?;
if let Some(metric) = self.children.read().get(&h).cloned() {
return Ok(metric);
}
self.get_or_create_metric(h, vals)
}
pub(crate) fn hash_label_values(&self, vals: &[&str]) -> Result<u64> {
if vals.len() != self.desc.variable_labels.len() {
return Err(Error::InconsistentCardinality(
self.desc.variable_labels.len(),
vals.len(),
));
}
let mut h = FnvHasher::default();
for val in vals {
h.write(val.as_bytes());
}
Ok(h.finish())
}
fn get_or_create_metric(&self, hash: u64, label_values: &[&str]) -> Result<T::M> {
let mut children = self.children.write();
// Check exist first.
if let Some(metric) = children.get(&hash).cloned() {
return Ok(metric);
}
let metric = self.new_metric.build(&self.opts, label_values)?;
children.insert(hash, metric.clone());
Ok(metric)
}
}现在看代码就很简单了,它首先会依据所有 Label Values 构造一个 Hash,接下来用这个 Hash 在 RwLock<HashMap<u64, T::M>> 中查找,如果找到了,说明给定的这个 Label Values 之前已经出现过、相应的 Metric 指标结构体已经初始化过,因此直接返回对应的实例;如果不存在,则要利用给定的 MetricVecBuilder 构造新的指标加入哈希表,并返回这个新的指标。
由上述代码可见,为了在线程安全的条件下实现 Metric Vector 各个 Label Values 具有独立的时间序列,Metric Vector 内部采用了 RwLock 进行同步,也就是说 with_label_values() 及类似函数内部是具有锁的。这在多线程环境下会有一定的效率影响,不过因为大部分情况下都是读锁,因此影响不大。当然,还可以发现其实给定 Label Values 之后调用 with_label_values() 得到的指标实例是可以被缓存起来的,只访问缓存起来的这个指标实例是不会有任何同步开销的,也绕开了计算哈希值等比较占 CPU 的操作。基于这个思想,就有了 Static Metrics,读者可以在本文的后半部分了解 Static Metrics 的详细情况。
另外读者也可以发现,Label Values 的取值应当是一个有限的、封闭的小集合,不应该是一个开放的或取值空间很大的集合,因为每一个值都会对应一个内存中指标实例,并且不会被释放。例如 HTTP Method 是一个很好的 Label,因为它只可能是 GET / POST / PUT / DELETE 等;而 Client Address 则很多情况下并不适合作为 Label,因为它是一个开放的集合,或者有非常巨大的取值空间,如果将它作为 Label 很可能会有容易 OOM 的风险。这个风险在 Prometheus 官方文档中也明确指出了。
整型指标(Integer Metric)
在讲解 Counter / Gauge 的实现时我们提到,rust-prometheus 使用 CAS 操作实现 AtomicF64 中的原子递增和递减,如果改用 atomic fetch-and-add 操作则一般可以取得更高效率。考虑到大部分情况下指标都可以是整数而不需要是小数,例如对于简单的次数计数器来说它只可能是整数,因此 rust-prometheus 额外地提供了整型指标,允许用户自由地选择,针对整数指标情况提供更高的效率。
为了增强代码的复用,rust-prometheus 实际上采用了泛型来实现 Counter 和 Gauge。通过对不同的 Atomic(如 AtomicF64、AtomicI64)进行泛化,就可以采用同一份代码实现整数的指标和(传统的)浮点数指标。
Atomic trait 定义如下(src/atomic64/mod.rs):
pub trait Atomic: Send + Sync {
/// The numeric type associated with this atomic.
type T: Number;
/// Create a new atomic value.
fn new(val: Self::T) -> Self;
/// Set the value to the provided value.
fn set(&self, val: Self::T);
/// Get the value.
fn get(&self) -> Self::T;
/// Increment the value by a given amount.
fn inc_by(&self, delta: Self::T);
/// Decrement the value by a given amount.
fn dec_by(&self, delta: Self::T);
}原生的 AtomicU64、AtomicI64 及我们自行实现的 AtomicF64 都实现了 Atomic trait。进而,Counter 和 Gauge 都可以利用上 Atomic trait:
pub struct Value<P: Atomic> {
pub val: P,
// Some fields are omitted.
}
pub struct GenericCounter<P: Atomic> {
v: Arc<Value<P>>,
}
pub type Counter = GenericCounter<AtomicF64>;
pub type IntCounter = GenericCounter<AtomicI64>;本地指标(Local Metrics)
由前面这些源码解析可以知道,指标内部的实现是原子变量,用于支持线程安全的并发更新,但这在需要频繁更新指标的场景下相比简单地更新本地变量仍然具有显著的开销(大约有 10 倍的差距)。为了进一步优化、支持高效率的指标更新操作,rust-prometheus 提供了 Local Metrics 功能。
rust-prometheus 中 Counter 和 Histogram 指标支持 local() 函数,该函数会返回一个该指标的本地实例。本地实例是一个非线程安全的实例,不能多个线程共享。例如,Histogram::local() 会返回 LocalHistogram。由于 Local Metrics 使用是本地变量,开销极小,因此可以放心地频繁更新 Local Metrics。用户只需定期调用 Local Metrics 的 flush() 函数将其数据定期同步到全局指标即可。一般来说 Prometheus 收集数据的间隔是 15s 到 1 分钟左右(由用户自行配置),因此即使是以 1s 为间隔进行 flush() 精度也足够了。
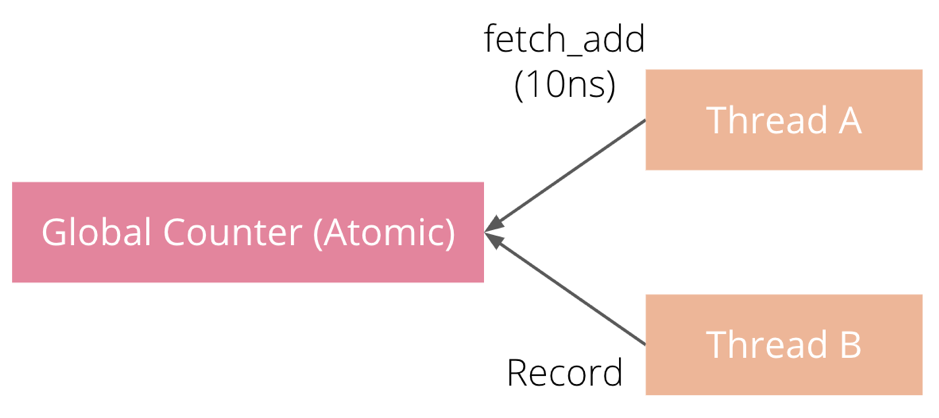
普通的全局指标使用流程如下图所示,多个线程直接利用原子操作更新全局指标:
本地指标使用流程如下图所示,每个要用到该指标的线程都保存一份本地指标。更新本地指标操作开销很小,可以在频繁的操作中使用。随后,只需再定期将这个本地指标 flush 到全局指标,就能使得指标的更新操作真正生效。
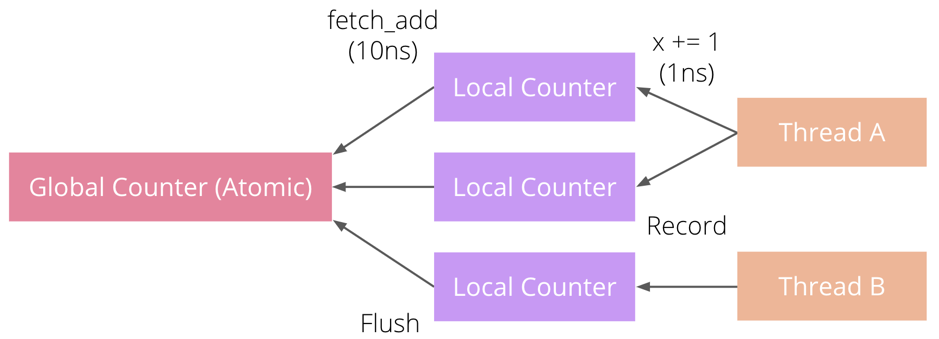
TiKV 中大量运用了本地指标提升性能。例如,TiKV 的线程池一般都提供 Context 变量,Context 中存储了本地指标。线程池上运行的任务都能访问到一个和当前 worker thread 绑定的 Context,因此它们都可以安全地更新 Context 中的这些本地指标。最后,线程池一般提供 tick() 函数,允许以一定间隔触发任务,在 tick() 中 TiKV 会对这些 Context 中的本地指标进行 flush()。
Local Counter
Counter 的本地指标 LocalCounter 实现很简单,它是一个包含了计数器的结构体,该结构体提供了与 Counter 一致的接口方便用户使用。该结构体额外提供了 flush(),将保存的计数器的值作为增量值更新到全局指标:
pub struct GenericLocalCounter<P: Atomic> {
counter: GenericCounter<P>,
val: P::T,
}
pub type LocalCounter = GenericLocalCounter<AtomicF64>;
pub type LocalIntCounter = GenericLocalCounter<AtomicI64>;
impl<P: Atomic> GenericLocalCounter<P> {
// Some functions are omitted.
pub fn flush(&mut self) {
if self.val == P::T::from_i64(0) {
return;
}
self.counter.inc_by(self.val);
self.val = P::T::from_i64(0);
}
}Local Histogram
由于 Histogram 本质也是对各种计数器进行累加操作,因此 LocalHistogram 的实现也很类似,例如 observe(x) 的实现与 Histogram 如出一辙,除了它不是原子操作;flush() 也是将所有值累加到全局指标上去:
pub struct LocalHistogramCore {
histogram: Histogram,
counts: Vec<u64>,
count: u64,
sum: f64,
}
impl LocalHistogramCore {
// Some functions are omitted.
pub fn observe(&mut self, v: f64) {
// Try find the bucket.
let mut iter = self
.histogram
.core
.upper_bounds
.iter()
.enumerate()
.filter(|&(_, f)| v <= *f);
if let Some((i, _)) = iter.next() {
self.counts[i] += 1;
}
self.count += 1;
self.sum += v;
}
pub fn flush(&mut self) {
// No cached metric, return.
if self.count == 0 {
return;
}
{
let h = &self.histogram;
for (i, v) in self.counts.iter().enumerate() {
if *v > 0 {
h.core.counts[i].inc_by(*v);
}
}
h.core.count.inc_by(self.count);
h.core.sum.inc_by(self.sum);
}
self.clear();
}
}静态指标(Static Metrics)
之前解释过,对于 Metric Vector 来说,由于每一个 Label Values 取值都是独立的指标实例,因此为了线程安全实现上采用了 HashMap + RwLock。为了提升效率,可以将 with_label_values 访问获得的指标保存下来,以后直接访问。另外使用姿势正确的话,Label Values 取值是一个有限的、确定的、小的集合,甚至大多数情况下在编译期就知道取值内容(例如 HTTP Method)。综上,我们可以直接写代码将各种已知的 Label Values 提前保存下来,之后可以以静态的方式访问,这就是静态指标。
以 TiKV 为例,有 Contributor 为 TiKV 提过这个 PR:#2765 server: precreate some labal metrics。这个 PR 改进了 TiKV 中统计各种 gRPC 接口消息次数的指标,由于 gRPC 接口是固定的、已知的,因此可以提前将它们缓存起来:
struct Metrics {
kv_get: Histogram,
kv_scan: Histogram,
kv_prewrite: Histogram,
kv_commit: Histogram,
// ...
}
impl Metrics {
fn new() -> Metrics {
Metrics {
kv_get: GRPC_MSG_HISTOGRAM_VEC.with_label_values(&["kv_get"]),
kv_scan: GRPC_MSG_HISTOGRAM_VEC.with_label_values(&["kv_scan"]),
kv_prewrite: GRPC_MSG_HISTOGRAM_VEC.with_label_values(&["kv_prewrite"]),
kv_commit: GRPC_MSG_HISTOGRAM_VEC.with_label_values(&["kv_commit"]),
// ...
}
}
}使用的时候也很简单,直接访问即可:
@@ -102,10 +155,8 @@ fn make_callback<T: Debug + Send + 'static>() -> (Box<FnBox(T) + Send>, oneshot:
impl<T: RaftStoreRouter + 'static> tikvpb_grpc::Tikv for Service<T> {
fn kv_get(&self, ctx: RpcContext, mut req: GetRequest, sink: UnarySink<GetResponse>) {
- let label = "kv_get";
- let timer = GRPC_MSG_HISTOGRAM_VEC
- .with_label_values(&[label])
- .start_coarse_timer();
+ const LABEL: &str = "kv_get";
+ let timer = self.metrics.kv_get.start_coarse_timer();
let (cb, future) = make_callback();
let res = self.storage.async_get(这样一个简单的优化可以为 TiKV 提升 7% 的 Raw Get 效率,可以说是很超值了(主要原因是 Raw Get 本身开销极小,因此在指标上花费的时间就显得有一些显著了)。但这个优化方案其实还有一些问题:
- 代码繁琐,有大量重复的、或满足某些 pattern 的代码;
- 如果还有另一个 Label 维度,那么需要维护的字段数量就会急剧膨胀(因为每一种值的组合都需要分配一个字段)。
为了解决以上两个问题,rust-prometheus 提供了 Static Metric 宏。例如对于刚才的 TiKV 改进 PR #2765 来说,使用 Static Metric 宏可以简化为:
make_static_metric! {
pub struct GrpcMsgHistogram: Histogram {
"type" => {
kv_get,
kv_scan,
kv_prewrite,
kv_commit,
// ...
},
}
}
let metrics = GrpcMsgHistogram::from(GRPC_MSG_HISTOGRAM_VEC);
// Usage:
metrics.kv_get.start_coarse_timer();可以看到,使用宏之后,需要维护的繁琐的代码量大大减少了。这个宏也能正常地支持多个 Label 同时存在的情况。
限于篇幅,这里就不具体讲解这个宏是如何写的了,感兴趣的同学可以观看我司同学最近在 FOSDEM 2019 上的技术分享 视频(进度条 19:54 开始介绍 Static Metrics)和 Slide,里面详细地介绍了如何从零开始写出一个这样的宏(的简化版本)。
点击查看更多 TiKV 源码解析系列文章
目录