
导读
内存管理是数据库系统不可忽视的核心问题之一,它直接影响系统的性能、稳定性和成本效率。
良好的内存管理有助于提高资源利用率、降低硬件成本、提升系统可扩展性,从而保障流畅的用户体验;反之,如果采取「无为而治」的方式管理内存,最终将难逃操作系统 OOM Killer 的审判 —— 进程被强制终止,服务暂时中断。在高可用要求的环境下,即使是几秒钟的服务中断也可能造成经济损失。因此,数据库系统必须具备完善的内存管理机制。
作为知名分布式数据库 TiDB 的基石,TiKV 是一款成熟的分布式存储引擎,对内存管理非常重视。本文作为 TiKV 源码解读系列的续篇,将展开探讨其内存管理机制。本文将重点聚焦于 Raft Store 模块的内存管理。
本文包含以下内容:
- 概览 TiKV 各模块的内存消耗,建立全局认知;
- 深入 Raft Store,介绍写请求的处理流程;
- 讨论处理流程中的内存消耗,并介绍 Raft Store 的内存监控与管理;
- 具体的源码实现。
TiKV 内存消耗概览
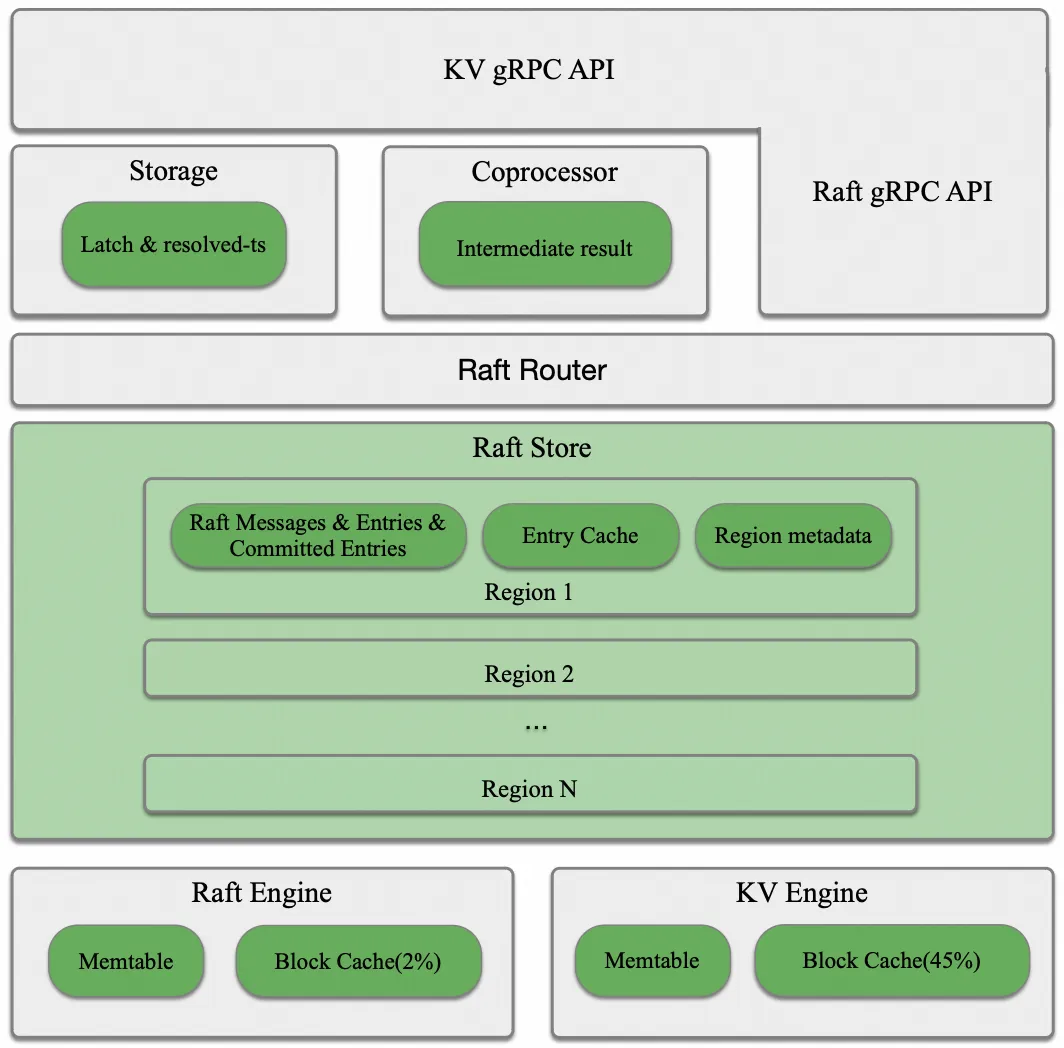
上图展示了 TiKV 的主要模块及其内存消耗来源,解释如下:
- Storage:内存用于维护写事务的 Latch 以及 resolved-ts 模块追踪写事务的 Lock。
- Coprocessor:内存用于缓存查询中间结果,与 gRPC 响应客户端速度相关,响应缓慢时内存消耗堆积。
- Raft Store:内存用于 Raft Messages & Entries & Committed Entries、Entry Cache 和 Region metadata。下文会详细介绍这三大部分。
- Raft Engine:基于 Append-only Log 结构,可视为只有 L0 的 LSM-tree,内存用于 Memtable 和 Block Cache,后者默认使用 2% 的系统内存。
- KV Engine (RocksDB):同样存在 LSM-tree 的内存消耗。Block Cache 用于缓存用户数据,默认分配 45% 的系统内存以保障读性能稳定。
在这些模块中,读请求主要在 Coprocessor 和 KV Engine 的 Block Cache 消耗内存,因为无需 Latch 和 Lock,并且可通过 Lease Read 避免走 Raft Store。相比之下,写请求才是 Raft Store 内存消耗的主要来源。因此,接下来我们将重点分析写请求在 Raft Store 的处理流程,以弄清 Raft Store 内存消耗的来源,为后面分析其内存管理机制打下基础。
写请求的处理流程
在 Raft Store 中,写请求的处理流程相对复杂,不仅涉及 Leader 和 Follower 的不同处理逻辑,还需要经过 Raft 流程的多个阶段。为了提升性能,TiKV 引入了多种优化技术,如 Async 和 Pipeline,这使得流程更加复杂。
我曾尝试用一幅序列图来展示整个写入流程,但最终得到的图片内容要素过多,不便展示。因此我决定将写入流程拆分为三幅图展示。这三幅图分别对应 Leader 和 Follower 处理逻辑的三个阶段 —— PreRaft、Raft 和 Apply。每个阶段的工作简单概括如下:
- PreRaft:负责接受,预处理和传递请求/消息给 Raft 系统处理;
- Raft:负责日志的复制与持久化;
- Apply:负责将日志应用到状态机。
写请求的生命周期实际经历了六个步骤:Leader PreRaft -> Leader Raft -> Follower PreRaft -> Follower Raft -> Leader Apply -> Follower Apply。这六个步骤构成一个流水线,实现了时间并行(Temporal Parallelism)。
话不多说,接下来请看三幅图(三个阶段):
前排提醒:
序列图的参与者除明确指出的 Service、Module 和 Thread 外,均为 TiKV 代码中的 struct 实例对象(下同);
序列图刻意忽略了 Raft Batch 处理以简化流程(下同)。
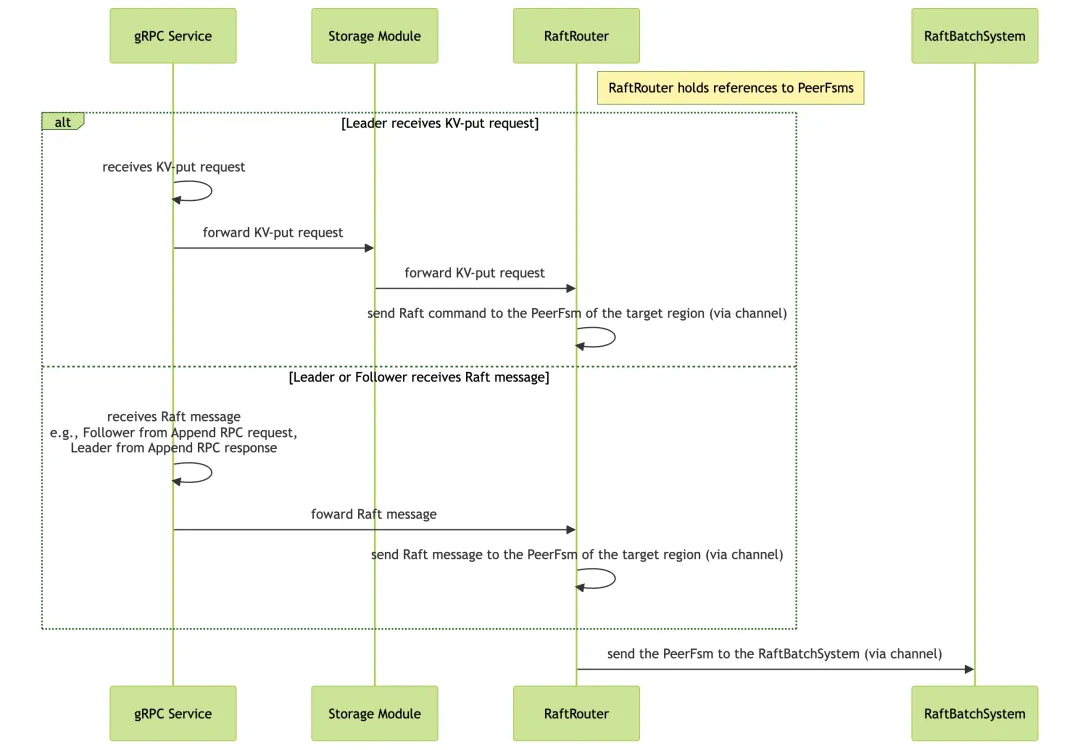
首先是 PreRaft 阶段的流程,如上图所示,具体解释如下:
- Leader:gRPC Service 收到写请求后,通过 Storage 模块和 RaftRouter 转发,生成 Raft Command,并通过 channel 将其发送给目标 Region 的 PeerFsm,最终交由 RaftBatchSystem 处理。
- Leader 或 Follower:收到 Raft Message 后,经过类似的流程后,将消息交由 RaftBatchSystem 处理。
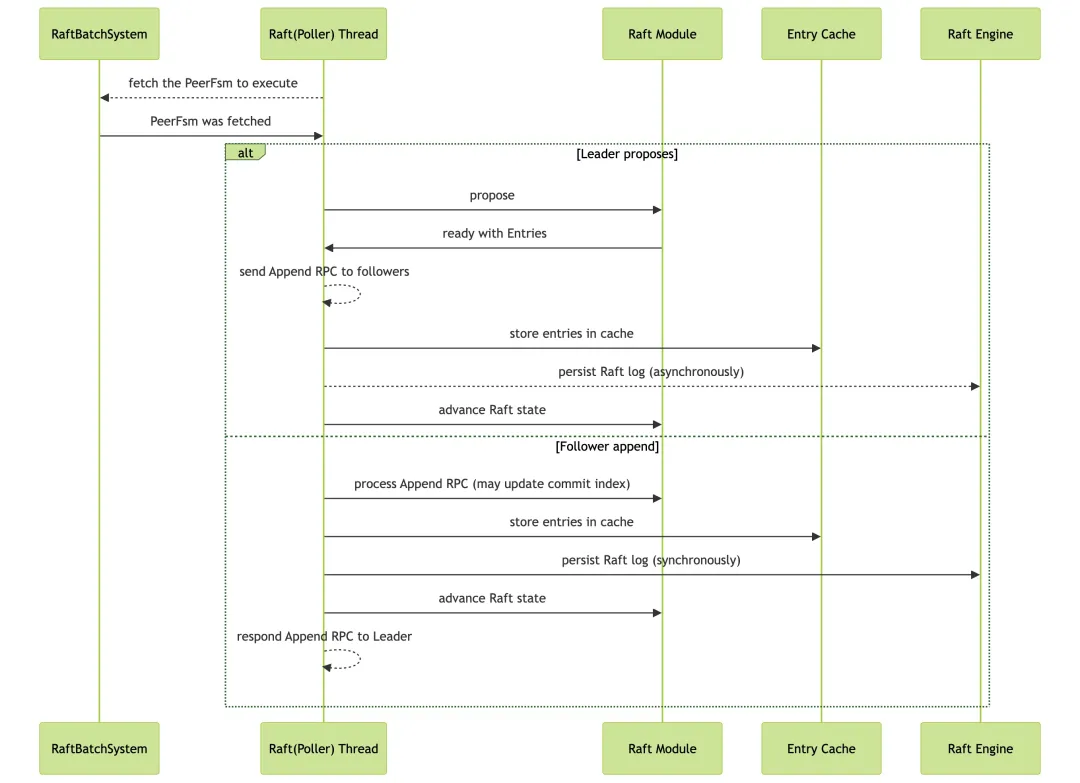
特别提醒:
虚线箭头表示异步操作,既可以是直接的异步调用,也可以是由异步事件触发的操作。
其次是 Raft 阶段的流程,如上图所示,具体解释如下:
- Leader:首先 Raft 线程从 RaftBatchSystem 拉取 PeerFsm 进行处理,向 Raft 模块发起 Propose,得到日志 Entries(未提交的 Entries,区别于下一幅图将介绍的 Committed Entries,)。随后将这些 Entries 异步地发往 Follower。接着将它们缓存到 Entry Cache(下文会详细介绍 Entry Cache),并发起异步地日志持久化操作。最后推进下 Raft 状态。
- Follower:处理流程与 Leader 类似,但处理的是 Append 而非 Propose。Follower 在处理 Append 请求时会同步更新自己的 Commit Index。此外,Follower 必须同步地持久化日志后,才能响应 Leader 的请求。
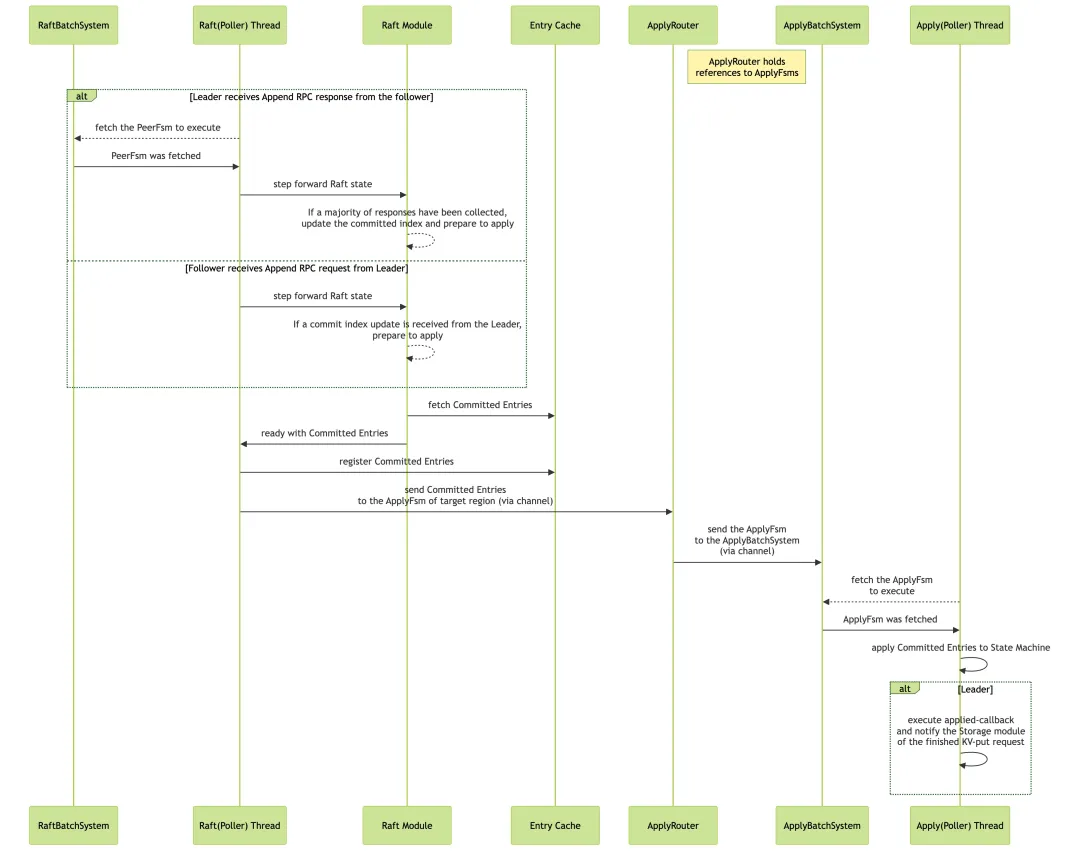
最后是 Apply 阶段的流程,如上图所示,具体解释如下:
- Leader 和 Follower:Raft 线程收到 Commit 消息后,通过 Raft 模块从 Entry Cache 中拿到 Committed Entries,注册这些 Entries 到 Entry Cache(下文会介绍这一步的用处),并将其发给到 ApplyFsm,最终 ApplyFsm 交由 ApplyBatchSystem 中的 Apply 线程应用到状态机。对于 Leader,在 Apply 完成后,会执行相应的回调函数并通知 Storage 模块写请求处理结束。
相信理解了以上三幅图三个阶段后,脑子里便能串联起写请求生命周期中的六个步骤所做的事情,对 Raft Store 中写请求的处理流程有更多的理解。那么接下来,我们将讨论流程中的内存消耗情况,并介绍 TiKV 如何进行有效的监控和管理。
内存消耗、监控与管理
内存消耗
首先,我们讨论 Raft Messages、Entries、Committed Entries 的内存消耗。确切地说,这部分内存消耗还包括 Raft Command。
在上文的写请求处理流程图中,Raft Command,Entries,Committed Entries 都已经出场。Raft Command 是写请求的包装,而 Entries 和 Commited Entries 是未提交和已提交两种形态下的 Entry。那么 Raft Messages 是什么呢?它涵盖了所有 Region Peer 之间与 Raft 协议相关的所有消息请求,支持很多的 MessageType,然而,在内存管理中我们主要关注 Append Message,因为它会携带 Entries,消耗较多内存。
总的来说,这些对象都是写请求在不同阶段的变体或载体。其形态变化过程可以用下图来表示:
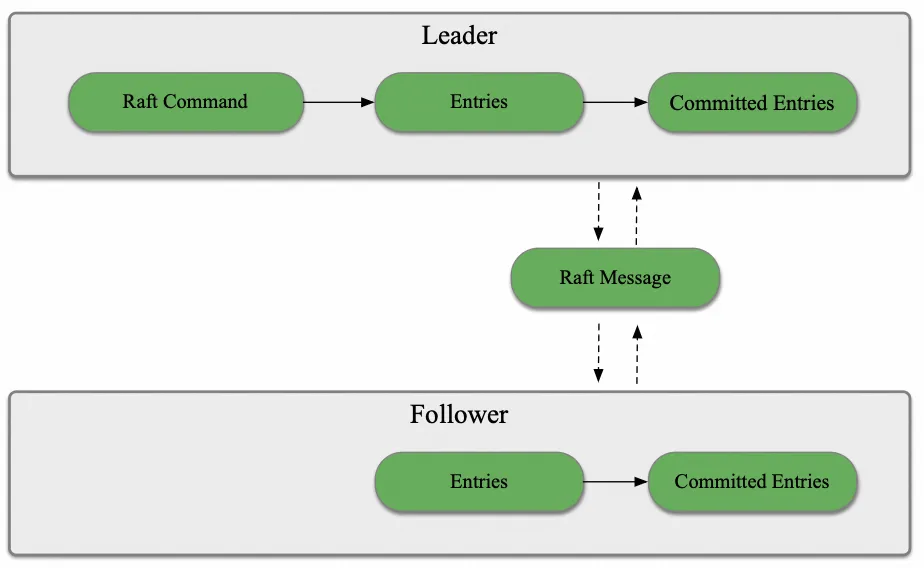
在单个 TiKV 节点上,这些对象的内存消耗空间复杂度为:
O(num_inflight_requests / request_throughput)
因为内存消耗的增长与并发请求数(num_inflight_requests)成正比,而与请求吞吐量(request_throughput)成反比(处理得越快,内存回收越快)。
假设单个 TiKV 节点能承载 10k 并发写请求,每个请求消耗 10KB 内存,总消耗为 100MB。虽然看似并不大,但这是在正常吞吐量的前提下。如果在写请求某一阶段发生拥塞,导致吞吐量下降。根据上述空间复杂度公式,内存消耗将上升。最常见的情况可能是 RocksDB 触发 Write Stall,导致 Apply 阶段拥塞,进而积压大量 Committed Entries。
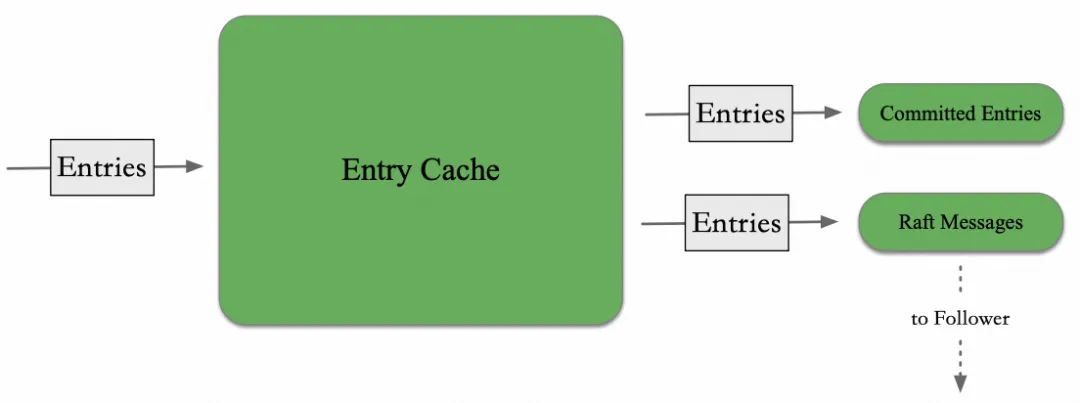
接下来,我们讨论上文写请求处理流程图中的重要参与者 —— Entry Cache。Entry Cache 的工作可以抽象为上图所示。输入是日志 Entries,缓存后输出用于两个方面:一是为 Apply 阶段提供数据,二是用于 Leader 向慢 Follower 同步日志。
为什么有了 raft-rs 的 Unstable 这一 log buffer,还需要 Entry Cache?因为 Unstable 在日志持久化后会清理掉缓存的日志 entries,而有时仍需要读取这些 Entries,就不得不穿透到 Raft Engine 进行读取。
为什么有了 Raft Engine Block Cache,还需要 Entry Cache?因为 Raft Engine 不是一个 per-region 的存储。在 Raft Engine 中,所有 Region 的日志会都写入同一个文件。因此,同一 Region 的日志可能位于不同的文件 Block 中,批量读取同一个 Region 的日志需要读取多个 Block,空间局部性不好,很可能穿透 Block Cache 引入额外的磁盘 IO。此外,Block Cache 中缓存的是磁盘格式的数据,读取时还需要进行解码,增加了额外的 CPU 开销。
在单个 TiKV 节点上,Entry Cache 的内存消耗空间复杂度为:
O(num_inflight_requests / min{replicate_to_all_throughput, request_throughput} )
replicate_to_all_throughput 是指日志复制(必须持久化)到所有节点的吞吐量。尽管 Follower 上缓存的 entries 在 Apply 阶段完成后可以清理,但 Leader 上缓存的 entries 需要等待所有节点复制完成才能清理(当然失联较久的 Follower 会被忽略)。
之所以使用 min,是因为内存回收速度取决于 replicate_to_all_throughput 和 request_throughput 中较慢的那个。replicate_to_all_throughput 较慢通常出现在慢 Follower 场景,而 request_throughput 较慢则可能发生在 Leader Apply 阶段出现拥塞时,即所有节点已完成日志复制,但请求仍堆积在 Apply 阶段。
最后,我们讨论一下 Region metadata 的内存消耗。通常认为,Region metadata 是指用于描述一个 Region 的数据结构(如:https://github.com/tikv/client-rust/blob/f6774b46a863f012c3a5bb9b1dc5540747082cf2/proto/metapb.proto#L113 中 Region 的定义)。但在本节中,Region metadata 的定义有所扩展,不仅包括 Region 自身的描述数据,还涵盖与 Region 相关的所有内存数据结构。例如,PeerFsm、ApplyFsm 结构体及其字段的内存消耗,尤其是一些用于消息通信的 channel 的内存消耗,PeerFsm 维护的 Raft RawNode 用到的 buffer 的内存消耗等等。这些在上文的写入流程图中大部分已经展示。
在单个 TiKV 节点上,Region metadata 的内存消耗空间复杂度为:
O(memory_cost_per_region * num_regions)
虽然 Region 数量(num_regions)可以根据节点数据量和 Region 大小推算,但由于 channel、buffer 等结构在无负载与有负载情况下的内存消耗差异较大,因此单个 Region 的 metadata 具体内存消耗(memory_cost_pre_region)并不好估算。根据经验,在无负载情况下,单个 Region 的 metadata 内存消耗大约为几十 KB。假设每个 Region 占用 20KB,一个节点存储 4TB 数据,即拥有 40k 个 Region,总内存消耗将达到约 800MB。仅这些静态内存消耗,就已经是不容忽视的开销了。
内存监控
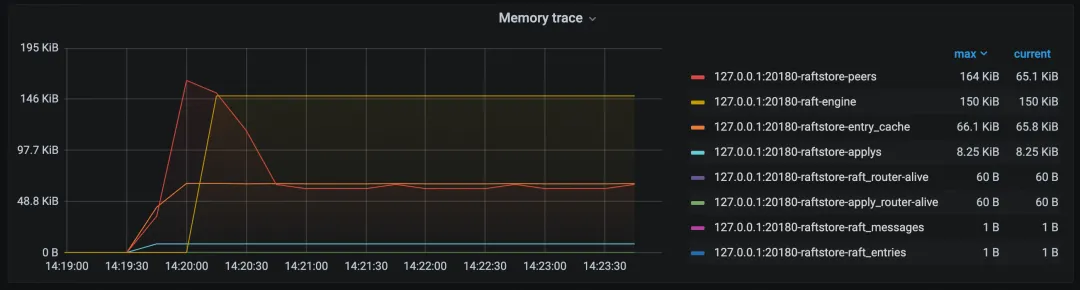
为了及时定位和解决内存异常问题,TiKV 的监控系统覆盖了消耗内存的主要对象,包括 Raft Messages、Entries、Entry Cache 以及 Region metadata 中占大头的 PeerFsm 和 ApplyFsm 等。这些监控项可以帮助运维人员迅速发现问题。在 TiDB Grafana -> TiKV-Details -> Server -> Memory Trace 中,可以直观地查看这些内存消耗数据。监控面板长这个样子:
内存管理
除了内存监控,TiKV 还实现了多层次的内存管理策略,以应对不同场景下的内存压力。主要分为三种策略:
1.内存回收(memory compaction)
- 策略:在系统内存资源充裕时,TiKV 会自动回收不再使用的内存。
- 实现:正如上文提到的,Raft Message 和 Entries 在完成其生命周期后会立即释放。而对于 Entry Cache 中缓存的 entries,Follower 节点在 Apply 阶段完成后立即释放,而 Leader 节点在 Raft tick 中定期检查并清理那些已成功复制到大多数的 entries。
- 目标:此策略通过在系统负载较轻时自动释放内存,减少无效占用,从而优化内存利用率。
2.内存淘汰
- 策略:当系统内存压力增大,接近高水位线(
memory_usage_limit * 0.9)时,如果此时 Entry Cache 的内存消耗超出阈值(evict_cache_on_memory_ratio), TiKV 会触发内存淘汰,清理一些未来仍可能会用到的内存对象。 - 实现:内存淘汰检查会在两种情况下触发:一是当 Entry Cache 发生写入时,二是 Raft tick 中定期触发。当确定需要内存淘汰时,会清理部分 Entry Cache entries 和积压在 Apply 阶段的 Committed Entries(两者由 Entry Cache 管理,这就是为什么上文的写入流程图中有一步是将 Committed Entries 注册到 Entry Cache)。当且仅当这些 entries 的日志已经持久化,才允许被清理,以确保在未来需要时能够从磁盘重新加载。
- 目标:此策略通过牺牲部分未来的内存缓存以减少当前的内存消耗,尽管这会增加未来的磁盘 I/O。
3.拒绝写入
- 策略:当系统内存压力爆表,超出高水位线时,如果此时 Entry Cache 和 Raft Message 等对象的内存消耗超出阈值(
reject_messages_on_memory_ratio),TiKV 会拒绝新的写入请求。(这种情况可能发生在因为磁盘故障导致日志无法持久化,Entre Cache 和积压的 Committed Entries 都无法淘汰时。) - 目标:此策略通过过拒绝部分写入请求,防止系统因 OOM 而终止,降低爆炸半径,为系统自动恢复争取时间。
源码实现
在经过上面几节的理论分析后,接下来我们进入源码分析环节(不得不说,这才是源码分析系列文章的核心内容 🙂
我们将主要分析一下 Raft Store 内存监控和管理的一些实现。先声明,以下所有的分析都基于 TiKV 最新的 8.3.0 版本,Raft Store v1 版本。
内存监控
内存监控代码的大致实现要点是:
- 采用一个树状的结构记录各个模块以及其子模块的内存消耗。
- 监控粒度为节点级别而不是 Region 级别。
- 在对象创建和销毁的时候分别增加和减少其内存消耗。
- 周期性地上报监控数据。
对应到具体的代码,树状结构就是 MemoryTrace。其 trace 字段是父模块的内存消耗值,children 字段持有子模块的指针列表:
pub struct MemoryTrace {
pub id: Id,
trace: AtomicUsize,
children: HashMap<Id, Arc<MemoryTrace>>,
}通过 mem_trace! 宏定义了 raftstore 模块,以及其子模块 peers(PeerFsm),raft_messages,raft_entreis 等。
pub static ref MEMTRACE_ROOT: Arc<MemoryTrace> = mem_trace!(
raftstore,
[
peers,
applys,
entry_cache,
// ...
raft_messages,
raft_entries
])因为监控是节点级别,所以所有 Region 的内存消耗用同一个全局变量记录:
/// Memory usage for raft peers fsms.
pub static ref MEMTRACE_PEERS: Arc<MemoryTrace> =
MEMTRACE_ROOT.sub_trace(Id::Name("peers"));
/// ...
/// Heap size trace for received Raft Messages.
pub static ref MEMTRACE_RAFT_MESSAGES: Arc<MemoryTrace> =
MEMTRACE_ROOT.sub_trace(Id::Name("raft_messages"));
/// ...至于对象内存消耗的增加和减少。我们以 Raft Message 为例。可以看到在 send_raft_message 创建 Raft Message 时,会增加其内存消耗(主要就是 Message 中携带的 Entries):
impl<EK, ER> RaftRouter<EK, ER>
where
EK: KvEngine,
ER: RaftEngine,
{
pub fn send_raft_message(
&self,
msg: RaftMessage,
) -> std::result::Result<(), TrySendError<RaftMessage>>
// ...
let mut heap_size = 0;
for e in msg.get_message().get_entries() {
heap_size += bytes_capacity(&e.data) + bytes_capacity(&e.context);
}
let event = TraceEvent::Add(heap_size);
// ...
MEMTRACE_RAFT_MESSAGES.trace(event);
defer!(if send_failed.get() {
MEMTRACE_RAFT_MESSAGES.trace(TraceEvent::Sub(heap_size));
});
// ...
}
}在 on_raft_message 中 Raft Message 成为 Entries 时,会减去其内存消耗,然后再增加 Entries 的内存消耗:
impl<'a, EK, ER, T: Transport> PeerFsmDelegate<'a, EK, ER, T>
where
EK: KvEngine,
ER: RaftEngine,
{
fn on_raft_message(&mut self, m: Box<InspectedRaftMessage>) -> Result<()> {
// ...
defer!({
// ...
MEMTRACE_RAFT_MESSAGES.trace(TraceEvent::Sub(heap_size));
if stepped.get() {
unsafe {
// It could be less than exact for entry overwriting.
*memtrace_raft_Entries += heap_size;
MEMTRACE_RAFT_Entries.trace(TraceEvent::Add(heap_size));
}
}
});
// ...
}其余的 Entry Cache、Committed Entries 等对象的处理逻辑类似。
至于 Region Metadata, 目前主要监控了一些消耗占大头的数据结构,具体可参考:PeerFsm::update_memory_trace 和 ApplyFsm::update_memory_trace。
最后,可以再看一下 TiKVServer::init_metrics_flusher。这里设定了监控上报的周期 DEFAULT_MEMTRACE_FLUSH_INTERVAL。
self.core.background_worker.spawn_interval_task(
DEFAULT_MEMTRACE_FLUSH_INTERVAL,
move || {
let now = Instant::now();
mem_trace_metrics.flush(now);
},
);这个周期默认是 1s。换句话说,一些生命周期短的对象(如 Raft Message 和 Entries)有可能在监控中看不到,因为通常它们「来也匆匆,去也匆匆」。
内存管理
接下来,我们将依次介绍 EntryCache 的读取、写入、内存回收,内存淘汰以及 TiKV 在内存压力爆表时拒绝写入等逻辑。
Entry Cache 的读取调用链为 PeerStorage::entries -> EntryStorage::entries -> EntryCache::fetch_entries_to。
若还想要追溯到 PeerStorage 的上一层,IDE 可能无能为力,因为更上一层位于另一个 repo —— raft-rs。raft-rs 在许多地方采用了「Don’t call me, I’ll call you」的设计。作为一个库,有时不让 TiKV 调用它,而是反过来调用 TiKV。它持有 TiKV 的存储数据结构 PeerStorage,并在合适的时机调用 PeerStorage 的方法读取 Entries。这发生在 RaftLog::slice 中:
impl<T: Storage> RaftLog<T> {
/// ...
/// Grabs a slice of entries from the raft. Unlike a rust slice pointer, these are
/// returned by value. The result is truncated to the max_size in bytes.
pub fn slice(
&self,
low: u64,
high: u64,
max_size: impl Into<Option<u64>>,
context: GetEntriesContext,
) -> Result<Vec<Entry>> {
// ...
if low < self.unstable.offset {
// ...
match self.store.entries(low, unstable_high, max_size, context)
}
// ...
}
// ...
}Entry Cache 的写入调用链为 PeerFsm::handle_normal -> PeerFsmDelegate::collect_ready -> Peer::handle_raft_ready_append -> PeerStorage::handle_raft_ready -> EntryStorage::append -> EntryCache::append。
Entry Cache 的内存回收逻辑位于 EntryStorage::compact_entry_cache。Follower 在 Apply 阶段结束后调用它,参见 Peer::post_apply;Leader 在日志复制到所有节点后调用,参见 PeerFsmDelegate::on_raft_gc_log_tick。
Entry Cache 的内存淘汰判定逻辑位于 needs_evict_entry_cache,触发于 PeerFsmDelegate::on_raft_log_gc_tick 或 Peer::handle_raft_committed_entries。在 EntryCache::compact_to 中,会同时清理已持久化的 Entry Cache entries 和 Committed Entries(注册在 EntryCache::trace 中)。清理 Committed Entries 时需谨慎处理,因为 Leader 支持异步持久化日志,未持久化的 Committed Entries 不能清理。主要代码如下:
pub fn compact_to(&mut self, mut idx: u64) -> u64 {
if idx > self.persisted + 1 {
// Only the persisted entries can be compacted
idx = self.persisted + 1;
}
// ...
while let Some(cached_entries) = self.trace.pop_front() {
// Do not evict cached entries if not all of them are persisted.
// After PR #16626, it is possible that applying entries are not
// yet fully persisted. Therefore, it should not free these
// entries until they are completely persisted.
if cached_entries.range.start >= idx || cached_entries.range.end > self.persisted + 1 {
self.trace.push_front(cached_entries);
let trace_len = self.trace.len();
let trace_cap = self.trace.capacity();
if trace_len < SHRINK_CACHE_CAPACITY && trace_cap > SHRINK_CACHE_CAPACITY {
self.trace.shrink_to(SHRINK_CACHE_CAPACITY);
}
break;
}
let (_, dangle_size) = cached_entries.take_entries();
// ...
idx = cmp::max(cached_entries.range.end, idx);
}
// ...
let cache_first_idx = self.first_index().unwrap_or(u64::MAX);
// ...
let cache_last_idx = self.cache.back().unwrap().get_index();
// Use `cache_last_idx + 1` to make sure cache can be cleared completely if
// necessary.
let compact_to = (cmp::min(cache_last_idx + 1, idx) - cache_first_idx) as usize;
for e in self.cache.drain(..compact_to) {
// ...
}
// ...
}最后,拒绝写入的逻辑可以参考 needs_reject_raft_append。
总结
本文首先概述了 TiKV 各模块的内存消耗情况,随后通过写请求的处理流程,分析了 Raft Store 中内存消耗的三大主要来源,并探讨了相关的内存监控与管理机制,最后简要浏览了一些源码。希望本文能帮助读者更好地了解 TiKV 实现内存可控和服务持续可用的原理,实现分布式系统的合理设计和高效运维。
目录