
本文作者:施闻轩,TiFlash 资深研发工程师
背景
在 Part1 中我们主要对 DeltaTree 引擎的结构和写入相关流程进行了介绍。本文对读取流程进行介绍。若读者尚未阅读过 Part1,需要先阅读 Part1 文章了解前置知识。
本文基于写作时最新的 TiFlash v6.1.0 设计及源码进行分析。随着时间推移,新版本中部分设计可能会发生变更,使得本文部分内容失效,请读者注意甄别。TiFlash v6.1.0 的代码可在 TiFlash 的 git repo 中切换到 v6.1.0 tag 进行查看。
读
如 Part1 所述,写入时,DeltaTree 引擎形成的结构如下:
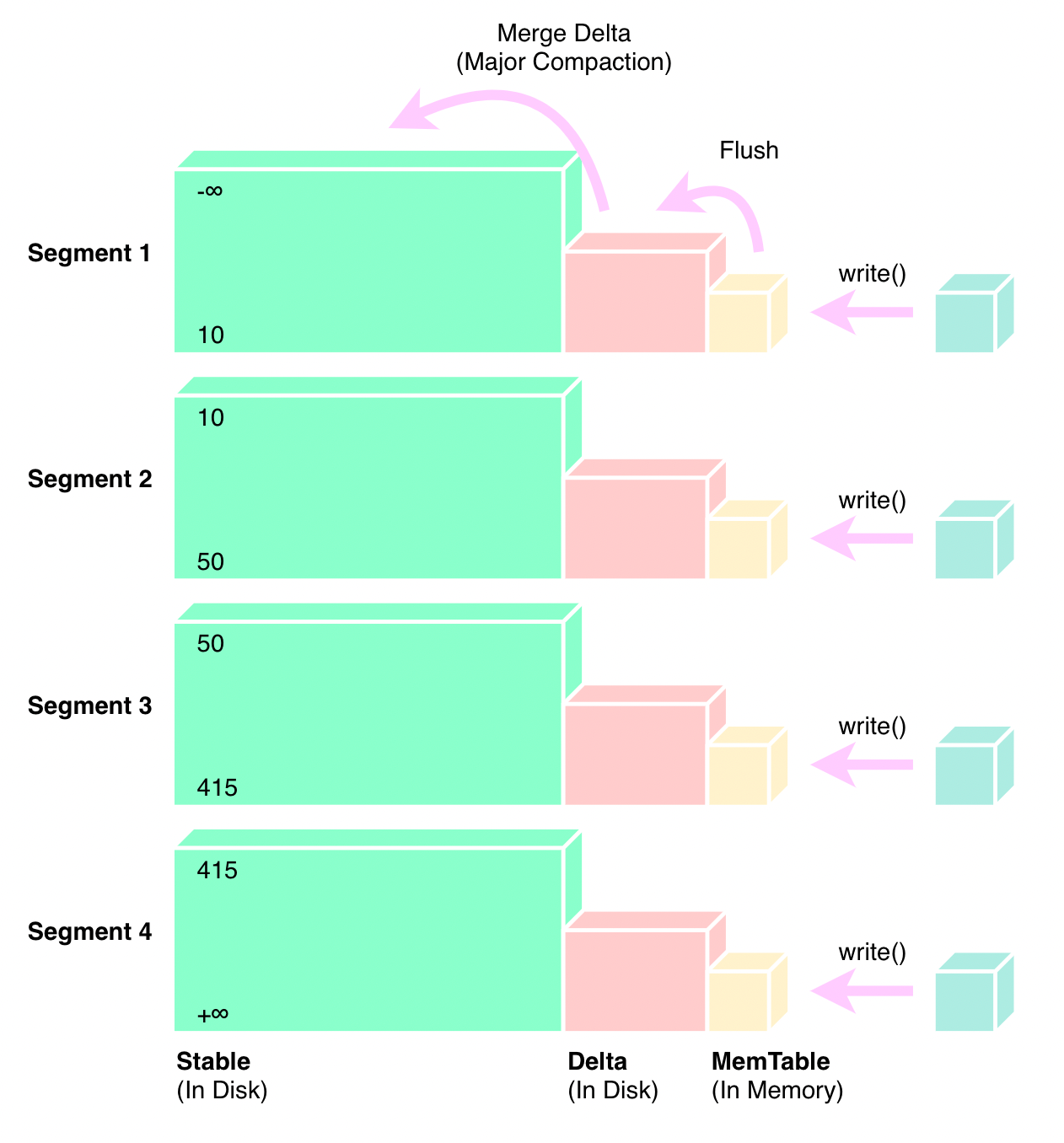
数据首先在值域范围上进行切分,分成了多个不同的 Segment,然后在时域范围上进行切分,按照新老数据分为 Stable 层(绝大多数数据)和 Delta 层(刚写入的数据)。其中,Delta 层又分为磁盘上的数据和内存中的 MemTable 数据。定期的 Flush 的机制会将内存数据写入到磁盘中。
如果想了解这个结构的详细情况,请参见 Part1。
若要从这样的结构中依次扫描数据,那么需要对每个 Segment 的 Stable、磁盘上的 Delta 层、内存中的 MemTable 数据这三部分数据进行联合扫描:
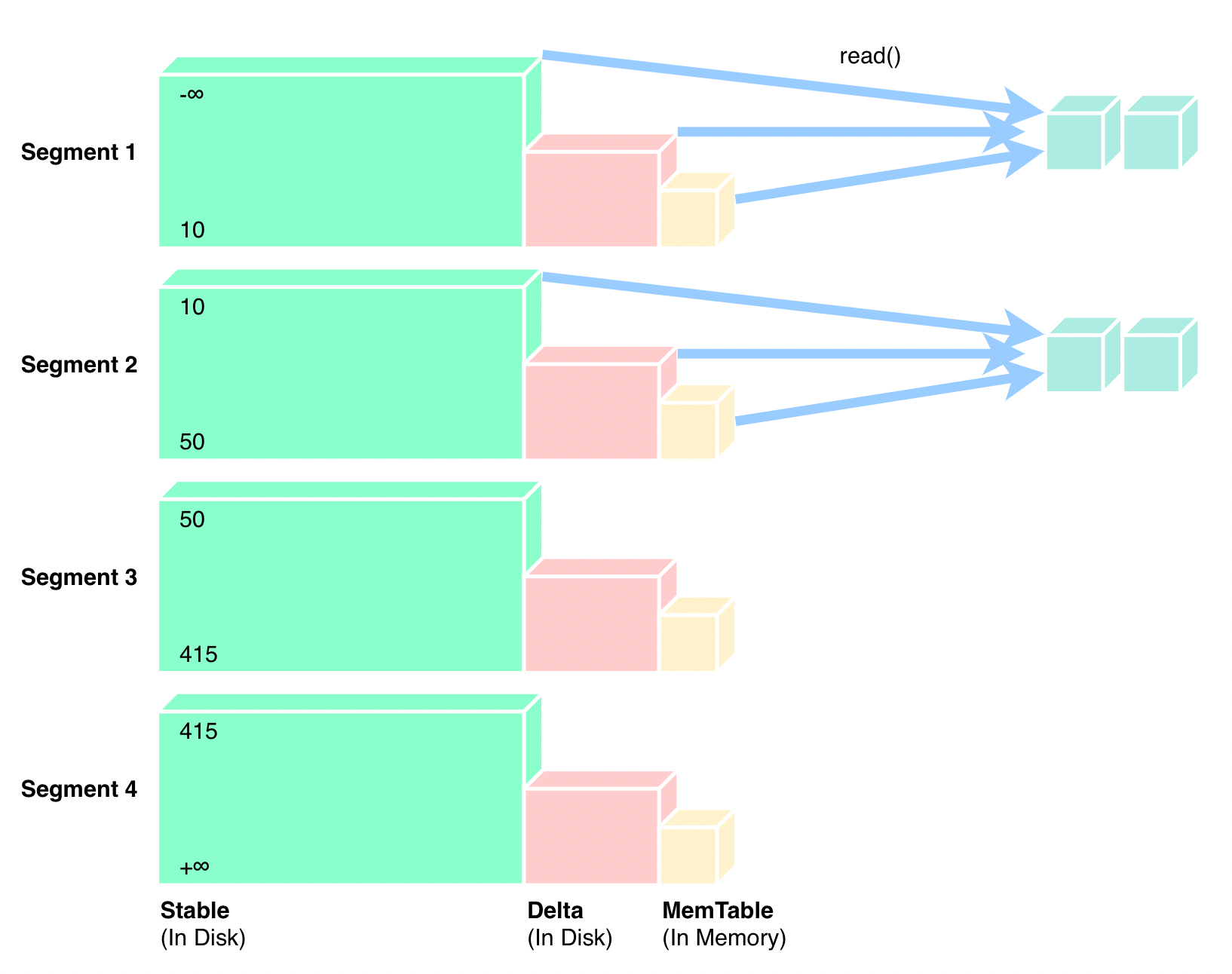
对 LSM Tree 比较熟悉的读者会发现,单个 Segment 内类似于一个 2 层 LSM Tree,由于两层的值域是重叠的,因此需要同时读取,并结合 MVCC 版本号,以便得到一个最终结果。
快照读
在实际实现中,TiFlash 并非直接对这三块数据直接进行读取,而是首先为它们构建快照,然后基于快照进行读取。快照是一种抽象概念,被「快照」下来的数据在读取的时候永远不会发生变化,即使实际数据由于发生了并行写入发生了变更。
快照读机制提供了以下好处:
- 可以提供一定的 ACID 隔离(快照隔离级别),例如不会读出写到一半的数据
- 长时间的读和写不会互相阻塞,可以同时进行,对于读大量数据的场景比较友好
从逻辑上来说,在读之前拿个锁阻塞写、并复制一遍数据,就可以以最简单的方式实现快照。但显而易见的是,复制数据是一个非常耗时的操作(例如考虑要扫 1TB 数据)。以下详细分析 TiFlash 各个部分数据是如何实现高性能快照的。
MemTableSet 的快照
对于 MemTable 中的 ColumnFileInMemory 数据,TiFlash 通过复制 Block 数据区指针的方式实现“快照”,不会复制它所包含的 Block 数据内容:
for (const auto & file : column_files)
{
if (auto * m = file->tryToInMemoryFile(); m)
{
snap->column_files.push_back(std::make_shared<ColumnFileInMemory>(*m));
}
else
{
snap->column_files.push_back(file);
}
total_rows += file->getRows();
total_deletes += file->getDeletes();
}注意,快照后的 ColumnFileInMemory 实际上与被快照的 ColumnFileInMemory 共享了相同的 Block 数据区域,而 ColumnFileInMemory 数据区是会随着新写入发生变更的。因此这个 ColumnFileInMemory “快照”并不保证后续读的时候不会遇到新数据,不是一个真正意义上的快照。在读过程中,TiFlash 还额外进行了 TSO 的过滤来规避这些后续可能新写入的数据。
磁盘上 Delta 层数据的快照
对于 ColumnFilePersistedSet,其各个 ColumnFile 的数据通过 PageStorage 存储在了磁盘中。这些数据是 immutable 的,不会随着新写入发生修改,因此直接复制 ColumnFile 结构体指针(std::shared_ptr)、对其引用计数进行更新即可。
磁盘上 Stable 层数据的快照
在 Part1 中我们可以了解到 Stable 层的数据也是 immutable 的:整个 Stable 层的数据文件不会被更改,只会在 Merge Delta 等过程中被整体替换成一个新的文件。因此与 Delta 层数据类似,Stable 层也是通过智能指针追踪引用计数、直接增加引用即可。
通过这些分析大家可以发现,TiFlash 中的快照过程是非常轻量的,基本上都仅仅涉及到指针复制和引用计数的更新,因此其效率非常高。
Scan 实现
Scan 是各个 AP 分析引擎最重要的读操作,TiFlash 也不例外。TiFlash 中 Scan() 实现的语义为:给定一个主键区间,流式地、按顺序地返回在这个区间内指定列的所有数据。
TiFlash 的 Scan 是三个流(Stream)的组合:
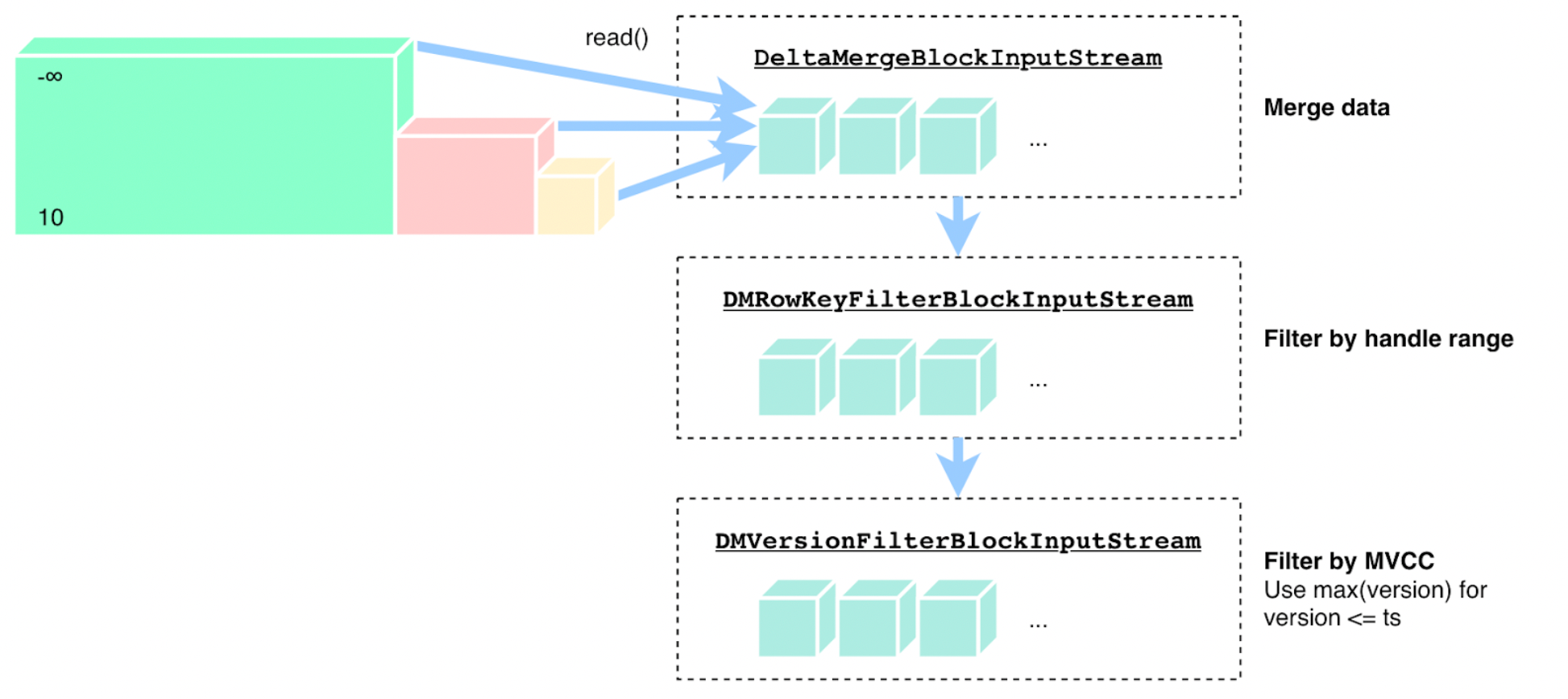
- 最底层 DeltaMergeBlockInputStream:返回合并自 MemTableSet、磁盘上的 Delta 层、磁盘上的 Stable 层这三个来源的数据流。这个流返回的数据是有序的,一定按照 (Handle, Version) 升序排列,但并不保证返回的数据一定符合给定的区间范围。
- DMRowKeyFilterBlockInputStream:依据 Handle 列的范围进行过滤并返回
- DMVersionFilterBlockInputStream:依据 Version 列的值进行 MVCC 过滤
DeltaMergeBlockInputStream
这个流有序地返回 MemTable、Delta、Stable 三层数据。在 Part1 中我们介绍过,MemTable 中可能存在多个值域重叠的 ColumnFileInMemory(每个 ColumnFile 内部是有序的),而 Delta 中也可能存在多个值域重叠的 ColumnFileTiny,Stable 层则比较简单,只有一个 DMFile,且内部是有序的。
以下边的图片为例,假设 MemTable、Delta、Stable 中各自有一些数据,我们期望 DeltaMergeBlockInputStream 返回的结果如图中最右侧红色表格所示:
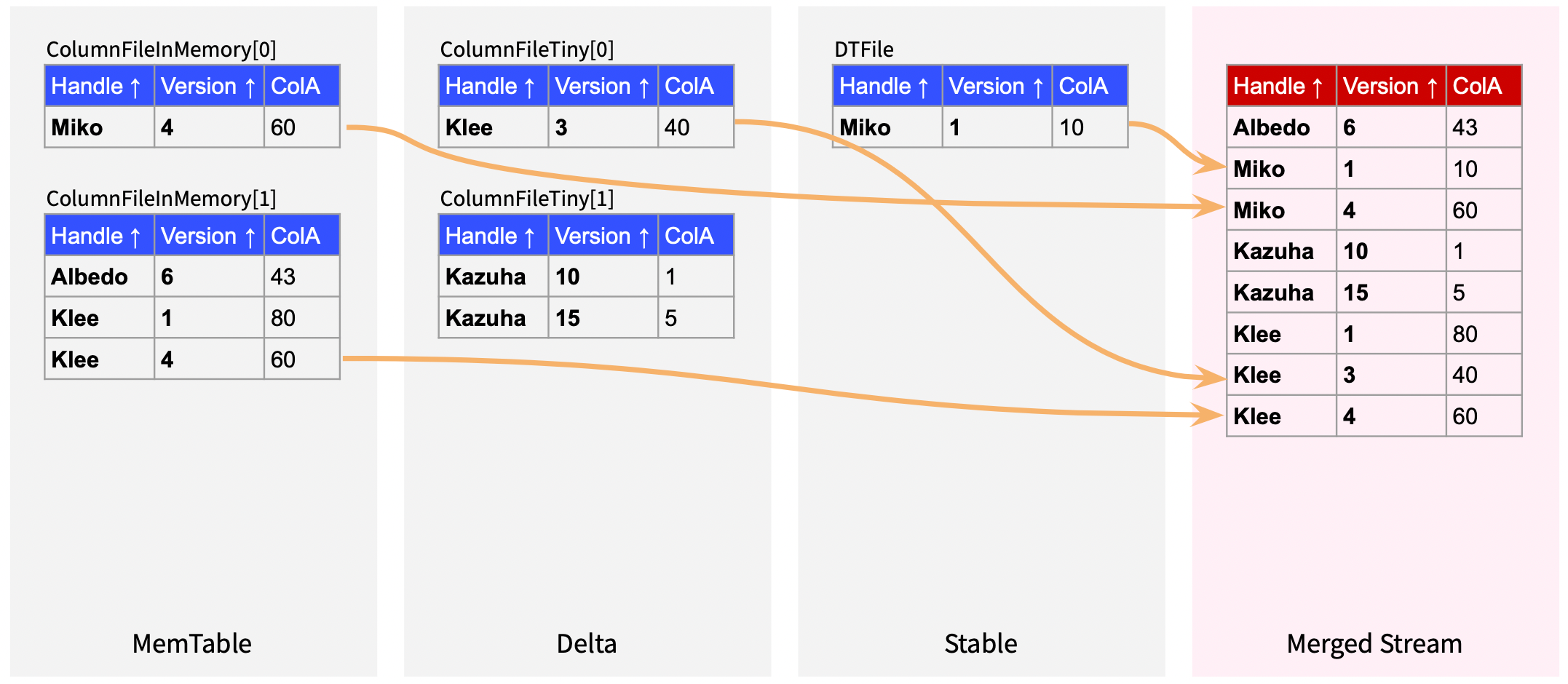
由此可见,这个流本质是,对于多个有序流返回一个有序的合并后的流。这是一个标准的 K 路归并问题(K-way Sort Merge),这也正是很多 LSM Tree 存储引擎(如 RocksDB)等对于 N 层有序数据进行 Scan 的实现方式。K 路归并的流可以通过一个最小堆实现:
- 从各个底层流中取一行,放入最小堆中
- 从最小堆中取出当前最小的这一行(这一行一定是步骤 1 中各行里最小的),作为流输出的第一行
- 从取走行的流中补充一行到最小堆中
- 重复步骤 2
K 路归并实现简单、使用广泛,但它也存在一些问题:
- 无论读哪一列,都需要依据 Sort Key 作为最小堆的排序依据,换句话说 Sort Key 列总是需要被读出来,哪怕它并不是用户所请求的数据列
- 基于堆的算法只能以行为单位处理,有较多的分支判断,无法充分利用 CPU 流水线
TiFlash 中这个流并没有采用 K 路归并的方式实现,而是采用了业界比较新的 Positional Index 方式。与 K 路归并不同的是,Positional Index 并不是基于 Sort Key 进行排序合并,而是基于各个记录的下标位置(即 Positional 名称的来源)进行差分合并。
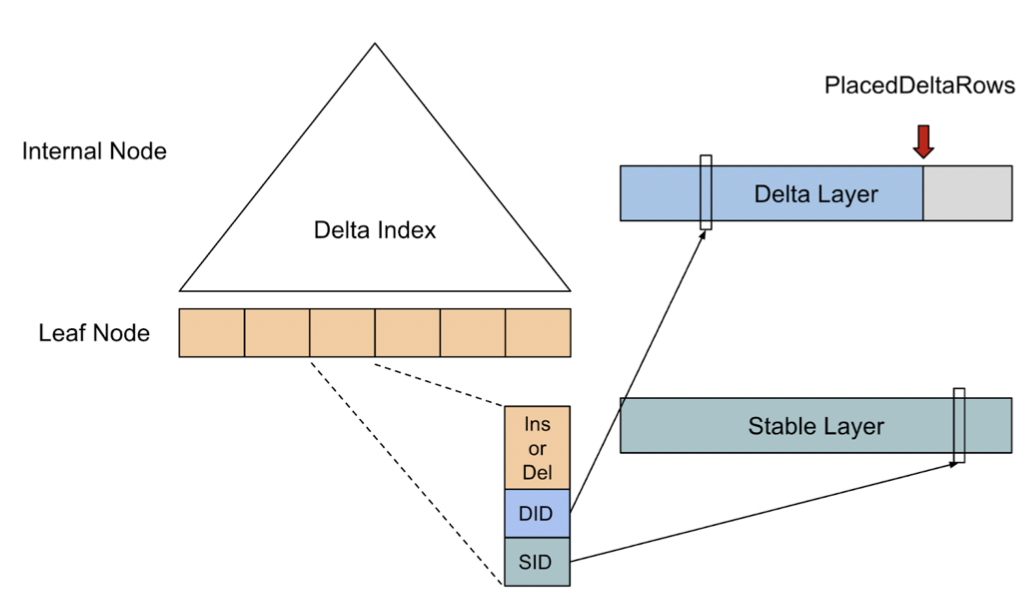
TiFlash 在写入的时候并不会更新 Positional Index,而是在读取的时候按需更新,这使得 TiFlash 得以维持高频写入性能。Positional Index 结构及算法比较复杂,后续的源码解读章节会单独涵盖,因而本文不作详细展开。感兴趣的读者也可以自行阅读 DeltaIndex.h 了解详细实现。
DMRowKeyFilterBlockInputStream
这个流会按照给定的 Handle 列范围对数据进行过滤。在 TiFlash 的实现中,虽然在从 Stable 读数据的时候也会指定读取的 Handle Range,但这个 Range 最终映射为了 Pack,返回的是以 Pack 为单位的流数据,因此还需要通过这个流对数据范围进行进一步准确地限定。
DMVersionFilterBlockInputStream
这个流的目的是实现 MVCC 过滤,下图展示了这个流的基本工作:接受一组包含 Version 及 Handle 列的数据(按 Handle, Version 排序),Handle 列可能存在多个 Version,并给定一个 MVCC 版本号,按序返回各个 Handle 不超过这个版本号最大的版本行。
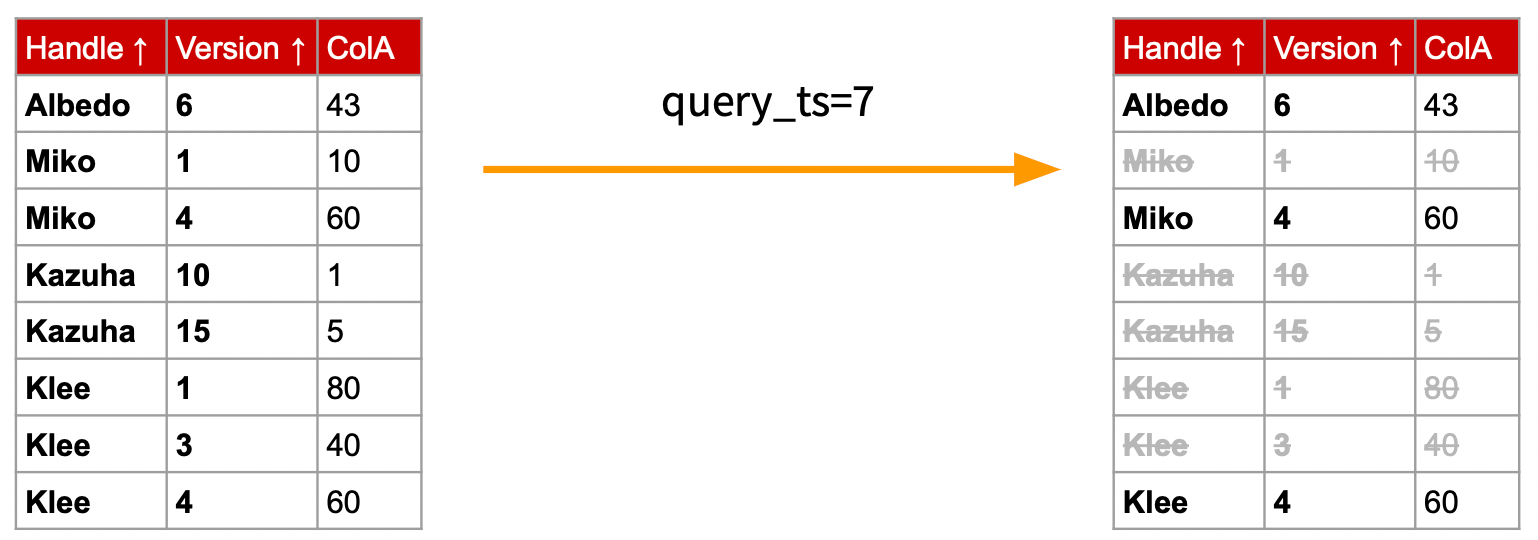
由于整体数据是按 Handle, Version 有序排列的,因此这个流的算法比较简单,这里也不做详细展开,感兴趣的读者可以阅读 DMVersionFilterBlockInputStream.h。
体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,在线申请 PoC 并获得专业技术支持。
目录