在 TiDB 里面,SQL 优化的过程可以分为逻辑优化和物理优化两个部分。逻辑优化主要是基于规则的优化,简称 RBO(rule based optimization)。物理优化会为逻辑查询计划中的算子选择某个具体的实现,需要用到一些统计信息,决定哪一种方式代价最低,所以是基于代价的优化 CBO(cost based optimization)。
本篇将主要关注逻辑优化。先介绍 TiDB 中的逻辑算子,然后介绍 TiDB 的逻辑优化规则,包括列裁剪、最大最小消除、投影消除、谓词下推等等。
逻辑算子介绍
在写具体的优化规则之前,先简单介绍查询计划里面的一些逻辑算子。
-
DataSource 这个就是数据源,也就是表,
select * from t里面的 t。 -
Selection 选择,例如
select xxx from t where xx = 5里面的 where 过滤条件。 -
Projection 投影,
select c from t里面的取 c 列是投影操作。 -
Join 连接,
select xx from t1, t2 where t1.c = t2.c就是把 t1 t2 两个表做 Join。
选择,投影,连接(简称 SPJ) 是最基本的算子。其中 Join 有内连接,左外右外连接等多种连接方式。
select b from t1, t2 where t1.c = t2.c and t1.a > 5变成逻辑查询计划之后,t1 t2 对应的 DataSource,负责将数据捞上来。上面接个 Join 算子,将两个表的结果按 t1.c = t2.c连接,再按 t1.a > 5 做一个 Selection 过滤,最后将 b 列投影。下图是未经优化的表示:
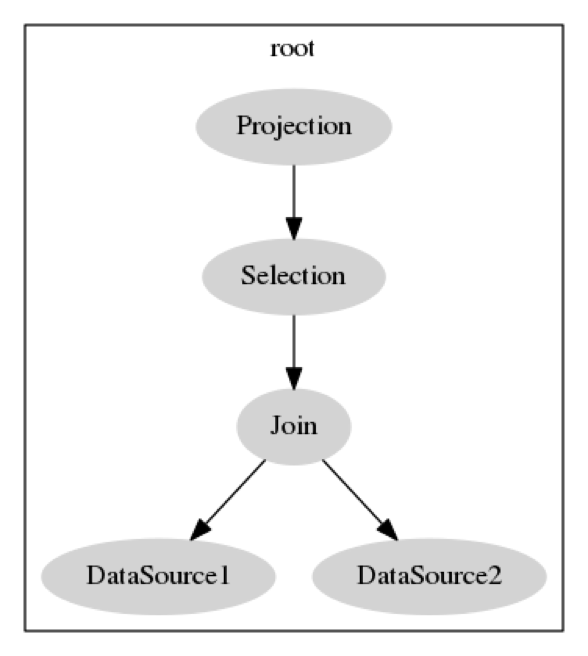
-
Sort 就是
select xx from xx order by里面的order by。 -
Aggregation,在
select sum(xx) from xx group by yy中的group by操作,按某些列分组。分组之后,可能带一些聚合函数,比如 Max/Min/Sum/Count/Average 等,这个例子里面是一个 sum。 -
Apply 这个是用来做子查询的。
列裁剪
列裁剪的思想是这样的:对于用不上的列,没有必要读取它们的数据,无谓的浪费 IO 资源。比如说表 t 里面有 a b c d 四列。
select a from t where b > 5这个查询里面明显只有 a b 两列被用到了,所以 c d 的数据是不需要读取的。在查询计划里面,Selection 算子用到 b 列,下面接一个 DataSource 用到了 a b 两列,剩下 c 和 d 都可以裁剪掉,DataSource 读数据时不需要将它们读进来。
列裁剪的算法实现是自顶向下地把算子过一遍。某个节点需要用到的列,等于它自己需要用到的列,加上它的父节点需要用到的列。可以发现,由上往下的节点,需要用到的列将越来越多。代码是在 plan/column_pruning.go 文件里面。
列裁剪主要影响的算子是 Projection,DataSource,Aggregation,因为它们跟列直接相关。Projection 里面会裁掉用不上的列,DataSource 里面也会裁剪掉不需要使用的列。
Aggregation 算子会涉及哪些列?group by 用到的列,以及聚合函数里面引用到的列。比如 select avg(a), sum(b) from t group by c d,这里面 group by 用到的 c 和 d 列,聚合函数用到的 a 和 b 列。所以这个 Aggregation 使用到的就是 a b c d 四列。
Selection 做列裁剪时,要看它父节点要哪些列,然后它自己的条件里面要用到哪些列。Sort 就看 order by 里面用到了哪些列。Join 则要把连接条件中用到的各种列都算进去。具体的代码里面,各个算子都是实现 PruneColumns 接口:
func (p *LogicalPlan) PruneColumns(parentUsedCols []*expression.Column)
通过列裁剪这一步操作之后,查询计划里面各个算子,只会记录下它实际需要用到的那些列。
最大最小消除
最大最小消除,会对 Min/Max 语句进行改写。
select min(id) from t我们用另一种写法,可以做到类似的效果:
select id from t order by id asc limit 1这个写法有什么好处呢?前一个语句,生成的执行计划,是一个 TableScan 上面接一个 Aggregation,也就是说这是一个全表扫描的操作。后一个语句,生成执行计划是 TableScan + Sort + Limit。
在某些情况,比如 id 是主键或者是存在索引,数据本身有序, Sort 就可以消除,最终变成 TableScan 或者 IndexLookUp 接一个 Limit,这样子就不需要全表扫了,只需要读到第一条数据就得到结果!全表扫操作跟只查一条数据,性能上可是天壤之别。
最大最小消除,做的事情就是由 SQL 优化器“自动”地做这个变换。
select max(id) from t生成的查询树会被转换成下面这种:
select max(id) from (select id from t where id is not null order by id desc limit 1) t这个变换复杂一些是要处理 NULL 的情况。经过这步变换之后,还会执行其它变换。所以中间生成的额外的算子,可能在其它变换里面被继续修改掉。
min 也是类似的语句替换。相应的代码是在 max_min_eliminate.go 文件里面。实现是一个纯粹的 AST 结构的修改。
投影消除
投影消除可以把不必要的 Projection 算子消除掉。那么,什么情况下,投影算子是可消除的呢?
首先,如果 Projection 算子要投影的列,跟它的子节点的输出列,是一模一样的,那么投影步骤就是一个无用操作,可以消除。比如 select a,b from t 在表 t 里面就正好就是 a b 两列,那就没必要 TableScan 上面再做一次 Projection。
然后,投影算子下面的子节点,又是另一个投影算子,那么子节点的投影操作就没有意义,可以消除。比如 Projection(A) -> Projection(A,B,C) 只需要保留 Projection(A) 就够了。
类似的,在投影消除规则里面,Aggregation 跟 Projection 操作很类似。因为从 Aggregation 节点出来的都是具体的列,所以 Aggregation(A) -> Projection(A,B,C) 中,这个 Projection 也可以消除。
代码是在 eliminate_projection.go 里面。
func eliminate(p Plan, canEliminate bool) {
对 p 的每个子节点,递归地调用 eliminate
如果 p 是 Project
如果 canEliminate 为真 消除 p
如果 p 的子节点的输出列,跟 p 的输出列相同,消除 p
}注意 canEliminate 参数,它是代表是否处于一个可被消除的“上下文”里面。比如 Projection(A) -> Projection(A, B, C) 或者 Aggregation -> Projection 递归调用到子节点 Projection 时,该 Projection 就处于一个 canEliminate 的上下文。
简单解释就是,一个 Projection 节点是否可消除:
- 一方面由它父节点告诉它,它是否是一个冗余的 Projection 操作。
- 另一方面由它自己和子节点的输入列做比较,输出相同则可消除。
谓词下推
谓词下推是非常重要的一个优化。比如
select * from t1, t2 where t1.a > 3 and t2.b > 5假设 t1 和 t2 都是 100 条数据。如果把 t1 和 t2 两个表做笛卡尔积了再过滤,我们要处理 10000 条数据,而如果能先做过滤条件,那么数据量就会大量减少。谓词下推会尽量把过滤条件,推到靠近叶子节点,从而减少数据访问,节省计算开销。这就是谓词下推的作用。
谓词下推的接口函数类似是这样子的:
func (p *baseLogicalPlan) PredicatePushDown(predicates []expression.Expression) ([]expression.Expression, LogicalPlan)PredicatePushDown 函数处理当前的查询计划 p,参数 predicates 表示要添加的过滤条件。函数返回值是无法下推的条件,以及生成的新 plan。
这个函数会把能推的条件尽量往下推,推不下去的条件,做到一个 Selection 算子里面,然后连接在节点 p 上面,形成新的 plan。比如说现在有条件 a > 3 AND b = 5 AND c < d,其中 a > 3 和 b = 5 都推下去了,那剩下就接一个 c < d 的 Selection。
我们看一下 Join 算子是如何做谓词下推的。代码是在 plan/predicate_push_down.go 文件。
首先会做一个简化,将左外连接和右外连接转化为内连接。
什么情况下外连接可以转内连接?左向外连接的结果集包括左表的所有行,而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配的行,则在结果集右边补 NULL。做谓词下推时,如果我们知道接下来的的谓词条件一定会把包含 NULL 的行全部都过滤掉,那么做外连接就没意义了,可以直接改写成内连接。
什么情况会过滤掉 NULL 呢?比如,某个谓词的表达式用 NULL 计算后会得到 false 或者 NULL;或者多个谓词用 AND 条件连接,其中一个会过滤 NULL;又或者用 OR 条件连接,其中每个都是过滤 NULL 的。术语里面 OR 条件连接叫做析取范式 DNF (disjunctive normal form)。对应的还有合取范式 CNF (conjunctive normal form)。TiDB 的代码里面用到这种缩写。
能转成 inner join 的例子:
select * from t1 left outer join t2 on t1.id = t2.id where t2.id is not null;
select * from t1 left outer join t2 on t1.id = t2.id where t2.value > 3;
select * from t1 left outer join t2 on t1.id = t2.id where t2.id is null and t2.value > 3;不能转成 inner join 的例子:
select * from t1 left outer join t2 on t1.id = t2.id where t2.id is null or t2.value > 3;接下来,把所有条件全收集起来,然后区分哪些是 Join 的等值条件,哪些是 Join 需要用到的条件,哪些全部来自于左子节点,哪些全部来自于右子节点。
区分之后,对于内连接,可以把左条件,和右条件,分别向左右子节点下推。等值条件和其它条件保留在当前的 Join 算子中,剩下的返回。
谓词下推不能推过 MaxOneRow 和 Limit 节点。因为先 Limit N 行,然后再做 Selection 操作,跟先做 Selection 操作,再 Limit N 行得到的结果是不一样的。比如数据是 1 到 100,先 Limit 10 再 Select 大于 5,得到的是 5 到 10,而先做 Selection 再做 Limit 得到的是 5 到 15。MaxOneRow 也是同理,跟 Limit 1 效果一样。
DataSource 算子很简单,会直接把过滤条件加入到 CopTask 里面。最后会通过 coprocessor 推给 TiKV 去做。
构建节点属性
在 build_key_info.go 文件里面,会构建 unique key 和 MaxOneRow 属性。这一步不是在做优化,但它是在构建优化过程需要用到的一些信息。
build_key_info 是在收集关于唯一索引的信息。我们知道某些列是主键或者唯一索引列,这种情况该列不会存在多个相同的值。只有叶子节点记录这个信息。build_key_info 就是要将这个信息,从叶子节点,传递到 LogicalPlan 树上的所有节点,让每个节点都知道这些属性。
对于 DataSource,对于主键列,和唯一索引列,都是 unique key。注意处理 NULL,需要列是带有 NotNull 标记的。
对于 Projection,它的子节点中的唯一索引列信息,跟它的投影表达式的列取交集。比如 a b c 列都是唯一索引,投影其中的 b 列,输出的 b 列仍然具有值唯一的属性。
如果一个节点输出肯定只有一行,这个节点会设置一个 MaxOneRow 属性。哪些情况节点输出只有一行呢?
-
如果一个算子的子节点是 MaxOneRow 算子。
-
如果是 Limit 1,可以设置 MaxOneRow。
-
如果是 Selection,并且过滤条件是一个唯一索引列等于某常量。
-
Join 算子,如果它的左右子节点都是 MaxOneRow 属性。
总结
这是基于规则优化(RBO)的上篇。介绍了逻辑查询计划里面基本的算子,以及一部分的优化规则。后续我们还将介绍更多的优化规则,以及基于代价的优化(CBO)。
点击查看更多 TiDB 源码阅读系列文章
目录