
聚合算法执行原理
在 SQL 中,聚合操作对一组值执行计算,并返回单个值。TiDB 实现了 2 种聚合算法:Hash Aggregation 和 Stream Aggregation。
我们首先以 AVG 函数为例(案例参考 Stack Overflow),简述这两种算法的执行原理。
假设表 t 如下:
| 列 a | 列 b |
|---|---|
| 1 | 9 |
| 1 | -8 |
| 2 | -7 |
| 2 | 6 |
| 1 | 5 |
| 2 | 4 |
SQL: select avg(b) from t group by a, 要求将表 t 的数据按照 a 的值分组,对每一组的 b 值计算平均值。不管 Hash 还是 Stream 聚合,在 AVG 函数的计算过程中,我们都需要维护 2 个中间结果变量 sum 和 count。Hash 和 Stream 聚合算法的执行原理如下。
Hash Aggregate 的执行原理
在 Hash Aggregate 的计算过程中,我们需要维护一个 Hash 表,Hash 表的键为聚合计算的 Group-By 列,值为聚合函数的中间结果 sum 和 count。在本例中,键为 列 a 的值,值为 sum(b) 和 count(b)。
计算过程中,只需要根据每行输入数据计算出键,在 Hash 表中找到对应值进行更新即可。对本例的执行过程模拟如下。
输入数据 a b |
Hash 表 [key] (sum, count) |
|---|---|
| 1 9 | [1] (9, 1) |
| 1 -8 | [1] (1, 2) |
| 2 -7 | [1] (1, 2) [2] (-7, 1) |
| 2 6 | [1] (1, 2) [2] (-1, 2) |
| 1 5 | [1] (6, 3) [2] (-1, 2) |
| 2 4 | [1] (6, 3) [2] (3, 3) |
输入数据输入完后,扫描 Hash 表并计算,便可以得到最终结果:
| Hash 表 | avg(b) |
|---|---|
[1] (6, 3) |
2 |
[2] (3, 3) |
1 |
Stream Aggregation 的执行原理
Stream Aggregate 的计算需要保证输入数据按照 Group-By 列有序。在计算过程中,每当读到一个新的 Group 的值或所有数据输入完成时,便对前一个 Group 的聚合最终结果进行计算。
对于本例,我们首先对输入数据按照 a 列进行排序。排序后,本例执行过程模拟如下。
| 输入数据 | 是否为新 Group 或所有数据输入完成 | (sum, count) |
avg(b) |
|---|---|---|---|
| 1 9 | 是 | (9, 1) | 前一个 Group 为空,不进行计算 |
| 1 -8 | 否 | (1, 2) | |
| 1 5 | 否 | (6, 3) | |
| 2 -7 | 是 | (-7, 1) | 2 |
| 2 6 | 否 | (-1, 2) | |
| 2 4 | 否 | (3, 3) | |
| 是 | 1 |
因为 Stream Aggregate 的输入数据需要保证同一个 Group 的数据连续输入,所以 Stream Aggregate 处理完一个 Group 的数据后可以立刻向上返回结果,不用像 Hash Aggregate 一样需要处理完所有数据后才能正确的对外返回结果。当上层算子只需要计算部分结果时,比如 Limit,当获取到需要的行数后,可以提前中断 Stream Aggregate 后续的无用计算。
当 Group-By 列上存在索引时,由索引读入数据可以保证输入数据按照 Group-By 列有序,此时同一个 Group 的数据连续输入 Stream Aggregate 算子,可以避免额外的排序操作。
TiDB 聚合函数的计算模式
由于分布式计算的需要,TiDB 对于聚合函数的计算阶段进行划分,相应定义了 5 种计算模式:CompleteMode,FinalMode,Partial1Mode,Partial2Mode,DedupMode。不同的计算模式下,所处理的输入值和输出值会有所差异,如下表所示:
| AggFunctionMode | 输入值 | 输出值 |
|---|---|---|
| CompleteMode | 原始数据 | 最终结果 |
| FinalMode | 中间结果 | 最终结果 |
| Partial1Mode | 原始数据 | 中间结果 |
| Partial2Mode | 中间结果 | 进一步聚合的中间结果 |
| DedupMode | 原始数据 | 去重后的原始数据 |
以上文提到的 select avg(b) from t group by a 为例,通过对计算阶段进行划分,可以有多种不同的计算模式的组合,如:
-
CompleteMode
此时
AVG函数的整个计算过程只有一个阶段,如图所示: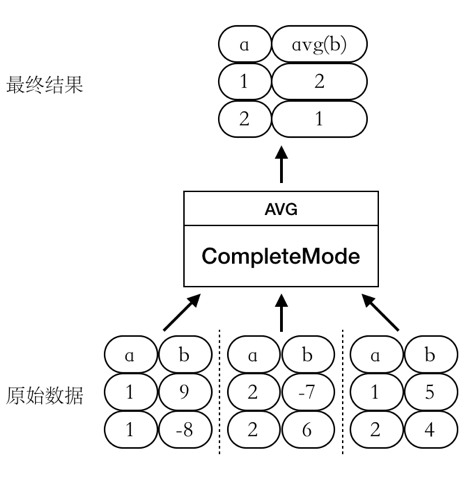
-
Partial1Mode --> FinalMode
此时我们将
AVG函数的计算过程拆成两个阶段进行,如图所示: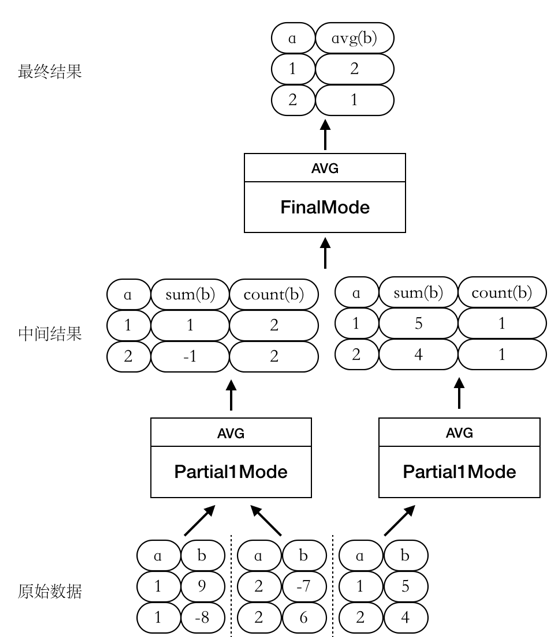
除了上面的两个例子外,还可能有如下的几种计算方式:
- 聚合被下推到 TiKV 上进行计算(Partial1Mode),并返回经过预聚合的中间结果。为了充分利用 TiDB server 所在机器的 CPU 和内存资源,加快 TiDB 层的聚合计算,TiDB 层的聚合函数计算可以这样进行:Partial2Mode --> FinalMode。
-
当聚合函数需要对参数进行去重,也就是包含
DISTINCT属性,且聚合算子因为一些原因不能下推到 TiKV 时,TiDB 层的聚合函数计算可以这样进行:DedupMode --> Partial1Mode --> FinalMode。
聚合函数分为几个阶段执行, 每个阶段对应的模式是什么,是否要下推到 TiKV,使用 Hash 还是 Stream 聚合算子等都由优化器根据数据分布、估算的计算代价等来决定。
TiDB 并行 Hash Aggregation 的实现
如何构建 Hash Aggregation 执行器
-
构建逻辑执行计划 时,会调用 NewAggFuncDesc 将聚合函数的元信息封装为一个 AggFuncDesc。 其中
AggFuncDesc.RetTp由 AggFuncDesc.typeInfer 根据聚合函数类型及参数类型推导而来;AggFuncDesc.Mode统一初始化为 CompleteMode。 -
构建物理执行计划时,
PhysicalHashAgg和PhysicalStreamAgg的attach2Task方法会根据当前task的类型尝试进行下推聚合计算,如果task类型满足下推的基本要求,比如copTask,接着会调用 newPartialAggregate 尝试将聚合算子拆成 TiKV 上执行的 Partial 算子和 TiDB 上执行的Final算子,其中 AggFuncToPBExpr 函数用来判断某个聚合函数是否可以下推。若聚合函数可以下推,则会在 TiKV 中进行预聚合并返回中间结果,因此需要将 TiDB 层执行的Final聚合算子的AggFuncDesc.Mode修改为 FinalMode,并将其AggFuncDesc.Args修改为 TiKV 预聚合后返回的中间结果,TiKV 层的 Partial 聚合算子的AggFuncDesc也需要作出对应的修改,这里不再详述。若聚合函数不可以下推,则AggFuncDesc.Mode保持不变。 -
构建 HashAgg 执行器时,首先检查当前
HashAgg算子是否可以并行执行。目前当且仅当两种情况下HashAgg不可以并行执行:- 存在某个聚合函数参数为 DISTINCT 时。TiDB 暂未实现对 DedupMode 的支持,因此对于含有
DISTINCT的情况目前仅能单线程执行。 - 系统变量
tidb_hashagg_partial_concurrency和tidb_hashagg_final_concurrency被同时设置为 1 时。这两个系统变量分别用来控制 Hash Aggregation 并行计算时候,TiDB 层聚合计算 partial 和 final 阶段 worker 的并发数。当它们都被设置为 1 时,选择单线程执行。
- 存在某个聚合函数参数为 DISTINCT 时。TiDB 暂未实现对 DedupMode 的支持,因此对于含有
若 HashAgg 算子可以并行执行,使用 AggFuncDesc.Split 根据 AggFuncDesc.Mode 将 TiDB 层的聚合算子的计算拆分为 partial 和 final 两个阶段,并分别生成对应的 AggFuncDesc,设为 partialAggDesc 和 finalAggDesc。若 AggFuncDesc.Mode == CompleteMode,则将 TiDB 层的计算阶段拆分为 Partial1Mode --> FinalMode;若 AggFuncDesc.Mode == FinalMode,则将 TiDB 层的计算阶段拆分为 Partial2Mode --> FinalMode。进一步的,我们可以根据 partialAggDesc 和 finalAggDesc 分别 构造出对应的执行函数。
并行 Hash Aggregation 执行过程详述
TiDB 的并行 Hash Aggregation 算子执行过程中的主要线程有:Main Thead,Data Fetcher,Partial Worker,和 Final Worker:
- Main Thread 一个:
- 启动 Input Reader,Partial Workers 及 Final Workers
- 等待 Final Worker 的执行结果并返回
- Data Fetcher 一个:
- 按 batch 读取子节点数据并分发给 Partial Worker
- Partial Worker 多个:
- 读取 Data Fetcher 发送来的数据,并做预聚合
- 将预聚合结果根据 Group 值 shuffle 给对应的 Final Worker
- Final Worker 多个:
- 读取 PartialWorker 发送来的数据,计算最终结果,发送给 Main Thread
Hash Aggregation 的执行阶段可分为如下图所示的 5 步:
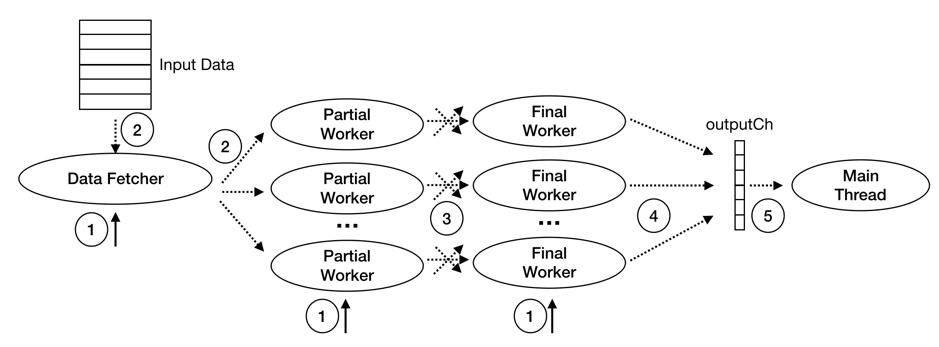
-
启动 Data Fetcher,Partial Workers 及 Final Workers。
这部分工作由 prepare4Parallel 函数完成。该函数会启动一个 Data Fetcher,多个 Partial Worker 以及 多个 Final Worker。Partial Worker 和 Final Worker 的数量可以分别通过
tidb_hashgg_partial_concurrency和tidb_hashagg_final_concurrency系统变量进行控制,这两个系统变量的默认值都为 4。 -
DataFetcher 读取子节点的数据并分发给 Partial Workers。
这部分工作由 fetchChildData 函数完成。
-
Partial Workers 预聚合计算,及根据 Group Key shuffle 给对应的 Final Workers。
这部分工作由 HashAggPartialWorker.run 函数完成。该函数调用 updatePartialResult 函数对 DataFetcher 发来数据执行 预聚合计算,并将预聚合结果存储到 partialResultMap 中。其中
partialResultMap的 key 为根据Group-By的值 encode 的结果,value 为 PartialResult 类型的数组,数组中的每个元素表示该下标处的聚合函数在对应 Group 中的预聚合结果。shuffleIntermData 函数完成根据 Group 值 shuffle 给对应的 Final Worker。 -
Final Worker 计算最终结果,发送给 Main Thread。
这部分工作由 HashAggFinalWorker.run 函数完成。该函数调用 consumeIntermData 函数 接收 PartialWorkers 发送来的预聚合结果,进而 合并 得到最终结果。getFinalResult 函数完成发送最终结果给 Main Thread。
- Main Thread 接收最终结果并返回。
TiDB 并行 Hash Aggregation 的性能提升
此处以 TPC-H query-17 为例,测试并行 Hash Aggregation 相较于单线程计算时的性能提升。引入并行 Hash Aggregation 前,它的计算瓶颈在 HashAgg_35。
该查询执行计划如下:
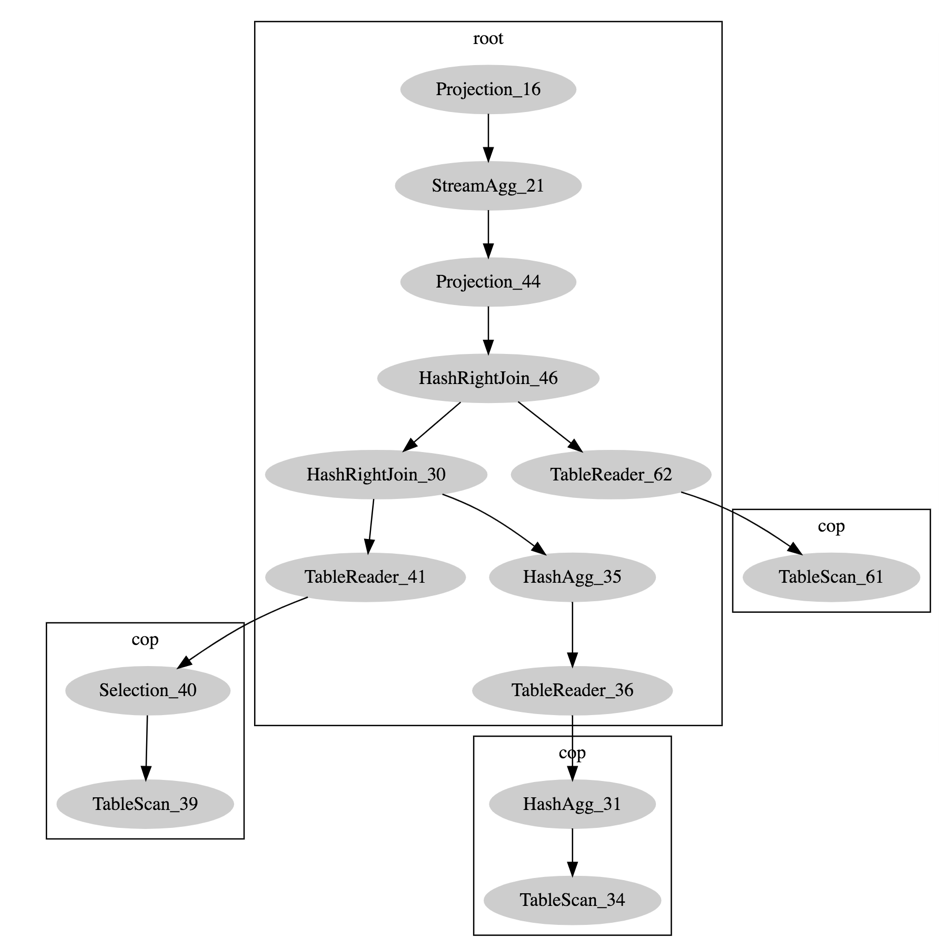
在 TiDB 中,使用 EXPLAIN ANALYZE 可以获取 SQL 的执行统计信息。因篇幅原因此处仅贴出 TPC-H query-17 部分算子的 EXPLAIN ANALYZE 结果。
HashAgg 单线程计算时:

查询总执行时间 23 分 24 秒,其中 HashAgg 执行时间约 17 分 9 秒。
HashAgg 并行计算时(此时 TiDB 层 Partial 和 Final 阶段的 worker 数量都设置为 16):

总查询时间 8 分 37 秒,其中 HashAgg 执行时间约 1 分 4 秒。
并行计算时,Hash Aggregation 的计算速度提升约 16 倍。
点击查看更多 TiDB 源码阅读系列文章
目录