
DDL 是数据库非常核心的组件,其正确性和稳定性是整个 SQL 引擎的基石,在分布式数据库中,如何在保证数据一致性的前提下实现无锁的 DDL 操作是一件有挑战的事情。本文首先会介绍 TiDB DDL 组件的总体设计,介绍如何在分布式场景下支持无锁 schema 变更,描述这套算法的大致流程,然后详细介绍一些常见的 DDL 语句的源码实现,包括 create table、add index、drop column、drop table 这四种。
DDL in TiDB
TiDB 的 DDL 通过实现 Google F1 的在线异步 schema 变更算法,来完成在分布式场景下的无锁,在线 schema 变更。为了简化设计,TiDB 在同一时刻,只允许一个节点执行 DDL 操作。用户可以把多个 DDL 请求发给任何 TiDB 节点,但是所有的 DDL 请求在 TiDB 内部是由 owner 节点的 worker 串行执行的。
- worker:每个节点都有一个 worker 用来处理 DDL 操作。
- owner:整个集群中只有一个节点能当选 owner,每个节点都可能当选这个角色。当选 owner 后的节点 worker 才有处理 DDL 操作的权利。owner 节点的产生是用 Etcd 的选举功能从多个 TiDB 节点选举出 owner 节点。owner 是有任期的,owner 会主动维护自己的任期,即续约。当 owner 节点宕机后,其他节点可以通过 Etcd 感知到并且选举出新的 owner。
这里只是简单概述了 TiDB 的 DDL 设计,下两篇文章详细介绍了 TiDB DDL 的设计实现以及优化,推荐阅读:
下图描述了一个 DDL 请求在 TiDB 中的简单处理流程:
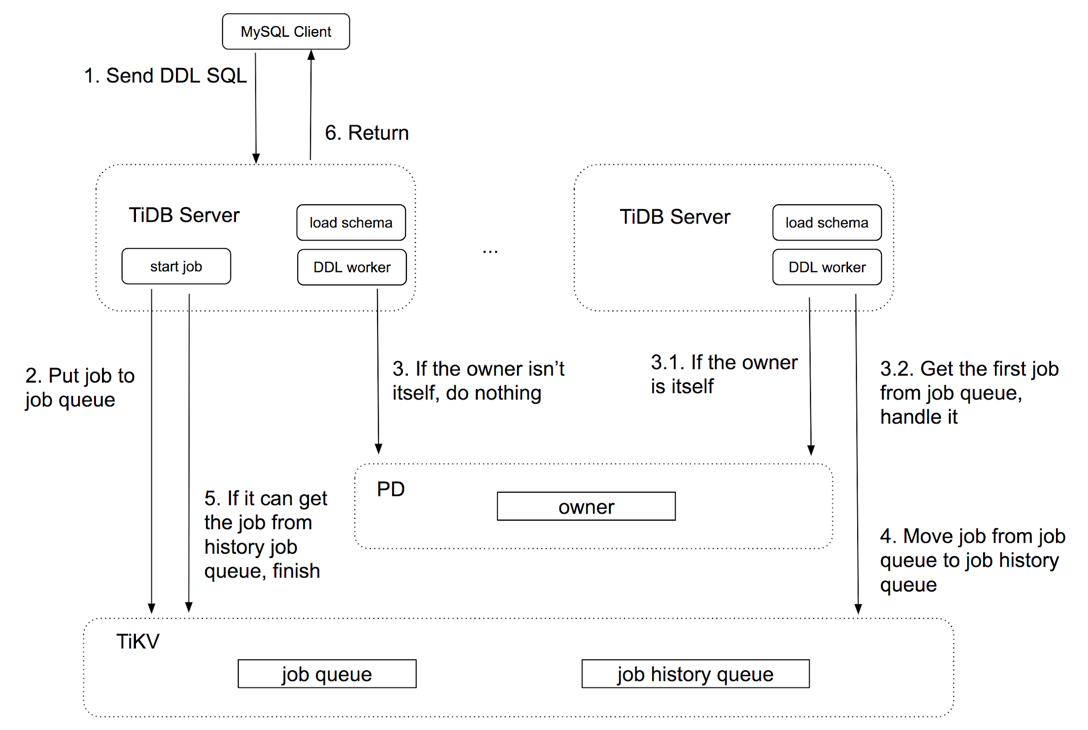
TiDB 的 DDL 组件相关代码存放在源码目录的 ddl 目录下。
| File | Introduction |
|---|---|
ddl.go |
包含 DDL 接口定义和其实现。 |
ddl_api.go |
提供 create , drop , alter , truncate , rename 等操作的 API,供 Executor 调用。主要功能是封装 DDL 操作的 job 然后存入 DDL job queue,等待 job 执行完成后返回。 |
ddl_worker.go |
DDL worker 的实现。owner 节点的 worker 从 job queue 中取 job,然后执行,执行完成后将 job 存入 job history queue 中。 |
syncer.go |
负责同步 ddl worker 的 owner 和 follower 间的 schema version。 每次 DDL 状态变更后 schema version ID 都会加 1。 |
ddl owner 相关的代码单独放在 owner 目录下,实现了 owner 选举等功能。
另外,ddl job queue 和 history ddl job queue 这两个队列都是持久化到 TiKV 中的。structure 目录下有 list,hash 等数据结构在 TiKV 上的实现。
本文接下来按照 TiDB 源码的 origin/source-code 分支讲解,最新的 master 分支和 source-code 分支代码会稍有一些差异。
Create table
create table 需要把 table 的元信息(TableInfo)从 SQL 中解析出来,做一些检查,然后把 table 的元信息持久化保存到 TiKV 中。具体流程如下:
- 语法解析:ParseSQL 解析成抽象语法树 CreateTableStmt。
- 编译生成 Plan:Compile 生成 DDL plan , 并 check 权限等。
- 生成执行器:buildExecutor 生成 DDLExec 执行器。TiDB 的执行器是火山模型。
-
执行器调用 e.Next 开始执行,即 DDLExec.Next 方法,判断 DDL 类型后执行 executeCreateTable , 其实质是调用
ddl_api.go的 CreateTable 函数。 -
CreateTable 方法是主要流程如下:
- 会先 check 一些限制,比如 table name 是否已经存在,table 名是否太长,是否有重复定义的列等等限制。
- buildTableInfo 获取 global table ID,生成
tableInfo, 即 table 的元信息,然后封装成一个 DDL job,这个 job 包含了table ID和tableInfo,并将这个 job 的 type 标记为ActionCreateTable。 - d.doDDLJob(ctx, job) 函数中的 d.addDDLJob(ctx, job) 会先给 job 获取一个 global job ID 然后放到 job queue 中去。
- DDL 组件启动后,在 start 函数中会启动一个
ddl_worker协程运行 onDDLWorker 函数(最新 Master 分支函数名已重命名为 start),每隔一段时间调用 handleDDLJobQueue 函数去尝试处理 DDL job 队列里的 job,ddl_worker会先 check 自己是不是 owner,如果不是 owner,就什么也不做,然后返回;如果是 owner,就调用 getFirstDDLJob 函数获取 DDL 队列中的第一个 job,然后调 runDDLJob 函数执行 job。- runDDLJob 函数里面会根据 job 的类型,然后调用对应的执行函数,对于
create table类型的 job,会调用 onCreateTable 函数,然后做一些 check 后,会调用 t.CreateTable 函数,将db_ID和table_ID映射为key,tableInfo作为 value 存到 TiKV 里面去,并更新 job 的状态。
- runDDLJob 函数里面会根据 job 的类型,然后调用对应的执行函数,对于
- finishDDLJob 函数将 job 从 DDL job 队列中移除,然后加入 history ddl job 队列中去。
- doDDLJob 函数中检测到 history DDL job 队列中有对应的 job 后,返回。
Add index
add index 主要做 2 件事:
-
修改 table 的元信息,把
indexInfo加入到 table 的元信息中去。 -
把 table 中已有了的数据行,把
index columns的值全部回填到index record中去。
具体执行流程的前部分的 SQL 解析、Compile 等流程,和 create table 一样,可以直接从 DDLExec.Next 开始看,然后调用 alter 语句的 e.executeAlterTable(x) 函数,其实质调 ddl 的 AlterTable 函数,然后调用 CreateIndex 函数,开始执行 add index 的主要工作,具体流程如下:
- Check 一些限制,比如 table 是否存在,索引是否已经存在,索引名是否太长等。
-
封装成一个 job,包含了索引名,索引列等,并将 job 的 type 标记为
ActionAddIndex。 - 给 job 获取一个 global job ID 然后放到 DDL job 队列中去。
-
owner ddl worker从 DDL job 队列中取出 job,根据 job 的类型调用 onCreateIndex 函数。buildIndexInfo生成indexInfo,然后更新tableInfo中的Indices,持久化到 TiKV 中去。- 这里引入了 online schema change 的几个步骤,需要留意 indexInfo 的状态变化:
none -> delete only -> write only -> reorganization -> public。在reorganization -> public时,首先调用 getReorgInfo 获取reorgInfo,主要包含需要reorganization的 range,即从表的第一行一直到最后一行数据都需要回填到index record中。然后调用 runReorgJob , addTableIndex 函数开始填充数据到index record中去。runReorgJob 函数会定期保存回填数据的进度到 TiKV。addTableIndex 的流程如下:- 启动多个
worker用于并发回填数据到index record。 - 把
reorgInfo中需要reorganization分裂成多个 range。扫描的默认范围是[startHandle , endHandle],然后默认以 128 为间隔分裂成多个 range,之后并行扫描对应数据行。在 master 分支中,range 范围信息是从 PD 中获取。 - 把 range 包装成多个 task,发给
worker并行回填index record。 - 等待所有
worker完成后,更新reorg进度,然后持续第 3 步直到所有的 task 都做完。
- 启动多个
-
后续执行 finishDDLJob,检测 history ddl job 流程和
create table类似。
Drop Column
drop Column 只要修改 table 的元信息,把 table 元信息中对应的要删除的 column 删除。drop Column 不会删除原有 table 数据行中的对应的 Column 数据,在 decode 一行数据时,会根据 table 的元信息来 decode。
具体执行流程的前部分都类似,直接跳到 DropColumn 函数开始,具体执行流程如下:
- Check table 是否存在,要 drop 的 column 是否存在等。
-
封装成一个 job, 将 job 类型标记为
ActionDropColumn,然后放到 DDL job 队列中去 -
owner ddl worker从 DDL job 队列中取出 job,根据 job 的类型调用 onDropColumn 函数:- 这里
column info的状态变化和add index时的变化几乎相反:public -> write only -> delete only -> reorganization -> absent。 - updateVersionAndTableInfo 更新 table 元信息中的 Columns。
- 这里
-
后续执行 finishDDLJob,检测 history ddl job 流程和
create table类似。
Drop table
drop table 需要删除 table 的元信息和 table 中的数据。
具体执行流程的前部分都类似,owner ddl worker 从 DDL job 队列中取出 job 后执行 onDropTable 函数:
-
tableInfo的状态变化是:public -> write only -> delete only -> none。 -
tableInfo的状态变为none之后,会调用 DropTable 将 table 的元信息从 TiKV 上删除。
至于删除 table 中的数据,后面在调用 finishDDLJob 函数将 job 从 job queue 中移除,加入 history ddl job queue 前,会调用 delRangeManager.addDelRangeJob(job),将要删除的 table 数据范围插入到表 gc_delete_range 中,然后由 GC worker 根据 gc_delete_range 中的信息在 GC 过程中做真正的删除数据操作。
New Parallel DDL
目前 TiDB 最新的 Master 分支的 DDL 引入了并行 DDL,用来加速多个 DDL 语句的执行速度。因为串行执行 DDL 时,add index 操作需要把 table 中已有的数据回填到 index record 中,如果 table 中的数据较多,回填数据的耗时较长,就会阻塞后面 DDL 的操作。目前并行 DDL 的设计是将 add index job 放到新增的 add index job queue 中去,其它类型的 DDL job 还是放在原来的 job queue。相应的,也增加一个 add index worker 来处理 add index job queue 中的 job。
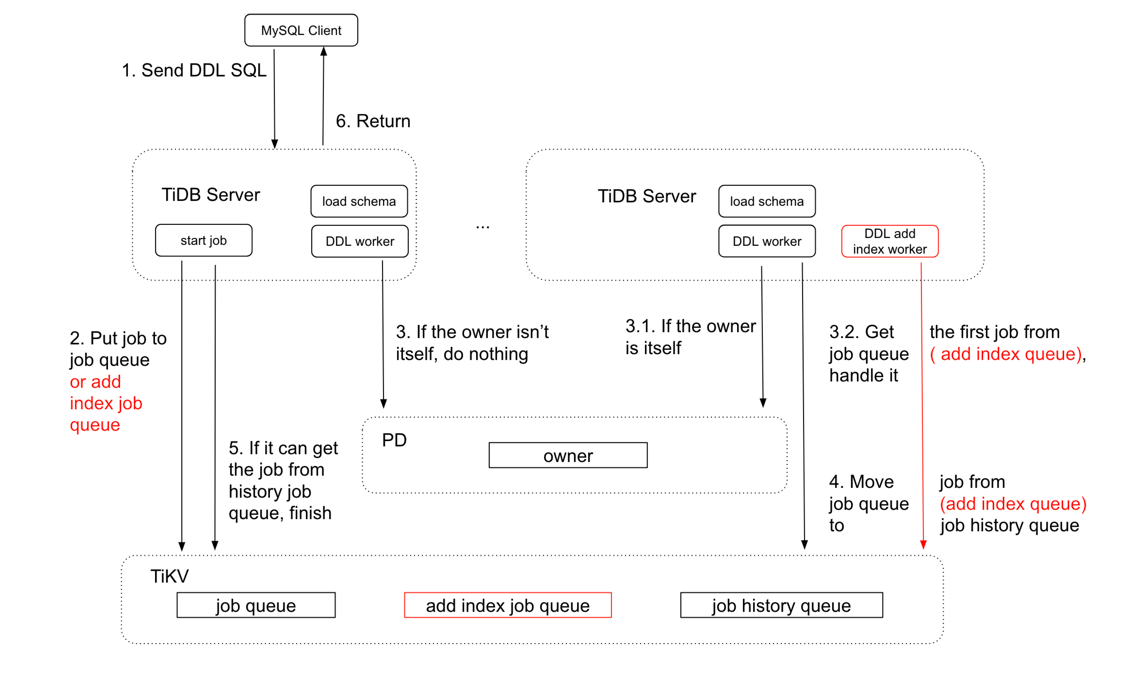
并行 DDL 同时也引入了 job 依赖的问题。job 依赖是指同一 table 的 DDL job,job ID 小的需要先执行。因为对于同一个 table 的 DDL 操作必须是顺序执行的。比如说,add column a,然后 add index on column a, 如果 add index 先执行,而 add column 的 DDL 假设还在排队未执行,这时 add index on column a 就会报错说找不到 column a。所以当 add index job queue 中的 job2 执行前,需要检测 job queue 是否有同一 table 的 job1 还未执行,通过对比 job 的 job ID 大小来判断。执行 job queue 中的 job 时也需要检查 add index job queue 中是否有依赖的 job 还未执行。
End
TiDB 目前一共支持 十多种 DDL,具体以及和 MySQL 兼容性对比可以看 CREATE TABLE 文档。剩余其它类型的 DDL 源码实现读者可以自行阅读,流程和上述几种 DDL 类似。
点击查看更多 TiDB 源码阅读系列文章
目录