
导读
在日常业务使用或运维管理 TiDB 的过程中,每个开发人员或数据库管理员都或多或少遇到过 SQL 变慢的问题。这类问题大部分情况下都具有一定的规律可循,通过经验的积累可以快速的定位和优化。但是有些情况下不一定很好排查,尤其涉及到内核调优等方向时,如果事先没有对各个组件的互访关系、引擎存储原理等有一定的了解,往往难以下手。
本文针对写 TiDB 集群的场景,总结业务 SQL 在写突然变慢时的分析和排查思路,旨在沉淀经验、共享与社区。
相关阅读:最佳实践:TiDB 业务读变慢分析处理
写入原理
业务对集群的数据写入流程会被 TiDB Server 封装为一个个的写事务,写事务的完成主要涉及的组件是 TiDB Server 和 TiKV Server。如下所示,是 TiDB 集群写入流程的架构简图:
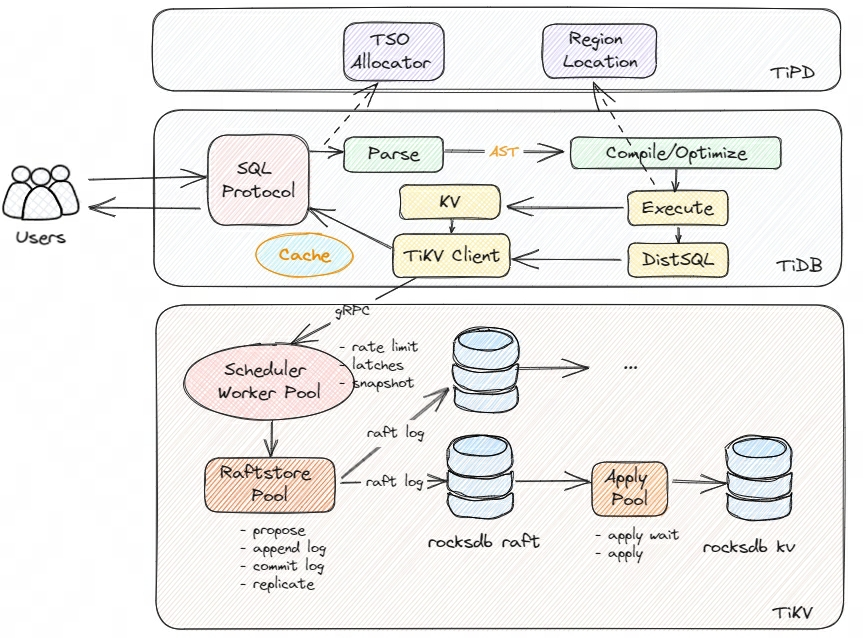
事务在写入的过程,分别会与 TiDB Server、PD 和 TiKV Server 进行交互:
TiDB Server
- 用户提交的业务 SQL 经过 Protocol Layer 进行 SQL 协议转换后,内部 PD Client 向 PD Server 申请到一个 TSO,此 TSO 即为事务的开始时间 txn_start_tso,同时也是事务在全局的唯一 ID
- 接着 TiDB Server 对 SQL 文本进行解析处理,转为抽象语法树 AST 传给下一个处理模块
- TiDB Server 对 AST 进行编译、SQL 等价改写等逻辑优化、参考系统统计信息进行物理优化后,会生成真正可以执行的计划
- 可执行的计划经过分析判断,点查询操作转到KV模块、复杂查询转到 DistSQL 模块(继续转为对单个表访问的多个请求),再经过 TiKV Client 模块与 TiKV 进行交互,在 TiDB Server 这一侧完成对数据的访问
TiKV Server
- TiKV 的 Scheduler Worker Pool 模块负责接收通过 gRPC 传过来的写请求数据,在这里它能实现写入流量的控制、锁冲突检查与获取(latch)、快照(snapshot)版本对比的功能
- 前面的校验通过后,写入的数据会进入到 Raftstore Pool 模块,它会将写入数据的请求封装为 raft log (Propose ),在本地持久化(append)的同时并发分发到 follower 节点,接着完成 raft log 的 commit 操作,最后将 raft log 日志数据写入到 rocksdb raft
- Apply Pool 模块充当消费者的的角色,会消费 rocksdb raft 里面的日志数据,转为真正的 KV 数据存储到 rocksdb KV,至此完成了一次写入数据的流程
- rocksdb 里面的数据写入包括了 LSM Tree 的写入过程,主要方面有 WAL、MemTable 、Immutable Table、L0\~L6 层的内存或磁盘 IO 操作,这里并没有详细阐述,有兴趣的可以前往官网查阅。
- 图中 Raftstore Pool 和 Apply Pool 这两步通常统称为 Async Write 操作,这个是 TiKV 写入数据的关键流程,也是数据写入分析的重点环节所在。
- Raftstore Pool 和 Apply Pool 处理数据的过程涉及到线程池的调度和处理等,主要消耗 CPU 资源
- rocksdb raft 和 rocksdb kv 由于涉及到数据落盘,主要消耗磁盘 IO 资源
- 数据在不同 TiKV 节点之间进行复制、同步等,主要消耗网络带宽 IO 资源
写变慢排查思路
常规排查
通常业务的 SQL 变慢后,我们在 TiDB Server 的 Grafana 面板可以看到整体的或者某一百分位的请求延迟会升高,我们可以依次排查物理硬件环境、是否有业务变更操作、数据库运行的情况等,定位到问题后再针对性解决。
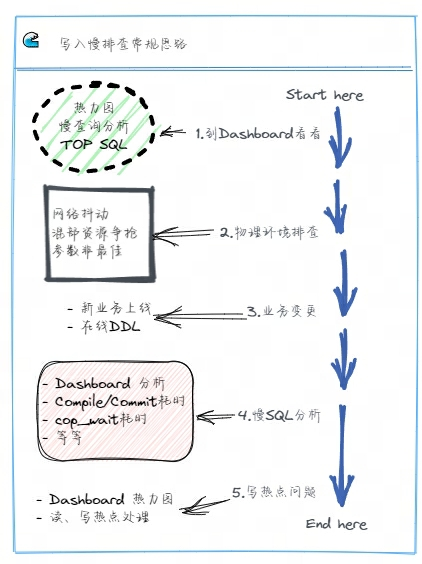
如上图是一个写入慢的常规排查思路,在实际工作中对于各项内容的排查可以同时进行,交叉分析,互相配合定位问题所在。
- 遇到问题,先到 Dashboard 看看,对整个集群运行状况有个整体的把握
- 查看集群热力图,关注集群高亮的区域,分析是否有写热点出现,如果有则确认对应的库表、Region 等信息
- 排查慢 SQL 情况,查看集群慢查询结果,分析 SQL 慢查询原因
- 查看 TOP SQL 面板,分析集群的 CPU 消耗与 SQL 关联的情况
- 物理硬件排查
- 排查客户端与集群之间、集群内部 TiDB 、PD、TiKV 各组件之间的网络问题
- 排查集群的内存、CPU、磁盘 IO 等情况,尤其是混合部署的集群,确认是否存在资源相互竞争、挤兑的场景出现
- 排查操作系统的内核操作是否与官方建议的最佳实践值是否一致,确认 TiDB 集群运行在最优的系统环境内
- 业务变更
- 确认是否是新上线业务
- 查看集群的 DDL Jobs,确认是否由于在线 DDL 导致的问题,特别是大表加索引的场景,会消耗集群较多的资源,从而干扰集群正常的访问请求
全链路排查
对于常规分析无法确认的或者复杂业务的问题,通常排查起来比较棘手,这时候可以分析数据从写入 TiDB Server 到 TiKV Server 、再落盘至 RocksDB 的整个过程,对全部写入链路逐一进行排查,从而确认写入慢所在的节点,定位到原因后再进行优化即可,这一过程大致如下图所示。
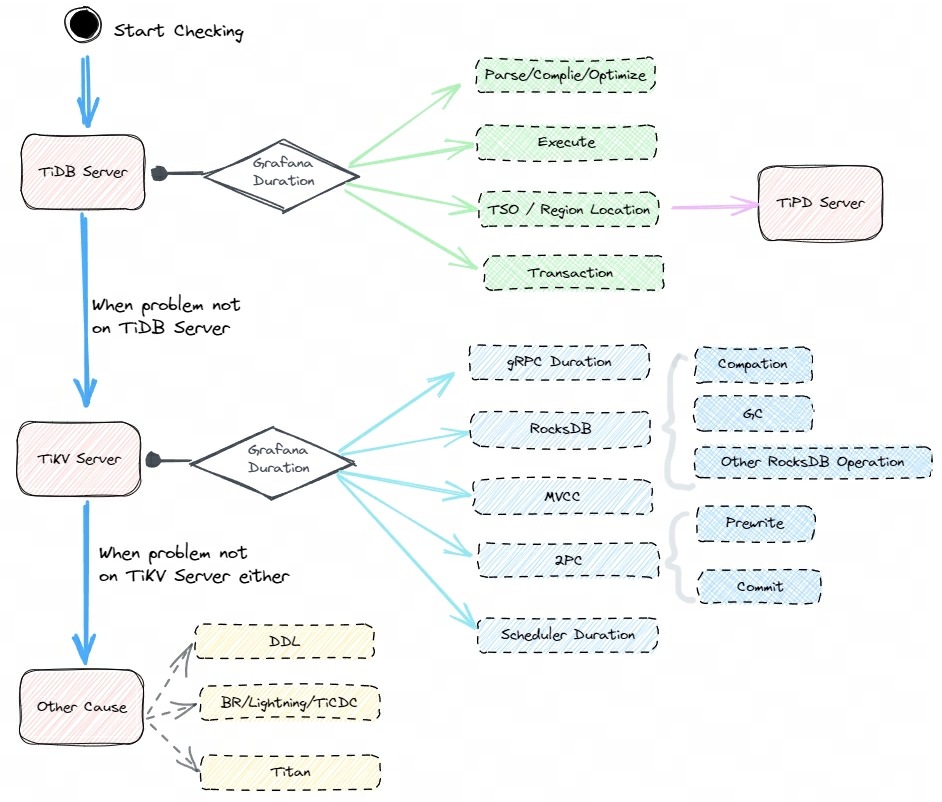
毫无疑问,这个是一个兜底的排查思路,适用范围较广,通用性较强,但是排查起来要花费更多的时间和精力,也要求管理员对数据库本身的运行原理有一定的掌握。
- 对于写入慢的全链路分析,我们首先在问题时段从整体上把握延迟情况,再分析 TiDB Server 和 TiKV Server 在对应时段的延迟,确认问题处于计算层还是存储层,接着再深入分析
- 对于 TiDB Server层,主要观察 SQL 的解析优化过程耗时,以及和 PD 进行交互过程的延迟情况
- 对于 TiKV Server 层,重点关注 Scheduler Worker Pool 、Raft log 同步复制与写入、Apply 这几个过程
上面的写入过程的延迟情况,可以从集群的 Grafana 监控面板观察得到,其中 TiKV 是重点所在,其每个阶段写入的流程以及对应在 Grafana 上的延迟监控面板如下。
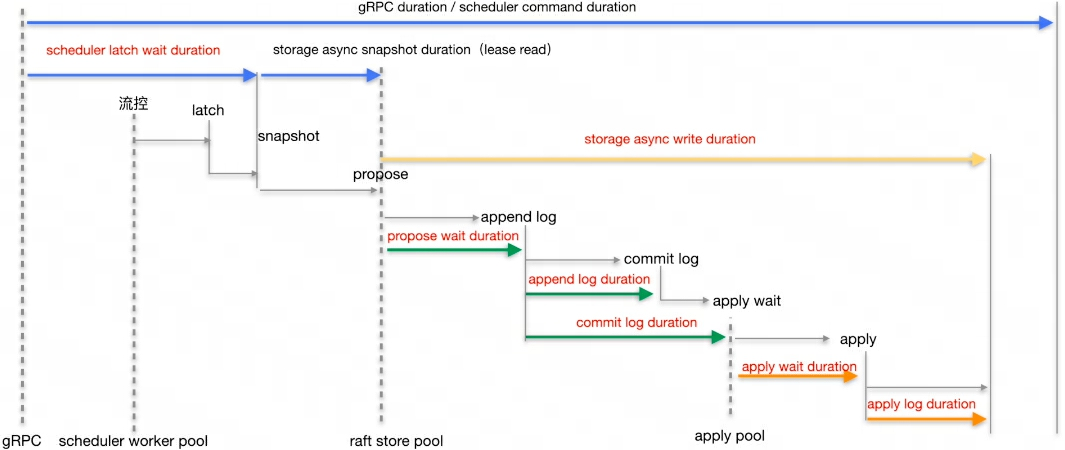
- gRPC duration 或 Scheduler command duration 表示整个写入过程在 TiKV 侧的耗时情况
- gRPC duration 是请求在 TiKV 端的总耗时。通过对比 TiKV 的 gRPC duration 以及 TiDB 中的 KV duration 可以发现潜在的网络问题。比如 gRPC duration 很短但是 TiDB 的 KV duration 显示很长,说明 TiDB 和 TiKV 之间网络延迟可能很高,或者 TiDB 和 TiKV 之间的网卡带宽被占满
- TiKV Details 下 Scheduler - commit 的 Scheduler command duration 表示执行 commit 命令所需花费的时间,正常情况下,应该小于 1s
- TiKV Details 下 Scheduler - commit 的 Scheduler latch wait duration表示由于等到锁 latch wait 造成的时间开销,正常情况下应该小于 1s
- TiKV Details 下 Storage 的 Storage async snapshot duration 表示异步处理 snapshot 所花费的时间,99% 的情况下应该小于 1s
- TiKV Details 下 Storage 的 Storage async write duration 表示异步写所花费的时间,99% 的情况下应该小于 1s
- TiKV Details 下 Raft propose 的 Propose wait duration 表示将写入数据请求转为 raft log 的等待时间
- TiKV Details 下 Raft IO 的 Append log duration 表示 Raft append 日志所花费的时间
- TiKV Details 下 Raft IO 的 Commit log duration 表示 Raft commit 日志所花费的时间
- TiKV Details 下 Raft propose 的 Apply wait duration 表示 apply 的等待时间
- TiKV Details 下 Raft IO 的 Apply log duration 表示 Raft apply 日志所花费的时间
通过对比分析不同阶段的延迟在整体中的占比,通常可以定位到比较慢的环节,然后再针对性优化即可。
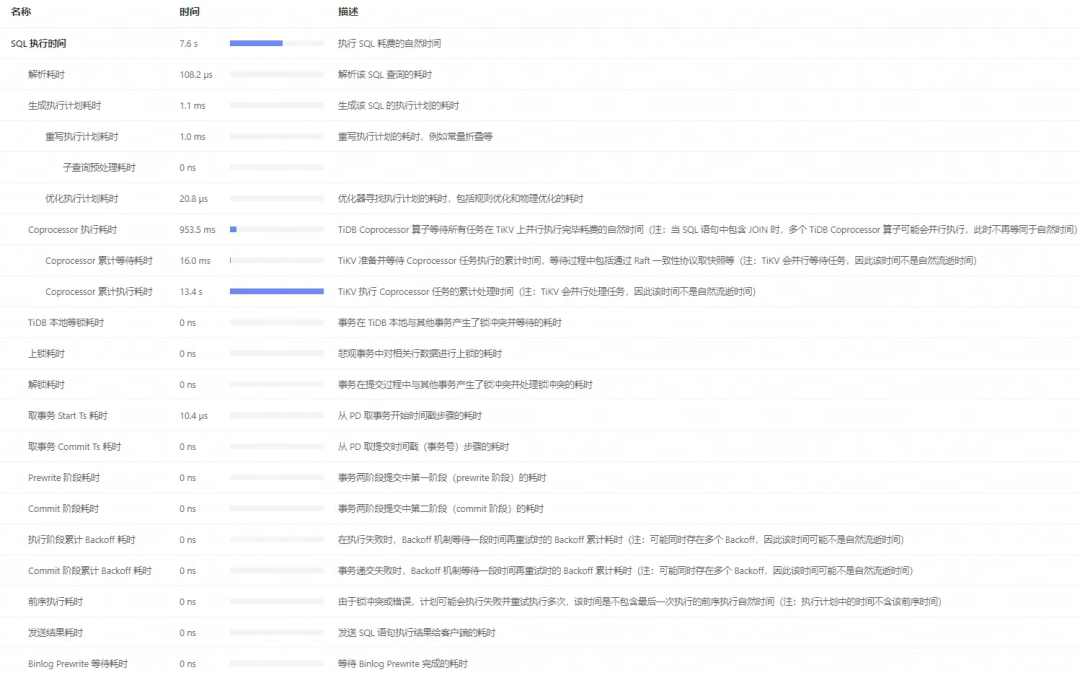
官方的 Dashboard 已经帮我们把各个环节汇总了起来,定位到具体的慢写入 SQL 后,可以查看其执行时间,下面是一个例子,里面每个环节的耗时和解释都写得非常清楚,大大降低了问题排查的难度和时间,非常好用:
总结
- 常规写入慢的问题,我们可以依次排查物理硬件环境、是否有业务新上线,是否有 DDL 变更操作、执行计划不准、热点问题等情况,通常可以定位到问题,再针对性解决
- 对于复杂问题则需要对写入过程逐一分析和对比,通常需要反复观察、对比、验证才能找到根本的原因
对于开发人员或 DBA,会解决具体的问题是一项很重要的能力,但定位问题根因所在的能力更难能可贵!
这里想表达的意思,和大家耳熟能详的故事异曲同工:
“老师傅,故障已排除,但就凭这一条线也要 10000$ ?!”
“画这条线要 1$,但知道在哪里画要 9999$!”
目录