
导读
在 TiDB 中,优化器的作用至关重要,它决定了 SQL 查询的执行计划,从而直接影响查询性能。尽管 TiDB 优化器采用了代价模型来选择最优执行计划,但由于统计信息、估算误差等因素,优化器并不能保证每次都选中最佳计划。本文深入解析了 TiDB 优化器的执行计划生成过程及其局限性,介绍了如何通过 Hint、SQL Binding、执行计划缓存等技术手段进行执行计划管理,确保查询性能的稳定性和高效性。
背景与现状
优化器和执行计划的影响
在数据库中,优化器负责将用户的 SQL 转换成执行计划,执行计划决定了数据库会怎么执行这条 SQL,如:
- 通过什么方式(全表扫描还是索引扫描)访问数据;
- 多表 Join 的顺序(先 Join 那几个表)及方式(HashJoin 还是 IndexJoin 等);
- 在 HTAP 系统中访问行存还是列存存储引擎等。
不同计划的执行效率可能有数量级的差异,错误计划可能带来很大的负面影响,以下面这个 SQL 为例:
create table customers (id int primary key, address varchar(20), key addr(address));
select count(*) from customers where address in ("X", "Y");这个 SQL 查询特定区域的用户数,对于这个 SQL 访问数据的方式有两种:
- 使用
primary key扫描数据,此时无法利用address的条件,需要扫描全部数据; - 使用
key(addr)索引扫描,可以把address in (...)的条件转换为此索引上的一小段扫描范围,减少需要扫描的数据量,提高执行效率。
比如这张表有 1000000 数据,但是 "X" 和 "Y" 的用户只有 20 个,那选择 key(addr) 仅需要扫描 20 行数据,而 primary key 则需要扫描 1000000 行。
TiDB 如何基于 CBO 选择执行计划
简单来说 TiDB 优化器生成执行计划有 3 步:
- 解析这个 SQL,得到一个最基础的 Plan;
- 在此 Plan 上进行改写和探索,得到多个相同语义的 Plan;
- 利用代价模型对这些 Plan 估算代价,选代价最低的那个。
我们以上面的 select count(*) from customers where address in ("X", "Y") 为例。
此 SQL 有两种扫描数据方式,我们用 explain format='cost_trace' 让优化器输出对应的代价计算过程。
如果使用 key(addr) 索引:
mysql> explain format='cost_trace' select count(*) from customers where address in ("X", "Y");
+-----------------------------+---------+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+--------------------------------------+----------------------------------------------+
| id | estRows | estCost | costFormula | task | access object | operator info |
+-----------------------------+---------+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+--------------------------------------+----------------------------------------------+
| StreamAgg_17 | 1.00 | 290.57 | ((((scan(20*logrowsize(9)*tikv_scan_factor(40.7))) + (agg(20*aggs(1)*tikv_cpu_factor(49.9))) + (group(20*cols(0)*tikv_cpu_factor(49.9)))) + (net(1*rowsize(8)*tidb_kv_net_factor(3.96))))/15.00) + (agg(1*aggs(1)*tidb_cpu_factor(49.9))) + (group(1*cols(0)*tidb_cpu_factor(49.9))) | root | | funcs:count(Column#5)->Column#3 |
| └─IndexReader_18 | 1.00 | 240.67 | (((scan(20*logrowsize(9)*tikv_scan_factor(40.7))) + (agg(20*aggs(1)*tikv_cpu_factor(49.9))) + (group(20*cols(0)*tikv_cpu_factor(49.9)))) + (net(1*rowsize(8)*tidb_kv_net_factor(3.96))))/15.00 | root | | index:StreamAgg_9 |
| └─StreamAgg_9 | 1.00 | 3578.32 | (scan(20*logrowsize(9)*tikv_scan_factor(40.7))) + (agg(20*aggs(1)*tikv_cpu_factor(49.9))) + (group(20*cols(0)*tikv_cpu_factor(49.9))) | cop[tikv] | | funcs:count(1)->Column#5 |
| └─IndexRangeScan_16 | 20.00 | 2580.32 | scan(20*logrowsize(9)*tikv_scan_factor(40.7)) | cop[tikv] | table:customers, index:addr(address) | range:["X","X"], ["Y","Y"], keep order:false |
+-----------------------------+---------+---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+--------------------------------------+----------------------------------------------+costFormula 这一列直接输出每个算子(包含其孩子节点)的代价公式:
IndexRangeScan_16:优化器估计会访问 20 行数据,行宽是 9 bytes,TiKV 的扫描因子是 40.7,所以对于这个算子,带入优化器的代价公式则是20*log(9)*40.7 = 2580.32;StreamAgg_9:优化器估计他需要处理 20 行数据,他有 1 个 agg 函数,TiKV 的 CPU 计算因子是 49.9,因此聚合函数的代价是20 * 1 * 49.9 = 998;由于没有group by子句,后面group代价部分的 col 是 0,因此后面group的代价则是 0,这个算子及其孩子的代价就是998+2580.32+0 = 3578.32;IndexReader_18:同理,会考虑上网络传输的代价,以及执行计划并发(默认的并发为 15);StreamAgg_17:同理,考虑最终对结果做聚合的代价,最终得到代价290.57作为此执行计划的代价。
作为对比,再看下使用 primary key 的代价:(我们使用 Hint 让优化器忽略 addr 索引)
mysql> explain format='cost_trace' select /*+ ignore_index(customers, addr) */ count(*) from customers where address in ("X", "Y");
+------------------------------+---------+------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+-----------------+--------------------------------------+
| id | estRows | estCost | costFormula | task | access object | operator info |
+------------------------------+---------+------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+-----------------+--------------------------------------+
| StreamAgg_20 | 1.00 | 80072.07 | (((((cpu(5020*filters(1)*tikv_cpu_factor(49.9))) + (scan(5020*logrowsize(25)*tikv_scan_factor(40.7)))) + (agg(20*aggs(1)*tikv_cpu_factor(49.9))) + (group(20*cols(0)*tikv_cpu_factor(49.9)))) + (net(1*rowsize(8)*tidb_kv_net_factor(3.96))))/15.00) + (agg(1*aggs(1)*tidb_cpu_factor(49.9))) + (group(1*cols(0)*tidb_cpu_factor(49.9))) | root | | funcs:count(Column#5)->Column#3 |
| └─TableReader_21 | 1.00 | 80022.17 | ((((cpu(5020*filters(1)*tikv_cpu_factor(49.9))) + (scan(5020*logrowsize(25)*tikv_scan_factor(40.7)))) + (agg(20*aggs(1)*tikv_cpu_factor(49.9))) + (group(20*cols(0)*tikv_cpu_factor(49.9)))) + (net(1*rowsize(8)*tidb_kv_net_factor(3.96))))/15.00 | root | | data:StreamAgg_9 |
| └─StreamAgg_9 | 1.00 | 1200300.83 | ((cpu(5020*filters(1)*tikv_cpu_factor(49.9))) + (scan(5020*logrowsize(25)*tikv_scan_factor(40.7)))) + (agg(20*aggs(1)*tikv_cpu_factor(49.9))) + (group(20*cols(0)*tikv_cpu_factor(49.9))) | cop[tikv] | | funcs:count(1)->Column#5 |
| └─Selection_19 | 20.00 | 1199302.83 | (cpu(5020*filters(1)*tikv_cpu_factor(49.9))) + (scan(5020*logrowsize(25)*tikv_scan_factor(40.7))) | cop[tikv] | | in(test.customers.address, "X", "Y") |
| └─TableFullScan_18 | 5020.00 | 948804.83 | scan(5020*logrowsize(25)*tikv_scan_factor(40.7)) | cop[tikv] | table:customers | keep order:false |
+------------------------------+---------+------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+-----------------+--------------------------------------+我们直接看 TableFullScan_18 ,如果不用 addr 索引,则需要全部扫描,总共需要扫描的行数增加到了 5020,且行宽更大为 25,最终光是扫描代价就是 948804.83,远高于上一个执行计划,因此优化器会在两个执行计划中选择上一个。
优化器为什么会选错计划
优化器内的几个模块相互协同工作产生最后的执行计划:改写模块依赖代价模型确定最优计划,代价模型需要依赖基数估算来计算代价,而基数估算又依赖统计信息。
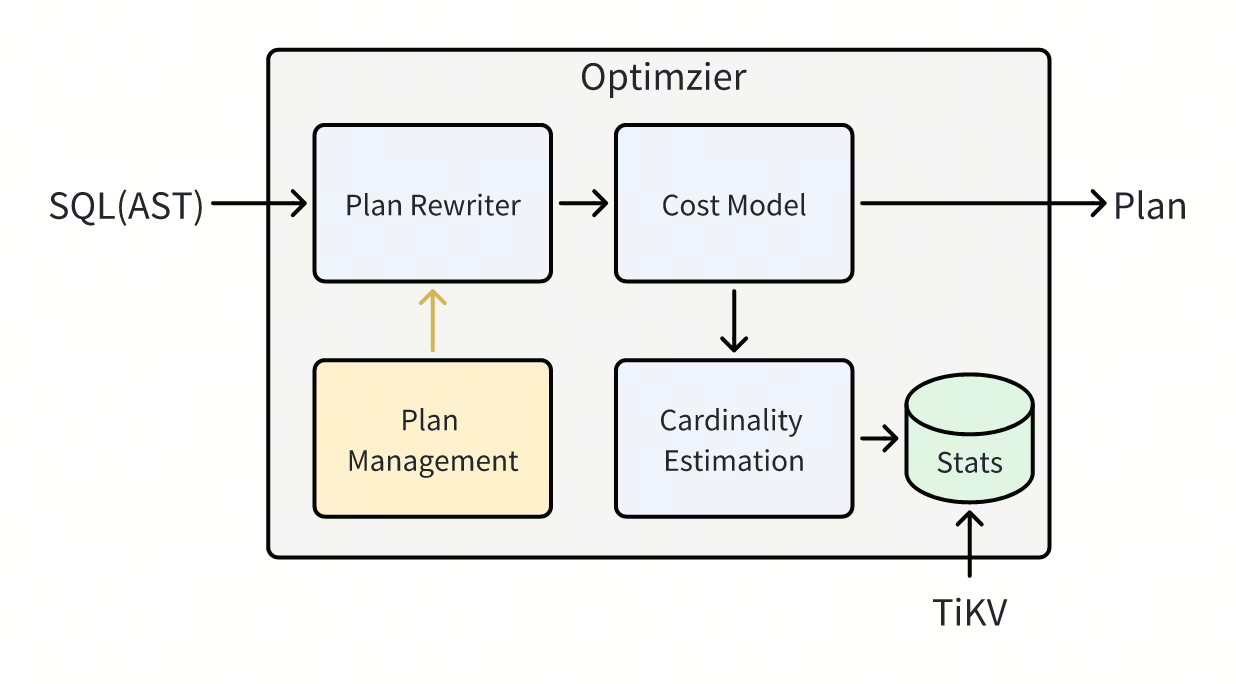
受限于各个模块自身的局限性和统计信息的问题,优化器无法保证每次都选对计划:
- 改写模块的局限性:比如优化器不支持某种特定的改写规则,如把
select min(a) from t改写成select a from t order by a limit 1,则可能无法利用上对应索引,选不上最优计划; - 代价模型的局限性:代价模型基于一些简化后的假设,比如在内存中处理一行数据的速度,是在磁盘上扫描一行数据速度的
100倍,但是由于物理环境的不同,这个假设可能被打破,导致代价模型不能完全准确; - 基数估计的局限性:基数估算会包含一些简化的假设,比如
where a=1 and b=1,优化器可能会先分别计算a=1,b=1的选择率(一行数据通过此条件的概率),然后基于独立条件假设,把他们的选择率乘起来作为最终的选择率,但是当a和b有较强的相关性时,此假设可能不成立,比如where country='CN' and city='Shanghai'。 - 统计信息不准确或缺失:比如新表还未搜集过统计信息、统计信息过期无法准确的刻画现在的数据分布,此时可能导致优化器无法准确进行基数估算,最终导致选错计划;
总之受限于技术原因,优化器无法保证完全选中最优计划,因此执行计划管理,是降低风险的重要措施。
执行计划管理可以指定优化器针对某些 SQL,只考虑特定的执行计划,比如针对上述查询,只考虑使用 key(addr) 索引的执行计划,可以减少甚至消除优化器选错计划的概率。
TiDB 执行计划管理
TiDB 可以通过 Hint、Binding、相关变量及 Plan Cache 来进行执行计划干预和管理,接下来会依次介绍。
SQL Hint
TiDB Hint 介绍
SQL Hint 是一种特殊的语法,用来告诉查询优化器如何生成执行计划,以达到人为控制或干预执行计划的目的。
比如在最开始的例子中,你可以使用 use_index 来手动指定选择 key(addr) 还是 primary(id) 作为索引来访问 customers 表:
select /*+ use_index(customers, addr) */ count(*) from customers where address in ("X", "Y");
select /*+ use_index(customers, primary) */ count(*) from customers where address in ("X", "Y");TiDB 支持超过 30 种 Hint,可以用来控制执行计划的方方面面。
全部的 Hint 可以在 TiDB Optimizer Hints 官方文档中查询,这些 Hint 可以被分为下面 5 类:
- 索引访问相关,如
use_index,ignore_index等告诉优化器是否选择某个索引; - Join 相关,如
hash_join,inl_join等指定特殊的 Join 方式,或leading,straight_join等指定 Join 顺序; - 资源控制相关,如
max_execution_time,memory_quota指定查询的最大执行时间和内存,或resource_group给查询指定特定的资源组; - HTAP 计划相关,如
read_from_storage指定从列存引擎读取出具,或mpp_2phase_agg指定用两阶段聚合等; - 其他特殊功能相关,如
ignore_plan_cache是否关闭对此条查询的缓存,或read_consistent_replica是否对查询开启 TiKV Follower 节点读取特性等;
怎么使用 Hint
Hint 不区分大小写,且支持 DML 语句,通过 /*+ ...*/ 的形式跟在 SELECT, INSERT, UPDATE 或 DELETE 关键字后即可生效。
多个 Hint 可以一起使用,使用逗号分开即可,如:
select /*+ use_index(c, primary), inl_join(o, c) */ o.id
from customers c, orders o
where c.id=100 and o.customer_id=c.id;在上述例子中,我们同时使用了两个 hint:
- 首先通过
use_index(c, primary)指定使用primary(id)访问c表以利用c.id=100的条件; - 然后使用
inl_join(o)指定c和o用IndexJoin进行联接,避免对o表进行全表扫描;
配合 Explain 语句,可以直接看到调整后的执行计划,如:
mysql> explain select /*+ use_index(c, addr), inl_join(o) */ o.id from customers c, orders o where c.address="X" and o.customer_id=c.id;
+-----------------------------+---------+-----------+---------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+---------+-----------+---------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------+
| IndexJoin_12 | 12.50 | root | | inner join, inner:IndexReader_11, outer key:test.customers.id, inner key:test.orders.customer_id, equal cond:eq(test.customers.id, test.orders.customer_id) |
| ├─IndexReader_29(Build) | 10.00 | root | | index:IndexRangeScan_28 |
| │ └─IndexRangeScan_28 | 10.00 | cop[tikv] | table:c, index:addr(address) | range:["X","X"], keep order:false, stats:pseudo |
| └─IndexReader_11(Probe) | 12.50 | root | | index:Selection_10 |
| └─Selection_10 | 12.50 | cop[tikv] | | not(isnull(test.orders.customer_id)) |
| └─IndexRangeScan_9 | 12.51 | cop[tikv] | table:o, index:cid(customer_id) | range: decided by [eq(test.orders.customer_id, test.customers.id)], keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+---------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------+
mysql> explain select /*+ hash_join(o) */ o.id from customers c, orders o where c.address="X" and o.customer_id=c.id;
+-----------------------------+---------+-----------+---------------------------------+--------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+---------+-----------+---------------------------------+--------------------------------------------------------------------+
| HashJoin_33 | 12.50 | root | | inner join, equal:[eq(test.customers.id, test.orders.customer_id)] |
| ├─IndexReader_35(Build) | 10.00 | root | | index:IndexRangeScan_34 |
| │ └─IndexRangeScan_34 | 10.00 | cop[tikv] | table:c, index:addr(address) | range:["X","X"], keep order:false, stats:pseudo |
| └─IndexReader_37(Probe) | 9990.00 | root | | index:IndexFullScan_36 |
| └─IndexFullScan_36 | 9990.00 | cop[tikv] | table:o, index:cid(customer_id) | keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+---------------------------------+--------------------------------------------------------------------+对比使用 HashJoin,第一个计划可以避免掉对 o 表的全表扫描。
如果查询中有子查询,可以直接把 Hint 写在对应的子查询中:
select * from
(select /*+ use_index(t, a) */ max(a),
(select /*+ use_index(t, b) */ max(b) from t)
from t) t1,
(select /* use_index(t, c) */ max(c) from t) t3;也可以通过指定查询块将所有 Hint 写在最外层。TiDB 会自动为查询块命名,最外层的查询为 sel_1,然后按照从左到右的顺序依次为 sel_2, sel_3, ...。
将查询块名字用 @ 指定放在 Hint 的最开头即可生效,如 use_index(@sel_2, t, b):
select /*+ use_index(@sel_2 t, a), use_index(@sel_3 t, b), use_index(@sel_4 t, c) */ * from
(select max(a),
(select max(b) from t)
from t) t1,
(select max(c) from t) t3;此种写法可以将 Hint 都写在一起,在子查询不可修改时可以使用此种方式。
Hint 不生效排查
Hint 对优化器来说只是一种建议,不具有强制性,当 Hint 无法生效时,TiDB 不会直接报错,而是会以 warning 的方式返回 Hint 无法生效的原因,然后继续执行查询,下面是几个例子:
-- 找不到对应的表名
mysql> select /*+ use_index(customer, addr) */ id from customers where address = "X";
Empty set, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+----------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+----------------------------------------------------------------------------------------------+
| Warning | 1815 | use_index(test.customer, addr) is inapplicable, check whether the table(test.customer) exists |
+---------+------+----------------------------------------------------------------------------------------------+
-- 在对应表中找不到对应索引
mysql> select /*+ use_index(customers, addrrr) */ id from customers where address = "X";
Empty set, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+-----------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------+
| Warning | 1176 | Key 'addrrr' doesn't exist in table 'customers' |
+---------+------+-----------------------------------------------+
-- 对应表无列存副本因此无法使用 TiFlash
mysql> select /*+ read_from_storage(tiflash[customers]) */ id from customers where address = "X";
Empty set, 1 warning (0.00 sec)
mysql> show warnings;
+---------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Warning | 1815 | No available path for table test.customers with the store type tiflash of the hint /*+ read_from_storage */, please check the status of the table replica and variable value of tidb_isolation_read_engines |
+---------+------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+导致 Hint 无法生效的原因可能多种多样,更多具体案例可见:TiDB 场景 Hint 不生效问题排查
执行计划绑定 (SQL Binding)
什么是 SQL Binding
Hint 可以控制执行计划,但是需要修改原 SQL,在一些场景下可能无法修改原 SQL,比如 SQL 是由业务代码组合生成得到的,此时就可以用 Binding。
本质上 SQL Binding 相当于是让查询优化器记录下一组 (查询, Hint) 的组合,在下次遇到指定查询时,则自动为查询添加此 Hint,使得在不修改查询原文的情况下干预其查询的执行计划。
Binding 的基本用法
Binding 的创建、验证、查看、删除
Binding 可以通过 SQL 原文或历史执行计划进行创建,具体语法如下:
CREATE [GLOBAL | SESSION] BINDING [FOR BindableStmt] USING BindableStmt;
CREATE [GLOBAL | SESSION] BINDING FROM HISTORY USING PLAN DIGEST <plan_digest>;通过历史计划创建 binding 我们在后续结合最佳实践解释,这里仅介绍第一种创建方式。
GLOBAL 和 SESSION 指定 binding 生效的范围,通常可以先创建 SESSION 级别的 binding,验证无误后再创建 GLOBAL 级别的 binding。
BindableStmt 则是包含对应 Hint 的 SQL,如:
create global binding using
select /*+ use_index(customers, addr) */ count(*) from customers
where address in ("X", "Y");通过此方式创建 binding 后,优化器会做 3 个操作:
- 把其中的 Hint 提取出来,得到
/*+ use_index(customers, addr) */; - 标准化提取 Hint 后的查询,得到
SELECT COUNT(*) FROM customers WHERE address IN (...); - 计算标准化后查询的指纹,比如得到
bd31...cbe2;
后续如果遇到标准化后指纹为 bd31...cbe2 的查询,则会自动把上述提取出来的 Hint 给使用上。
同一个 SQL 指纹的 binding 只能有一个,如果再次创建相同 SQL 指纹的 binding,则会把前一条给覆盖掉。
创建 binding 后可以使用 Explain 和 @@last_plan_from_binding 变量进行验证:
mysql> explain select count(*) from customers where address in ("A");
+-----------------------------+---------+-----------+--------------------------------------+-------------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+---------+-----------+--------------------------------------+-------------------------------------------------+
| StreamAgg_17 | 1.00 | root | | funcs:count(Column#5)->Column#3 |
| └─IndexReader_18 | 1.00 | root | | index:StreamAgg_9 |
| └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#5 |
| └─IndexRangeScan_16 | 10.00 | cop[tikv] | table:customers, index:addr(address) | range:["A","A"], keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+--------------------------------------+-------------------------------------------------+
mysql> select @@last_plan_from_binding;
+--------------------------+
| @@last_plan_from_binding |
+--------------------------+
| 1 |
+--------------------------+@@last_plan_from_binding 为 1 则说明上一条查询的执行计划通过 binding 生成。
通过 show global bindings 则可以查询当前的全部 binding:
mysql> show global bindings;
+--------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+------------+---------+-------------------------+-------------------------+---------+-----------------+--------+------------------------------------------------------------------+-------------+
| Original_sql | Bind_sql | Default_db | Status | Create_time | Update_time | Charset | Collation | Source | Sql_digest | Plan_digest |
+--------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+------------+---------+-------------------------+-------------------------+---------+-----------------+--------+------------------------------------------------------------------+-------------+
| select count ( ? ) from `test` . `customers` where `address` in ( ... ) | SELECT /*+ use_index(`customers` `addr`)*/ count(1) FROM `test`.`customers` WHERE `address` IN ('X','Y') | test | enabled | 2024-11-18 17:04:16.463 | 2024-11-18 17:04:16.463 | utf8 | utf8_general_ci | manual | bd31331855266354bc37ce59161609e1697d2faf7500f1cf2d531bf8c502cbe2 | |
+--------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------+------------+---------+-------------------------+-------------------------+---------+-----------------+--------+------------------------------------------------------------------+-------------+删除 binding 则可以通过 SQL 原文或者指纹来指定删除,语法如下:
DROP [GLOBAL | SESSION] BINDING FOR BindableStmt;
DROP [GLOBAL | SESSION] BINDING FOR SQL DIGEST <sql_digest>;对应到上述 binding 则是:
drop global binding for SELECT count(1) FROM `test`.`customers` WHERE `address` IN ('X','Y');
drop global binding for digest 'bd31331855266354bc37ce59161609e1697d2faf7500f1cf2d531bf8c502cbe2';利用 TiDB Dashboard 快速绑定执行计划
v6.6 及后续版本,TiDB Dashboard 对 Binding 做了 UI 上的支持,配合 Dashboard 可以方便的对不稳定的计划进行排查和绑定。
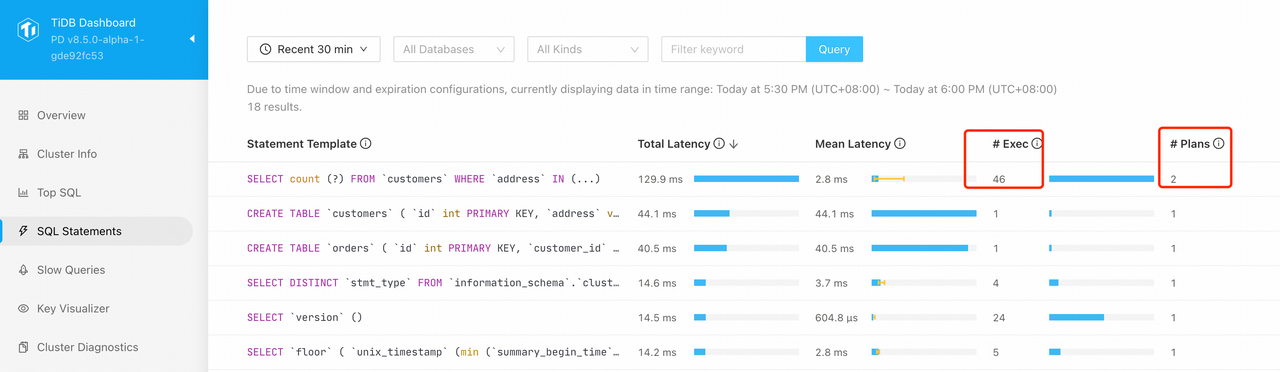
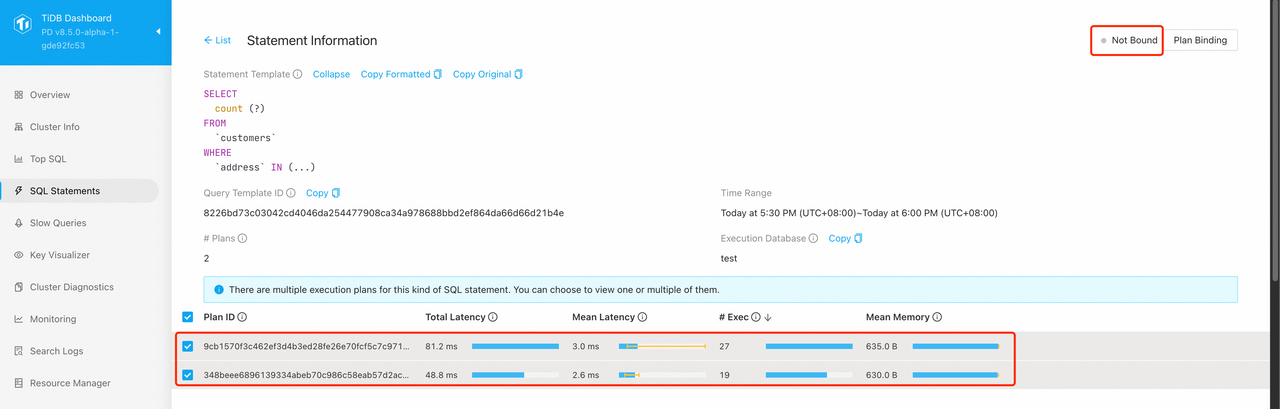
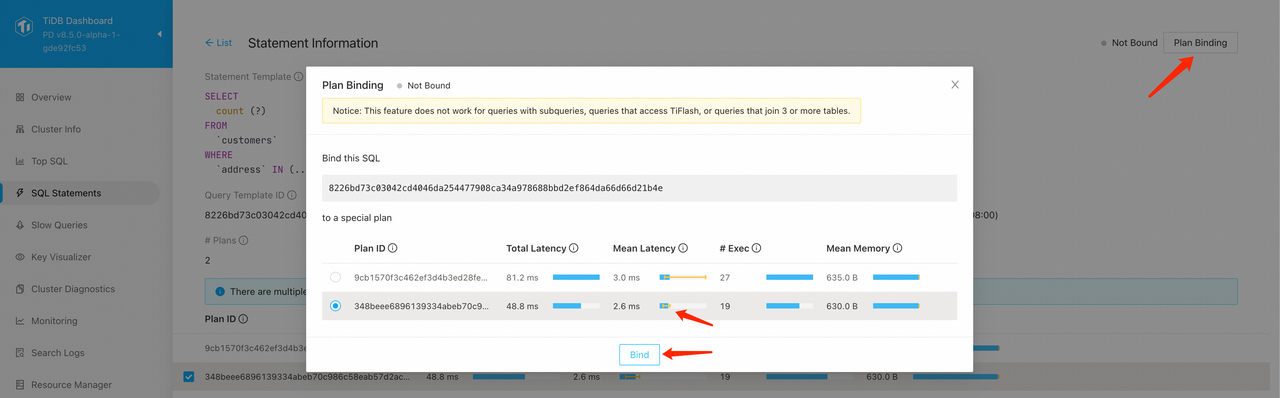
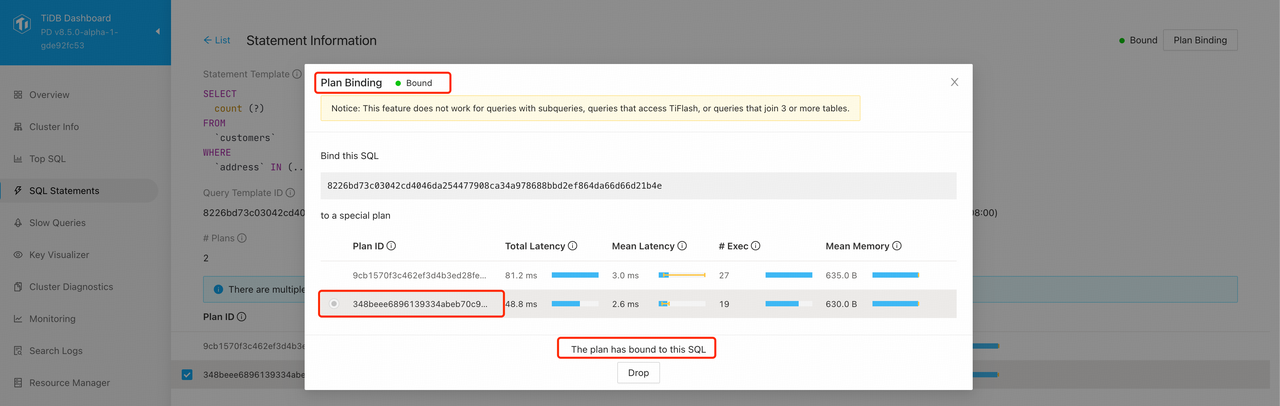
整个过程分为:
- 在 Dashboard-SQLStatements 中,找到执行频率高,且计划不稳定的查询(Plans 数量大于 1);
- 进入对应的 Statement Information 详情页,可以看到此 SQL 尚未绑定,且其对应的执行计划情况;
- 点击右上角的 Plan Binding 按钮,在弹出的页面中,选中执行速度更快更稳定的计划,再点击 Bind 按钮;
- 点击 Bind 按钮后,此 SQL 会被绑定到对应的执行计划上。
跨数据库绑定执行计划
在一些场景中,数据可能按照数据库分开存储,同时各数据库具有相同的对象定义并且运行相似的业务逻辑。比如在 SaaS 或者 PaaS 中,每个租户的数据可能存储在独立的数据库中,且每个租户有相似的查询。
对于这类场景,TiDB 还支持使用通配符 * 表示数据库,实现跨数据库绑定。此功能可以减少此场景下 binding 的数量,方便运维,且让 binding 有扩展性(比如每次创建新租户时,不需要再重新创建一遍 binding)。
该功能自 v7.6.0 开始引入,首先需要开启 tidb_opt_enable_fuzzy_binding 系统变量,下面是一个实例:
CREATE DATABASE tenant1;
CREATE TABLE tenant1.orders (id int primary key, a int, key(a));
CREATE DATABASE tenant2;
CREATE TABLE tenant2.orders (id int primary key, a int, key(a));
SET tidb_opt_enable_fuzzy_binding=1;
CREATE GLOBAL BINDING USING SELECT /*+ use_index(orders, a) */ * FROM *.orders WHERE a=1;
USE tenant1;
SELECT * FROM orders WHERE a=2;
SELECT @@last_plan_from_binding;
+--------------------------+
| @@last_plan_from_binding |
+--------------------------+
| 1 |
+--------------------------+
USE tenant2;
SELECT * FROM orders WHERE a=3;
SELECT @@last_plan_from_binding;
+--------------------------+
| @@last_plan_from_binding |
+--------------------------+
| 1 |
+--------------------------+Binding 最佳实践实例
1. 升级集群前固定高频查询以防计划回退
升级数据库时因为各种原因,可能遇到执行计划变化,为了降低风险,建议在升级前将集群的高频查询进行绑定。
TiDB 的 Statement Summary 表中存放了近期的 SQL 相关的执行信息,如延迟、执行次数、对应计划等。我们可以通过此表查询符合条件的执行计划或 SQL,然后创建对应的 binding。
在 Statement Summary 表中有两列可以帮助创建 binding:
plan_digest: 存放了此执行计划唯一的指纹,可以通过指定历史计划的方式创建 binding;plan_hint: 存放对应 Plan 的一组 Hint,可以通过此 Hint 来创建 binding;
下面是一个例子,这个例子演示:查找过去 2 周执行次数超过 10 次、执行计划不稳定(计划数超过 1 个)、未被绑定的 Select 语句,且按照执行次数排序前 100 条查询:
WITH stmts AS ( -- Gets all information
SELECT * FROM INFORMATION_SCHEMA.CLUSTER_STATEMENTS_SUMMARY
UNION ALL
SELECT * FROM INFORMATION_SCHEMA.CLUSTER_STATEMENTS_SUMMARY_HISTORY
),
best_plans AS (
SELECT plan_digest, `digest`, avg_latency,
CONCAT('create global binding from history using plan digest "', plan_digest, '"') as binding_stmt
FROM stmts t1
WHERE avg_latency = (SELECT min(avg_latency) FROM stmts t2 -- The plan with the lowest query latency
WHERE t2.`digest` = t1.`digest`)
)
SELECT any_value(digest_text) as query,
SUM(exec_count) as exec_count,
plan_hint, binding_stmt
FROM stmts, best_plans
WHERE stmts.`digest` = best_plans.`digest`
AND summary_begin_time > DATE_SUB(NOW(), interval 14 day) -- Executed in the past 2 weeks
AND stmt_type = 'Select' -- Only consider select statements
AND schema_name NOT IN ('INFORMATION_SCHEMA', 'mysql') -- Not an internal query
AND plan_in_binding = 0 -- No binding yet
GROUP BY stmts.`digest`
HAVING COUNT(DISTINCT(stmts.plan_digest)) > 1 -- This query is unstable. It has more than 1 plan.
AND SUM(exec_count) > 10 -- High-frequency, and has been executed more than 10 times.
ORDER BY SUM(exec_count) DESC LIMIT 100; -- Top 100 high-frequency queries.这个 SQL 有点长,但不难理解:
- CTE
stmts用来 unionstatements_summary和statements_summary_history以获取所有执行计划数据,因为超过一段时间的 statements 数据会被归档到statements_summary_history中; - CTE
best_plans选出每个查询的最优计划的指纹,也就是平均耗时最低的计划的指纹; - 主查询部分则是按照预期的规则进行过滤,然后拼出对应的 binding。
上述 SQL 的结果实例如下:
+---------------------------------------------+------------+-----------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+
| query | exec_count | plan_hint | binding_stmt |
+---------------------------------------------+------------+-----------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+
| select * from `t` where `a` = ? and `b` = ? | 401 | use_index(@`sel_1` `test`.`t` `a`), no_order_index(@`sel_1` `test`.`t` `a`) | create global binding from history using plan digest "0d6e97fb1191bbd08dddefa7bd007ec0c422b1416b152662768f43e64a9958a6" |
| select * from `t` where `b` = ? and `c` = ? | 104 | use_index(@`sel_1` `test`.`t` `b`), no_order_index(@`sel_1` `test`.`t` `b`) | create global binding from history using plan digest "80c2aa0aa7e6d3205755823aa8c6165092c8521fb74c06a9204b8d35fc037dd9" |
+---------------------------------------------+------------+-----------------------------------------------------------------------------+-------------------------------------------------------------------------------------------------------------------------+我们找到了两条满足条件的查询,如果需要创建 binding,则直接执行 binding_stmt 列对应的 SQL 即可。
上述 SQL 只是一个基本的例子,还可以根据 statements_summary 的其他字段来定制信息:
- 根据
avg_latency和 SQL 长度来过滤一些查询,因为执行时间或 SQL 较长的查询可能比较复杂,存在多种最优执行计划,不宜绑定; BINARY_PLAN字段中仅有PointGet的查询,这类查询已是最优计划,可以直接绑定;- 过滤
AVG_MEM或AVG_TOTAL_KEYS较高的计划,这类计划消耗资源较多(内存、扫描磁盘),不宜绑定;
2. 利用 TiDB Dashboard 应急计划回退
环境发生变化后,如升级或重新搜集统计信息,执行计划可能发生回退,此时可用 TiDB Dashboard 快速应急。
注意这里计划回退指的是:此查询之前有最优的执行计划,但是由于环境变动,现在无法选中之前的最优执行计划了;如果查询的执行计划一直很差,从来没有过好的执行计划,则此方法不适用。
处理这类问题可以分为两步:
- 从所有的查询中定位出发生回退的查询;
- 利用 binding 把此查询的执行计划调整回之前的最优计划。
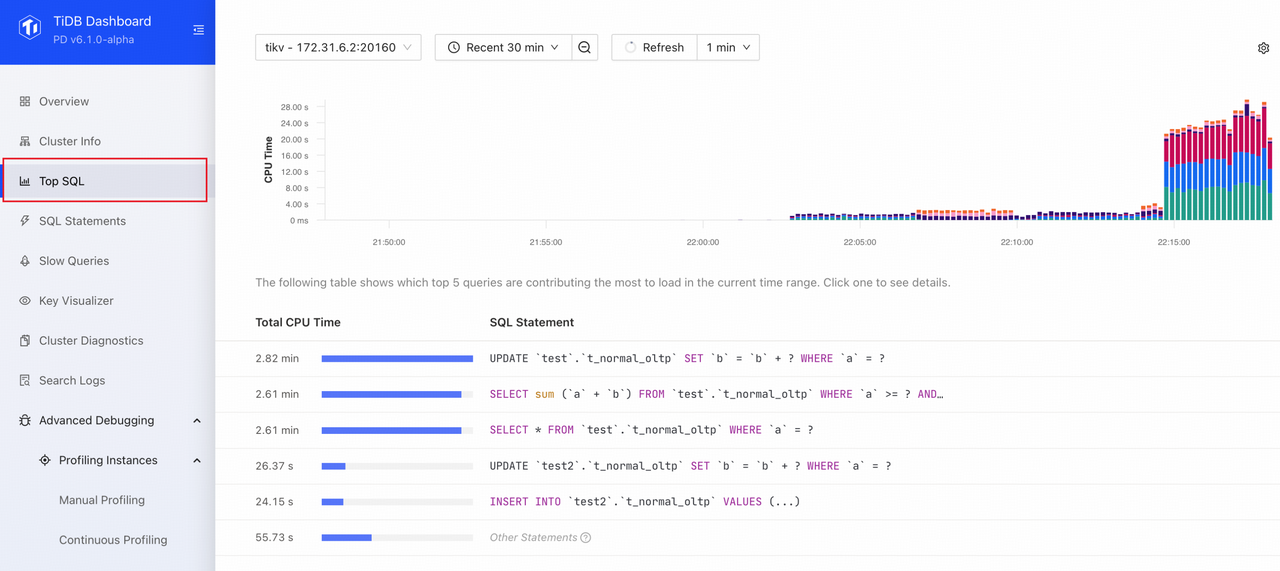
步骤 1 可以利用 TiDB Dashboard 的 TopSQL、慢查询、SQL语句分析 页面来帮助定位:
- 在 TopSQL 或 慢查询 中(如下图),可以直接看到资源消耗最高、对集群影响最大的一些 SQL,然后再找到 SQL 对应的详情页查看其是否发生了计划回退;
- 在 SQL语句分析 页面中,可以按照执行次数或者资源消耗排序,重点关注高频、消耗资源高、且计划不稳定的查询(Plan 数大于 1),判断是否发生了计划回退。
除了 Dashboard,也可以直接通过 SQL 访问 statement summary 来直接得到可能发生了回退的查询。
如下面 SQL,通过对比一天之前和当天的查询的执行时间来筛选出出现了回退的查询。
WITH stmts AS ( -- get all queries
SELECT * FROM INFORMATION_SCHEMA.CLUSTER_STATEMENTS_SUMMARY
UNION ALL
SELECT * FROM INFORMATION_SCHEMA.CLUSTER_STATEMENTS_SUMMARY_HISTORY
),
stmt_yesterday AS (
SELECT `digest`, AVG(avg_latency) AS latency FROM stmts
WHERE summary_begin_time < DATE_SUB(NOW(), interval 1 day)
GROUP BY `digest`
),
stmt_today AS (
SELECT `digest`, AVG(avg_latency) AS latency FROM stmts
WHERE summary_begin_time > DATE_SUB(NOW(), interval 1 day)
GROUP BY `digest`
)
SELECT t.digest FROM stmt_today t, stmt_yesterday y
WHERE t.latency > 20000000 -- more than 20ms
AND (t.latency-y.latency)/y.latency > 0.2 -- regression more than 20%通过步骤 1 定位出出现回退的查询后,则可以直接参考 利用 TiDB Dashboard 快速绑定执行计划,找到对应的查询,绑定其之前的最优计划即可。
影响执行计划的变量
影响执行计划的变量
除了 Hint 和 Binding 外,一些变量也可以用来影响优化器的行为。在所有的 TiDB 系统变量 中,带有 tidb_opt 前缀的变量,都可以用于影响优化器的行为。
对于大多数的变量,保持默认值即可,下面罗列一些可能需要根据情况进行调整的变量:
tidb_opt_enable_non_eval_scalar_subquery:在优化过程中 TiDB 会提前执行非关联子查询,对于仅想用Explain查看执行计划的用户,这可能会增加不必要的开销,比如执行EXPLAIN SELECT * FROM t2 WHERE a = (SELECT a FROM t1)时,实际上会触发对t1的全表扫描,这个开关用于关闭Explain语句的子查询的提前执行。tidb_opt_limit_push_down_threshold:优化器会根据代价来决定是否将Limit ?下推到 TiKV 执行,但是如果统计信息不准时可能出现无法下推的情况,此时可以通过此变量来调节,当?小于此阈值时,优化器会强制下推Limit ?到 TiKV。tidb_opt_prefer_range_scan:如果这个变量被设置为ON,当存在FullScan和RangeScan时,优化器会跳过代价模型,直接选择包含RangeScan的计划,在统计信息缺失时,基数估算无法正确的估算FullScan和RangeScan的行数,此变量可能有帮助。tidb_opt_range_max_size:当存在如index(a, b, c)和where a in (1, 2, ...) and b in (1, 2, ...) and c in (1, 2, ...)这样的条件时,优化器会把条件展开为(a, b, c) in (1, 1, 1), (1, 1, 2), ...,然后去访问索引,但是如果值较多,这个过程可能是 OOM,这个开关会限制这个过程最大的内存使用量。
Fix Control 变量
随着产品迭代演进,TiDB 优化器的行为会发生变化,进而生成更加合理的执行计划。但在某些特定场景下,新的行为可能会导致非预期结果。例如:
- 部分行为的效果和场景相关。有的行为改变,能在大多数场景下带来改进,但可能在极少数场景下导致回退。
- 有时,行为细节的变化和其导致的结果之间的关系十分复杂。即使是对某处行为细节的改进,也可能在整体上导致执行计划回退。
因此除了常规的 SQL 变量外,TiDB 还提供了 Optimizer Fix Controls 功能,允许用户通过设置一系列 Fix 控制 TiDB 优化器的行为细节。
如 fix-control:44262 可以控制在缺少全局统计信息的情况下,是否允许动态访问分区表。
所有的 fix-control 开关可以见文档:optimizer-fix-controls。
配合 Set Var 控制变量
大多数变量默认是全局生效的,直接调整变量值可能会造成一些非预期的影响,比如只想针对 SQL1 调整,但是修改变量值后影响了其他的 SQL2,此时可以使用 SET_VAR hint。
SET_VAR(VAR_NAME=VAR_VALUE) 允许在语句执行期间以 Hint 形式临时修改会话级系统变量的值。当语句执行完成后,系统变量将在当前会话中自动恢复为原始值。通过这个 Hint 可以修改一部分与优化器、执行器相关的系统变量行为,比如:
select /*+ set_var(tidb_opt_range_max_size=120000000) */ * from t
where a in (...) and b in (...) and c in (...)其他支持通过 SET_VAR(VAR_NAME=VAR_VALUE) Hint 修改的系统变量请查看系统变量。
Plan Cache 执行计划缓存
TiDB 支持 Plan Cache 功能,这个功能也会影响执行计划的生成。
优化器会缓存部分执行计划,如果新来的 SQL 可以服用缓存中的执行计划,优化器则会跳过执行计划生成,直接使用缓存中的执行计划。
通常我们建议使用 Prepare/Execute 的语法来使用 Plan Cache,比如:
mysql> create table t (a int, b int, key(a));
mysql> insert into t values (1, 1), (2, 2);
mysql> prepare st from "select * from t where a=?";
mysql> set @a=1;
mysql> execute st using @a;
+------+------+
| a | b |
+------+------+
| 1 | 1 |
+------+------+
mysql> set @a=2;
mysql> execute st using @a;
+------+------+
| a | b |
+------+------+
| 2 | 2 |
+------+------+
mysql> select @@last_plan_from_cache;
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 1 |
+------------------------+在上面的例子中,我们执行了两次 select * from t where a=?,第一次使用参数 1,第二次使用参数 2,则第二次会复用第一次的执行计划,可以使用 @@last_plan_from_cache 来确认。
TiDB 也支持对部分 SQL 的 Non-Prepared Plan Cache,即不使用 Prepare/Execute 语法也可以被缓存:
mysql> set @@tidb_enable_non_prepared_plan_cache=1;
mysql> select * from t where a=1;
+------+------+
| a | b |
+------+------+
| 1 | 1 |
+------+------+
mysql> select * from t where a=2;
+------+------+
| a | b |
+------+------+
| 2 | 2 |
+------+------+
1 row in set (0.01 sec)
mysql> select @@last_plan_from_cache;
+------------------------+
| @@last_plan_from_cache |
+------------------------+
| 1 |
+------------------------+但是相较于直接使用 Prepare/Execute,Non-Prepared Plan Cache 会有更多的限制,且性能会落后一点。
对于 TP 场景,大多数 TP 查询都只有 1 个最优计划,因此优化一次,多次复用相同的执行计划,既可以减少优化器犯错的概率,提升执行计划稳定性,也可以节省 CPU 开销,带来更高的性能,通常使用 Prepare/Execute + Plan Cache 后会有至少 20% 左右的性能提升。
总结
正确的执行计划是保证 SQL 执行性能的前提条件,但是受限于各种原因,优化器无法保证每次都能选中正确的执行计划,因此认为的对执行计划进行干预是降低风险的重要措施。
我们建议尽量使用 Prepare/Execute 来执行 SQL,以使用上 Plan Cache,提升执行计划稳定性的同时,也获得一定的性能提升;当执行计划出现问题时,使用执行计划绑定来进行修复,相比于直接使用 Hint,绑定可以减少对应用代码的侵入,且有 TiDB Dashboard UI 支持,易用性更高。
TiDB优化器新特性预告
Instance Plan Cache
目前 TiDB Plan Cache 为会话级别,即每一个连接会话都会维护自己的 Plan Cache,这会导致多个会话缓存相同的执行计划,造成内存的浪费。
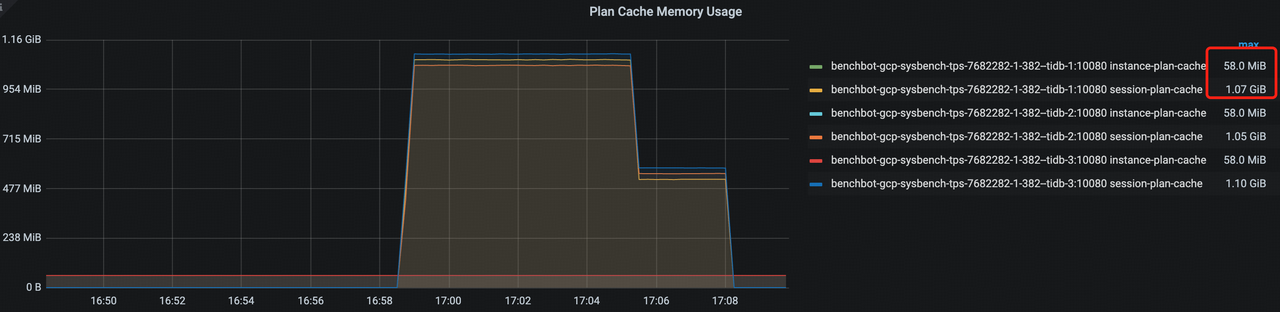
在后续版本我们会支持实例级别的 Instance Plan Cache,相比之下可以大幅减少内存使用,缓存更多的计划,提升 Plan Cache 命中率。
比如在 sysbench、并发 120 的某测试场景中,Instance Plan Cache 可以在无性能损耗的情况下,把内存使用从 1GB 减少到 60MB。
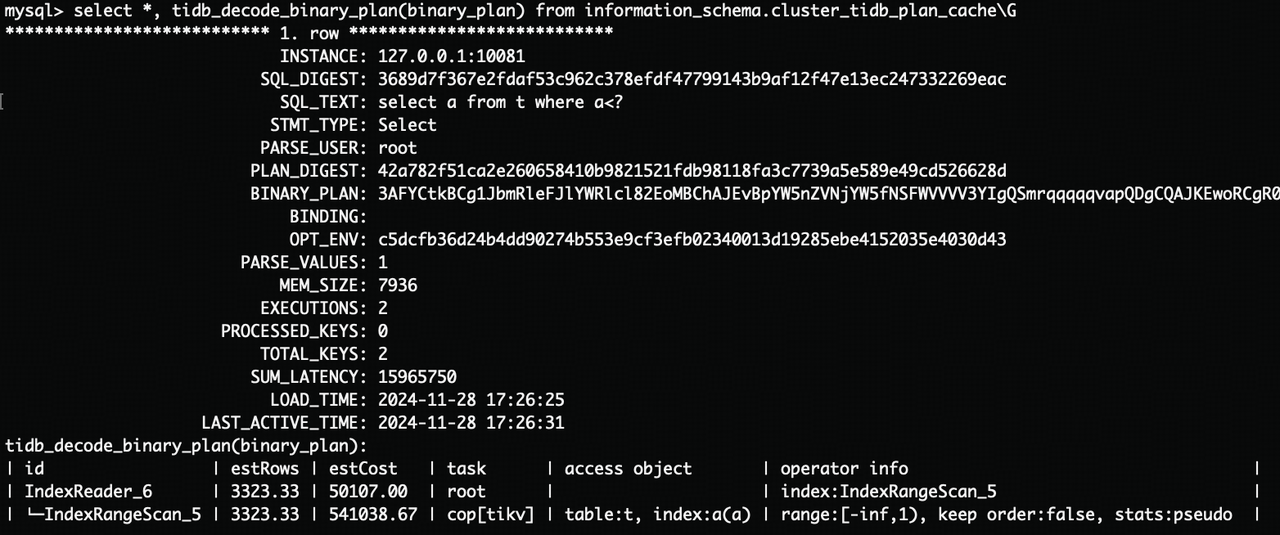
另外 Instance Plan Cache 还提供了系统视图,方便用户直接看到整个集群缓存的具体计划,提升一些诊断性:
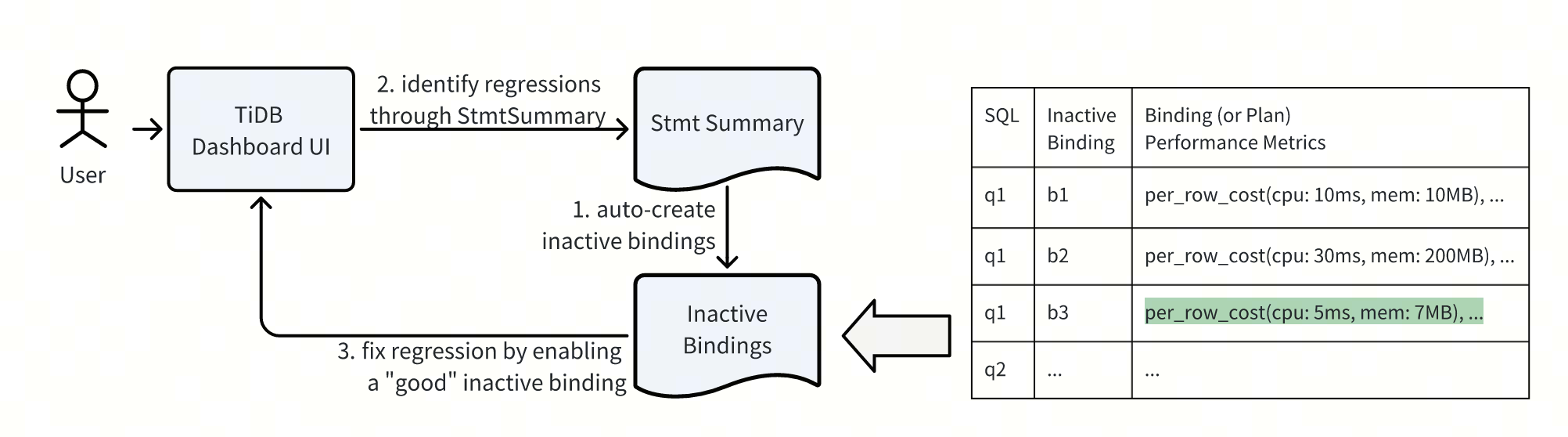
Inactive Binding
我们会将 TP 查询的历史计划,以 Inactive Binding 和 Perf-Metrics 的方式记录下来,当后续这些查询出现性能回退时,我们可以从这些历史计划中,选择一个好的来锁定此查询的执行计划。
Perf-Metrics 记录了对应计划的执行信息,如返回一行数据对应的资源消耗、扫描的数据量等,这些执行信息可以帮助判断此查询计划的性能是否优秀,比如扫描数据量过多则可能选错了索引。
然后基于 Statement Summary 的信息,自动的定位可能出现回归的查询,比如观察查询过去几天是否出现了执行计划变动,执行时间是否明显变长等。
最后配合 TiDB Dashboard UI 的支持,可以通过鼠标完成一整套的执行计划回退的定位和修复操作:定位计划回退、查看历史计划、选择执行计划、锁定执行计划、解决回退问题。
目录