
作者:某物联网公司设施云平台负责人
用户简介:我们是一家提供全链智慧园区整体解决方案的物联网公司,致力于打造可持续发展的智慧园区。
导读
本文由某物联网公司设施云平台负责人编写,介绍了其公司基础设施平台的设计与挑战。面对 MySQL 主从架构在高峰期性能不足的问题,文章详述了引入 TiDB 的原因和实施过程。基于 TiDB 的 HTAP 能力,用户通过巧妙的设计与运用,实现了 OLTP 与 OLAP 负载的彻底隔离,成功解决了数据库性能瓶颈,提升了应用核心功能、BI 报表性能以及 ETL 作业的效率。文章最后总结了 TiDB 上线以来的运行状况,展望了未来在更多业务场景中的应用。
基础设施平台简介
基础设施平台是集团一线作业人员日常工作中高度依赖的重要系统,涵盖了各类基础设施的管理、报修、保养等一系列数字化办公功能,同时实现了对基础设施、作业人员、项目成本等多种维度的精细化管理。其使命在于不断提升一线作业效率,提高业主的服务满意度。
以下为该平台手机端应用截图。工作中心页面提供了大量常用的业务功能,同时还包含了面对一线、项目、集团等多个维度的报表功能,是一个典型的 HTAP 混合负载场景。
手机端应用截图
面临的挑战
随着数据规模达到亿级别、业务规模不断扩大以及数字化需求的增加,该平台面临的挑战变得愈发严峻。在日常的业务高峰期,特别是在一些关键业务期间,如每周初、月初和月末,一线作业人员和集团运营业务部门的工作都可能受到一些影响。这主要是由于底层数据库在资源、架构和性能方面存在一些不足。
应用架构
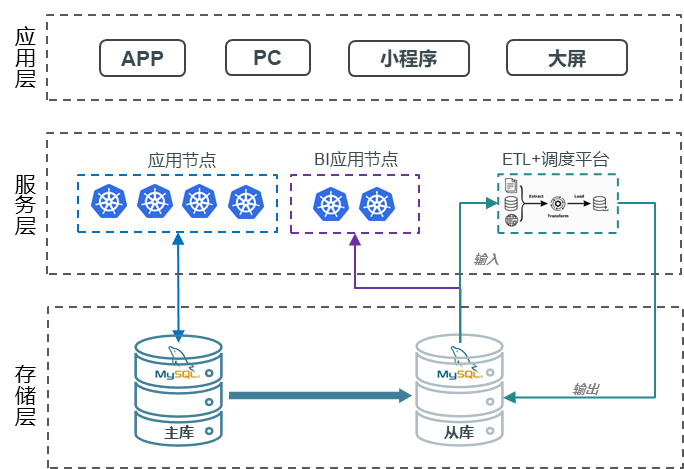
原先采用 MySQL 数据库的主从架构来为平台提供服务(16VC/64GB),其中包括:
- 主库存储业务数据(450GB),用于支撑应用中的绝大部分的业务功能,峰值 QPS 2500+;
- 从库除了业务数据外,还有 ETL 转化之后的汇总数据(200GB),峰值 QPS 1000+,支撑:
- 应用中的 BI 报表功能,集团的大屏实时展示;
- ETL 数据计算,在业务数据基础上进行加工,并写入到汇总库中;
- 当主库不可用时,支撑应用的高可用。
MySQL 不堪重负
- 在业务高峰期,主库的 CPU 使用率达到 90%,应用响应非常慢;
- 在业务高峰期,从库的 CPU 使用率也达到 90%,个别 BI 报表无法打开;
- 凌晨在从库上运行的 ETL 作业耗时非常久,有时到需要运行到第二天工作时间,严重影响 BI 报表服务。
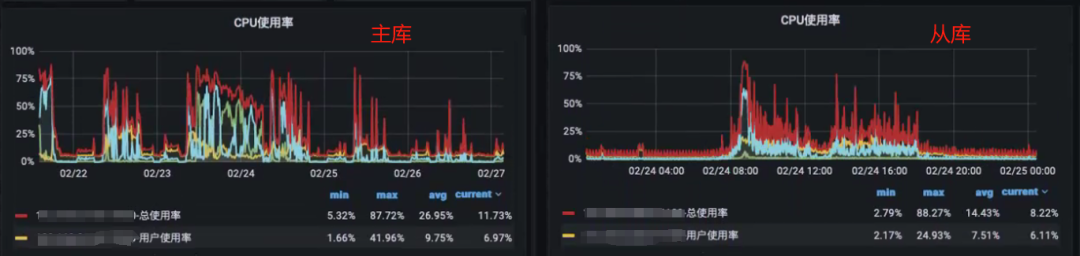
以上为两个实例的 CPU 使用率
为何引入 TiDB
在引入 TiDB 前,我们研讨了基于 MySQL 当前架构的扩容方案,将实例规格从 16VC/64G 扩展到 32VC/128G,甚至再加一个从节点,然后在应用层进行读写分离设计。
该扩容方案可以解决在并发时资源不足的问题,从而在一定程度上缓解高峰期服务响应慢的情况。然而,它并不能解决 SQL 本身执行速度较慢的问题。例如,在从库执行凌晨的 ETL 作业期间,虽然负载并不高,但是 ETL 运行时间很长。方案上还是存在一定的不足:
- 核心工单表 5 亿多行,扩容后,该表的查询和写入 SQL 性能仍然没有提升;
- BI 报表查询以及 ETL 转化作业时,涉及大量复杂的 Join/聚合计算,涵盖了多张大表,即使扩容了也还是慢;
- 花费成本高,同时改善空间有限:
- 3 倍的资源成本,从 32VC/128GB 变成 96VC/384GB;
- 改造成本,需要对应用代码进行读写分离的改造,随着未来该系统接入更多项目时,可能还需要投入更多精力进行分库分表的改造工作。
最终我们计划选择原生分布式数据库来解决该系统面临的问题,其中 TiDB 分布式数据库这些能力非常吸引我们:
- 原生分布式架构,能够彻底解决大数据量下读写性能问题;
- HTAP 混合负载,BI 或者 ETL 中包含大量复杂“Join/聚合”的 SQL,性能可以大幅提升;
- MySQL 兼容,使得应用架构和代码几乎不用调整便能完成应用的移植。
以下为 TiDB 的集群配置(合计约 76VC)
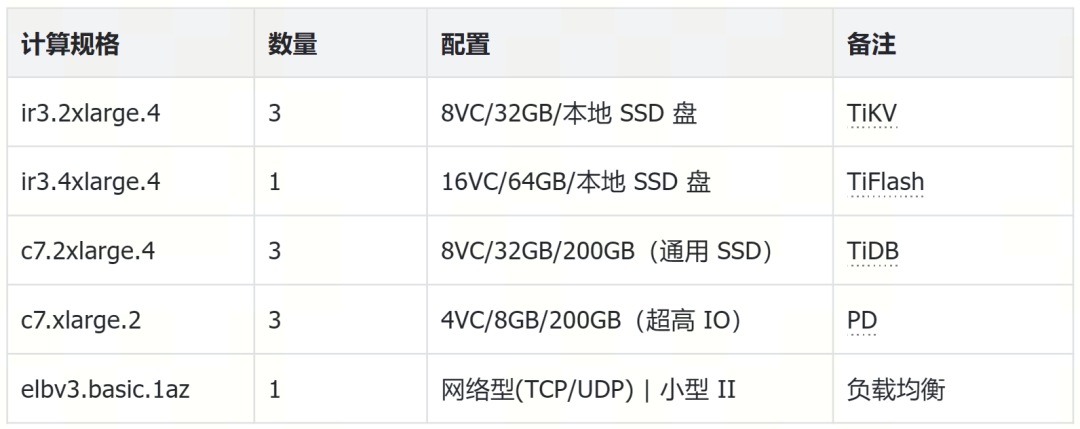
OLTP 与 OLAP 负载彻底隔离的 HTAP 架构设计
应用架构无需改动
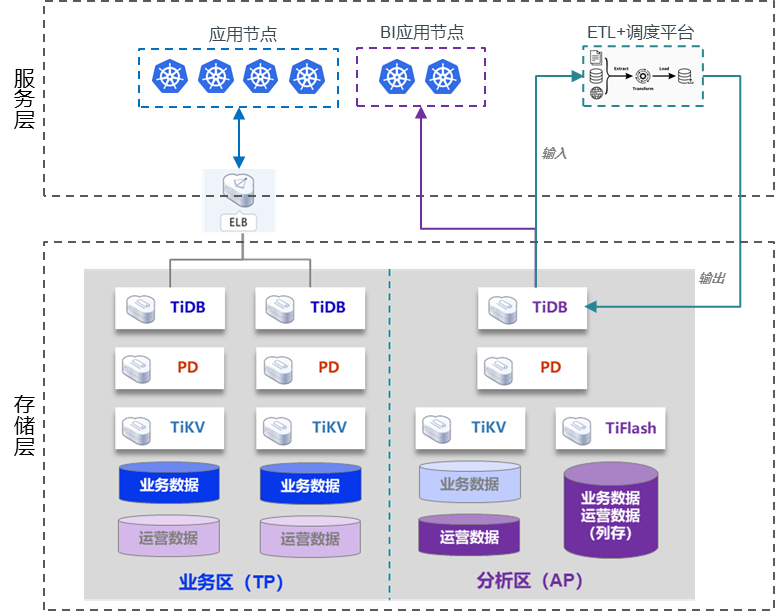
为了实现最小成本的系统移植,我们在一套 TiDB 中同时支撑 OLTP(应用基础功能)、OLAP(BI 报表、ETL 作业)两种负载,同时确保两种负载之间互不影响,并且提供了最大的可用性保障。以下是我们针对 TiDB HTAP 架构进行的一些设计。
存储节点规划
我们将 TiKV1 和 TiKV2 规划为 OLTP 区,将 TiKV3 和 TiFlash 规划为 OLAP 区
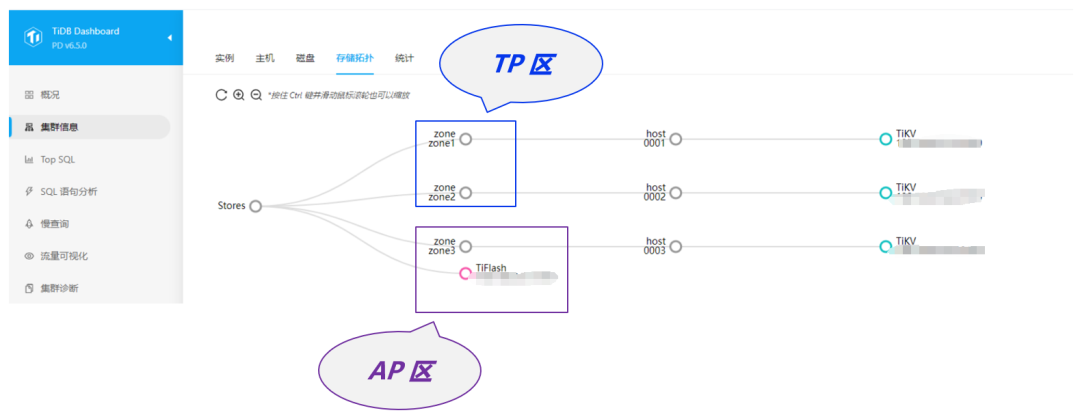
数据 Leader 隔离
默认情况下 TiDB 中数据 Leader 的分布是随机的,而 SQL 请求默认都是发往 Leader 执行,所以默认机制下无法满足我们的隔离要求。所以我们进行了如下设计:
1.将 OLTP 所用到的业务数据的 leader 固定在 TiKV1/TiKV2 上
策略一: policy_eyas(业务库策略)
预期效果:数据的 Leader 在 zone1 和 zone2 上,zone3 上不会产生 Leader(只有 Follower)
-- 创建策略
create placement policy policy_eyas leader_constraints = "[-zone=zone3]";
-- 为业务库指定策略,让业务读写都发生在 TiKV 节点 1,2
alter database eyas placement policy policy_eyas;2.将 OLAP 中 ETL 作业产生的汇总数据的 leader 固定在 TiKV3 上
策略二:policy_bi(汇总库策略)
预期效果:数据的 Leader 只在 zone3 上,zone1 和 zone2 上只有 Follower (没有 Leader)
-- 创建策略
create placement policy policy_bi leader_constraints="[+zone=zone3]" follower_constraints ='{"+zone=zone1": 1,"+zone=zone2": 1}';
-- 为汇总库指定策略,让汇总库上的读写都发生在 TiKV 节点 3
alter database bi_eyas placement policy policy_bi;
alter database da_ping placement policy policy_bi;3.为所有数据设置一份 TiFlash 副本
alter database eyas set tiflash replica 1;
alter database bi_eyas set tiflash replica 1;
alter database da_ping set tiflash replica 1;目的:加速 BI 报表和 ETL 中复杂查询 SQL 的性能
计算隔离
我们同样也针对计算节点进行了隔离,TiDB1 和 TiDB2 两个计算节点接入负载均衡供应用节点使用,并且限制其只能访问 TiKV 上的数据(原因:应用基础功能无须使用 TiFlash)。
config:
isolation-read.engines:
- tikv
- tidb对于 BI 应用和 ETL 平台,我们则是让其直连 TiDB3 计算节点。由于它们都存在大量复杂“Join/聚合”的 SQL,我们希望这样的 SQL 可以通过优化器自动决定去 TiKV 或 TiFlash 引擎执行,以获得最大的性能,参数如下:
config:
isolation-read.engines:
- tikv
- tiflash
- tidb
labels.zone: zone3注意:在 TiDB 数据库中,默认所有的读请求都是发往数据的 Leader,而在 ETL 作业中的输入基本都是查询业务库(非常复杂的 Join/聚合)、BI 报表中也有相当一部分会实时查询业务库(而业务库的数据 Leader 在 TiKV1/TiKV2 上),这样的 SQL 一旦出现将发往 TiKV1/TiKV2 上执行,此时会影响到应用核心功能。
为了避免这一问题,我们为 TiDB3 设置了一个 Label: zone3(与 TiKV3 的 Label 一致),此时便可以实现就近副本的读取(TiDB3 上即使有非常复杂的业务库的查询,也只会在 TiKV3 的 Follower 副本上或 TiFlash 上执行):
set global tidb_replica_read = 'closest-replicas’;使用效果:性能大幅提升
应用部分(页面端到端耗时)
- 应用核心功能基本优化到 1 秒内,大幅提升了一线的使用体验和作业效率;
- BI 报表性能大幅提升,之前打不开的报表均能快速展示,提升运营管理效率。
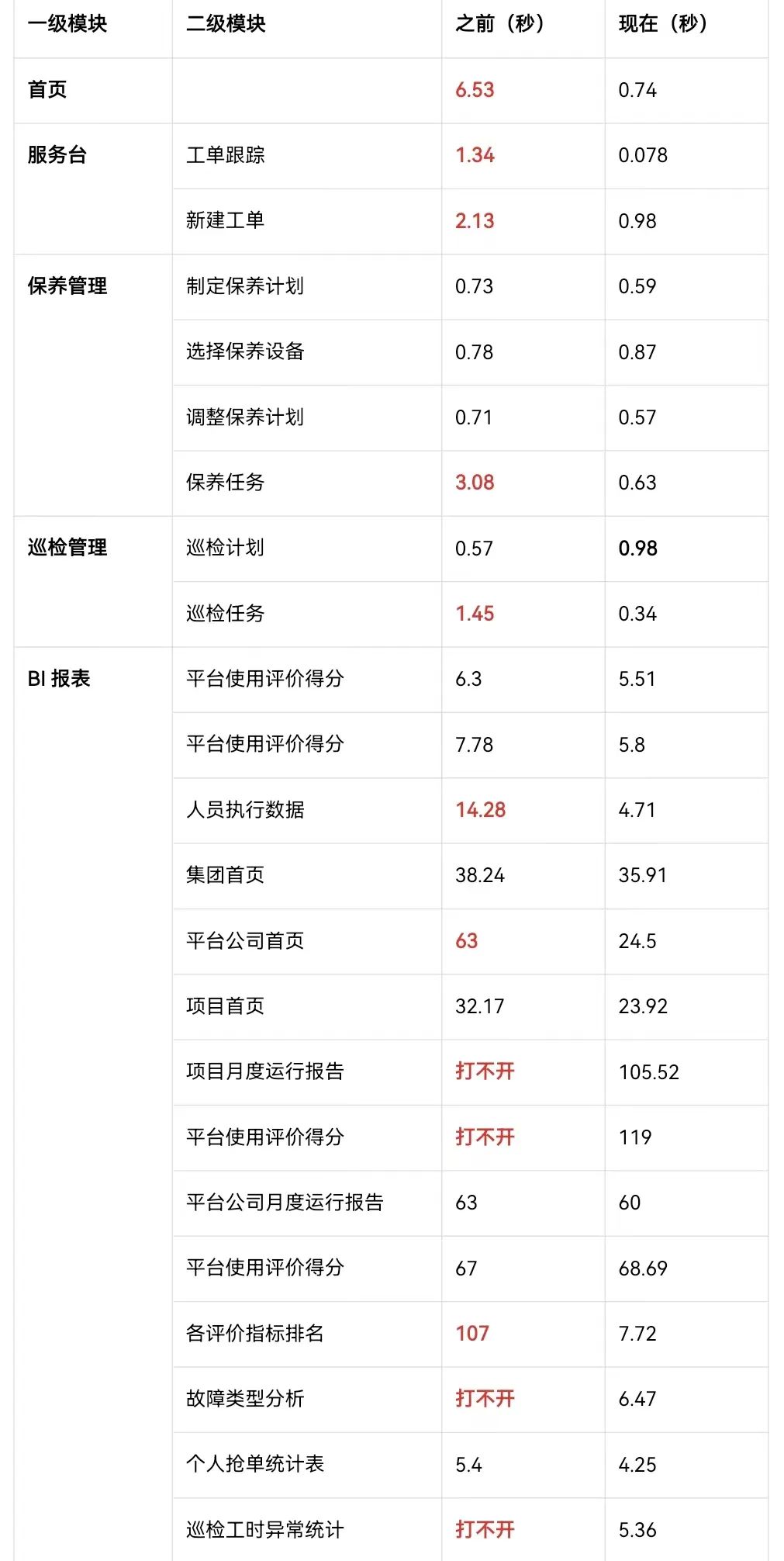
注:一张报表包含若干条 SQL,最大的报表包含 200 多条 SQL(串行执行、页面逐一渲染展示)
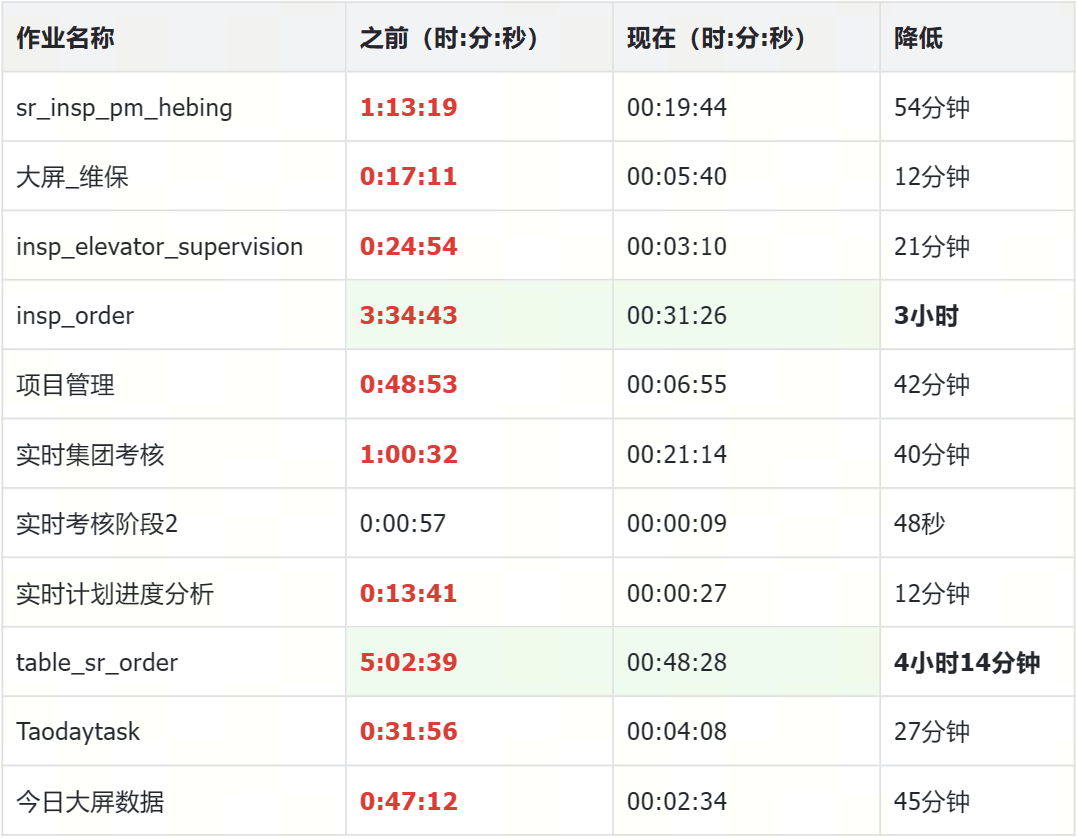
ETL 作业
ETL 作业性能大幅提升,之前最久的作业执行超过 5 小时,现在的执行时间仅为 48 分钟,性能提升了 80% 以上。
遇到的问题和解决办法
虽然 TiDB 高度兼容 MySQL,几乎不需要改造,但在测试过程中发现了以下两处问题。
SQL 不兼容
5 条 SQL 报错:ON condition doesn't support subqueries yet,原因为 TiDB 在 join 中不支持 on 判断使用子查询,如:
1. select t1.* from sbtest1 t1 join sbtest2 t2 on t1.id=t2.id and t2.id in (select id from sbtest3)
2. select t1.* from sbtest1 t1 join sbtest2 t2 on t1.id=t2.id and exists (select 1 from sbtest3 t3 where t3.id=t1.id)解决办法:改写成 join 表的形式
特定写法下 SQL 性能退化
像查询列中包含 case when in subquery 这样的写法时,执行时与这个 subquery join 的时候变成了笛卡尔积,性能退化十倍以上。
解决办法:上线版本为 TiDB 6.5.0,当时通过将 case when in subquery 改写成 exists 后解决,目前该问题已经在高版本中已经修复。
总结
TiDB 自今年 3 月上线以来,性能提升非常明显。目前已经平稳运行了超过半年时间,这充分增强了我们深度使用 TiDB 的信心。未来,我们计划利用 TiDB HTAP 架构来支撑更多业务场景的需求,持续创造价值。
目录