
系列导读
徐戟(白鳝):Oracle 数据库优化专家,前 Oracle ACE,PostgreSQL ACE Director
当前,国内大量的关键行业的核心系统正在实现国产化替代,而与此同时,这些行业的数字化转型也正在进入深水区。在信息系统的升级换代过程中,夯实 IT 基础设施是极其关键的。从服务器、操作系统、中间件、数据库等基础软硬件选型到系统架构、应用架构的重新设计,再到数据迁移、系统迁移、系统优化、运维体系重构的一系列工作都是十分具有挑战性的。大多数工作中,都会遇到无法完全参考前人的探索和创新。
一些勇敢的先行者已经在这条荆棘丛生的道路上硬生生的创出了一条血路,而更多的人还在未知与迷茫中摸索。“银⾏核⼼背后的落地⼯程体系”系列技术文章来自于金融行业用户真实故事,从中可以窥见的不仅是国产化替代路上的艰辛历程,更多的是对于后来者极其宝贵的实践经验。
在本系列文章中你不仅可以看到 TiDB 与 Oracle 的异构迁移、基于 TiCDC 的逻辑容灾与数据共享、构建双活数据中心的真实案例,还可以了解到混沌测试、应急预案等方面,以及利用数据库可观测性构建智能化、自动化运维体系的方案与技巧。“积小流,成江海”,希望这些案例能够对您有所裨益。
【系列推荐】
TiDB DR-Auto-Sync 是 TiDB 分布式数据库同城双中心高可用方案,在银行核心业务场景中得到了充分的实践验证。与常见的 TiDB 三中心部署方案类似,DR-Auto-Sync 同样能满足机房级 RPO=0 的高可用能力,两中心间的数据复制也是通过集群自身的 Raft 机制完成。两中心可同时对外进行读写服务,任一中心发生故障不影响数据一致性。
DR-Auto-Sync 简介
DR-Auto-Sync 适用于同一城市两个数据中心(同城双中心)的场景,建议两数据中心相聚 50 km 以内,网络时延小于 1.5 ms,两中心间网络带宽大于 10 Gbps。DR-Auto-Sync 架构定义三种状态来标识集群的数据同步情况。集群的复制模式可以自动在三种状态之间自适应切换。
- sync:同步复制模式,此时副中心至少有一个副本与主中心保持同步,Raft 算法保证每条日志按 Label 标签同步复制到副中心。
- async:异步复制模式,此时不保证副中心与主中心完全同步,Raft 算法使用经典的 majority 方式复制日志。
- sync-recover:恢复同步模式,此时不保证副中心与主中心完全同步,各 region raft 逐步切换成同步复制模式(主/副中心均有最新 raft log 落地),切换成功后汇报给 PD。
DR-Auto-Sync 架构依赖 Placement Rules 定义 TiKV 实例,涉及三种角色。
- Voter:TiKV 实例相关 region peer 参与 raft 选主投票,并可以被推举为 Leader。
- Follower:TiKV 实例相关 region peer 参与 raft 选主投票,但不可以被推举为 Leader。
- Learner:TiKV 实例相关 region peer 只从 Leader 实时同步 raft log,不参与 raft 选主投票,也不可以被推举为 Leader。
TiDB 集群支持在线调整 Placement Rules 规则,重新定义 TiKV 实例角色。
部署架构
下图为典型的双中心 5+1 副本 DR-Auto-Sync 集群部署架构图,具体如下:
- 集群采用推荐的 6 副本模式,其中主中心 (DC1) 3 副本 TiKV 均为 Voter,副中心 (DC2) 2 副本 TiKV 为 Follower,1 副本 TiKV 为 Learner。
- PD 采用 5 实例部署,PD Leader 位于主中心 (DC1),并且实例优先级高于副中心 (DC2) 实例。
- TiDB 计算双活,应用通过负载均衡访问同中心的 TiDB 实例。
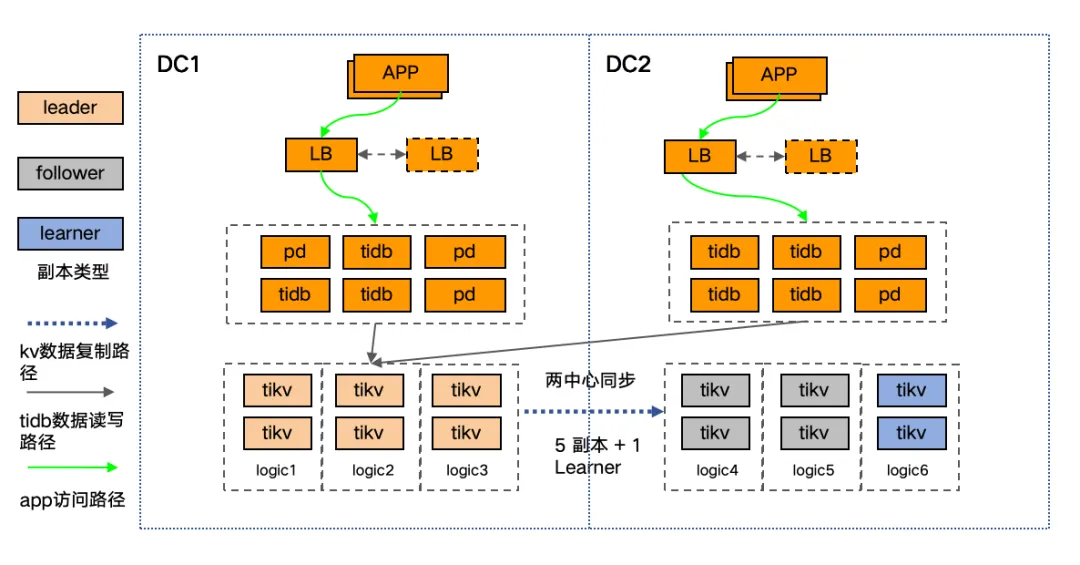
集群配置
集群拓扑文件
以下是双中心部署 6 副本集群的配置文件信息,和普通集群相比,有以下几个参数设置需要注意:
- 调整 TiKV 心跳上报频率,pd-store-heartbeat-tick-interval,与 Dr-Auto-Sync 相关的 wait-store-timeout 同频可能导致 sync/async 切换无故自动切换问题。
- 调整 snapshot 相关参数,规避 sync_recover 阶段 snapshot 传输导致的 QPS 下降问题。
- 为 TiKV 实例配置 dc (数据中心) 以及 logic (逻辑单元,部署时与机柜对应) 标签 (注意:相同 logic 标签的 TiKV 实例承载一份完整的数据副本)。
server_configs:
tidb:
proxy-protocol.networks: 192.168.1.70 #IP透传能力,硬件负载配置需要对应调整
tikv:
raftstore.pd-store-heartbeat-tick-interval: 2s
raftstore.snap-generator-pool-size: 1 #调整这个和下面的参数降低 sync_recovery 时候的 snapshot 传输速度,以避免该阶段 QPS 下跌的太严重
server.snap-max-write-bytes-per-sec: 30MB
server.concurrent-send-snap-limit: 4
server.concurrent-recv-snap-limit: 4
pd:
replication.max-replicas: 5 ##副本数量
replication.location-labels: ["dc", "logic","host"]
replication.isolation-level: "logic"
tikv_servers:
- host: 192.168.1.1
config:
server.labels:
dc: dc1
host: "192_168_1_1"
logic: logic1
arch: arm64
os: linux
- host: 192.168.1.2
config:
server.labels:
dc: dc1
host: "192_168_1_2"
logic: logic2
- host: 192.168.1.3
config:
server.labels:
dc: dc1
host: "192_168_1_3"
logic: logic3
- host: 192.168.2.1
config:
server.labels:
dc: dc2
host: "192_168_2_1"
logic: logic4
- host: 192.168.2.2
config:
server.labels:
dc: dc2
host: "192_168_2_2"
logic: logic5
- host: 192.168.2.3
config:
server.labels:
dc: dc2
host: "192_168_2_3"
logic: logic6
pd_servers:
- host: 192.168.1.101
- host: 192.168.1.102
- host: 192.168.1.103
- host: 192.168.2.101
- host: 192.168.2.102
monitoring_servers:
- host: 192.168.1.101
grafana_servers:
- host: 192.168.1.101
alertmanager_servers:
- host: 192.168.1.101
- host: 192.168.4.101配置 Placement Rules
为集群配置 Placement Rules,规划集群副本的放置位置,标记各 Logic 副本角色。
#修改placement rule配置
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 config placement-rules rule-bundle save --in="/home/tidb/dr_auto_sync_dc1_rule.json"
#查看当前placement rule
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 config placement-rules show
#/home/tidb/dr_auto_sync_dc2_rule.json
[
{"rules": [
{"group_id": "pd","id": "dc1-logic1","role": "voter","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic1"]}]
},
{"group_id": "pd","id": "dc1-logic2","role": "voter","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic2"]}]
},
{"group_id": "pd","id": "dc1-logic3","role": "voter","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic3"]}]
},
{"group_id": "pd","id": "dc2-logic4","role": "follower","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic4"]}]
},
{"group_id": "pd","id": "dc2-logic5","role": "follower","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic5"]}]
},
{"group_id": "pd","id": "dc2-logic6","role": "learner","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic6"]}]
}
]}
]PD 中与 DR-Auto-Sync 有关的设置
DR-Auto-Sync 相关配置,涉及主中心和副中心的标签、副本数、集群同步降级阻塞时间等。
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 -i
#修改dr-auto-sync 模式
config set replication-mode dr-auto-sync
#配置dr-auto-sync 的机房标签
config set replication-mode dr-auto-sync label-key dc
#配置主中心
config set replication-mode dr-auto-sync primary dc1
#配置副中心
config set replication-mode dr-auto-sync dr dc2
#配置主中心副本数量
config set replication-mode dr-auto-sync primary-replicas 3
#配置副中心非learner副本数量
config set replication-mode dr-auto-sync dr-replicas 2
#当出现网络隔离或者故障时,降级为异步模式的等待时间
config set replication-mode dr-auto-sync wait-store-timeout "15s"通过以上三个部分的操作即可完成双中心 5+1 副本 DR-Auto-Sync 集群的所有配置。
DR-Auto-Sync 容灾切换
DR-Auto-Sync 集群支持计划内切换和计划外切换(故障抢修)两种模式的容灾切换操作。
- 计划内切换:有计划的主中心、副中心角色转换,常用于日常容灾演练、副中心业务验证、计划内机房硬件维护等场景,具备操作简单、业务无感知等优点。
- 计划外切换:应对主中心机房级故障导致的集群不可用,通过人工干预快速恢复集群并对外提供服务。操作相对复杂,在大部分场景下提供 RPO=0、RTO<1 min(从中心故障) 或 RTO<10 min(主中心故障)的容灾保障。
计划内切换和实战演练
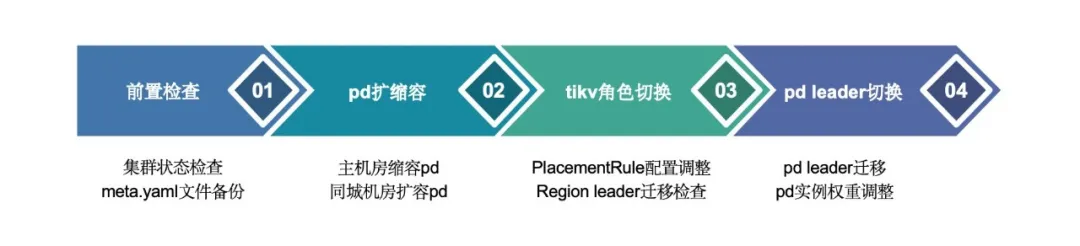
DR-Auto_Sync 计划内切换的目标是完成主副中心的转换,将 PD Leader,Region Leader 等资源迁移至副中心。主要涉及集群环境前置检查、PD 扩缩容、TiKV 角色转换、PD Leader 切换四个步骤。
前置检查
为确保计划内切顺利完成,需要在切换操作前进行如下操作:

PD 缩扩容
计划内切换前置步骤,通过 PD 缩扩容,实现 PD 实例迁移工作,确保 DC1/2 机房中心角色转换后,新的主中心(DC2) PD 实例数满足单中心多数派选举需求。(注意:选择 DC1 非 PD Leader 实例进行缩容,规避 PD Leader 切换带来的业务影响)
#获取pd实例信息
tiup cluster display tidb-test -R pd
#选择DC1机房非pd leader 实例进行缩容操作,规避pd leader 切换带来的业务影响
tiup cluster scale-in tidb-test -N 192.168.1.2:2379
#扩容DC2机房pd实例
pd_servers:
- host: 192.168.2.5
ssh_port: 22
name: pd-192.168.2.5-2379
client_port: 2379
peer_port: 2380
arch: arm64
os: linux
tiup cluster scale-out tidb-test pd-scale.yaml -uroot -pTiKV 角色转换
TiKV 角色转换涉及 Placement Rules 配置修改,DR-Auto-Sync 数据中心角色配置对换,主/副中心 Region Leader 数量统计等操作。
- 通过修改 Placement Rules 配置,完成主/副中心 TiKV 角色转换 (DC1:2 Follower + 1 Learner,DC2:3 Voter)。PD Leader 根据新的 Placement Rules 配置,重新调度 Region Leader。
- pd-ctl 调整 DR-Auto-Sync primary/dr dc 配置,完成数据中心角色配置对换。
- 循环统计各 TiKV Region Leader 数量,确保 DC1 Region Leader 数为 0。
######placement-rule配置修改#######
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 config placement-rules rule-bundle save --in="/home/tidb/dr_auto_sync_dc2_rule.json"
#/home/tidb/dr_auto_sync_dc2_rule.json
[
{"rules": [
{"group_id": "pd","id": "dc1-logic1","role": "follower","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic1"]}]
},
{"group_id": "pd","id": "dc1-logic2","role": "follower","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic2"]}]
},
{"group_id": "pd","id": "dc1-logic3","role": "learner","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic3"]}]
},
{"group_id": "pd","id": "dc2-logic4","role": "voter","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic4"]}]
},
{"group_id": "pd","id": "dc2-logic5","role": "voter","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic5"]}]
},
{"group_id": "pd","id": "dc2-logic6","role": "voter","count": 1,
"location_labels": ["dc", "logic", "host"],
"label_constraints": [{"key": "logic", "op": "in", "values": ["logic6"]}]
}
]}
]
#####集群主副中心角色转换####
#调整PRIMARY DC
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 config set replication-mode dr-auto-sync primary dc2
#调整DR DC
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 config set replication-mode dr-auto-sync dr dc1
#######循环统计region leader 方法
function drautosynccheck()
{
local cluster_name="$1"
local cluster_version="$2"
local pd_leader_addr="$3"
local new_primary_dc="$4"
local new_dr_dc="$5"
echo "开始监查副region leader信息"
second_dc_leader_list=0
check_status=0
for ((i=1; i<= 100 ; ++i)) do
tiup ctl:$cluster_version pd -u $pd_leader_addr store --jq='.stores[]|{dc:.store|.labels[],address:.store|.address,leader_count: .status|.leader_count}'|grep $new_dr_dc
second_dc_leader_list=`tiup ctl:$cluster_version pd -u $pd_leader_addr store --jq='.stores[]|{dc:.store|.labels[],address:.store|.address,leader_count: .status|.leader_count}'|grep $new_dr_dc|jq 'select(.leader_count!=0)'|wc -l`
if [ "$second_dc_leader_list" -gt "0" ];then
echo "副机房还有region leader"
sleep 15
else
echo -e "副机房无region leader"
check_status=1
break
fi
done
if [ "$check_status" -ne "1" ]; then
exit 1
fi;
}
drautosynccheck()PD Leader 切换
PD Leader 切换涉及 PD 实例优先级设置,PD Leader 迁移两个操作。
- 将副中心 (DC2) 3 个 PD 实例优先级提升为 100,主中心 (DC1) 2 个 PD 实例权重降低为 50。确保 PD Leader 与 Region Leader 一样位于副中心,从而减少数据读写访问的网络延迟,提升业务性能。
- 选择副中心 PD 实例,发起 PD Leader 迁移。(注意:PD Leader 切换期间少量业务查询因无法获取最新 ts 报错,持续大约 1s)
#设置pd实例优先级,确保pd leader始终处于主中心
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 -i
#DC2 pd实例
member leader_priority ${pd_name} 100
#DC1 pd实例
member leader_priority ${pd_name} 50
#触发pd leader切换
tiup ctl:v6.5.6 pd -u 192.168.1.1:2379 -i
#选择DC2 pd 实例
member leader transfer ${pd_name实战演练效果
以下是某生产集群计划内切换演练的效果,通过脚本封装整个切换过程持续约 6 分钟,业务影响约 1 秒:

- TiKV 角色转换:TiKV 角色转换期间,通过 Region Leader 数量检测脚本实时统计 TiKV Region Leader 数量,确保 DC1 主机房相关 Leader 迁移完成。
下图为 TiKV Region Leader 数量检测脚本输出:
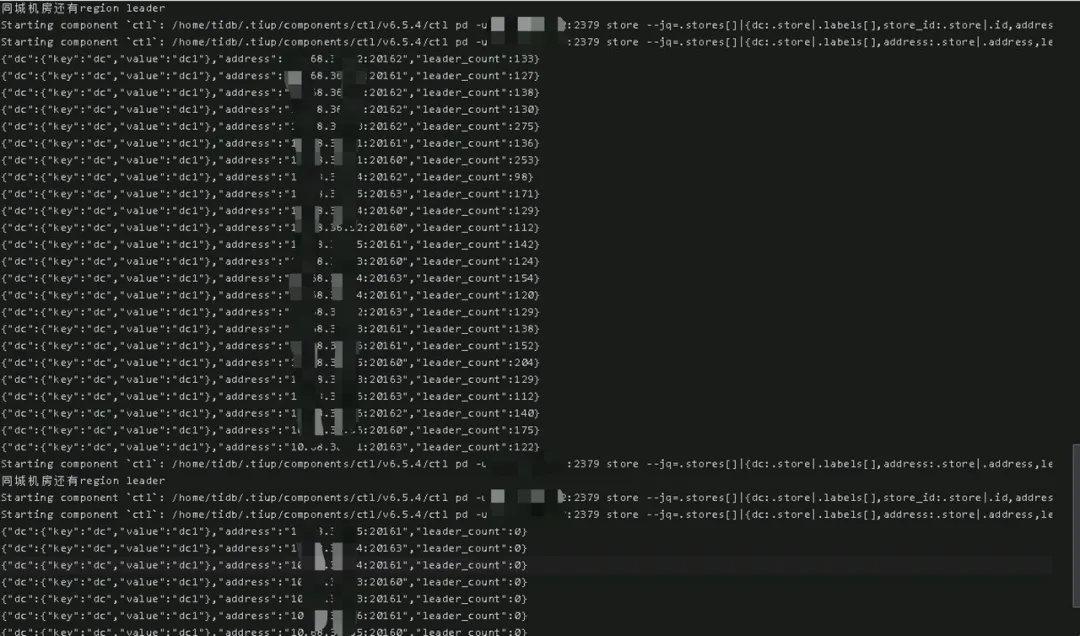
TiKV Region Leader 迁移监控图:
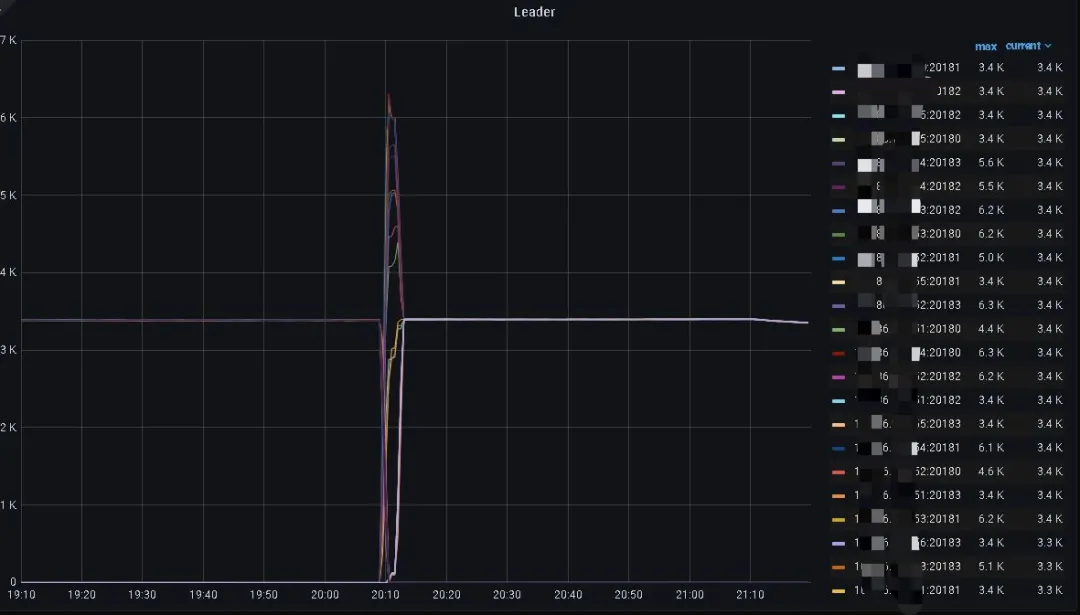
PD Leader 切换:如下图所示,PD Leader transfer 操作大约只需要 500 ms 即可完成 Leader 的角色转移,业务影响大约只有 1 s。

计划外切换和实战演练
DR-Auto-Sync 的计划外切换主要用于在主数据中心发生故障后迅速恢复,以确保集群能够继续对外提供服务。以下是不同复制模式下,计划外切换后集群的数据形态,目前支持 sync/async 模式下的计划外修复工作。
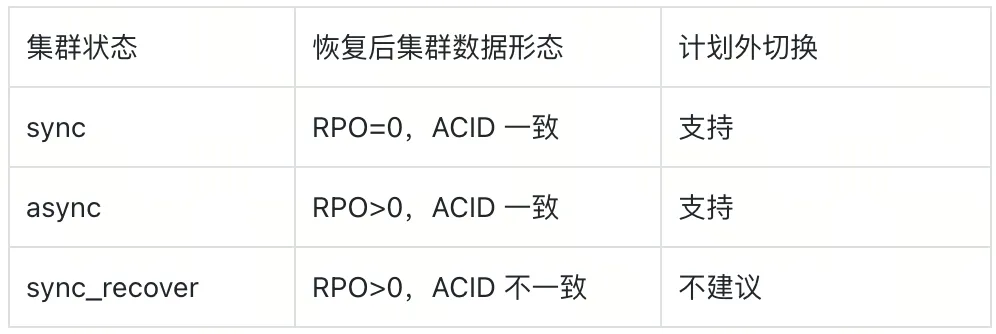
切换步骤主要涉及确认集群复制模式,检查相关工具,重建 meta.yaml 文件,计划外抢修(重构 PD、unsafe recovery)等工作。

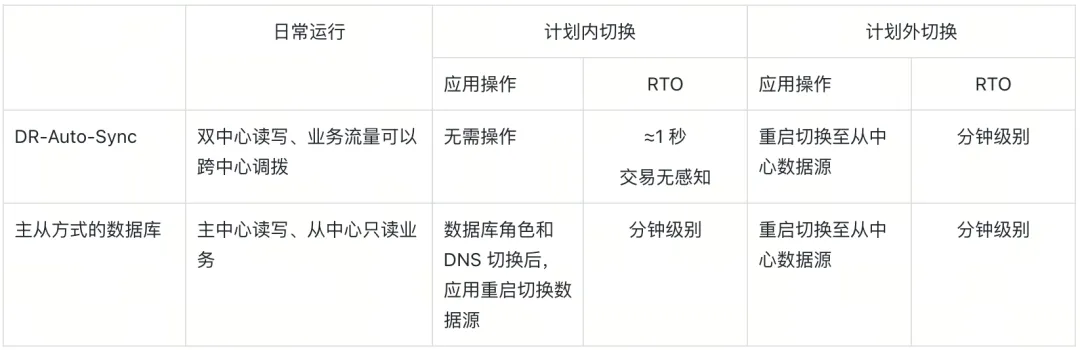
切换方式实战效果对比
与主从架构的数据库集群相比, DR-Auto-Sync 方案在灵活性上优势明显,业务调配的灵活度更高。日常运行时,上层应用流量的调拨几乎无影响,计划内切换时,上层应用交易无感知,符合金融级客户的容灾需求。
监控与告警
从 TiDB v6.5.6 开始,Grafana PD 面板上为 DR-Auto-Sync 添加了 status、sync progress 指标看板,可以直观反映集群的同步状态和进度。
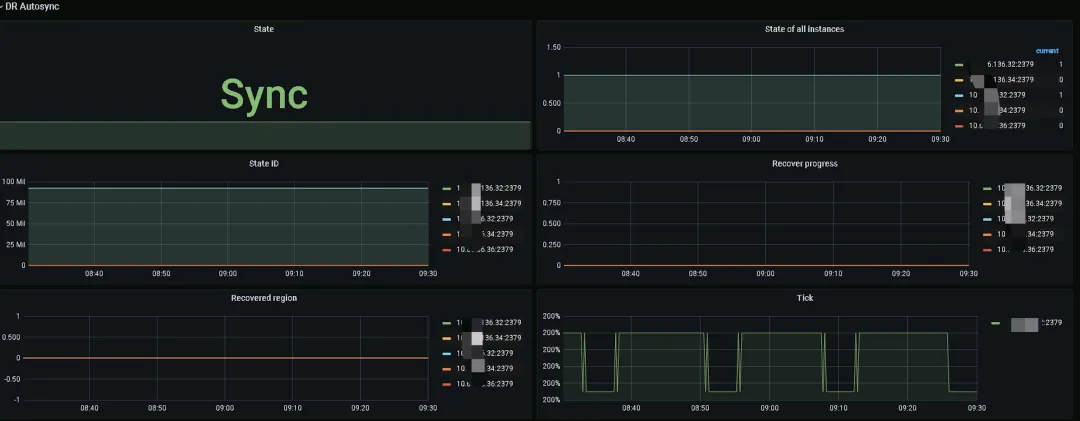
DR-Auto-Sync 日常运维主要关注主、副中心数据同步状态和 Region Leader 、PD Leader 分布情况,可以通过设置监控告警为运维人员及时提供信息。
1.集群状态监控
告警阈值:status 状态为 async/sync_recovery
#通过api实时获取集群同步状态
curl http://{pd_leader_ip}:{pd_port}/pd/api/v1/replication_mode/status2.Region Leader 分布状态监控
告警阈值:副中心 Region Leader >0 告警
leader_count=`tiup ctl:$cluster_version pd -u $pd_leader_addr store --jq='.stores[]|{dc:.store|.labels[],address:.store|.address,leader_count: .status|.leader_count}'|grep $dr_dc|jq 'select(.leader_count!=0)'|wc -l`
if [ "$leader_count" -gt "0" ];then
echo "触发告警"
else
echo "状态正常"
fi3.PD Leader 监控
告警阈值:无(用于计划外切换前辅助判定 pd leader 节点使用,日常无需告警)
状态 1 Leader,状态 0 Follower
#通过prometheus获取最新的pd leader 信息
curl http://{prometheus_url}/api/v1/query?query=pd_tso_role(dc="global",instance="{pd_id}:{pd_port}")注意事项
建议在 TiDB 6.5.6 及以后的版本中使用 DR-Auto-Sync,以下是在测试和实际生产使用过程中可能遇到的问题和解决办法。
1.pd-store-heartbeat-tick-interval 与 wait-store-timeout 设置
pd-store-heartbeat-tick-interval 与 wait-store-timeout 设置同频可能导致集群无故在 sync 和 async 模式之间进行切换。
#edit-config 修改
raftstore.pd-store-heartbeat-tick-interval: 2s
#pd-ctl修改
tiup ctl:v6.5.4 pd -u 192.168.1.1:2379 config set replication-mode dr-auto-sync wait-store-timeout 15s2.snapshot copy 对集群的影响
如果集群长期处于 async 模式,副中心故障修复后,可能产生大量的 region 副本 copy,占用主副中心间网络以及主机 IO 带宽,影响正常业务读写性能,建议对如下参数做出调整(注意:限制这些参数有一定的负面影响,可能导致 BR restore 失败,需要在 restore 之前解除相关限制)。
#调整这下面的参数降低 sync_recovery 时候的 snapshot 传输速度,以避免该阶段 QPS 下跌的太严重
raftstore.snap-generator-pool-size: 1
server.snap-max-write-bytes-per-sec: 30MB
server.concurrent-send-snap-limit: 4
server.concurrent-recv-snap-limit: 4
raftstore.store-io-pool-size: 2
raftstore.apply-pool-size: 43.集群升级或 PD 打 patch 之前临时将 PD 优先级设置成一致
在打 patch 或滚动升级的时候,一定要把所有 PD 的优先级设置为同样的大小,如果保持不同的优先级配置,有概率会遇到 TiUP patch 或 upgrade 的失败( TiUP 切走的 PD 可能可能因为优先级高,又主动回切)。
方案总结
基于 DR-Auto-Sync 方案,TiDB 在业界率先实现了银行核心系统双中心部署下保证 RPO=0 的情况下的数据库双活双写架构。支持应用双写条件下的交易流量分拨、中心角色计划内切换等场景具有很强的实践意义,为金融机构的业务连续性提供了强有力的保障。包括 DR-Auto-Sync 方案在内,TiDB 还提供同城三中心、两地三中心等多种金融级容灾方案,应对不同场景下的容灾高可用需求。后续,我们将推出更多的灾备实践和案例分享。
延展阅读:
- 金融行业内容专区上线,为金融机构数据库选型和应用提供深入洞察和可靠参考路径。立即浏览
目录