
导读
引用一首打油诗开始本篇文章:手持两把锟斤拷,口中疾呼烫烫烫。脚踏千朵屯屯屯,笑看万物锘锘锘。
计算机相关行业的人士或多或少对这些词语都有一定印象,出现这些字样本质上的原因是因为计算机实际上存储的都是二进制的内容,我们能看见的字符都是经过一定的规则进行转换得到的,如果在存储和转换的过程中,没有按照一定的规则去解析,就会出现前面的乱码问题。
在数据库系统中,也需要这样的规则,就是数据库字符集,它主要用于定义如何将字符数据转换为数据库可以存储的格式,决定了数据库能够存储哪些字符以及这些字符的编码方式,常用的字符集有:UTF-8、UTF-16、ISO-8859-1、ASCII、GBK,其中 UTF-8 作为 Unicode 字符集的一种编码形式能够覆盖几乎所有字符,这使它在处理西方语言和多字节字符(如中文、日文等)时都非常灵活和高效。字符集不仅关系到数据的存储方式,还会影响到数据的排序和比较。例如,采用不同字符集的数据库在排序同一组字符串时可能会得到不同的结果。因此,恰当地选择字符集对于确保数据库的性能、兼容性和数据的准确性非常关键。
在使用数据库的时候,我们也会碰见很多关于字符集的问题,希望本文可以给各位读者一些参考:
- 库,表,列各是什么字符集。客户端配置什么字符集;
- 为什么有时候 'A' 等于 'a',有时候又不等于;
- 做异构数据库迁移的时候,为什么原先读取正常,在新的数据库里,全是乱码;
- 多表关联查询的时候,为什么关联字段都有索引,依然是全表扫描,没有利用索引。
常见字符集类型
- ASCII:American Standard Code for Information Interchange,是一种最早的字符编码方案,仅使用 7 个 bit 来表示 128 个字符。它只能表示基本的拉丁字母、数字和一些控制字符。ASCII 的优点非常简单,编码和解码速度极快,因此在某些特定应用中仍有使用价值;
- ISO-8859-1: 也就是 Latin-1,在 ASCII 编码基础上扩展而来,主要用于表示西欧语言的字符。优点是简单易用,编码和解码速度快,但它的局限性在于只能表示 256 个字符,无法满足多语言应用的需求。随着全球化的发展,ISO-8859-1 的使用率逐渐下降,UTF-8 成为了更为普遍的选择;
- GB2312: 信息交换用汉字编码字符集,是中国于 1980 年发布,主要用于计算机系统中的汉字处理。基本集共收录 6763 个汉字、682 个符号;
- GBK: 汉字编码字符集,使用了双字节编码方案,共收录了 21003 个汉字,主要用来扩展 GB2312 标准,2000 年后被 GB18030 国家强制标准替换;
- GB18030:信息技术中文编码字符集,共收录汉字 87887 个,它主要采用单字节、双字节、四字节对字符编码,它是向下兼容 GB2312 和 GBK 的,可覆盖中国绝大部分人名、地名用生僻字以及文献、科技等专业领域的用字,能够满足各类使用需求。
以上字符集可以看出大多数是针对某种特定语言或者一个地域的语言的编码,这些字符编码是有限的,并没有涵盖世界上所有语言的字符,所以当数据在计算机之间传递且使用不同的编码时,它增加了数据损坏或错误的风险。所以 ISO 组织就提出了一种新的编码叫 Unicode,Unicode 标准提供了一种一致的多语言纯文本编码方式,给混乱的多语言编码提供一个通用的标准。Unicode 的设计基于 ASCII 的简单性和一致性,但远远超出了 ASCII 有限的编码能力(只能编码拉丁字母)。Unicode 标准提供了编码世界上所有书面语言使用的所有字符的能力。为了保持字符编码的简单和高效,Unicode 标准为每个字符分配了一个唯一的数值和名称。Unicode 标准支持三种编码形式(UTF-8、UTF-16、UTF-32),它们使用共同的字符集。这些编码形式允许编码多达一百万字符,足以满足所有已知字符编码需求。
- UTF-8:UTF-8 在 HTML 及其类似协议中非常流行。UTF-8 是一种将所有 Unicode 字符转换为可变长度字节编码的方法。它的优点是,在表示 ASCII 字符时候只存储 1 个字节,并且转换为 UTF-8 的 Unicode 字符可以与大量现有软件一起使用,而无需进行广泛的软件重写;
- UTF-16:每个字符占用 2 字节(16 bits)。UTF-16 在许多需要平衡高效访问字符与经济使用存储空间的环境中很受欢迎。它相当紧凑,所有常用字符都适合于一个 16 位的单元,而所有其他字符都可以通过一对 16 位单元来访问;
- UTF-32:字符占用的字节数可变。UTF-32 在内存空间不是问题,但希望以固定宽度、单个代码单元访问字符的情况下很有用。在使用 UTF-32 时,每个 Unicode 字符都被编码到一个单独的 32 位单元中。
TiDB 中的排序规则还是遵循的 MySQL 的命名规则,
- 排序规则名称以对应的字符集名称开头,后面跟着一个或多个表示其他校对特性的后缀。例如,utf8mb4_0900_ai_ci 和 latin1_swedish_ci 分别是 utf8mb4 和 latin1 字符集的排序规则;
- 特定语言的排序包括地区代码或语言名称。例如,utf8mb4_tr_0900_ai_ci 和 utf8mb4_hu_0900_ai_ci 分别使用土耳其语和匈牙利语的规则对 utf8mb4 字符集的字符进行排序;
- 校对后缀表明校对是否区分大小写、是否区分重音或假名敏感(或某些组合),或是否为二进制。下表显示了用于指示这些特性的后缀:
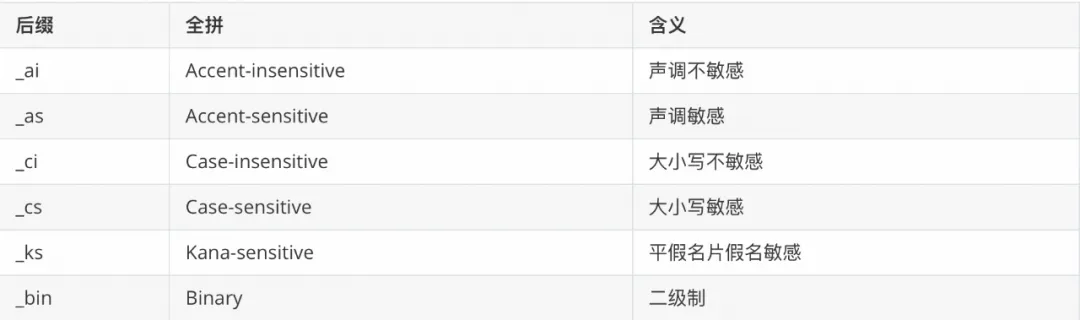
Unicode 字符集的排序规则名称包含一个版本号,用来标明所基于的 Unicode 排序算法(UCA)的版本。名称中没有版本号的基于 UCA 4.0.0 的版本。例如:
utf8mb4_0900_ai_ci基于 UCA 9.0.0 权重。utf8mb4_unicode_520_ci基于 UCA 5.2.0 权重。utf8mb4_unicode_ci基于 UCA 4.0.0 权重。
TiDB 中的字符集和排序规则
目前 TiDB 支持的字符集和排序规则:
mysql> show character set;
+---------+-------------------------------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+-------------------------------------+--------------------+--------+
| ascii | US ASCII | ascii_bin | 1 |
| binary | binary | binary | 1 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
| gbk | Chinese Internal Code Specification | gbk_chinese_ci | 2 |
| latin1 | Latin1 | latin1_bin | 1 |
| utf8 | UTF-8 Unicode | utf8_bin | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_bin | 4 |
+---------+-------------------------------------+--------------------+--------+
7 rows in set (0.00 sec)
mysql> show collation;
+--------------------+---------+------+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------+---------+------+---------+----------+---------+
| ascii_bin | ascii | 65 | Yes | Yes | 1 |
| binary | binary | 63 | Yes | Yes | 1 |
| gb18030_bin | gb18030 | 249 | | Yes | 1 |
| gb18030_chinese_ci | gb18030 | 248 | Yes | Yes | 2 |
| gbk_bin | gbk | 87 | | Yes | 1 |
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
| latin1_bin | latin1 | 47 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | Yes | Yes | 1 |
| utf8_general_ci | utf8 | 33 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 1 |
| utf8mb4_bin | utf8mb4 | 46 | Yes | Yes | 1 |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 |
+--------------------+---------+------+---------+----------+---------+
13 rows in set (0.00 sec)全局配置
- character_set_server:默认值是 utf8mb4,当 create database 中没有指定字符集时,该变量表示这些新建的表结构所使用的字符集;
- collation_server:默认值是 utf8mb4_bin,该变量表示创建数据库时默认的排序规则。
数据库
每个数据库或者 schema 都可以设置自己的字符集和排序规则,通过系统变量 character_set_database 和 collation_database 可以查看到当前数据库的字符集以及排序规则。
- character_set_database:默认值 utf8mb4,该变量表示当前默认使用的数据库的字符集,不建议设置该变量。选择新的默认数据库后(use db),服务器会更改该变量的值;
- collation_database:默认值 utf8mb4_bin,该变量表示当前数据库默认所使用的排序规则。与 MySQL 中的 collation_database 一致。不建议设置此变量,当前使用的数据库变动时,此变量会被 TiDB 修改。
示例:
MySQL [(none)]> create database db_character
-> default character set utf8mb4
-> default collate utf8mb4_0900_bin;
Query OK, 0 rows affected (0.132 sec)
MySQL [(none)]> create database db_character_general
-> default character set utf8mb4
-> default collate utf8mb4_general_ci;
Query OK, 0 rows affected (0.121 sec)
MySQL [(none)]> use db_character_general
Database changed
MySQL [db_character_general]> SELECT @@character_set_database, @@collation_database;
+--------------------------+----------------------+
| @@character_set_database | @@collation_database |
+--------------------------+----------------------+
| utf8mb4 | utf8mb4_general_ci |
+--------------------------+----------------------+
1 row in set (0.001 sec)
MySQL [db_character_general]> use db_character
Database changed
MySQL [db_character]> SELECT @@character_set_database, @@collation_database;
+--------------------------+----------------------+
| @@character_set_database | @@collation_database |
+--------------------------+----------------------+
| utf8mb4 | utf8mb4_0900_bin |
+--------------------------+----------------------+也可以通过 INFORMATION_SCHEMA 查看不同 schema 的值:
MySQL [db_character]> SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_character';
+----------------------------+------------------------+
| DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+----------------------------+------------------------+
| utf8mb4 | utf8mb4_0900_bin |
+----------------------------+------------------------+
1 row in set (0.001 sec)
MySQL [db_character]> SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_character_general';
+----------------------------+------------------------+
| DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+----------------------------+------------------------+
| utf8mb4 | utf8mb4_general_ci |
+----------------------------+------------------------+在 TiDB 中,如果创建数据库时仅指定字符集为 utf8mb4,但未设置排序规则时,将会使用 utf8mb4 默认的排序规则 utf8mb4_bin:
MySQL [(none)]> create database t1 default character set utf8mb4;
Query OK, 0 rows affected (0.125 sec)
MySQL [(none)]> use t1
Database changed
MySQL [t1]> SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
-> FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 't1';
+----------------------------+------------------------+
| DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+----------------------------+------------------------+
| utf8mb4 | utf8mb4_bin |
+----------------------------+------------------------+
1 row in set (0.001 sec)表和列
表和列的字符集和排序规则可以通过以下语句来设置:
-- 这里表和列字符集排序都不一致,只做示例,生产环境建议库,表,列字符集和排序规则都一直
create table character_t_c
(utf8_c varchar(10) character set utf8 collate utf8_general_ci)
CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;字符串
字符串的字符集和排序规则通过以下语句来设置:
MySQL [db_character]> SELECT 'string';
+--------+
| string |
+--------+
| string |
+--------+
1 row in set (0.001 sec)
MySQL [db_character]> SELECT _utf8mb4'string';
+--------+
| string |
+--------+
| string |
+--------+
1 row in set (0.000 sec)
MySQL [db_character]> SELECT _utf8mb4'string' COLLATE utf8mb4_general_ci;
+---------------------------------------------+
| _utf8mb4'string' COLLATE utf8mb4_general_ci |
+---------------------------------------------+
| string |
+---------------------------------------------+
1 row in set (0.001 sec)字符串的字符集和排序规则如下:
- 如果指定了 CHARACTER SET charset_name 和 COLLATE collation_name,则直接使用 charset_name 字符集和 collation_name 排序规则;
- 如果指定了 CHARACTER SET charset_name 且未指定 COLLATE collation_name,则使用 charset_name 字符集和 charset_name 对应的默认排序规则;
- 如果 CHARACTER SET charset_name 和 COLLATE collation_name 都未指定,则使用 character_set_connection 和 collation_connection 系统变量给出的字符集和排序规则。
会话
通过前面的内容,我们得到如下结论:
- character_set_server 和 collation_server 系统变量指定服务器的字符集和排序规则;
- character_set_database 和 collation_database 系统变量指定默认数据库的字符集和排序规则。
其他的的字符集和排序规则变量主要用来处理客户端与服务器之间连接的数据流量。每个客户端都有会话相关的字符集和排序规则变量。这些变量值可以在连接时初始化,也可以在会话中更改。
- character_set_client:代表客户端的字符集;
- character_set_results:默认值是 utf8mb4,在返回结果前,服务端会把结果根据 character_set_results 转换成对应的字符集,这里包括字段值,元信息,报错信息;
- character_set_connection:默认值是 utf8mb4,若没有为字符串常量指定字符集,该变量表示这些字符串常量所使用的字符集;
- collation_connection:默认值是 utf8mb4_bin,该变量表示连接中所使用的排序规则。与 MySQL 中的 collation_connection 一致。
这四个变量具体流程如下图,为了保证不出现字符集转换后的数据丢失,我们要保证 connection 部分的字符集是 client 部分的超集,另外 character_set_connection 和 collation_connection 两个参数会互相影响,设置其中一个会同步影响另外一个参数。
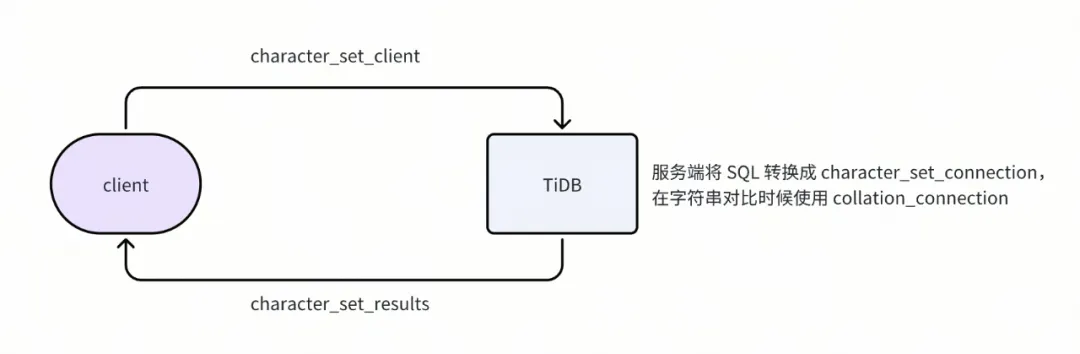
MySQL 客户端
使用 MySQL 客户端连接 TiDB 时候,这里需要注意的一点是 TiDB 和 MySQL 对于 utf8mb4 的默认排序规则的差异,
- MySQL 5.7 客户端 中 utf8mb4 默认排序是 utf8mb4_general_ci,而在 8.0 中默认是 utf8mb4_0900_ai_ci,在 TiDB 中默认是 utf8mb4_bin;
- 当 MySQL 8.0 客户端使用 --default-character-set=utf8mb4 连接 MySQL 5.7 服务端时候,它发送给服务端的是默认的 8.0 utf8mb4 排序规则,即 utf8mb4_0900_ai_ci。而 utf8mb4_0900_ai_ci 排序规则在 MySQL 8.0 之后才实现,所以在 MySQL 5.7 的版本里又会回退到 MySQL 服务端配置的默认字符集和排序规则;
- 当 MySQL 8.0 客户端使用 --default-character-set=utf8mb4 连接 TiDB 服务端时候,当版本在 7.4 之后,collation_connection 会是 utf8mb4_0900_ai_ci ,如果在 7.4 版本之前会是 utf8mb4_bin。
具体情况如下表,

从上表可以看出,为了可以兼容 MySQL 的行为,从 TiDB 7.4 版本以后(包括 7.4),排序的默认规则可以在变量 default_collation_for_utf8mb4 配置, 默认值是 utf8mb4_bin,可以配置的值有:utf8mb4_bin、utf8mb4_general_ci、utf8mb4_0900_ai_ci,它影响以下语句的行为:
- SHOW COLLATION 和 SHOW CHARACTER SET 语句显示的默认排序规则;
- CREATE TABLE 和 ALTER TABLE 语句中对表或列使用 CHARACTER SET 语法明确指定 utf8mb4 字符集而未指定排序规则时,将使用该变量指定的排序规则。不影响未使用 CHARACTER SET 语法时的行为;
- CREATE DATABASE 和 ALTER DATABASE 语句中使用 CHARACTER SET 语法明确指定 utf8mb4 字符集而未指定排序规则时,将使用该变量指定的排序规则。不影响未使用 CHARACTER SET 语法时的行为;
- 任何使用 _utf8mb4'string' 形式的字符串在未使用 COLLATE 语法指定排序规则时,将使用该变量指定的排序规则。
Java 连接
从 MySQL Connector/J session 可以看到字符集和排序规则的两个重要参数:characterEncoding 和 connectionCollation ,其中
- characterEncoding 设置了 character_set_client 和 character_set_connection,同时也设置了对应字符集的默认排序规则为 collation_connection(如果没配置 connectionCollation);
- connectionCollation 设置了 collation_connection,同时也设置了 character_set_client 和 character_set_connection 为排序规则对应的字符集(如果没配置 characterEncoding);
- 当 characterEncoding 和 connectionCollation 都没配置的时候 8.0.26 之前的驱动会配置服务端默认的字符集和排序规则,而在 8.0.26 之后的驱动版本中会设置为 utf8mb4,排序规则因版本变化,在 MySQL 5.7 之前默认是 utf8mb4_general_ci,MySQL 8.0 之后默认是 utf8mb4_0900_ai_ci, 在 TiDB 7.4 之前默认是 utf8mb4_bin,TiDB 7.4 之后默认是 default_collation_for_utf8mb4 配置的值。
详细说明参考:
characterEncoding
Instructs the server to set session system variables 'character_set_client' and 'character_set_connection' to the default character set supported by MySQL for the specified Java character encoding and set 'collation_connection' to the default collation for this character set. If neither this property nor the property 'connectionCollation' is set:
For Connector/J 8.0.25 and earlier, the driver will try to use the server's default character set;
For Connector/J 8.0.26 and later, the driver will use "utf8mb4".
connectionCollation
Instructs the server to set session system variable 'collation_connection' to the specified collation name and set 'character_set_client' and 'character_set_connection' to a corresponding character set. This property overrides the value of 'characterEncoding' with the default character set this collation belongs to, if and only if 'characterEncoding' is not configured or is configured with a character set that is incompatible with the collation. That means 'connectionCollation' may not always correct a mismatch of character sets. For example, if 'connectionCollation' is set to "latin1_swedish_ci", the corresponding character set is "latin1" for MySQL, which maps it to the Java character set "windows-1252"; so if 'characterEncoding' is not set,"windows-1252" is the character set that will be used; but if 'characterEncoding' has been set to, e.g. "ISO-8859-1", that is compatible with "latin1_swedish_ci", so the character encoding setting is left unchanged; and if client is actually using "windows-1252" (which is similar but different from "ISO-8859-1"), errors would occur for some characters. If neither this property nor the property 'characterEncoding' is set:
For Connector/J 8.0.25 and earlier, the driver will try to use the server's default character set;
For Connector/J 8.0.26 and later, the driver will use utf8mb4's default collation.排序优先级
在大多数情况下,比较容易判断排序规则的优先级,下面的 SQL 里使用字段 x 的排序规则对比数据。
SELECT x FROM T ORDER BY x;
SELECT x FROM T WHERE x = x;
SELECT DISTINCT x FROM T;也有一些情况下,排序规则的优先级会有一定的疑惑性,TiDB 按照以下方式计算字符串的 coercibility (数值越低,优先级越高):
- 显式的 COLLATE 子句具有 0 的 coercibility(不可转换);
- 两个不同排序规则的字符串连接具有 1 的 coercibility;
- 列或局部变量的排序规则具有 2 的 coercibility;
- “系统常量”(由诸如 USER() 或 VERSION() 等函数返回的字符串)具有 3 的 coercibility;
- 字符串的排序规则具有 4 的 coercibility;
- 数值或时间值的排序规则具有 5 的 coercibility;
- NULL 或从 NULL 派生的表达式具有 6 的 coercibility。
TiDB 使用 coercibility 的值来解决转换冲突:
- 优先使用 coercibility 越低的排序规则
- 如果两者有相同的 coercibility 值
- 两边都是 Unicode 编码或者两边都不是 Unicode,报错。
- 一边是 Unicode,一边不是 Unicode,使用 Unicode 的排序规则,自动转换非 Unicode 字符集为 Unicode 字符集。
总结
-
为了保证不会出现乱码情况,我们最好保证数据库的库、表、列、字符串字符集和会话的配置(character_set_client,character_set_results,character_set_connection)一致。
-
如果不能保证上述条件,建议数据库的库、表、列、字符串字符集要是会话相关字符集的超集,这样可以保证字符集的无损转换。
目录