

我们很高兴地宣布,TiDB 7.0 正式发布。TiDB 7.0 聚焦于帮助用户通过可靠性能和简化数据库操作来快速响应业务需求,从而满足客户的高期望值,并提升开发人员和 IT 运维人员的生产力。新版本中,TiDB 在可扩展性与性能、稳定性与高可用、SQL 以及可观测性几个领域获得持续提升,累计引入新特性 20 余项,优化功能 50 余项。TiDB 7.0 是 TiDB 7 系列首个 DMR 版本,适用于开发、测试和 PoC 等场景。
在 7 系列版本以及之后 2-3 年的时间里,我们希望 TiDB 在不断迭代中拥有:
- 更强的基础能力(核心性能,扩展性,性价比,云原生等);
- 更加多元化的场景支持(多租户,更多数据模型支持,更好的生态适配);
- 更顺滑的运维体验(更强的 DDL 能力,以 SQL 为统一界面的运维体验等,智能运维);
- 更可靠更安全(更高的可用性,更好的安全体系整合,更多合规认证)。这些主题都将逐步在 7 系列以及后续版本中落实,给予用户更优的使用体验,让 TiDB 变成一个好用且泛用,可靠且经济的选择。具体到 7.0 版本,TiDB 初步提供了更好的资源管控能力,让 TiDB 针对 SaaS 和多平台统一共存等场景有了根本性的解决方案;其次,TiFlash 发布了面向云的存算分离新架构,这使其可以真正做到存算资源解耦,计算资源可以按需启停,且基于 S3 的存储设计也将大幅降低存储成本;而诸如分析引擎支持落盘,自动执行计划缓存等,则是针对企业级场景做出的必要强化;最后,TiDB 7.0 提供了对 MySQL 8.0 的兼容,这将使得相关用户能更方便地迁移到 TiDB。
接下来让我们具体看看新版本的情况。
资源管控增强多租户形态下工作负载稳定性
资源管控特性(Resource Control)在 TiDB 6.6 中引入(实验特性),在 TiDB 7.0 中得到增强和优化,极大地提升 TiDB 集群的资源利用效率和性能表现,为稳定的多租户奠定了基础。资源管控特性对 TiDB 具有里程碑的意义,用户可以将一个分布式数据库集群划分成多个逻辑单元,将不同的数据库用户映射到对应的资源组中,并根据需要设置每个资源组的配额。该功能允许为一个或多个会话组设置资源上限,如果来自某个工作负载或应用程序的消耗异常重,则其资源消耗将被限制在配额内,以防止对其他更关键的工作负载造成干扰。
资源管控适用于以下场景:
- 用户可以将多个应用程序合并到单个 TiDB 集群中,降低 TCO 并保证重要工作负载所需的资源。
- 用户可以在业务运营时间内安全运行批处理任务。
- 模拟环境(Staging Environments)可共享具有受资源管控限制的单个 TiDB 集群。
会话可通过三种方式绑定到资源组:通过 CREATE USER 或 ALTER USER 语句将用户绑定到特定的资源组,使得用户会话始终受到设定边界约束;通过 SET RESOURCE GROUP 设置当前会话的资源组;也可通过优化器 Hint RESOURCE_GROUP() 设置当前语句的资源组。
TiFlash 支持数据落盘来稳定分析工作负载
TiFlash 是 TiDB 的列存储和计算引擎,是数据库分析工作负载能力的支柱。在 TiDB 7.0 之前,TiFlash 在内存中处理所有数据。从这个版本开始,TiFlash 支持数据落盘功能(Spill to disk),通过调整算子内存使用阈值,控制对应算子的最大内存使用量。对于大查询而言,当算子使用内存超过一定阈值时会自动将数据落盘,牺牲一定的性能换取整体分析查询的稳定性。数据落盘操作根据用户配置参数进行,并适用于单个推送下去的操作。由于该优化发生在单个运算符级别上,因此必须在多个位置执行数据落盘操作。在 TiDB 7.0 中,它首先被应用于以下情况:
- 相等条件下的哈希连接;
- GROUP BYs 上的哈希聚合;
- 窗口函数中 TopN 和排序运算符。
在执行这些操作期间,如果运算符使用的内存量超过了配置限制,会自动将数据落盘并继续进行后续处理。为了说明目标工作负载受影响程度,我们模拟了决策支持系统,使用 TPC-H 基准测试工具进行测试,结果如下表所示:
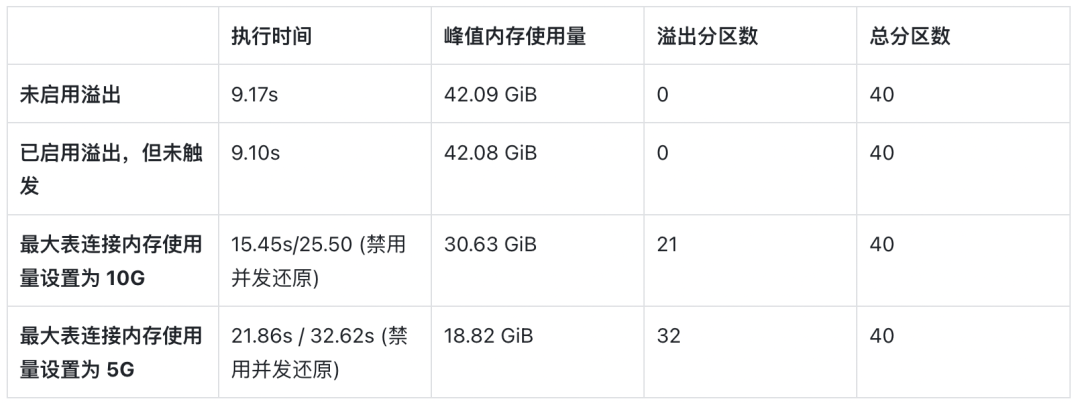
自动计划缓存减少查询延迟
在此之前,TiDB 已经支持使用 PREPARE 准备语句来进行计划缓存。TiDB 7.0 中,非 Prepare 语句的执行计划也能够被缓存,使执行计划缓存能够应用于更广泛的场景。该功能支持在会话级别上对查询进行缓存,全局级别的支持将在未来发布中推出。会话级别的缓存将减少由于查找正确计划而导致的延迟,但可能也会增加全局缓存中可能存在重复数据时所需内存。目前可以通过此功能进行单表过滤和范围查询类型的查询进行缓存,但不能够处理单表复杂查询和 JOIN 查询等其他类型。
TiFlash 支持存算分离架构,降低数据分析成本
在 TiDB 7.0 版本,TiFlash 支持存算分离和 S3 对象存储(实验特性)。之前版本的 TiFlash 是存算一体架构,TiFlash 节点既是存储节点,也是计算节点,其计算和存储能力扩展受到一定限制。同时,TiFlash 节点只能使用本地存储。在 7.0 版本中,TiFlash 支持存算分离架构,分为 Write Node 和 Compute Node 两种节点,可以分别部署,单独按需扩展,并支持将数据存储在 Amazon S3 或兼容 S3 API 的对象存储中。
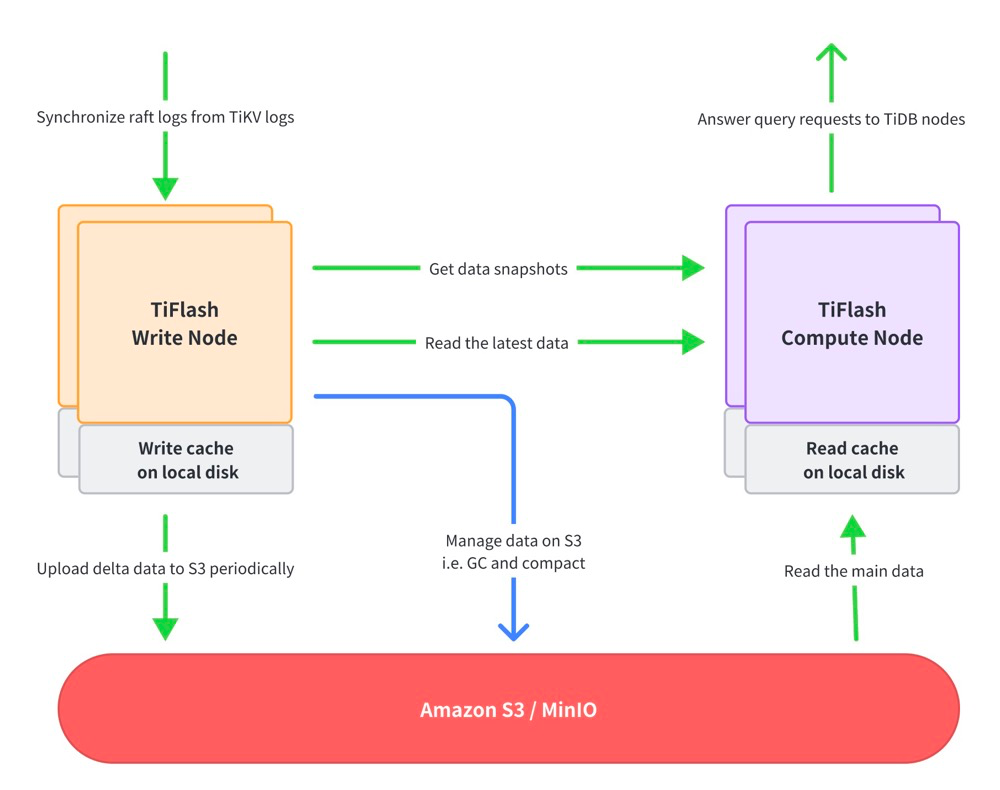
TiFlash 存算分离架构适用于高性价比的数据分析场景。在数据量很大,但是只有少量数据被频繁查询,大部分冷数据很少被查询的场景下,将经常被查询的数据缓存在 Compute Node 的本地 SSD 上,可以提供较快查询性能,将大量冷数据存储在成本较低的 S3 或者其他对象存储上,从而节省存储成本。在计算资源需求有明显的波峰和波谷场景下,例如晚上执行的重型对账查询,对计算资源要求较高,可以临时扩展 Compute Node,其他时间可以用较少的 Compute Node 完成查询任务。TiFlash 的存算分离架构大幅降低了使用 TiFlash 支持分析工作负载的成本,并且提供了一定程度的工作负载隔离。目前,TiUP 和 TiDB Operator 已经支持部署和缩放 TiFlash 独立组件的能力。
TTL 定期删除过期数据为系统减负
TiDB 6.5 引入了 Time to live(TTL)实验特性,提供了行级别的生命周期控制策略,该项特性在 TiDB 7.0 中正式 GA。TTL 是一种通过 SQL 配置设置表中行到期时间的方式,帮助用户周期性且及时地清理不需要的数据,并尽量减少对用户负载的影响。TTL 以表为单位,并发地分发不同的任务到不同的 TiDB Server 节点上,进行并行删除处理。在某些情况下,较大的表格意味着查询时间更长;较大的表格意味着更多的存储成本;在 TiDB 中,一个表越大,Region 就越多,限制表格大小可以减轻系统负担;各种合规性要求可能需要设置数据过期。基于成本、性能或安全等因素考虑,数据库管理员可以配置自动检查并删除过期的表格行数据,例如定期删除验证码、短网址记录、不需要的历史订单、计算的中间结果等。
使用 Key 分区提高可扩展性
在 7.0 之前,TiDB 支持 Hash、Range 和 List 分区。新版本引入了 key 分区,与 Hash 分区类似,Key 分区可以保证将数据均匀地分散到一定数量的分区里面。Hash 分区只能根据一个指定的整数表达式或字段进行分区,而 Key 分区可以根据字段列表进行分区,且 Key 分区的分区字段不局限于整数类型。Key 分区提供了一种更灵活的方式来对数据集进行划分以改善集群的可扩展性。
使用 REORGANIZE PARTITION 适应不断变化的需求
TiDB 长期以来一直支持分区,修改分区表的唯一方法是添加或删除分区和截断 LIST/RANGE 分区。TiDB 7.0 TiDB 支持 ALTER TABLE... REORGANIZE PARTITION 语法,用户可以对表的部分或所有分区进行重新组织,包括合并、拆分、或者其他修改,并且不丢失数据,增加了可用性和灵活性以满足不断变化的需求。
使用 LOAD DATA 从远程存储导入数据
TiDB 7.0 中,LOAD DATA 语句集成 TiDB Lightning,用户可以使用 LOAD DATA 语句完成原先需要使用 TiDB Lightning 才能完成的数据导入任务(实验特性),不仅可以省去 TiDB Lightning 的部署和管理成本,还可以借助 TiDB Lightning 的功能极大扩展 LOAD DATA 语句的能力,包括:支持从 Amazon S3 和 Google Cloud Storage 导入数据到 TiDB,且支持使用通配符一次性匹配多个源文件导入到 TiDB;支持查询任务状态,添加操作便利性等。
浏览 TiDB 7.0.0 Release Notes,了解更多新增和优化特性。立即下载试用,开启崭新的 TiDB 探索之旅。企业级用户期待的 TiDB 7.1 LTS 版本将很快与大家见面,敬请期待!
目录