
关系型数据库的 DBA 日常肯定遇到过这样的一种场景:SQL 执行计划选择错误,这类问题的危害是很大的,常常导致业务突然卡顿,数据库过载等不良后果。
举个例子,假设我们有这么一张表:
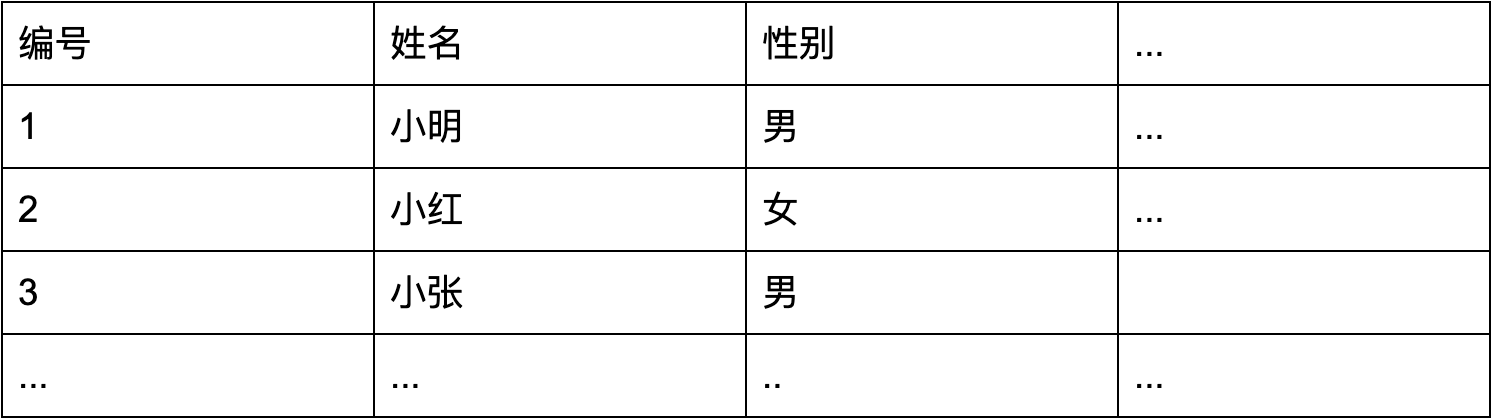
其中,姓名和性别这两列有索引。我们设想一下,在这张表上,我们进行下面一条查询:
SELECT * FROM t WHERE 姓名='小明' and 性别='男'正常情况下,SQL 优化器内部会通过采样等手段,得到姓名和性别这两个索引的数据区分度,在这个场景下,大多数时候,「姓名」都是一个更有区分度的索引,所以优化器会选择姓名进行查询就能过滤掉大量的行。
但是,我们设想一个比较极端的情况,突然这个表中写入了大量的“女性小明”:
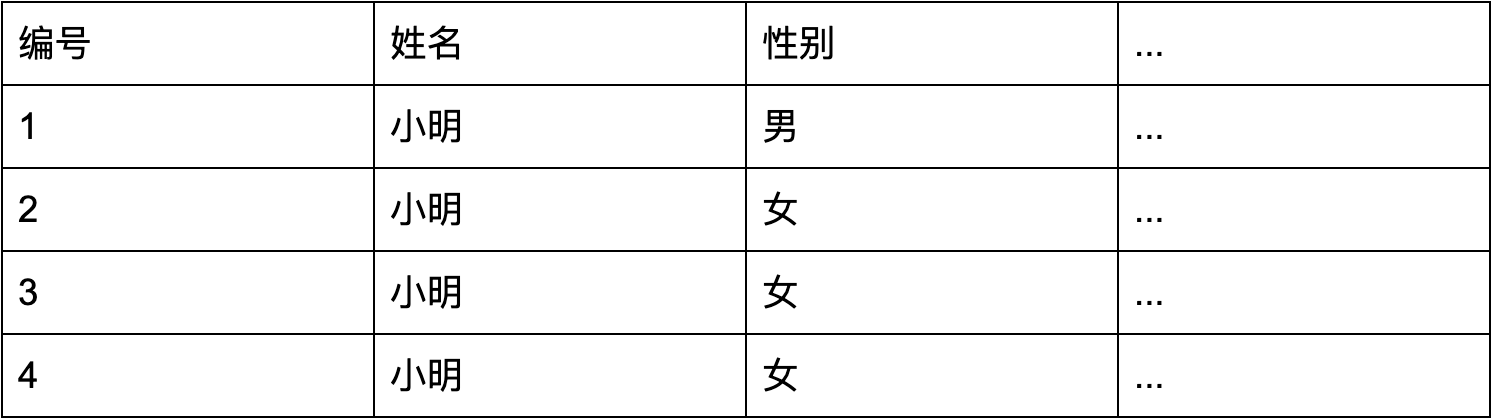
也就是会出现这样一种情况:对这条语句来说,使用「姓名」这个索引区分度变得不高,因为有大量的同名小明,但是「性别」这个索引却非常合适(只有一个男性小明)。
如果这个时候 SQL 优化器仍然选择了姓名的索引,在业务中就会出现一条本来跑得好好的 SQL 突然变成了慢查询。
由于 TiDB 作为一个关系型数据库,而且优化器也是基于代价的优化器,通常基于代价的优化器对于数据的采样很难做到瞬时,尤其是数据量特别大表来说,总是有可能出现数据的分布随着业务的变化发生突变,即时采样做到实时,不仅仅是索引的选择,也包括 JOIN 方式的选择,JOIN 的顺序等,很难保证 100% 的情况都选对。根据我们的观察,大多数生产环境中的 SQL 问题都是由于这个原因产生的。
知道了问题的根源,解决起来也比较简单了,DBA 经常做的事情:找到慢查询,使用给语句加 hint 之类的方式(给查询语句写注释),告诉优化器:不要自己猜,我这边更了解我的业务特征,就按我告诉你的这么查。
但是通过 hint 的方式,也有以下的几个问题:
- 这些 SQL 可能不一定是手写的,可能是 ORM 之类的数据库框架生成的,修改 SQL 不现实。
- 即使改写了业务层的 SQL,相当于修改了业务代码,必然需要重新部署业务,这个可能会带来不确定的风险。
- 虽然有 hint,但是如果后期数据分布发生了变化,即使优化器知道存在更好的查询计划,但是优化器也没有办法覆盖原先的 hint。
因为有上面的问题存在,我们在 TiDB 4.0 中引入了一套全新的机制:SQL Plan Management(SPM) 帮助 DBA 解决这个问题。
我们先看看怎么用,还是上面那个例子,DBA 只需要在数据库中执行下面一条语句:
CREATE GLOBAL BINDING FOR
SELECT * FROM t WHERE 姓名='小明' and 性别='男'
USING
SELECT * FROM t USE INDEX(性别) WHERE 姓名='小明' and 性别='男'其实很简单,我们引入了一个新的语法叫做,CREATE BINDING FOR …(语句) USING …(语句2) 来给一类 SQL 查询绑定执行计划。
像上面通过 SPM 来修正执行计划比起 hint 的方式来说,最明显的区别就是:不需要修改业务的代码,可以由 DBA 直接实时操作数据库系统表完成且实时生效,避免了重新上线业务的麻烦。
但我们回头看一下,上面列出的问题 3 似乎没解决,如果 SQL 优化器发现了更好的执行计划,例如上面的例子,后来发现数据分布又变化了,选择「姓名」又是一个更好的方案了,且这个执行计划并没有在绑定列表中怎么办?这个问题在 TiDB 4.0 的 SPM 里面,我们通过一个叫「计划演进」的机制,很好的解决了这个问题。
顾名思义,「演进」指的就是自主的发展、进化。TiDB 4.0 的 SPM 会在设置的业务低峰时间段里抽取一小部分资源,在后台尝试其他的执行计划,如果探测出更好的执行计划,那么,SPM 会将这个新的计划加入绑定列表,下次正常的查询,TiDB 也会将这个新计划考虑在内。
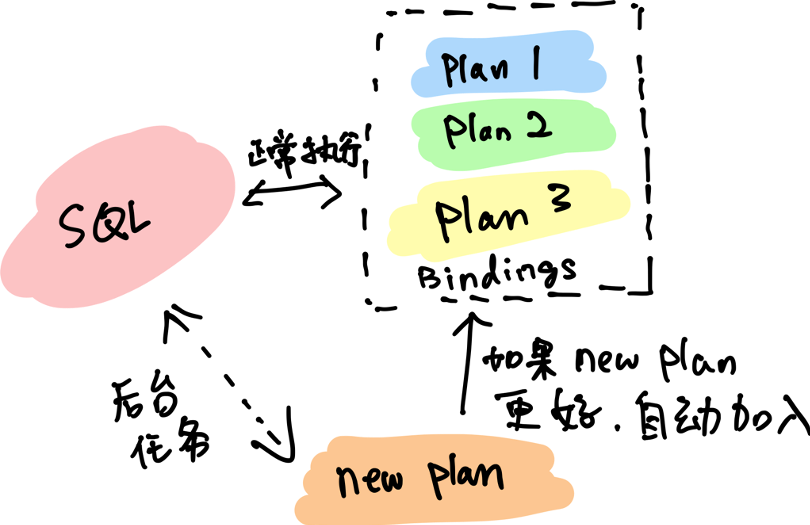
计划演进功能,目前需要通过执行下面的 SQL语句,设置一个全局开关开启:
SQL> SET GLOBAL tidb_evolve_plan_baselines = on;总的来说,SPM 功能使得用户可以对 SQL 执行计划有比较大的控制,同时又提供了灵活演进的方法,对线上执行计划的稳定性有很大帮助,相信能让 DBA 在使用 TiDB 的过程中更加安心。大家目前可以在 4.0.0 beta 中体验该功能,如果需要了解更多,请查看 相关的文档。在 TiDB 社区伙伴们合写的开源电子书《TiDB in Action》中也有 相关章节 介绍。欢迎大家试用并提出宝贵意见 info@pingcap.com。
相关阅读:
TiDB 4.0 新特性前瞻(一)拍个 CT 诊断集群热点问题;
TiDB 4.0 新特性前瞻(二)白话“悲观锁”;
TiDB 4.0 新特性前瞻(四)图形化诊断界面。