
内容概要
本文是 TiCDC 源码解读的第五篇,本文将会介绍 TiCDC 对 DDL 的处理方式和 Filter 功能的实现(基于 TiCDC v6.5.0 版本代码) ,文章将会围绕以下 4 个问题展开。
- 为什么 TiCDC 只用 Owner 节点来同步 DDL?
- DDL 事件会对同步任务的进度有什么影响?
- TiCDC 是怎么在内部维护表的 Schema 信息的?
- TiCDC 的 Filter 功能是怎么实现的?
希望在回答完这几个问题之后,大家能够对 TiCDC DDL 同步机制有所了解,并且能够对 Filter 模块的有比较深入的认识。
同步架构回顾
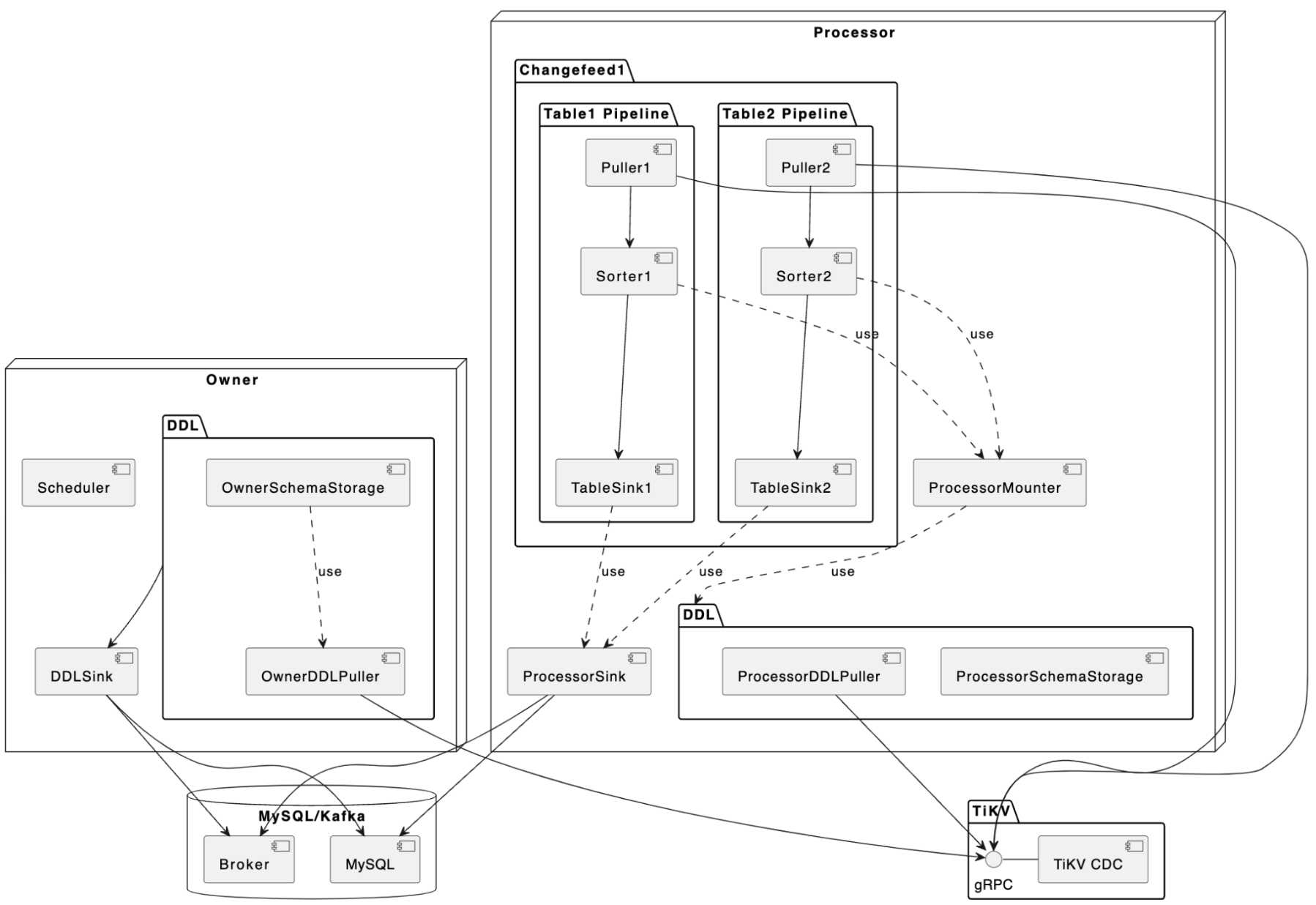
第一期《TiCDC 架构概览》的文章中,我们就认识到了 TiCDC 的 DML 同步流和 DDL 同步流是分开的。
从上面的架构图中可以看到, DML 的同步是由 Processor 进行的,数据流从上游的 TiKV 流入经过 Processor 内的 TablePipeline ,最后被同步到下游。而 DDL 同步则是由 Owner 进行的,OwnerDDLPuller 拉取上游发生的 DDL 事件,然后在内部经过一系列的处理之后,通过 DDLSink 同步到下游。
在深入认识 DDL 的处理细节之前,需要先结合以上的架构图,对下面几个实体有所了解:
- OwnerSchemaStorage:由 Owner 持有,维护了当前所有表最新的 schema 信息,这些表的 schema 信息主要会被 scheduler 所使用,用来感知同步任务的表数量的变化;此外,还会被 owner 用来解析 ddlPuller 拉取到的 DDL 事件。
- ProcessorSchemaStorage:由 Processor 持有,维护了当前所有表的多个版本的 schema 信息,这些信息会被 Mounter 用来解析行变更信息。
- BarrierTs:由 Owner 向 Processor 发送的控制信息,它会让 Processor 把同步进度阻塞到 BarrierTs 所指定的值。TiCDC 内部有几种不同类型的 BarrierTs,为了简化叙述,本文中提到的 BarrierTs 仅表示 DDL 事件产生的 DDLBarrierTs。
- OwnerDDLPuller:由 Owner 持有,负责拉取和过滤上游 TiDB 集群的 DDL 事件,并把它们缓存在一个队列中,等待 Owner 处理;此外,它还会维护一个 ResolvedTs,该值为上游 TiKV 发送过来的最新的 ResolvedTs,在没有 DDL 事件到来的时候,Owner 将会使用它来推进 DDLBirrierTs。
- ProcessorDDLPuller:由 Processor 持有,负责拉取和过滤上游 TiDB 集群的 DDL 事件,然后把它们发送给 Processor 去更新 ProcessorSchemaStorage。
- DDLSink:由 Owner 持有,负责执行 DDL 到下游。
为什么 TiCDC 选择由 Owner 节点来同步 DDL?
TiCDC 之所以选择由 Owner 来同步 DDL,是因为需要确保在同步一条 DDL 的时候:
- 所有早于该条 DDL 的行变更事件都已同步到下游。
- 所有晚于该条 DDL 的行变更都需要在该条 DDL 成功同步到下游之后才会继续同步。
否则,就有可能出现上下游数据不一致的情况。
要达到以上两个目的,就需要保证我们执行一条 DDL 之前,所有 Processor 上面的同步流都准确地停在 DDL 的 commitTs 这个时间点,等到 DDL 被成功同步到下游之后再恢复同步。
在当前 TiCDC 的同步模型中,Owner 是负责发号施令的角色,它拥有整个同步任务所有表的状态信息,能够对 Processor 下达停止同步的控制指令,也能够得知同步流是否停止在恰当的时刻上。所以,为了简化 DDL 的处理逻辑,我们选择仅由 Owner 节点来进行 DDL 的同步。
DDL 事件会对同步任务的进度产生什么影响?
如上文所述,在同步一条 DDL 之前,我们需要先让同步任务的数据流准确地停止在该 DDL 的 commitTs 这个时刻。这是通过 Owner 计算并向 Processor 发送 BarrierTs 实现的,接下来将会结合下面的顺序图来详细讲解该流程。
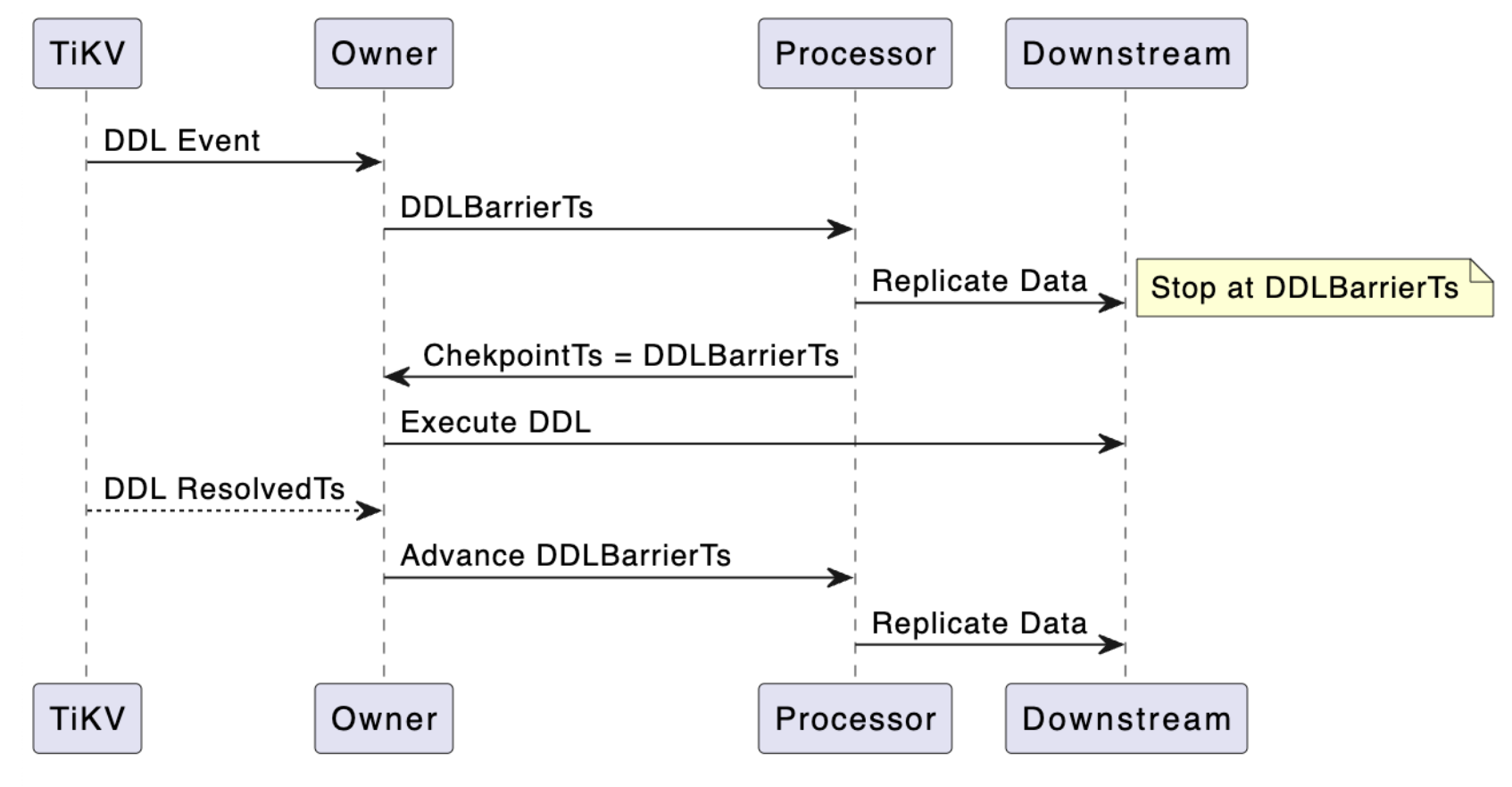
OwnerDDLPuller 在 Changefeed 启动之后,就会持续监听上游 TiDB 集群发生的 DDL 事件,当接收到一条 DDL 事件之后,它会先对该条 DDL 事件进行过滤。如果该条 DDL 和 Changefeed 所需同步的表无关,则会被直接忽略,否则将会被加入到 OwnerDDLPuller 的 pendingDDL 队列中。
Owner 在每轮 tick 里面都会去检查 pendingDDL 队列中是否有待执行的 DDL 事件。如果有待执行的 DDL 事件,则会取队头的 DDL 的 CommitTs 为 DDLBarrierTs。然后,通过 Etcd 向 Processor 广播这个 DDLBarrierTs,Processor 收到之后,会把该值设置为所有 TablePipeline 同步数据流的上界,当同步流前进到这个时间点之后,就需要停下来等待。
Owner 在每轮 tick 内部都会检查当前 Changefeed 的 CheckpointTs 是否已经前进到 DDLBarrierTs 的值,若前进到该值,则说明该条 DDL 之前的所有 DML 事件都已经被成功同步到下游了。此时,Owner 会把 DDL 事件应用到 OwnerSchemaStorage 上,使得元数据和上游保持一致;然后,Owner 会调用 DDLSink 把该条 DDL 同步到下游。等到 DDL 成功执行之后,Owner 就会推进 DDLBarrierTs 为下一条未执行的 DDL 的 CommitTs,如果不存在未执行的 DDL 事件,那么 DDLBarrierTs 会被推进到 OwnerDDLPuller 维护的 ResolvedTs 值。这样,Processor 的同步流就能够继续向前推进。
在当前的实现中,Owner 对 DDL 事件的处理逻辑主要存在 handlerBarrier() 这个函数中,核心逻辑如下:
// 检查是 checkpointTs 是否已经前进到下一条需要执行的 ddl commitTs 处。
if !checkpointReachBarrier {
return barrierTs, nil
}
// 通过以上检查,则尝试执行 ddl。这个执行是异步的,因此不会阻塞 owner tick 的主流程。
done, err := c.asyncExecDDLJob(ctx, ddlJob)
if err != nil {
return 0, errors.Trace(err)
}
if !done {
return barrierTs, nil
}
// 执行成功,则从 pendingDDL 队列中弹出该 DDL
c.lastDDLTs = ddlResolvedTs
c.ddlPuller.PopFrontDDL()
newDDLResolvedTs, _ := c.ddlPuller.FrontDDL()
// 更新 DDLBarrierTs
c.barriers.Update(ddlJobBarrier, newDDLResolvedTs)在 Processor 侧的主要逻辑则存在于 pushResolvedTs2Table() 这个函数中,核心逻辑如下:
// 这个 resolvedTs 就是上文提到的 BarrierTs
resolvedTs := p.changefeed.Status.ResolvedTs
schemaResolvedTs := p.schemaStorage.ResolvedTs()
if schemaResolvedTs < resolvedTs {
// Do not update barrier ts that is larger than
// DDL puller's resolved ts.
// When DDL puller stall, resolved events that outputted by sorter
// may pile up in memory, as they have to wait DDL.
resolvedTs = schemaResolvedTs
}
// 更新每个 table 的 BarrierTs,使得它们的进度能够推进。
if p.pullBasedSinking {
p.sinkManager.UpdateBarrierTs(resolvedTs)
} else {
for _, table := range p.tables {
table.UpdateBarrierTs(resolvedTs)
}
}通过上述的讲解,可以较为自然的得出这个结论:任意一张表的 DDL 事件会阻塞所有表的 DML 同步进度,因此上游执行耗时较长的 DDL 或者短时间内执行大量 DDL,都容易引起同步任务的延迟上升。
TiCDC 是怎么在内部维护表的 Schema 信息的?
TiCDC 对表的 Schema 信息的维护是 Changefeed 级别的,每个 Changefeed 在 Owner 节点上都会拥有一份 Schema 信息,在每个 Processor 节点上也都会有一份 Schema 信息。
// Owner 节点上的 changefeed
type changefeed struct {
// 存储表的最新信息
schema *schemaWrap4Owner
}
// Processor 节点上的 changefeed
type processor struct {
// 存储表的多版本信息
schemaStorage entry.SchemaStorage
}Schema 在 Changefeed 创建的时候被初始化,TiCDC 使用 Changefeed 的 startTs 从上游 TiKV 获取了一份 snapshot,并把 snapshot 里面所有的数据库和表信息都存储在 Schema 里。在 Changefeed 的运行过程中,TiCDC 会持续维护和更新 Schema 信息,每次有新的 DDL 事件到来的时候,TiCDC 都会把 DDL 事件应用到这个 Schema 上面,以保证 Schema 和上游 TiDB 中的 Schema 是一致的。
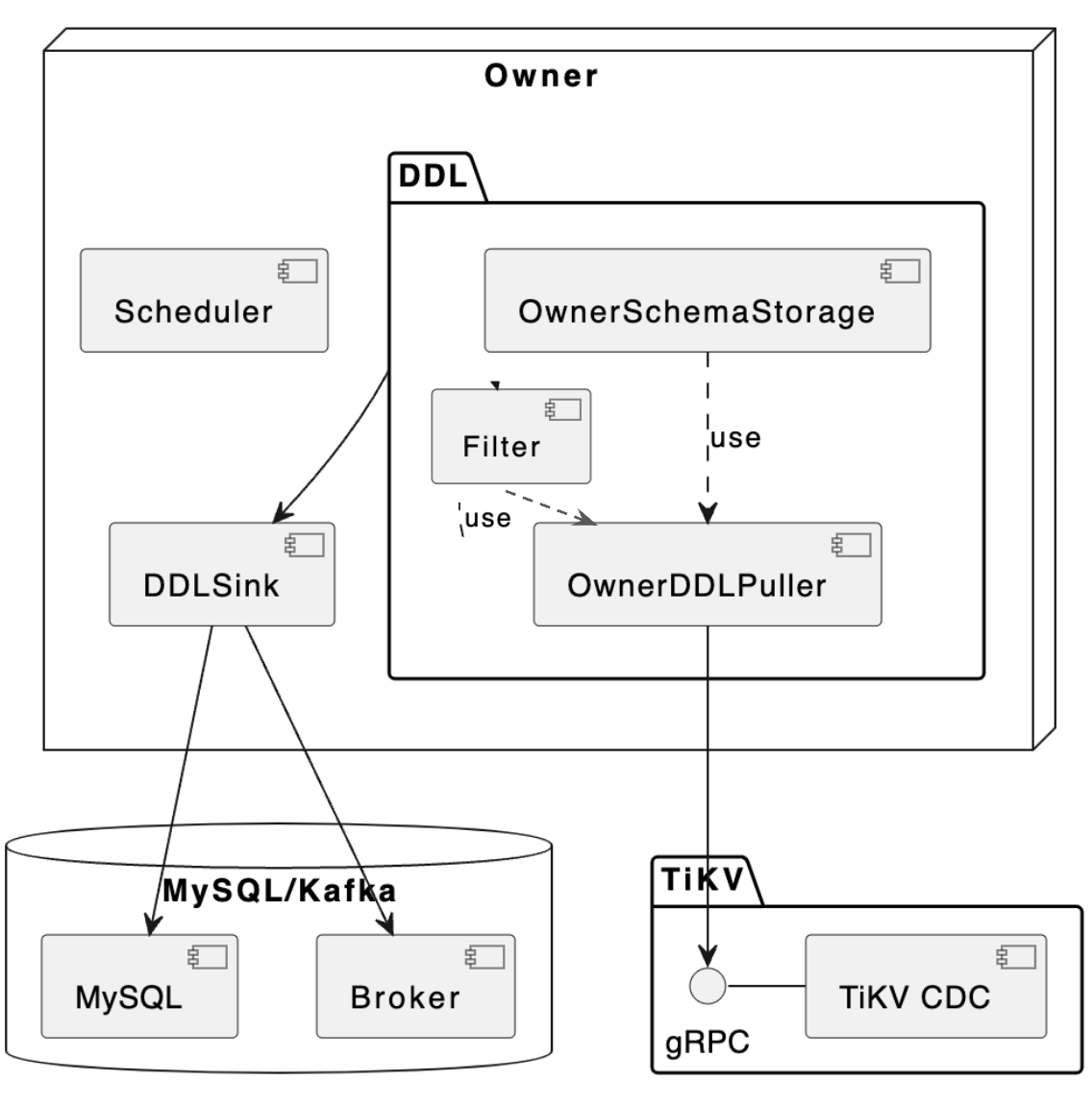
Owner 节点上的 Schema 中只保存了每张表最新的那份信息,原因在于 Owner 节点只负责 DDL 的同步,并且 TiCDC 保证了 DDL 的同步是线性有序的,它在解析下一条 DDL 的时候,只需要上一条 DDL 执行结束的时候的 Schema 信息就可以确保解析的正确性。除此之外,Scheduler 还会调用 Schema 提供的 AllPhysicalTables() 方法来感知当前是否有表的增减,触发调度任务。
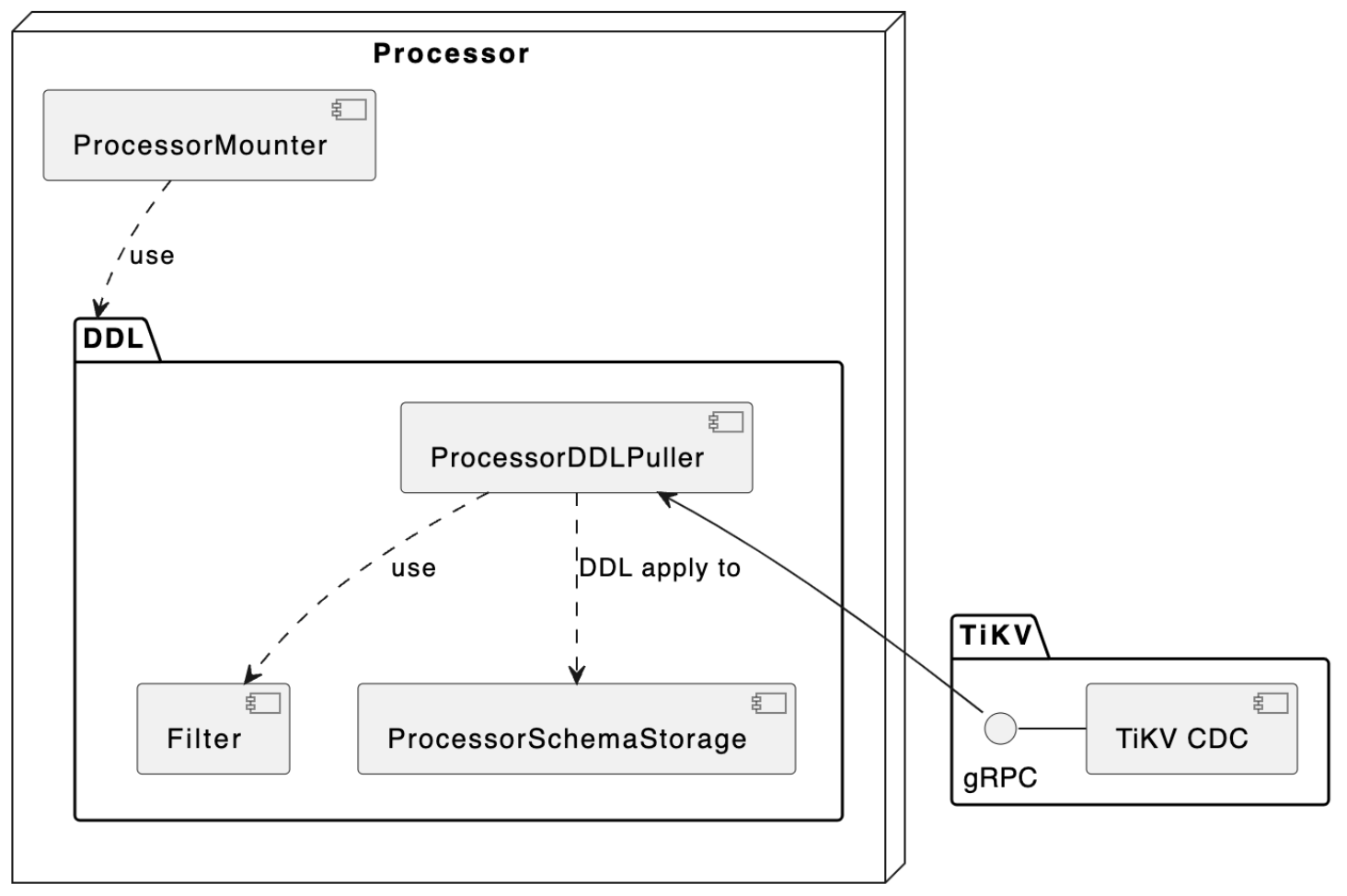
而 Processor 节点上的 SchemaStorage 中则保存了每张表最近几个版本的信息,因为 Processor 需要负责 DML 的同步,而 DML 的同步进度是有可能落后于 Processor 节点上 DDLPuller 拉取 DDL 事件的速度的。所以,为了能够正确地解析 DML 事件,我们需要在 SchemaStorage 中维护 CheckpointTs 之后版本的表信息,而 CheckpointTs 之前的信息则可以清理掉。TiCDC 保证 CheckpointTs 之前的变更事件都已经被同步到下游,也就肯定不会再需要解析 CheckpointTs 的 DML 事件了。
需要注意的是,在上游短时间发生大量的 DDL 时,SchemaStorage 需要频繁地进行更新,并且会短时间内产生多个版本的 Schema 信息,有可能造成 TiCDC 内存使用量大幅上升。
TiCDC 的 Filter 功能是怎么实现的?
目前 TiCDC 的 Filter 的基本功能如下:
- 同步或者忽略用户指定的库或者表
- 过滤 TiCDC 不支持同步的 DDL 事件
- 过滤用户指定忽略的 DDL 事件
- 过滤用户指定忽略的行变更事件
Filter 主要会被 DDLPuller、Mounter、SchemaStorage 这三者调用,用来实现以上提到的几个功能。若需要了解如何配置 Filter,可以参考文档:Changefeed 日志过滤器。接下来,我们将会从源码的角度来了解 Filter 的相关实现。
type Filter interface {
// ShouldIgnoreDMLEvent returns true and nil if the DML event should be ignored.
ShouldIgnoreDMLEvent(dml *model.RowChangedEvent, rawRow model.RowChangedDatums, tableInfo *model.TableInfo) (bool, error)
// ShouldIgnoreDDLEvent returns true and nil if the DDL event should be ignored.
// If a ddl is ignored, it will applied to cdc's schema storage,
// but not sent to downstream.
ShouldIgnoreDDLEvent(ddl *model.DDLEvent) (bool, error)
// ShouldDiscardDDL returns true if this DDL should be discarded.
// If a ddl is discarded, it will neither be applied to cdc's schema storage
// nor sent to downstream.
ShouldDiscardDDL(ddlType timodel.ActionType, schema, table string) bool
// ShouldIgnoreTable returns true if the table should be ignored.
ShouldIgnoreTable(schema, table string) bool
// Verify should only be called by create changefeed OpenAPI.
// Its purpose is to verify the expression filter config.
Verify(tableInfos []*model.TableInfo) error
}上面即是 Filter 的接口定义,大家可以从接口中的方法名和注释就了解到 Filter 具有什么样的功能。实现 Filter 接口的结构体定义如下:
// filter implements Filter.
type filter struct {
// tableFilter is used to filter in dml/ddl event by table name.
tableFilter tfilter.Filter
// dmlExprFilter is used to filter out dml event by its columns value.
dmlExprFilter *dmlExprFilter
// sqlEventFilter is used to filter out dml/ddl event by its type or query.
sqlEventFilter *sqlEventFilter
// ignoreTxnStartTs is used to filter out dml/ddl event by its starsTs.
ignoreTxnStartTs []uint64
}下面详细介绍一下组成 filter 的几个结构体:
- tableFilter 是表库过滤器,根据用户指定的规则来同步或者过滤对应的表和库,它是通过表名和库名在 changefeed 初始化的阶段进行过滤的。如果用户在 Filter 规则中配置了只同步某张表,那么 changefeed 就只会拉取该表的变更事件。
- dmlExprFilter 是 sql 表达式过滤器,实现了通过用户指定的 SQL 表达式来过滤对应 DML 事件的功能。该行为是在 Mounter 中进行的,它会根据用户提供的 sql 表达式来对每一行变更进行计算,过滤掉符合计算结果的行变更事件。
- sqlEventFilter 是事件类型过滤器,它根据用户指定的事件类型来过滤符合条件的 DDL 或者 DML 事件。该行为也是在 Mounter 中进行的。
- ignoreTxnStartTs 则是根据指定的 startTs 来过滤事件,一般不推荐用户使用。
以上几个结构体内部的实现逻辑都较为简单,整个 Filter 接口的方法就是由这几个结构体提供的方法组合而成的,感兴趣的读者可以自行点进源码链接进行阅读。比较值得注意的一点是 TiCDC 对 DDL 事件的同步支持,目前 TiCDC 对 DDL 同步采用的是白名单模式,仅支持同步白名单内的 DDL 事件。因此,当接收到非白名单事件的 DDL 时,TiCDC 会直接丢弃。
以上就是本文章的全部内容,希望读者看完之后能够对 TiCDC 有更深入的认识。
目录