
本文是 TiCDC 源码解读的第四篇,主要内容是讲述 TiCDC 中 Scheduler 模块的工作原理。主要内容如下:
- Scheduler 模块的工作机制
- 两阶段调度原理
Scheduler 模块介绍
Scheduler 是 Changefeed 内的一个重要模块,它主要负责两件事情:
- 将一个 Changefeed 所有需要被同步的表,分发到不同的 TiCDC 节点上进行同步工作,以达到负载均衡的目的。
- 维护每张表的同步进度,同时推进 Changefeed 的全局同步进度。
本次介绍的 Scheduler 相关代码都在 tiflow/cdc/scheduler/internal/v3 目录下,包含多个文件夹,具体如下:
- Coordinator 运行在 Changefeed,是 Scheduler 的全局调度中心,负责发送表调度任务,维护全部同步状态。
- Agent 运行在 Processor,它接收表调度任务,汇报当前节点上的表同步状态给 Coordinator。
- Transport 是对底层 peer-2-peer 机制的封装,主要负责在 Coordinator 和 Agent 之间传递网络消息。
- Member 主要是对集群中 Captures 状态的管理和维护。
- Replication 负责管理每张表的同步状态。
ReplicationSet记录了每张表的同步信息,ReplicationManager负责管理所有的ReplicationSet。 - Scheduler 实现了多种不同的调度规则,可以由 OpenAPI 触发。
下面我们详细介绍 Scheduler 模块的工作过程。
表 & 表调度任务 & 表同步单元
TiCDC 的任务是以表为单位,将数据同步到下游目标节点。所以对于一张表,可以通过如下形式来表示,该数据结构即刻画了一张表当前的同步进度。
type Table struct {
TableID model.TableID
Checkpoint uint64
ResolvedTs uint64
}Scheduler 主要是通过 Add Table / Remove Table / Move Table 三类表调度任务来平衡每个 TiCDC 节点上的正在同步的表数量。对于这三类任务,可以被简单地刻画为:
- Add Table:「TableID, Checkpoint, CaptureID」,即在 CaptureID 所指代的 Capture 上从 Checkpoint 开始加载并且同步 TableID 所指代的表同步单元。
- Remove Table:「TableID, CaptureID」,即从 CaptureID 所指代的 Capture 上移除 TableID 所指代的表同步单元。
- Move Table:「TableID, Source CaptureID, Target CaptureID」,即将 TableID 所指代的表同步单元从 Source CaptureID 指代的 Capture 上挪动到 Target CaptureID 指代的 Capture 之上。
表同步单元主要负责对一张表进行数据同步工作,在 TiCDC 内这由 Table Pipeline 实现。它的基本结构如下所示:
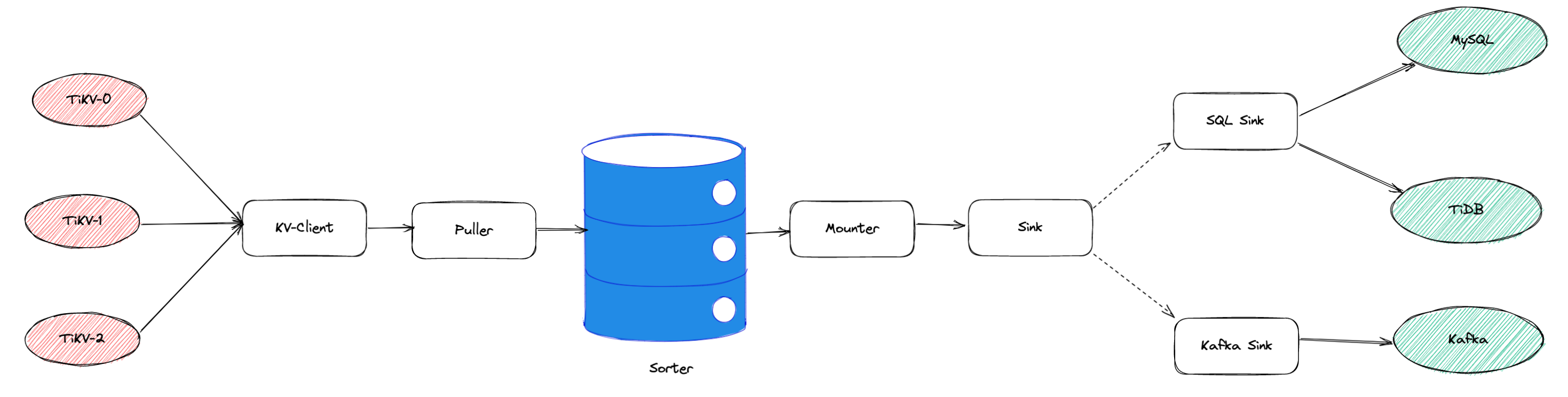
每个 Processor 开始同步一张表,即会为这张表创建一个 Table Pipeline,该过程可以分成两个部分:
- 加载表:创建 Table Pipeline,分配相关的系统资源。KV-Client 从上游 TiKV 拉取数据,经由 Puller 写入到 Sorter 中,但是此时不向下游目标数据系统写入数据。
- 复制表:在加载表的前提下,启动 Mounter 和 Sink 开始工作,从 Sorter 中读取数据,并且写入到下游目标数据系统。
Processor 实现了 TableExecutor 接口,如下所示:
type TableExecutor interface {
// AddTable add a new table with `startTs`
// if `isPrepare` is true, the 1st phase of the 2 phase scheduling protocol.
// if `isPrepare` is false, the 2nd phase.
AddTable(
ctx context.Context, tableID model.TableID, startTs model.Ts, isPrepare bool,
) (done bool, err error)
// IsAddTableFinished make sure the requested table is in the proper status
IsAddTableFinished(tableID model.TableID, isPrepare bool) (done bool)
// RemoveTable remove the table, return true if the table is already removed
RemoveTable(tableID model.TableID) (done bool)
// IsRemoveTableFinished convince the table is fully stopped.
// return false if table is not stopped
// return true and corresponding checkpoint otherwise.
IsRemoveTableFinished(tableID model.TableID) (model.Ts, bool)
// GetAllCurrentTables should return all tables that are being run,
// being added and being removed.
//
// NOTE: two subsequent calls to the method should return the same
// result, unless there is a call to AddTable, RemoveTable, IsAddTableFinished
// or IsRemoveTableFinished in between two calls to this method.
GetAllCurrentTables() []model.TableID
// GetCheckpoint returns the local checkpoint-ts and resolved-ts of
// the processor. Its calculation should take into consideration all
// tables that would have been returned if GetAllCurrentTables had been
// called immediately before.
GetCheckpoint() (checkpointTs, resolvedTs model.Ts)
// GetTableStatus return the checkpoint and resolved ts for the given table
GetTableStatus(tableID model.TableID) tablepb.TableStatus
}在 Changefeed 的整个运行周期中,Scheduler 都处于工作状态,Agent 利用 Processor 提供的上述接口方法实现,实际地执行表调度任务,获取到表调度任务进行的程度,以及表同步单元当前的运行状态等,以供后续做出调度决策。
Coordinator & Agent
Scheduler 模块由 Coordinator 和 Agent 两部分组成。Coordinator 运行在 Changefeed 内,Agent 运行在 Processor 内,Coordinator 和 Agent 即是 Changefeed 和 Processor 之间的通信接口。二者使用 peer-2-peer 框架完成网络数据交换,该框架基于 gRPC 实现。下图展示了一个有 3 个 TiCDC 节点的集群中,一个 Changefeed 的 Scheduler 模块的通信拓扑情况。可以看到,Coordinator 和 Agent 之间会交换两类网络消息,消息格式由 Protobuf 定义,源代码位于 tiflow/cdc/scheduler/schedulepb。
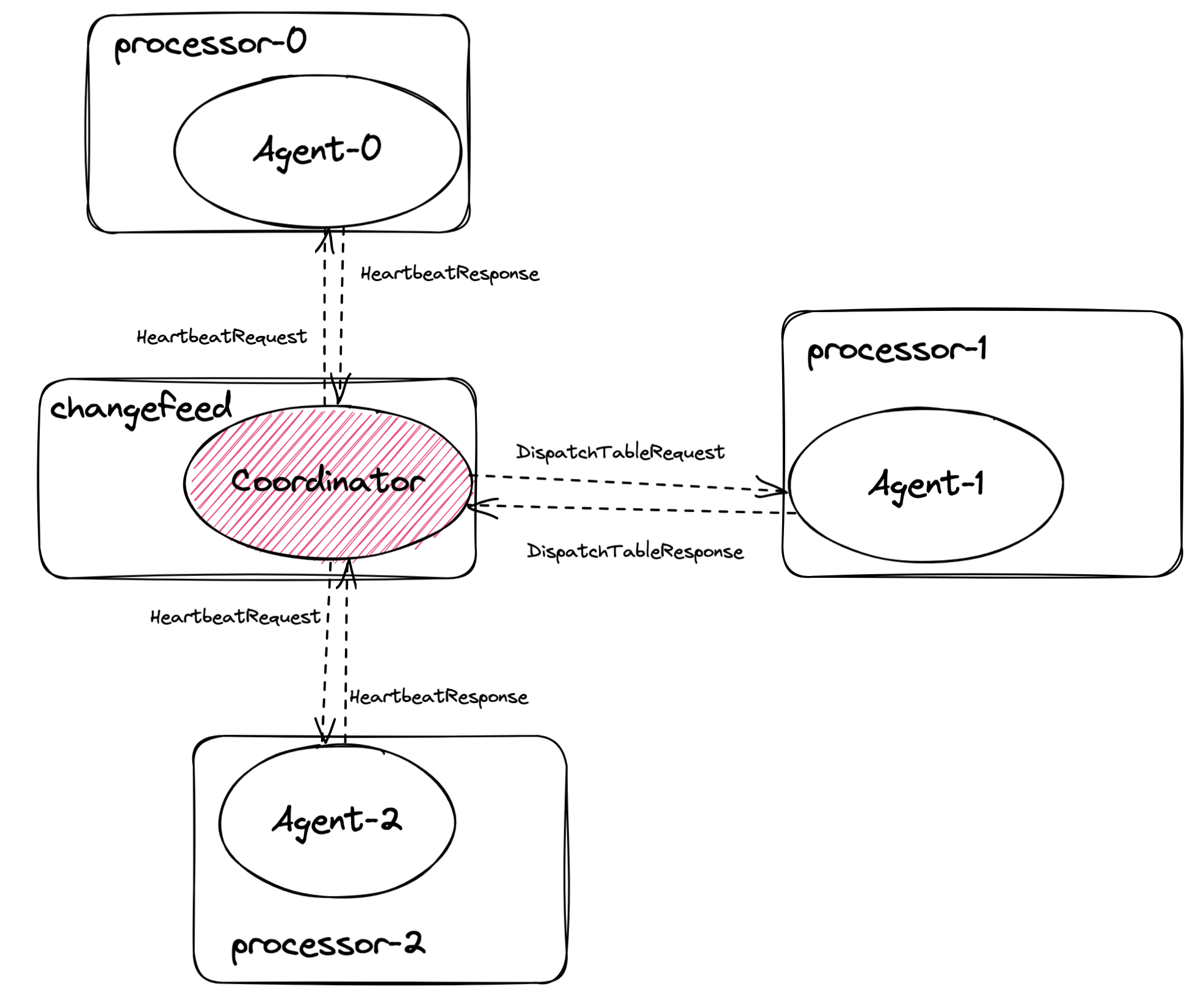
- 第一类是
Heartbeat消息,Coordinator 周期性地向 Agent 发送HeartbeatRequest,Agent 返回相应的HeartbeatResponse,该类消息主要目的是让 Coordinator 能够及时获取到所有表在不同 TiCDC 节点上的同步状态。 - 第二类是
DispatchTable消息,在有对表进行调度的需求的时候,Coordinator 向特定 Agent 发送DispatchTableRequest,后者返回DispatchTableResponse,用于及时同步每一张表的调度进展。
下面我们从消息传递的角度,分别看一下 Coordinator 和 Agent 的工作逻辑。
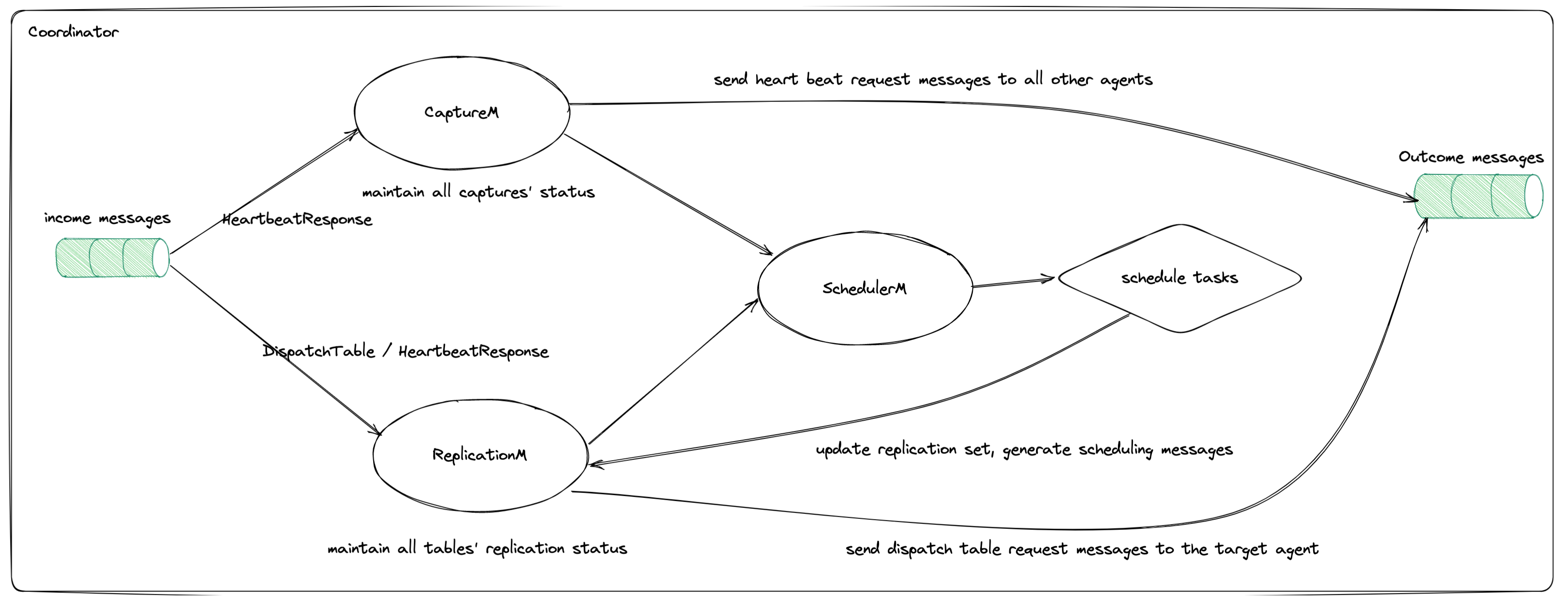
Coordinator 工作过程
Coordinator 会收到来自 Agent 的 HeartbeatReponse 和 DispatchTableResponse 这两类消息。Coordinator 内的 CaptureM 负责维护 Capture 的状态,在每次接收到 HeartbeatResponse 之后,都会更新自身维护的 Captures 的状态,包括每个 Capture 当前的存活状态,Capture 上当前同步的所有表信息。同时也生成新的 HeartbeatRequest 消息,再次发送到所有 Agents。ReplicationM 负责维护所有表的同步状态,它接收到 HeartbeatResponse 和 DispatchTableResponse 之后,按照消息中记录的表信息,更新自己维护的这些表对应的同步状态。CaptureM 提供了当前集群中存活的所有 Captures 信息,ReplicationM 则提供了所有表的同步状态信息,SchedulerM 以二者提供的信息为输入,以让每个 Capture 上的表同步单元数量尽可能均衡为目标,生成表调度任务,这些表调度任务会被 ReplicationM 进一步处理,生成 DispatchTableRequest,然后发送到对应的 Agent。
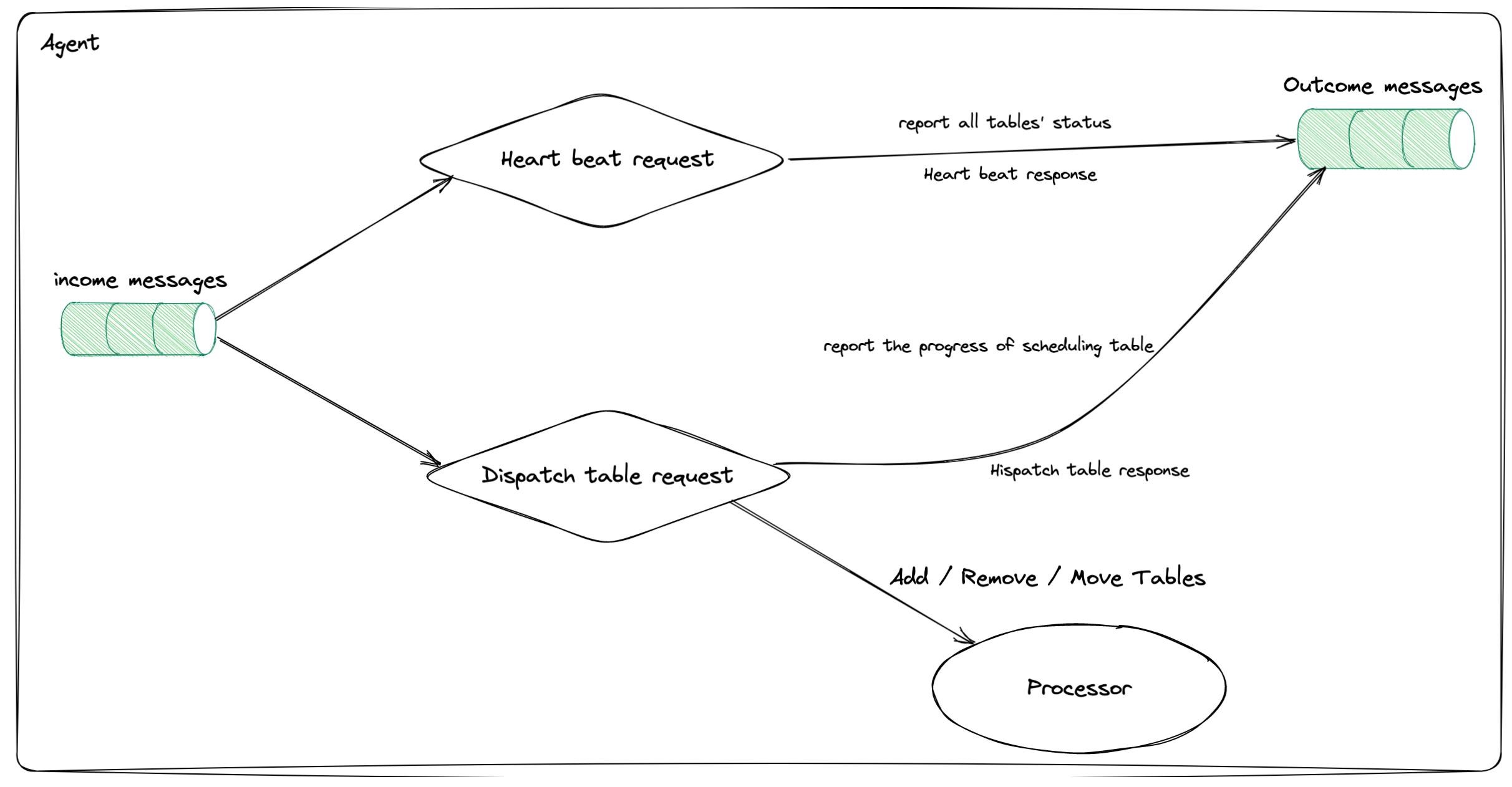
Agent 工作过程
Agent 会从 Coordinator 收到 HeartbeatRequest 和 DispatchTableRequest 这两类消息。对于前者,Agent 会收集当前运行在当前 TiCDC 节点上的所有表同步单元的运行状态,构造 HeartbeatRespone。对于后者,则通过访问 Processor 来添加或者移除表同步单元,获取到表调度任务的执行进度,构造对应的 DispatchTableResponse,最后发送到 Coordinator。
Changefeed 同步进度计算
一个 changefeed 内同步了多张表。对于每张表,有 Checkpoint 和 ResolvedTs 来标识它的同步进度,Coordinator 通过 HeartbeatResponse 周期性地收集所有表的同步进度信息,然后就可以计算得到一个 Changefeed 的同步进度。具体计算方法如下:
// AdvanceCheckpoint tries to advance checkpoint and returns current checkpoint.
func (r *Manager) AdvanceCheckpoint(currentTables []model.TableID) (newCheckpointTs, newResolvedTs model.Ts) {
newCheckpointTs, newResolvedTs = math.MaxUint64, math.MaxUint64
for _, tableID := range currentTables {
table, ok := r.tables[tableID]
if !ok {
// Can not advance checkpoint there is a table missing.
return checkpointCannotProceed, checkpointCannotProceed
}
// Find the minimum checkpoint ts and resolved ts.
if newCheckpointTs > table.Checkpoint.CheckpointTs {
newCheckpointTs = table.Checkpoint.CheckpointTs
}
if newResolvedTs > table.Checkpoint.ResolvedTs {
newResolvedTs = table.Checkpoint.ResolvedTs
}
}
return newCheckpointTs, newResolvedTs
}从上面的示例代码中我们可以看出,一个 Changefeed 的 Checkpoint 和 ResolvedTs,即是它同步的所有表的对应指标的最小值。Changefeed 的 Checkpoint 的意义是,它的所有表的同步进度都不小于该值,所有时间戳小于该值的数据变更事件已经被同步到了下游;ResolvedTs 指的是 TiCDC 当前已经捕获到了所有时间戳小于该值的数据变更事件。除此之外的一个重点是,只有当所有表都被分发到 Capture 上并且创建了对应的表同步单元之后,才可以推进同步进度。
以上从消息传递的角度对 Scheduler 模块基本工作原理的简单介绍。下面我们更加详细地聊一下 Scheduler 对表表度任务的处理机制。
两阶段调度原理
两阶段调度是 Scheduler 内部对表调度任务的执行原理,主要目的是降低 Move Table 操作对同步延迟的影响。
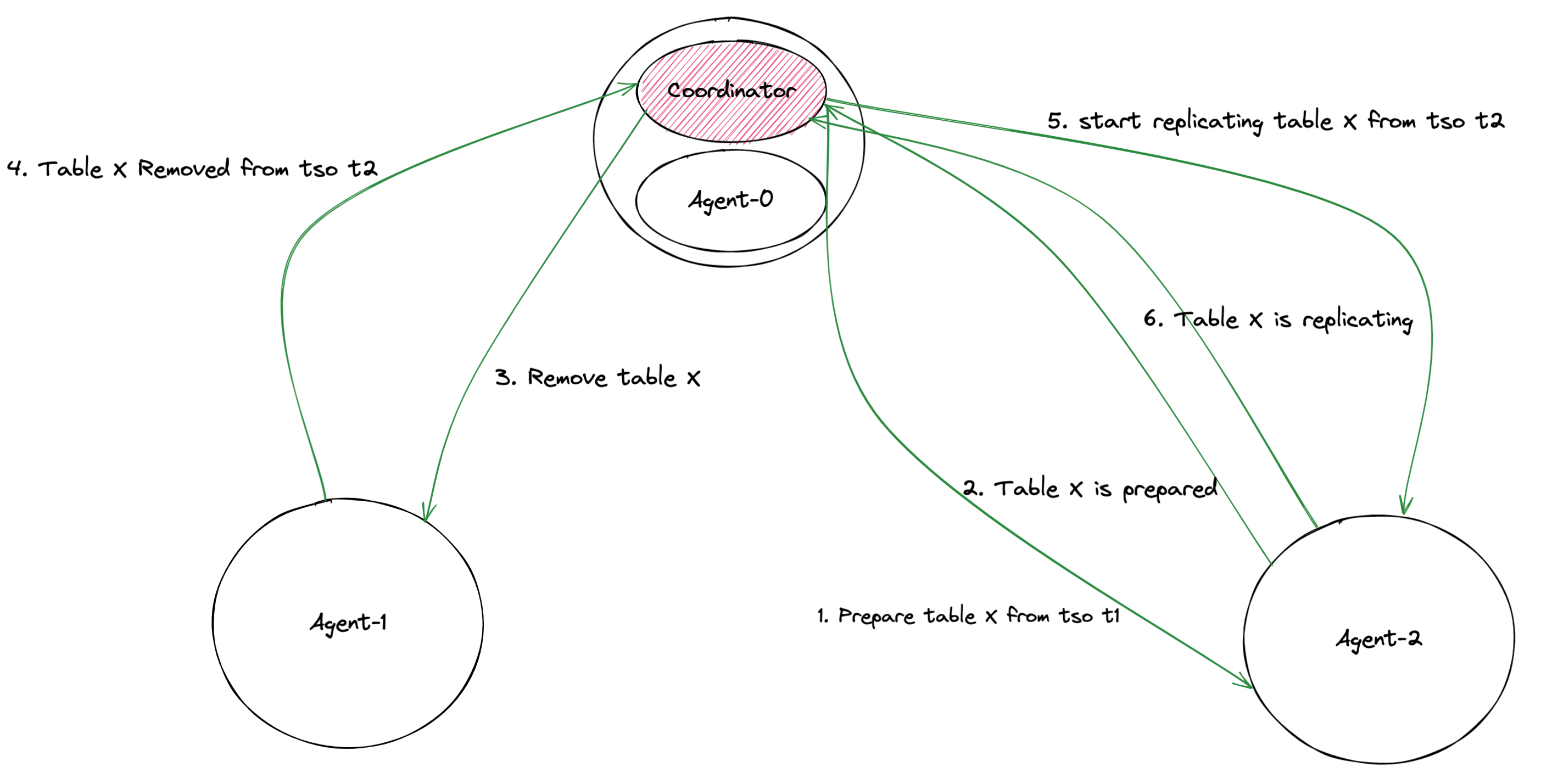
上图展示了将表 X 从 Agent-1 所在的 Capture 上挪动到 Agent-2 所在的 Capture 上的过程,具体如下:
- Coordinator 让 Agent-2 准备表 X 的数据。
- Agent-2 在准备好了数据之后,告知 Coordinator 这一消息。
- Coordinator 发送消息到 Agent-1,告知它移除表 X 的同步任务。
- Agent-1 在移除了表 X 的同步任务之后,告知 Coordinator 这一消息。
- Coordinator 再次发送消息到 Agent-2,开始向下游复制表 X 的数据。
- Agent-2 再次发送消息到 Coordinator,告知表 X 正处于复制数据到下游的状态。
上述过程的重点是在将一张表从原节点上移除之前,先在目标节点上分配相关的资源,准备需要被同步的数据。准备数据的过程,往往颇为耗时,这是引起挪动表过程耗时长的主要原因。两阶段调度机制通过提前在目标节点上准备表数据,同时保证其他节点上有该表的同步单元正在向下游复制数据,保证了该表一直处于同步状态,这样可以减少整个挪动表过程的时间开销,降低对同步延迟的影响。
Replication set 状态转换过程
在上文中讲述的两阶段调度挪动表的基本过程中,可以看到在 Agent-2 执行了前两步之后,表 X 在 Agent-1 和 Agent-2 的 Capture 之上,均存在表同步单元。不同点在于,Agent-1 此时正在复制表,Agent-2 此时只是加载表。
Coordinator 使用 ReplicationSet 来跟踪一张表在多个 Capture 上的表同步单元的状态,并以此维护了该表真实的同步状态。基本定义如下:
// ReplicationSet is a state machine that manages replication states.
type ReplicationSet struct {
TableID model.TableID
State ReplicationSetState
Primary model.CaptureID
Secondary model.CaptureID
Checkpoint tablepb.Checkpoint
...
}TableID 唯一地标识了一张表,State 则记录了当前该 ReplicationSet 所处的状态,Primary 记录了当前正在复制该表的 Capture 的 ID,而 Secondary 则记录了当前已经加载了该表,但是尚未同步数据的 Capture 的 ID,Checkpoint 则记录了该表当前的同步状态。
在对表进行调度的过程中,一个 ReplicationSet 会处于多种状态。如下图所示:
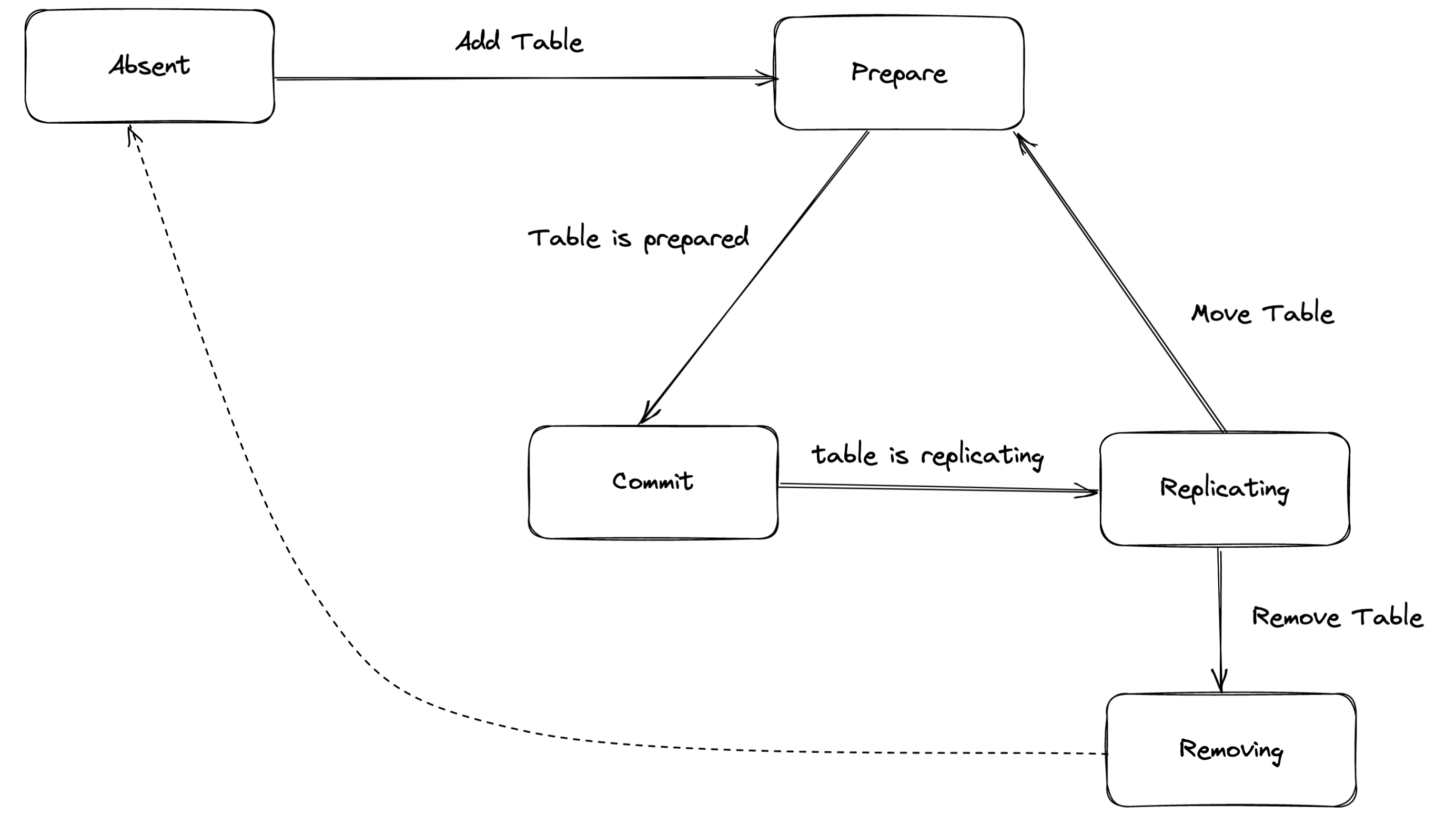
- Absent 表示没有任何一个节点加载了该表的同步单元。
- Prepare 可能出现在两种情况。第一种是表正处于
Absent状态,调用Add Table在某一个 Capture 上开始加载该表。第二种情况是需要将正在被同步的表挪动到其他节点上,发起Move Table请求,在目标节点上加载表。 - Commit 指的是在至少一个节点上,已经准备好了可以同步到下游的数据。
- Replicating 指的是有且只有一个节点正在复制该表的数据到下游目标系统。
- Removing 说明当前只有一个节点上加载了表的同步单元,并且当前正在停止向下游同步数据,同时释放该同步单元。一般发生在上游执行了
Drop table的情况。在一张表被完全移除之后,即再次回到 Absent 状态。
下面假设存在一张表 table-0,它在被调度时发生的各种情况。首先考虑如何将表 X 加载到 Agent-0 所在的 Capture 之上,并且向下游复制数据。
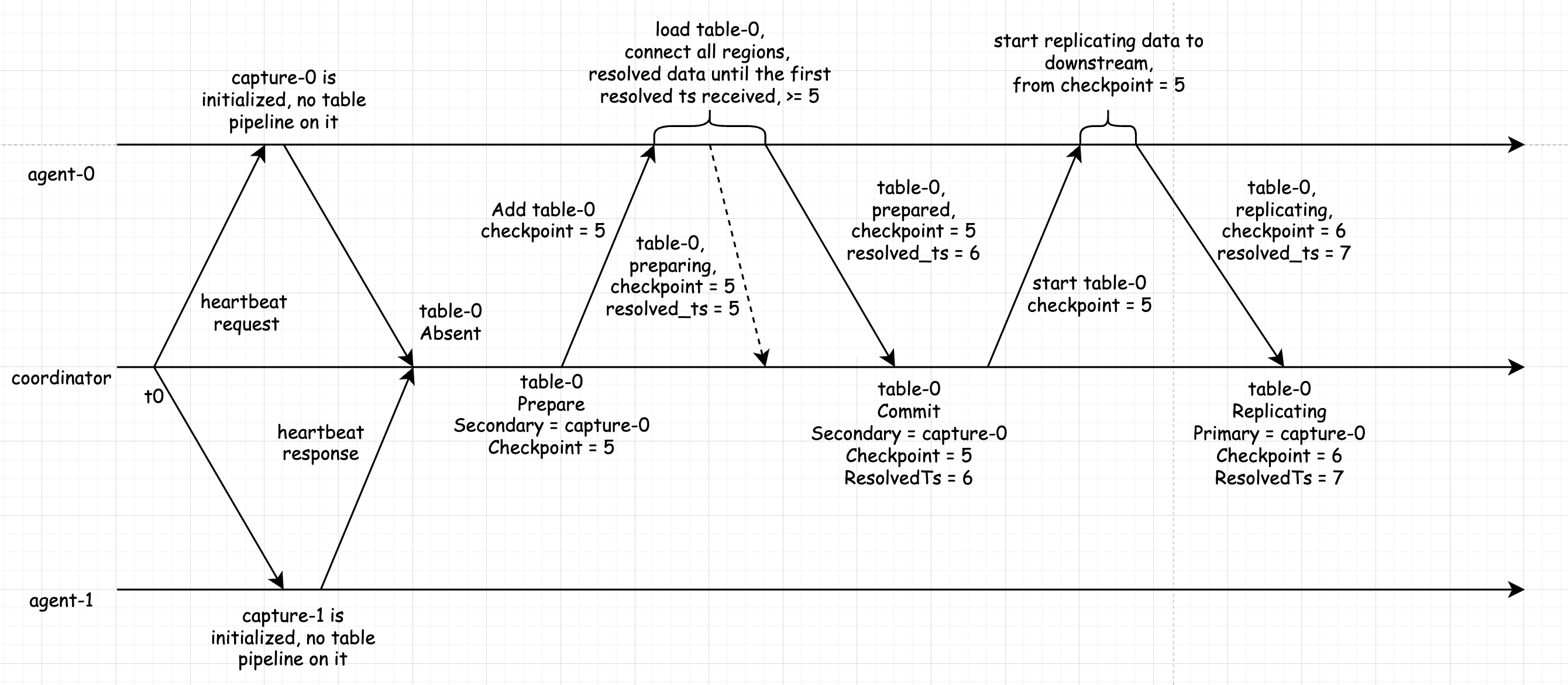
首先 table-0 处于 Absent 状态,此时发起 Add Table 调度任务,让 Agent-0 从 checkpoint = 5 开始该表的同步工作,Agent-0 会创建相应的表同步单元,和上游 TiKV 集群中的 Regions 建立网络连接,拉取数据。当准备好了可以向下游同步的数据之后,Agent-0 告知 Coordinator 该表同步单元当前已经处于 Prepared 状态。Coordinator 会根据该消息,将该 ReplicationSet 从 Prepare 切换到 Commit 状态,然后发起第二条消息到 Agent-0,让它开始从 checkpoint = 5 从下游开始同步数据。当 Agent-0 完成相关操作,返回响应到 Coordinator 之后,Coordinator 再次更新 table-0 的 ReplicationSet,进入到 Replicating 状态。
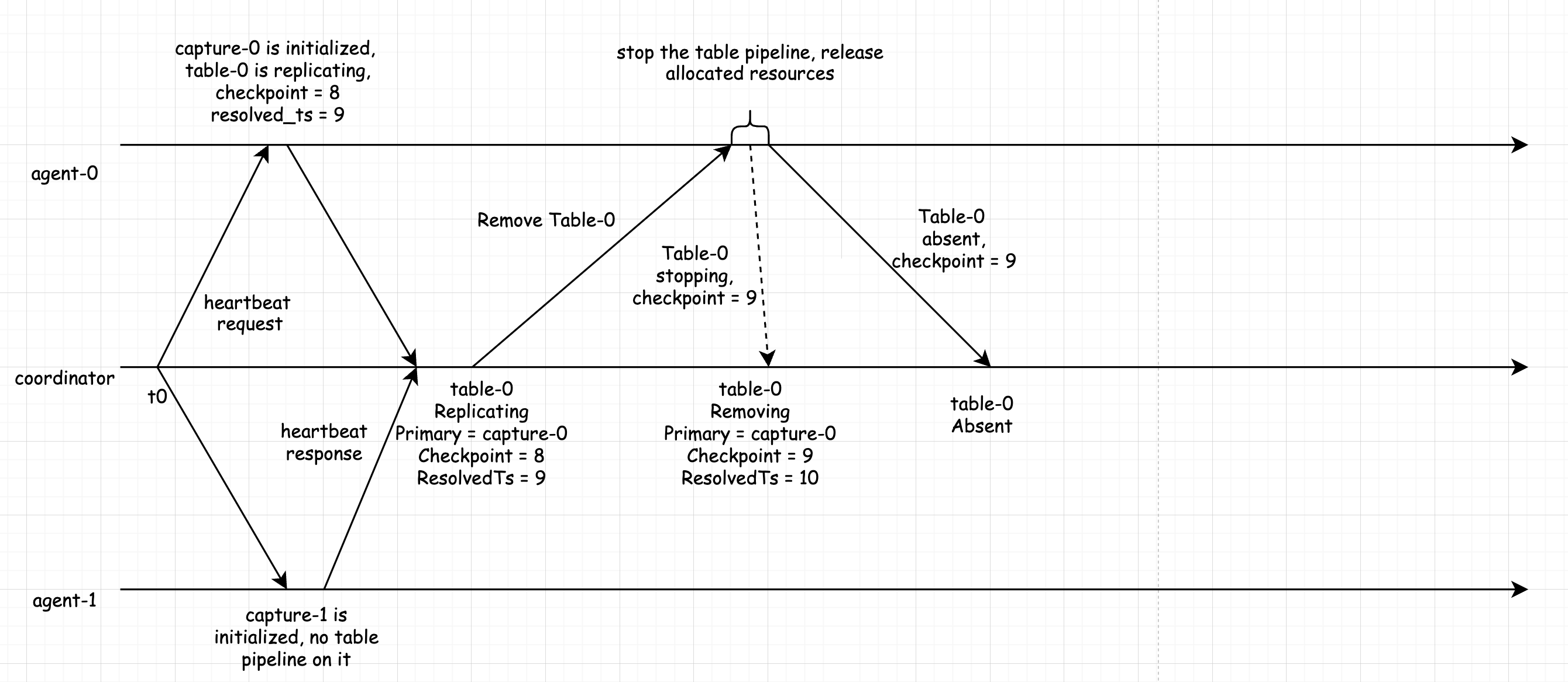
再来看一下移除表 table-0 的过程,如上所示。最开始正处于 Replicating 状态,并且在 Capture-0 上同步。Coordinator 向 Agent-0 发送 Remove Table 请求,Agent-0 通过 Processor 来取消该表的同步单元,释放相关的资源,待所有资源释放完毕之后,返回消息到 Coordinator,告知该表当前已经没有被同步了,同时带有最后同步的 Checkpoint。在 Agent-0 正在取消表的过程中,Coordinator 和 Agent-0 之间依旧有保持通过 Heartbeat 进行状态通知,Coordinator 可以及时地知道当前表 t = 0 正处于 Removing 状态,在后续收到表已经被完全取消的消息之后,则从 Removing 切换到 Absent 状态。
最后再来看一下 Move Table,它本质上是先在目标节点 Add Table,然后在原节点上 Remove Table。
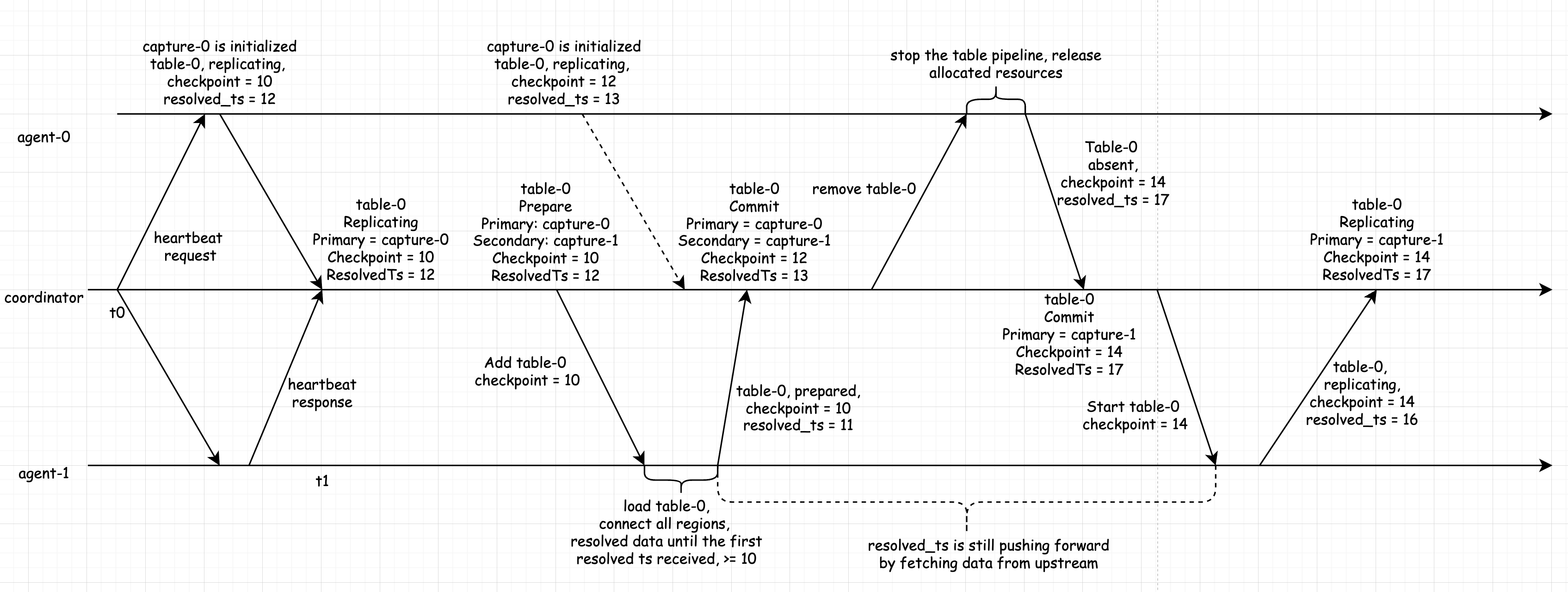
如上图所示,首先假设 table-0 正在 capture-0 上被同步,处于 Replicating 状态,现在需要将 table-0 从 capture-0 挪动到 capture-1。首先 Coordinator 将 ReplicationSet 的状态从 Replicating 转移到 Prepare,同时向 Agent-1 发起添加 table-0 的请求,Agent-1 加载完了该表的同步单元之后,会告诉 Coordinator 这一消息,此时 Coordinator 会再次更新 table-0 到 Commit 状态。此时可以知道表 table-0 目前正在 capture-0 上被同步,在 agent-1 上也已经有了它的同步单元和可同步数据。Coordinator 再向 Agent-0 上发送 Remove Table,Agent-0 收到调度指示之后,停止并且释放表 table-0 的同步单元,再向 Coordinator 返回执行结果。Coordinator 在得知 capture-0 上已经没有该表的同步单元之后,将 Primary 从 capture-0 修改为 capture-1,告知 Agent-1 开始向下游同步表 table-0 的数据,Coordinator 在收到从 Agent-1 传来的响应之后,再次更新 table-0 的 状态为 Replicating。
从上面三种调度操作中,可以看到 Coordinator 维护的 ReplicationSet 记录了整个调度过程中,一张表的同步状态,它由从 Agent 处收到的各种消息来驱动状态的改变。同时可以看到消息中还有 Checkpoint 和 Resolved Ts 在不断更新。Coordinator 在处理收到的 Checkpoint 和 ResolvedTs 时,保证二者均不会发生会退。
总结
以上就是本文的全部内容。希望在阅读上面的内容之后,读者能够对 TiCDC 的 Scheduler 模块的工作原理有一个基本的了解。
目录