导读
在 PingCAP 用户峰会 2023 上,PingCAP 联合创始人兼 CTO 黄东旭分享了“The Future of Database”为主题的演讲,介绍了 TiDB Serverless 作为未来一代数据库的核心设计理念。黄东旭通过分享个人经历和示例,强调了数据库的服务化而非服务化数据库的重要性,并展示了 TiDB Serverless 架构的创新之处,同时探讨了 TiDB Serverless 对于中国用户的价值。以下为分享实录。
作为今天上午的最后一个话题,相信大家已经感受到今天我们分享的最核心逻辑,跟刚才刘奇分享的我们部署一代、研发一代相承接,到我这部分就是未来的一代:预研一代。
因为今天会场有很多熟悉的老朋友,看到我这个标题肯定会心一笑,我每次在大会上的演讲都是这个题目:The Future of Database。选择这个主题一是我发现每次讲未来的东西都有东西可以讲;另外一点,很多老朋友发现我去年总是不时消失一段时间,怀疑我去闭关修炼了,我也跟大家汇报一下东旭去哪儿了。
Demo:我花了多长时间构建我自己的 OSSInsight Lite

分享之前给大家看看,刘奇的分享里面的这一页,把我 GitHub 个人数据分析的服务截图放上去了,这个小 demo 是我个人的挑战,我能不能完全做到不写代码,不去买服务器,完全用现代化的在线的云上的应用做一个我自己的数据服务。
在这个小的视频里边,我几乎全程只用了鼠标来操作,我想分享的点并不是让大家去学习这些技术,而是想让大家稍微体验一下现代的开发者构建应用的方式已经完全不同——门槛越来越低。
我经常会有一些天马行空的想法,比如我会想如果要给全世界的开发者都提供免费的数据库,这个成本得有多大?以现在的技术肯定支撑不了。那如果要做这么个东西的话,我们可能需要重新去思考数据库本身的一些最基础的东西。
一个人人可用的数据库服务有怎样的技术架构?

这是一些数据库厂商会说的老生常谈:扩展性、稳定性、用户线性的扩缩容、节省成本、多租户、云原生。
但是刚才我说的那些新的需求或者面向未来的数据库,可能对每一项都会有更高的要求。比如你的系统已经具备了一定的扩展性和稳定性,但更重要的是你能不能给用户一个稳定的性能的预期,我经常说一句话,稳定的慢比不稳定的快其实更好,可预测性对系统和底层的架构提出了更高的要求;第二就是现在几乎每个分布式数据库都支持弹性扩容,而更高的要求可能是,在做这些扩缩容的复杂操作的时候,开发者、DBA 都不需要去费心,数据库的扩缩容对业务来讲是完全无感的,体验非常顺滑;成本层面,我们再把成本压缩到极限——我能不能,不用的时候就不花钱?开源软件的分发上、下载不要钱,但是运行软件的服务器要花钱,现在我们再往前想一步,——数据库、服务器零成本的起步能不能支持;多租户上,我们过去要去强调互相的隔离,但是如果为了实现大规模的海量的免费的用户、中小型的敏捷的业务,不仅要强调隔离,还得强调资源的高效利用和共享;云原生是老生常谈,做到云中立就是进一步的目标。

我这边挑一个简单的例子,就从最近发布的多租户能力说起。如果把租户的规模从私有化部署的几十几百个,扩大到十万个、一百万个、一千万个甚至一亿个,平台如何去支撑这么大的租户数量,它需要哪些基础的能力,我们是怎么思考的?第一老生常谈,多租户一定要隔离;第二是刚才唐刘稍微讲了一下我们现在在研发的东西:资源管控,我们必须得实现一套很好的机制能够让海量用户更高效地利用和共享底层系统的资源,才能达到很低的成本;第三就是能区分,每一个用户在使用的体验上都必须能够感受到自己是在拥有整个数据库的。

之前有人问我 TiDB 支持多租户、多应用这种模式吗,我当时一直都是比较保守,通过几个大版本的迭代,我现在可以负责任的说,TiDB 要去实现现代的多租户,基础的能力都已经满足了。
TiDB Serverless:未来数据库理念的“概念车”
我们回到最开始的话题:如果我们要给全世界的开发者提供数据库该咋做?今天我就给大家说一下背后的概念车,把 TiDB Serverless 引擎盖掀起来大家看一看。
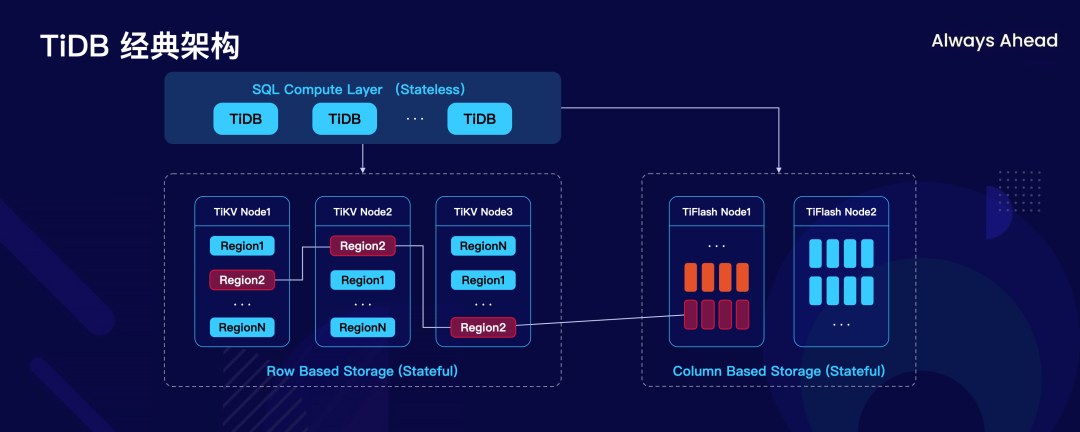
今天无数次讲到了 TiDB 的经典架构,然而如果把 TiDB 这个经典架构搬到云上,想实现“人人可用”这个目标,仅从成本上考虑,PingCAP 就得赔死了。

所以重新设计 TiDB Serverless 的时候,我当时定下了几个规范或者开发的哲学,其中最重要的一条就是我们应该做的是数据库的服务化,而不是服务化的数据库。
传统意义上来说我们要做云数据库,大家第一直观感觉,底下做个云管平台,每个租户部署一套 TiDB,把自动化的管控做完,这不就可以了吗?但是 TiDB Serverless 在这个方面,我们选择重新去思考一些非常基础的东西,刚才做云上运维 TiDB 的思路是行不通的,如果要做这么大规模这么新的东西的话,而且应该当做一个完整的服务去设计,而不是把它当做一个数据库去设计。
八年前一开始设计 TiDB 的时候,我看到的东西就是一台台具体的服务器,我看到的是 CPU、内存、磁盘,基于这些东西我们构造了 TiDB。但是如果我们现在在云上构建 Serverless 这个系统,拿到的是一张白纸,我今天重新再开始去设计这个系统的时候,我看到的已经不是 CPU、磁盘机器这样的东西了,我看到的东西是云上给我的服务,EC2、虚拟机,我看到的是对象存储,我甚至可以看到云厂商的 RDS,我能不能拿 RDS 作为系统的一部分,所以在新的云原生的工程哲学里边必须有一条能够充分利用云的基础设施,这也是我们能把成本推到如此极限的一个核心的思想。

掀开 TiDB Serverless 的引擎盖,大概有三个新的东西,第一个换了新的云原生的引擎 CSE(Cloud-native Storage Engine),非常朴素的名字。第二是终于在 TiDB 引入了逻辑上的 Key Space,第三就是 Resource Control 以及 RU 的概念,从上到下做全局流控。
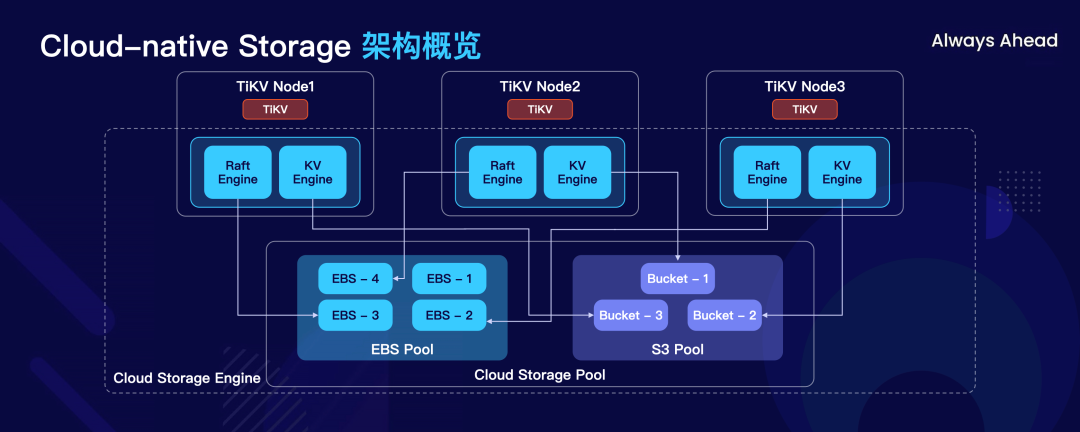
这是 CSE 整体的架构,核心就一点,它是一个极致的成本考虑下,极致的多租户背景下的新一代云上 OLTP 存储引擎。本质来说即使在之前的存储层,TiKV 这一层也开始做了存算分离,这就带来一个好处,比如有一些用户的数据是冷数据,因为我们在云上发现大多数的用户的业务和数据满足 82 法则,20%的热数据,80%可能是冷数据,但这些冷数据你在它不用的时候就可以按照流量的需求,直接 compact 到 AWS S3 这样云上更便宜的存储上面。AWS S3 存储的价格每 TB 每个月大概 20 美金,喝两杯咖啡就有一个月一个 TB 的存储空间了,这还是没有任何优惠的情况,实际上还可以更便宜。
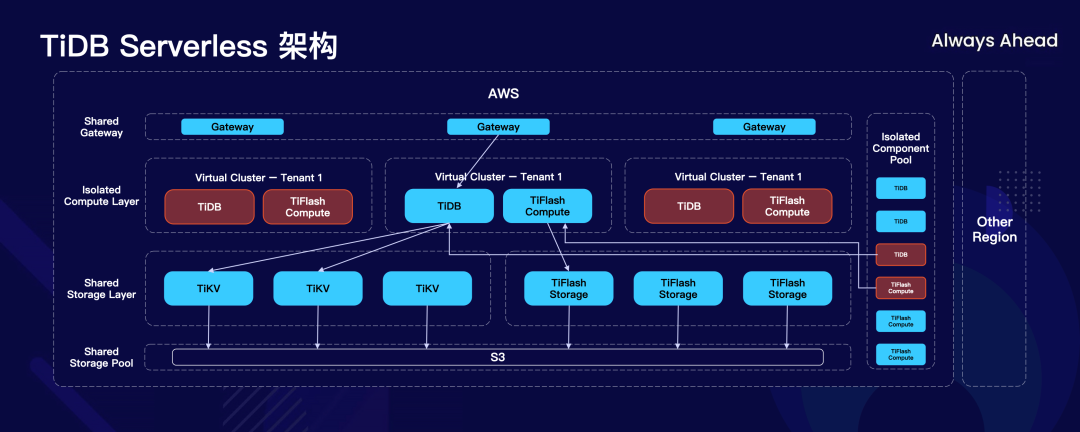
所以基于新的存储引擎,我们可以发现本身 TiDB 之上所有的组件一下子就变成了无状态的。当一个组件变成无状态了以后,怎么去降低成本?池化。
图中 TiDB 右边现在已经把所有的包括计算节点存储节点全都变成了池化的设计,最上面加入了一层 Gateway,用户直接连接到 Gateway,Gateway 负责对现在用户的请求从资源池中捞出一个活跃的节点,它不用的时候连接断开再放回去。
大家看这个图尤其是做系统架构多年的朋友会有个感觉,这个东西感觉不像一个数据库,反而像大型互联网公司后台的服务——有这个感觉就对了,因为我们在设计这个系统的时候就不是把它当做一个数据库在设计,而是把它当做一个真正的云服务在设计,所以才能达到极致的性能和成本的压缩。
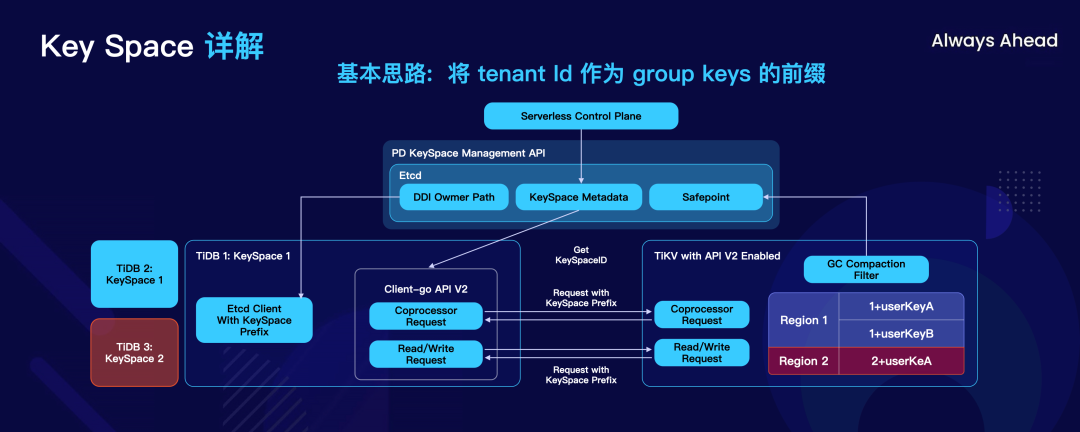
TiKV 是 TiDB 的存储引擎,所有的数据都是通过 key-value 来编码的,Key Space 本质上,就是在编码前面加上一个用户 ID 的前缀,将 tenant ID 作为 group keys 的前缀。
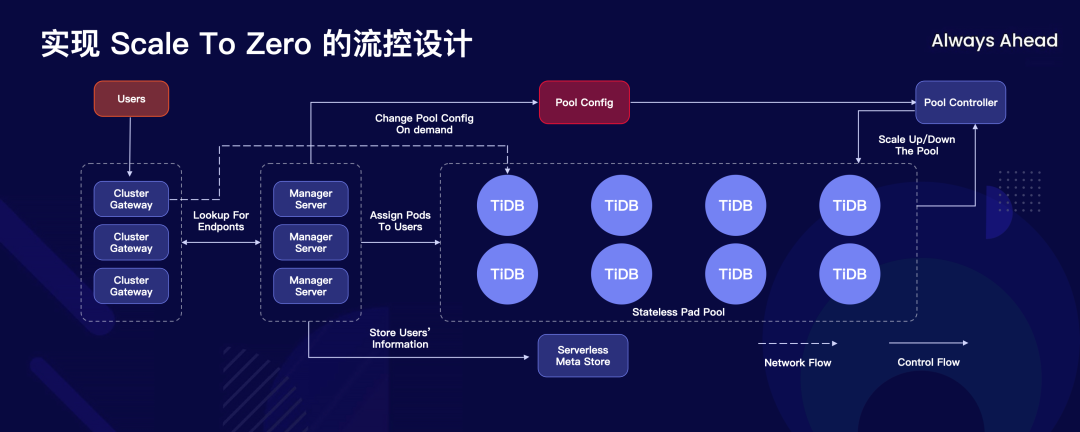
这张图解释了零成本起步,业务没有流量的时候就不收钱,本质上还是依靠池化来实现的。刚才我提到用户的连接都是连接到一层可以水平扩展的 Cluster Gateway 上,Gateway 来控制计算节点是否启用。如果这个客户的数据特别冷,十天半个月都不访问一下,这个数据完全存储在对象存储上,在对象存储上的成本是极其低的,在用户请求的时候再快速加载回来。这样一个架构保证了 TiDB Serverless 基础设施的成本会被均摊到所有用户身上,用户越多,数据量越大的时候,成本也就会越来越低。
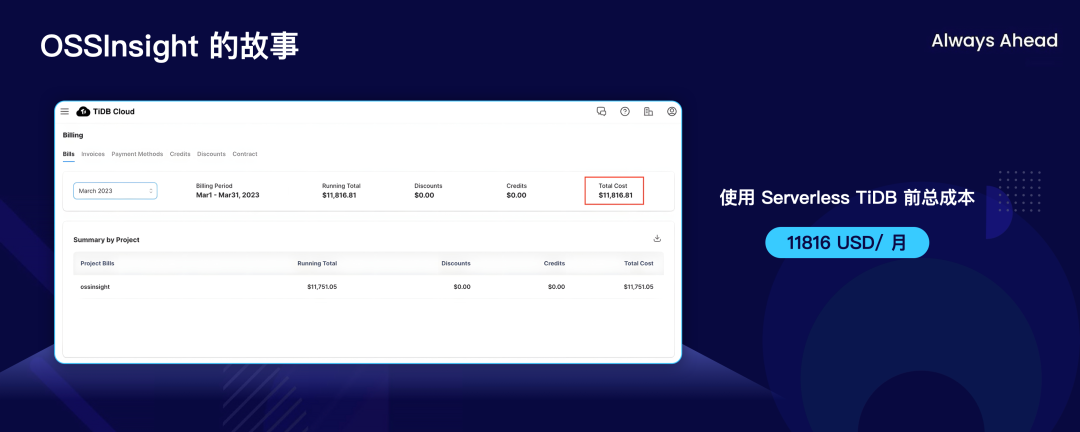
我最后分享一个小小的例子。我们公司内部也有自己用自己产品的习惯,这是我们自己的一些服务 demo,全部用 TiDB 自己构建。我们做了一个很有趣的工具叫 OSS Insight,把 GitHub 上的数据抓下来做分析的一个在线应用,这个在以前传统的 TiDB Cloud,也就是经典 TiDB 云上部署架构下,一个月的成本在一万美金左右,上图就是我们付给自己的账单。

同样这个业务今天已经接近 12 个 TB 了,这样一个巨型的数据库前一段把它迁移到 Serverless 以后,总体成本下降了 70%,而业务在使用层面上也完全没有任何的感知。
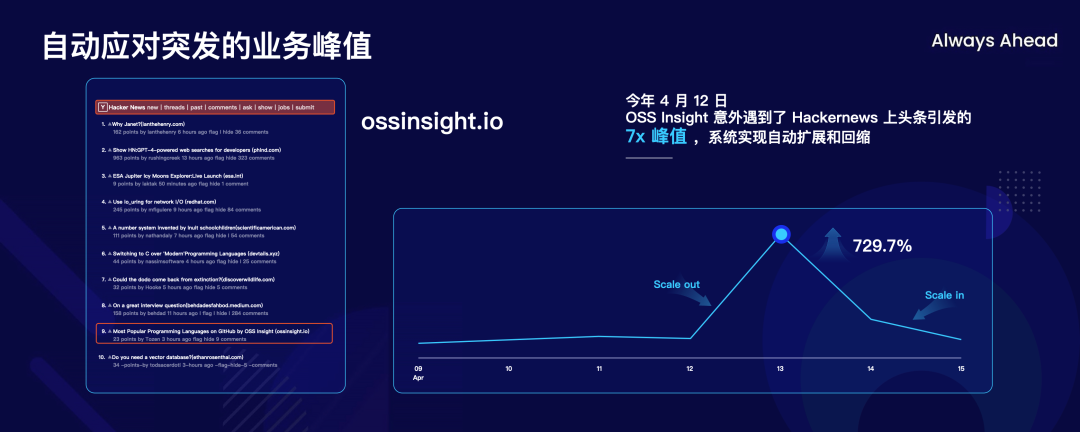
这里有一个很有趣的真实例子,刚才我们看到整体的 TiDB Serverless 的设计是面向弹性去做设计的,但是这种东西总是希望能有一个实际的例子去验证一下这东西是不是真的在现实生活中比较好用,我们也真的有了这样的机会。今年 4 月初 OSS Insight 成功登上了 HackerNews 的首页,流量一下暴增到原来的 7 倍,这个事情还发生在中国时间的深夜,我们的工程师都还在睡梦中,TiDB Serverless 自动发现了流量的突变把集群扩容,承担起 7 倍流量的业务负载以后,又自动缩回来,前端业务的各项指标都还是非常稳定的,也没有额外的收费。这是一个特别好的例子,我们也特别欣慰。

我今天分享了一些我们未来对数据库的看法,关于 TiDB Serverless,我还有三个点想强调。第一,虽然看到现在它是一个在纯云端的服务,但是我们有计划将更先进的架构服务于中国的客户,甚至你可以未来在私有化环境里面部署 TiDB 的 Serverless。因为我们设计这个系统内核的时候非常仔细的考虑了这个系统本身的可移植性,刚才这些东西未来大家会在自己的数据中心或者自己的云上去使用;第二,我个人认为这也是代表着数据库最前沿的发展的方向,就是云原生加上极致的弹性,我们在思考数据库本身的一些架构或者最底层的想法的变革都会遵循这个方向;第三点我个人觉得Serverless 是我们很好的练兵场,包括中国企业级客户我们预研出来的版本我们新的一些特性,最早会在 Serverless 上应用,比如刚才我说的 Key Space 这个功能,目前已经在 Serverless Tier 上实现了上万个用户的部署,经过上万个集群的打磨,很快也会在企业版和云上托管版本里边落地。
最后我想小小的总结一下今天我的分享以及我的一些感受。我也代表着 PingCAP,纵使大的经济环境充满各种不确定性,我们永远相信技术创新能够真正给业务带来价值,我也相信技术真正能够改变世界,所以我们相信未来永远是一个更好的世界。
目录