
导读
在金融领域,随着数字化服务的深入和监管要求的提高,反洗钱工作变得尤为关键。洗钱活动不仅威胁金融安全,也对社会秩序构成挑战。本文深入探讨了国产 HTAP 分布式数据库 TiDB 在某国有大行反洗钱系统中的应用实践。
依托 TiDB 构建的新一代反洗钱系统每日处理上亿笔增量数据和千万笔实时查询,管理着百 TB 级数据,架构上实现了高并发数据访问和多技术栈融合,提升了业务连续性和数据处理效率;有效地确保了金融交易的透明度和监管合规性,同时显著提升了客户体验。
引言
谈及“洗钱”,很多人认为它只出现在影视作品中,然而,洗钱活动可能就潜藏在我们的日常生活中,通过艺术品交易、跨境投资、赌博、证券交易等多种渠道进行。“反洗钱”是指为了预防通过各种方式掩饰、隐瞒各类犯罪所得及其收益的来源和性质的洗钱活动,依照反洗钱相关法规制定采取相关措施的行为。
业务挑战
银行经营模式正在发生重大的转变,金融服务呈现线上化、数字化、智能化等特点。在监管力度加大的背景下,监管部门对金融机构的反洗钱工作提出了更加严格的要求,包括严格核实客户身份、详细记录和妥善保存客户及交易信息、主动监测并及时报告可疑交易、以及定期进行风险评估和采取相应措施等,给反洗钱工作带来了巨大的挑战。
- 监管范围与数据存储跨度不断扩展
监管要求金融机构在反洗钱工作中,需根据客户特性或账户属性,合理评定洗钱和恐怖融资风险等级,并据此执行相应的控制措施。同时,金融机构必须确保历史交易记录的完整性与准确性,例如部分跨境汇款业务记录,至少需保存五年。
- 上报时效性和数据准确性要求不断提升
监管机构对交易数据的上报时限提出更高要求,如 5 至 10 个工作日内完成报送(部分场景要求 T+1 日数据报送)。金融机构需采用高效的数据处理方式以满足时效性要求,并实现复杂的识别与监测规则,进行大量量化指标的计算。
- 监管规则变更频繁
面对不断创新的业务模式,反洗钱系统需采用规则引擎来配置灵活的监测模型,对数据进行筛选、分析,并生成反洗钱报告。系统设计需确保在监管规则变更时,能够迅速适应,避免因技术限制如“分片键”阻碍业务规则的及时更新。
某国有大行原有的反洗钱业务系统基于多个数据技术栈和异构数据库构建,存在高开发维护成本、OLTP 与 OLAP 混合处理能力的不足、大规模弹性存储和高可用性缺失,以及数据时效性差等问题。为了解决这些问题,行方重新构建了一套服务全球业务的反洗钱系统,基于国产 HTAP 分布式数据库 TiDB,创新性地融合了流式计算与批量处理,支持高并发数据访问和在线交互式多维查询,实现了多技术栈的融合,并确保了业务连续性。
新一代反洗钱业务的构建
业务架构
反洗钱系统**事中系统**:主要面向客户发起交易的实时监控,即通过接口方式接收上游联机系统的交易请求,登记并实时进行规则集匹配(如累计交易中涉及客户送检交易和历史交易的金额、笔数),若匹配则生成案例信息,最终将处理结果实时返回调用方。该系统属于关键业务系统(数据 5 副本),并搭建灾备集群。反洗钱事中业务包括联机和批量业务,按业务维度包括客户尽调、交易尽调等模块。
客户尽调:涉及的数据表包括客户信息表 6 亿、客户评级历史表百亿(存量 6 年)、案例表(规模 10 亿)。日间交易约 70 万笔,以客户维度插入或更新客户信息表。批量转联机模式以联机接口形式处理,瞬时并发会较高,主要是基于客户号维度的操作,包括客户信息表的 insert、update 操作,以及案例表作为驱动表与其它多张表的关联。批量计算功能基于交易记录、合并后的客户信息表、以及其它表通过关联的方式计算结果集,计算维度多,结果集会放大,预期当日内完成。
交易尽调:涉及的数据表包括:以交易表、案例表、拦截信息表、行为类报文表为主(其中数据规模在亿级,行为类表数据量更大)。业务功能包括对柜员提供拦截信息表的写入和更新类操作;对柜员提供灵活的数据查询,涉及多表关联,包括表单形式的分页查询、以及轻度 AP 类聚合查询为主。
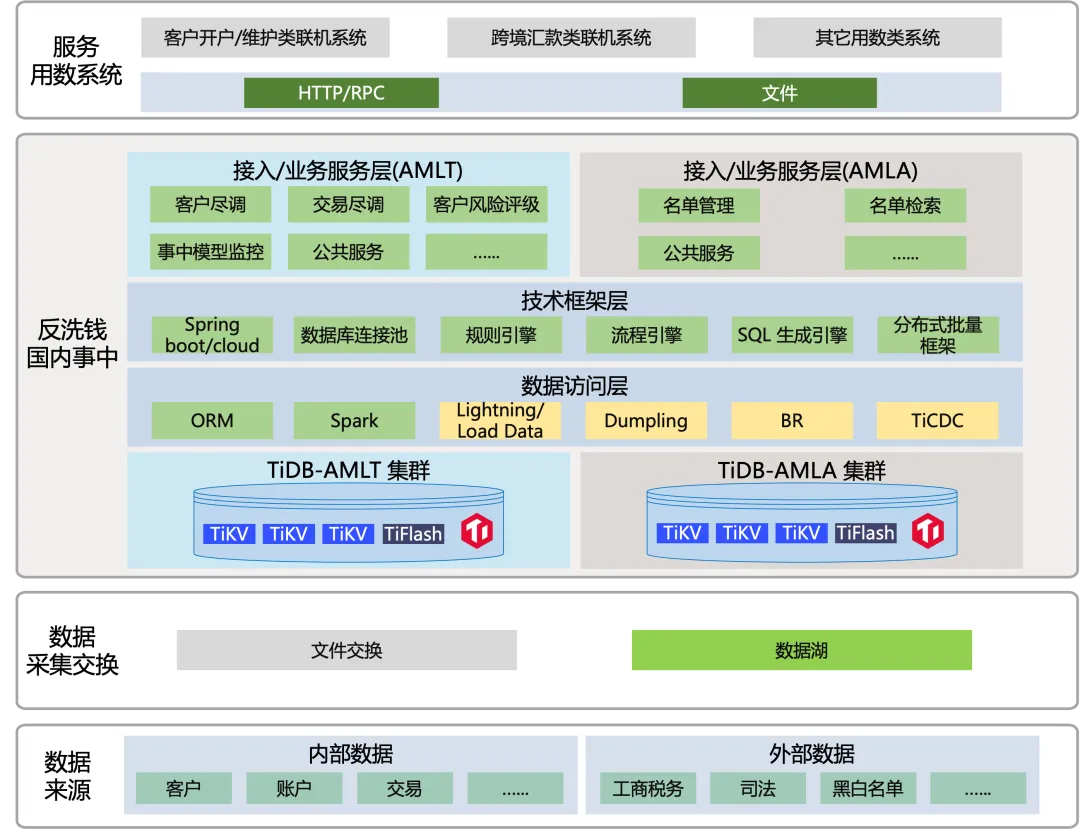
数据架构
如上图所示,反洗钱国内事中部分按业务领域垂直拆分为联机交易、批量分析两部分,分别对应独立的 TiDB 分布式数据库集群,每套集群包含了 TiKV 行存和 TiFlash 列存两种存储引擎。
-
AMLT 集群:主集群五副本配置,对应联机交易部分,即客户尽调、交易尽调、公共服务等模块,以客户维度联机、内部前端场景为主。主要应对客户开户、维护场景的尽调,以及跨境汇款类交易的尽调。批量行为以 T-1 日客户信息、交易信息合并入主表为主。
-
AMLA 集群:主集群三副本配置。对应批量分析部分,即 SS、公共服务模块,以内外部名单加工批处理为主的数据消费类系统,加工结果表用于内部业务人员的在线灵活查询。因涉及内外部黑名单,故系统重要程度也较高,必须确保业务连续性。
-
外围系统:包括了近百个上游联机交易类系统,通过 API 接口方式将符合反洗钱门槛的交易进行送检和筛查。
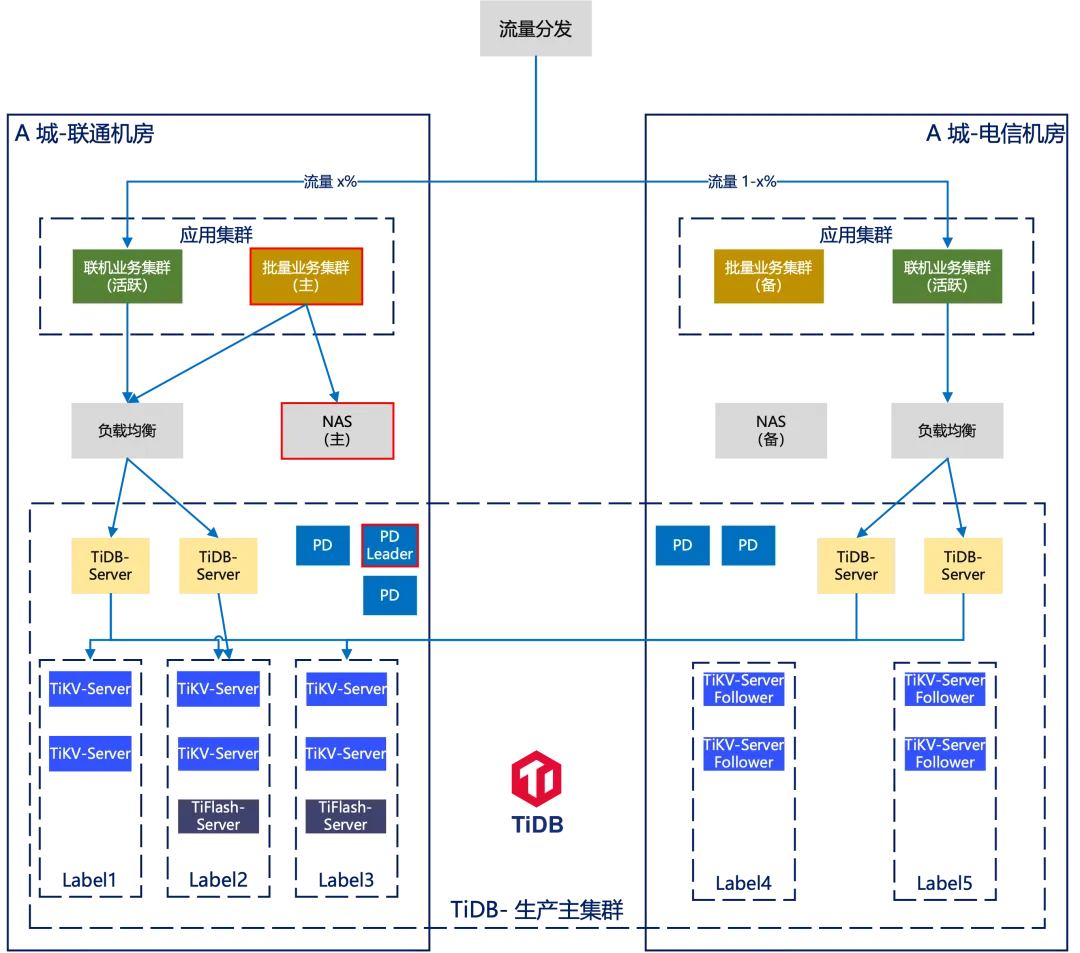
数据库集群部署
行方在 A 城市跨机房部署 TiDB 主集群,在 B 城市部署 TiDB 灾备集群,主集群采用同城双机房 3+2 模式部署。
-
联机采用双活模式,应用侧双机房都会有实际的业务读写流量,相关表可采用双机房均匀分布 leader 的方式。
-
重点关注的是批量作业,应用侧数据迁移、日常数据加载、批量处理、数据导出,优先将纯跑批涉及的表绑定单边 leader,保证应用、TiDB leader 副本亲和性访问,TiFlash 副本也是同理,可有效降低跨机房网络流量。
-
对于联机、批量都会使用的表,若使用 TiKV 且不涉及复杂 join、子查询等场景可维持现状,也可根据实际业务情况按需开启就近读功能。
应用成效
新一代反洗钱业务系统对接了全行近百个上下游系统,存储了百 TB 级数据,在支撑日均上亿笔增量数据、千万笔 T+0 实时查询的基础上,实现了超长跨度查询、以及更完整准确的交易全景视图,大幅提升了移动互联时代全天候、多样化、高时效的综合数据服务能力和客户体验。
- 高并发能力大幅提升了业务查询分析效率
得益于 TiDB 的高并发、高吞吐特性,确保了预期目标的顺利实现,同时系统展现出良好的读写性能和稳定性,没有出现延迟或故障问题。
- 可弹性水平扩展提升了数据库计算、存储能力
TiDB 的原生分布式架构支持按需灵活扩展计算能力,并且集群的扩展过程对应用程序完全透明,简化了运维管理,有效解决了单机 Oracle 容量告警的难题。
- Spark 高速数据库读写引擎,大幅提升了批处理计算效率
Spark 组件提供索引支持,多种计算下推使 Spark 能够高效的读取 TiKV 中的数据,可大幅提升批处理业务的性能,Spark 还提供了海量数据的更新功能并保证更新事务的原子性。
- 高效的数据写入实现数据快速导入
支持上游 Hive 数仓推送文件载入,在 Spark 批处理并行直写 TiKV 的技术加持下,数据导性能得到了大幅提升。
延展阅读:
- 金融行业内容专区上线,为金融机构数据库选型和应用提供深入洞察和可靠参考路径。立即浏览
目录