
本文整理自网易互娱资深工程师, Flink Contributor, CDC Contributor 林佳,在 FFA 实时风控专场的分享。本篇内容主要分为五个部分:
- 实时风控业务会话
- 会话关联的 Flink 实现
- HTAP 风控平台建设
- 提升风控结果数据能效
- 发展历程与展望未来

众所周知,网易互娱的核心业务之一是线上互动娱乐应用服务,比如大家耳熟能详的梦幻西游、阴阳师等都是网易互娱的产品。不管是游戏产品还是其他应用,都需要做出好的内容来吸引用户进行应用内购买,进而产生盈利。
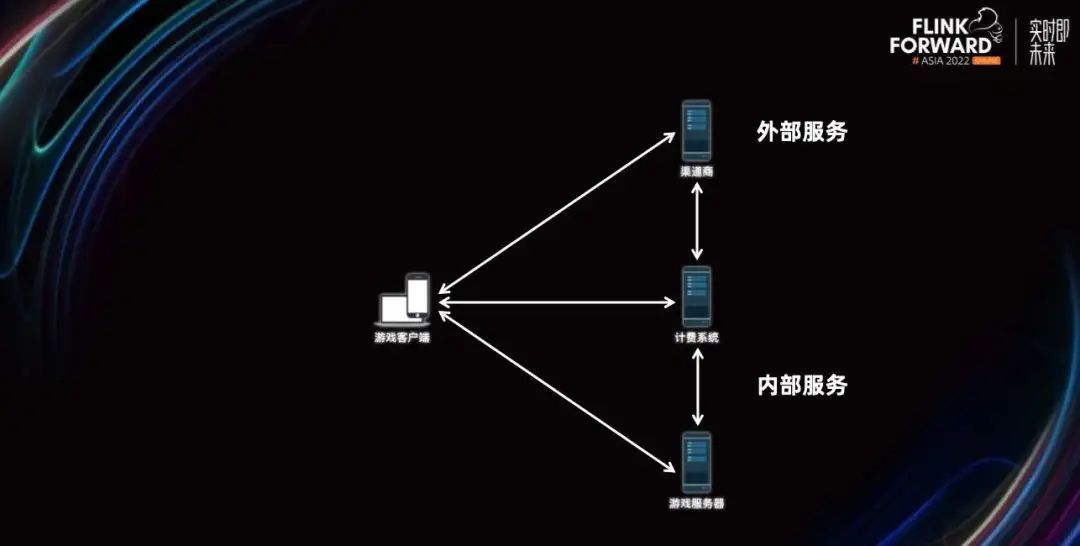
当用户在商城里点击商品进行购买的时候,会弹出支付界面,进行验证、支付后,就可以收到道具了。这个过程对于用户来说往往都是一些非常简单的操作,但为了保证这个过程可以正确结算、发货,整个支付流程其实跨越了很多服务提供商和终端,走了一条相当复杂的调用链路。这些不同的业务节点之间会产生很多相互的调用关系,进而产生一些异构的日志、数据、记录。
由于经过了网络,其中的数据可能会有一定时间水位线的不一致、延迟,甚至数据丢失的情况,且本身这些数据又很可能是异构的,就更增大了我们对这些数据进行分析和使用的难度。
如果我们需要用这些数据进行高时效性的故障排查或者风险控制,就势必需要研制一套方案,来适配这样技术需求。为了解决以上的问题,我们以 Flink 为计算引擎构建了一套实时风控平台,并为他起名为 Luna,下面我将为大家进行详细的介绍。
实时风控业务会话
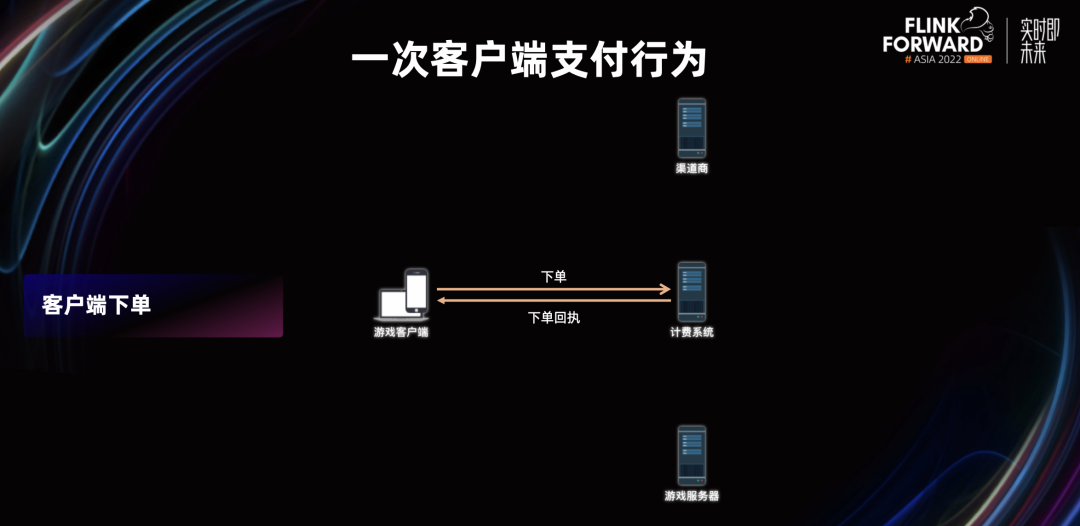
常见的线上支付逻辑是,当用户在应用上点击商城的道具进行应用内购买的时候,用户的客户端终端就会到计费系统进行下单,获得本次下单的订单信息。
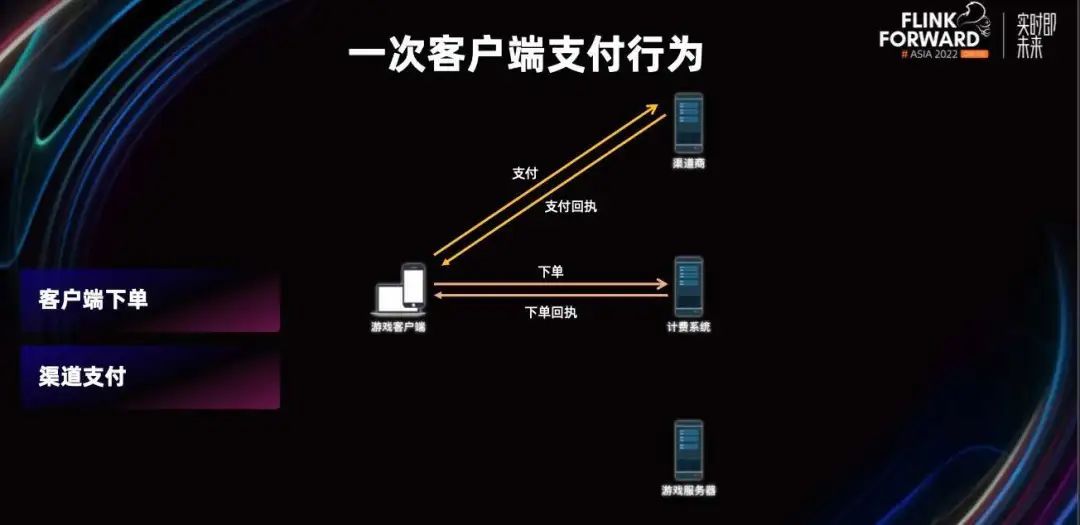
然后我们的客户端会弹出支付界面,用户进行渠道付款。
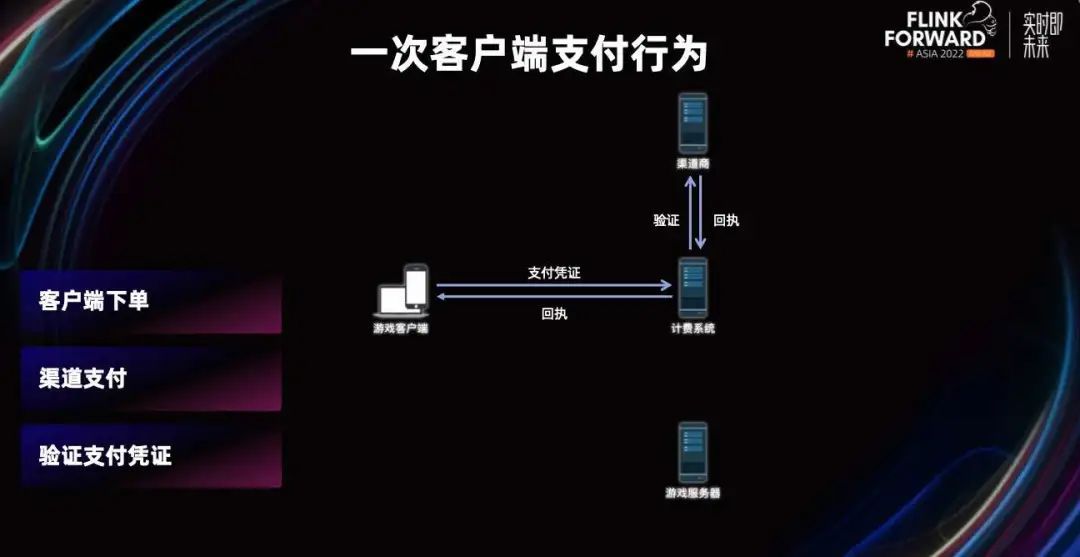
当支付完成后,我们会把渠道返回给客户端的支付凭证回传给计费系统,计费系统会去渠道验证凭证是否有效。
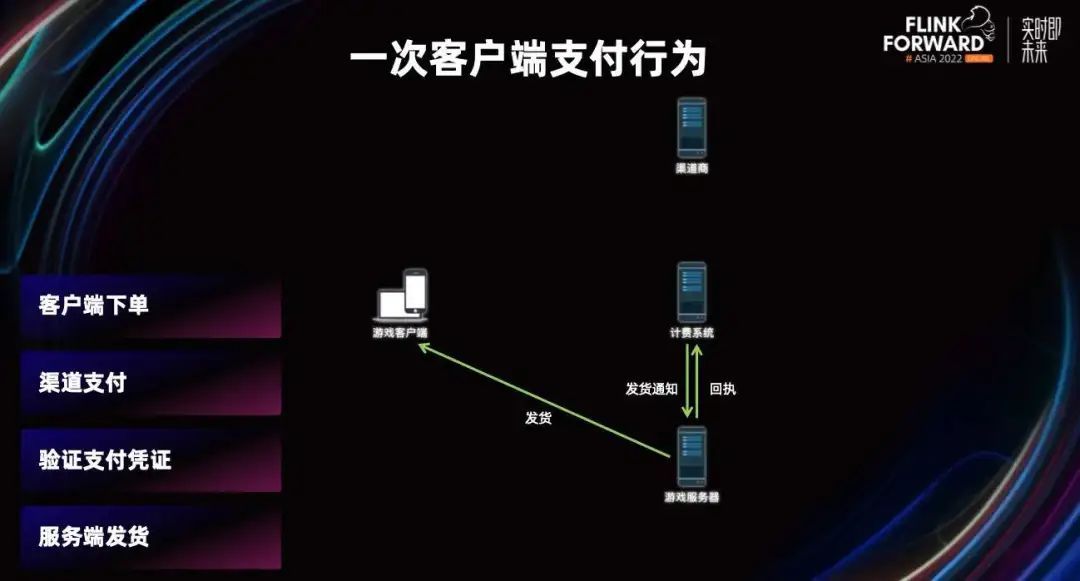
如果是有效的,就会通知游戏服务器发货,这个时候我们的客户端才会收到道具。这就是从用户点击到最终收到道具的整个流程。

从这个已经极度简化了的支付模型可以看到,不同的公司、服务提供商、部门、服务系统会产生了一系列会话下的数据。如果我们能把这些数据收集起来,进行一定的处理后,还原当时用户操作的现场。这将对运营运维人员在定位故障、排查故障,甚至整个业务环境的宏观分析都有着非常重要的价值。
而分析的关键点是,我们如何还原这个行为的现场,我们把这个行为的现场叫风控业务会话,即由一次用户行为所引发的,需要多个系统协作完成、同时触发多个请求、产生跨越多个服务提供方调用的全过程。
这里需要注意的是,业务会话跨越了多个相互独立的请求链路,且没有统一全局的 trace-id 可以被提前置入所有的数据中。

由于我们的业务会话需要跨越多个请求链路,所以在数据关联分析的时候就存在很多难题。比如
- 多服务、多请求产生的异构结果难以直接关联。
- 调用顺序复杂,存在并发、异步的情况。
- 时间跨度大、业务水位不同步。
以前在解决支付丢单、支付一次重复发货等问题的时候,往往只能通过运营人员去处理,这就非常依赖于运维人员的经验了。并且在这些大量的数据里,会有非常多冗余和无用字段,还有可能会有一些非常复杂的嵌套关系。这些都有可能让运维人员在判断时产生错判和误判。此外,还会给运维人员带来非常多的重复性工作,从而使得人力能效低下,把时间浪费在重复的事情上。
前文也提到了开源 Tracing 方案,往往需要依赖全局的 trace-id。对于新的系统,我们可以提前设计 trace-id 打点。但是对于有历史包袱的系统来说,他们往往不愿意修改跟踪来跟踪打点,那么这个时候传统的方案就走不通了。

在这种情况下,如果我们要进行业务会话还原,就需要设计一套新的方案。这套方案我们希望可以具备以下功能:
- 实时微观业务会话检索与查错。
- 实时宏观业务环境统计与风控。
- 业务会话级数据能效挖掘与提升。

从还原业务会话到使用数据做 HTAP 实时风控平台的全过程,我们使用 Flink 消费原始数据,根据平台上提前配置好的分析模板,实时还原出业务会话。然后把业务会话的结果存储存起来,并为它打上我们提前设置好的一些结论模型,产生的风控结论。
对于存储起来的这些微观会话进一步被聚合,进而产生整个业务环境上的宏观统计量,以支持我们在整个平台上的风控分析需求。
会话关联的 Flink 实现
Flink 是实时计算的实施标准,基于此我们毫无疑问地选择了它。

那么实时业务会话关联在 Flink 系统上,我们希望可以做出怎样的效果呢?
- 第一,零侵入。即无需对现有业务进行改动,也无需有全局的跟踪 ID,就可以做到业务会话的还原。
- 第二,跨数据源。因为我们的业务往往需要跨越 n 种数据源,所以我们希望这 n 种数据源都可以被这个系统所支持,比如日志、维表、事实表、REST 接口等。
- 第三,实时。实时产生结果,无需等待 T+1。
- 第四,低代码。我们希望基于分析需求,可以通过向导式的配置,来产生实时的分析模板,并对宏观统计报表,可以配置式的进行多维度聚合。
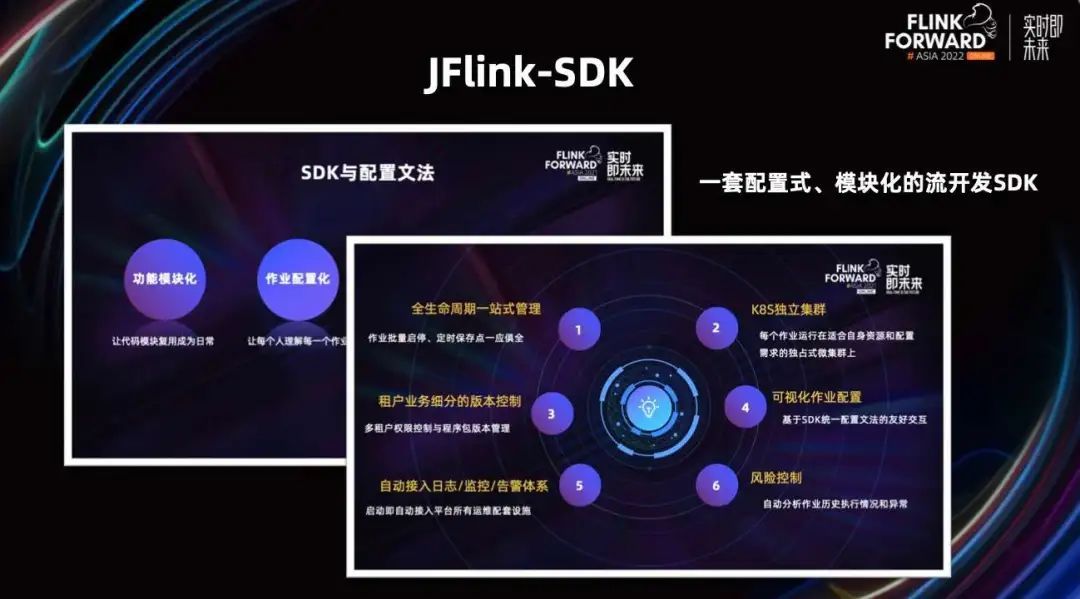
上图展示的是 JFlink-SDK,它是网易自研的一套流管理平台以及它的开发手脚架 SDK。大家可以把它理解成是一套可以模块化配置式开发的流作业手脚架,实时关联分析的引擎就是基于这套手脚架开发出来的。
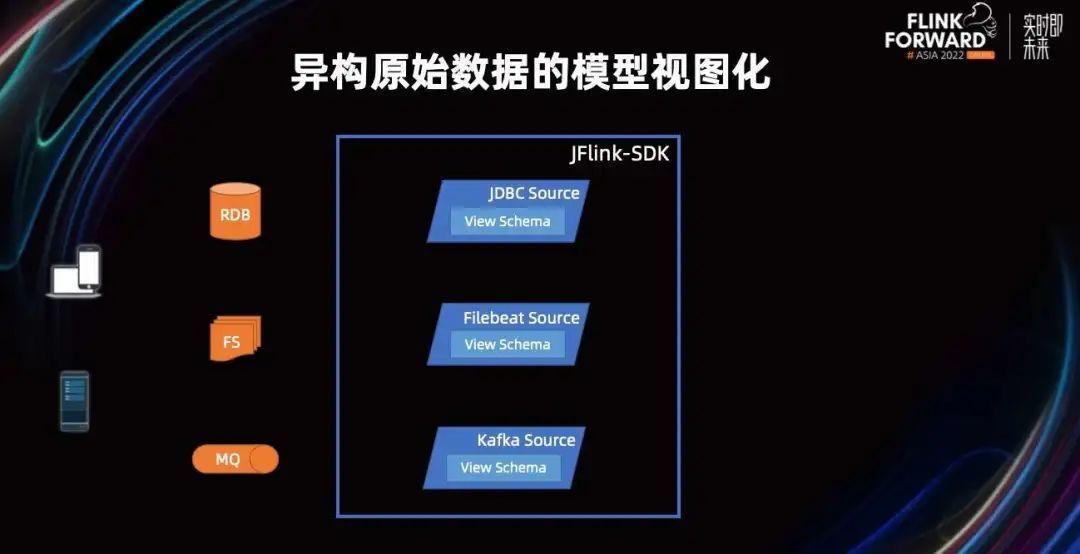
回到在使用业务会话还原的问题上。来自各个数据源的数据业务点,通过各种方式被同步收集到数据仓库的存储层中,我们有多种数据存储收集这些数据。针对各种各样的数据存储,Flink 有非常丰富的 connect 可以进行消费。然后 JFlink-SDK 又对它进行了二次封装,定义异构数据。使其在读取到 Flink 的时候,可以被转化成统一的视图。
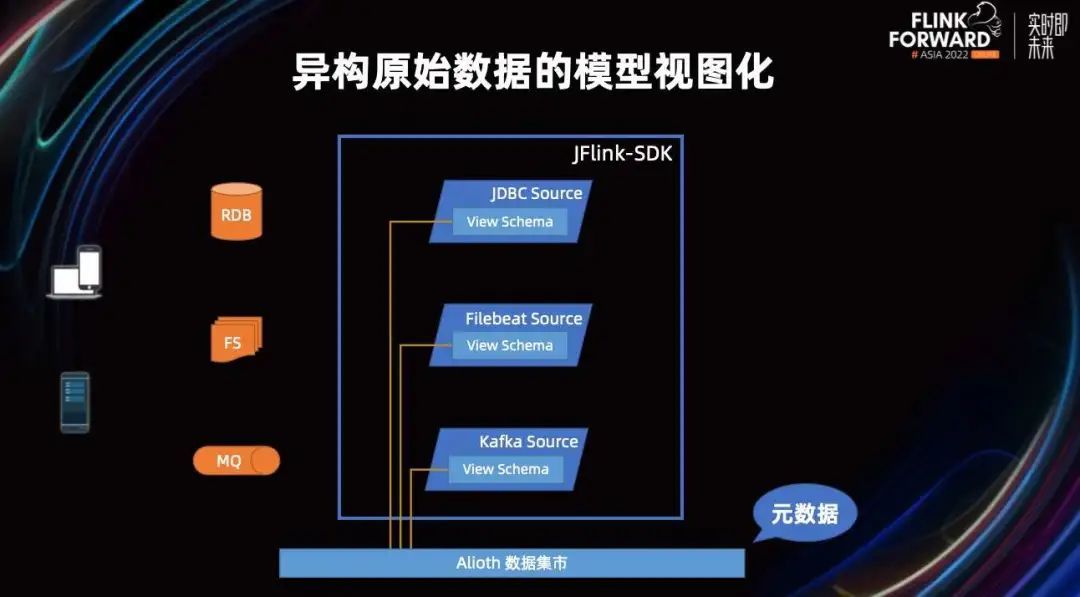
这些数据视图是我们提前建设好的一些数据治理系统和平台,数据治理系统会为 JFlink-SDK 提供数据读取的规范。
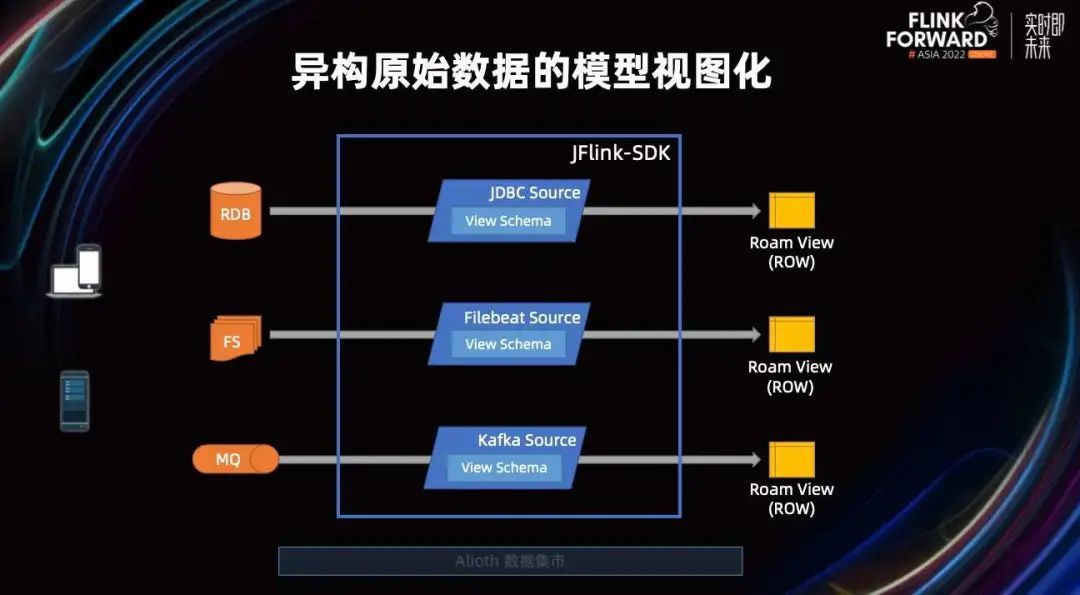
当通过 SDK Source 读取后,他们就会被统一转化成业务视图,这样就非常方便我们后续对这些原始异构的数据进行关联了。
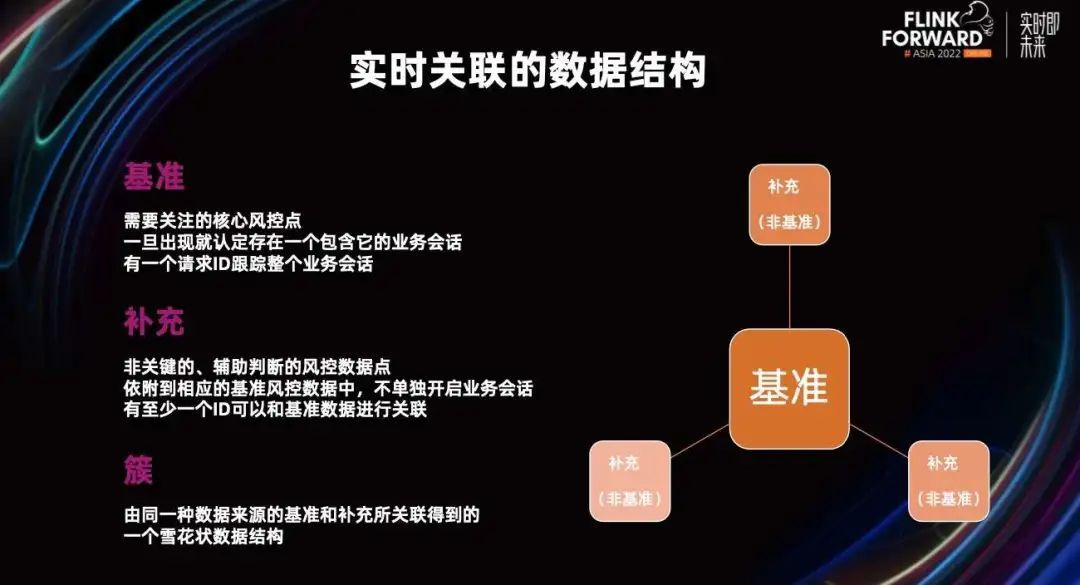
它的数据结构是以基准和非基准共同构成的一种设计。在进行业务数据点关联的时候,它的基本思想是基准+补充。所以我们在选择业务时,会选择最为核心的风控阶段作为基准,也就意味着,基准是整个业务中最关键的步骤,可以用唯一的 ID 关联起来。
对于通过业务 ID 关联起来的基准,我们会形成一个类似图的数据结构,这个东西我们称之为基准簇,它由同一种数据来源的基准和补充所关联得到的一个雪花状数据结构。
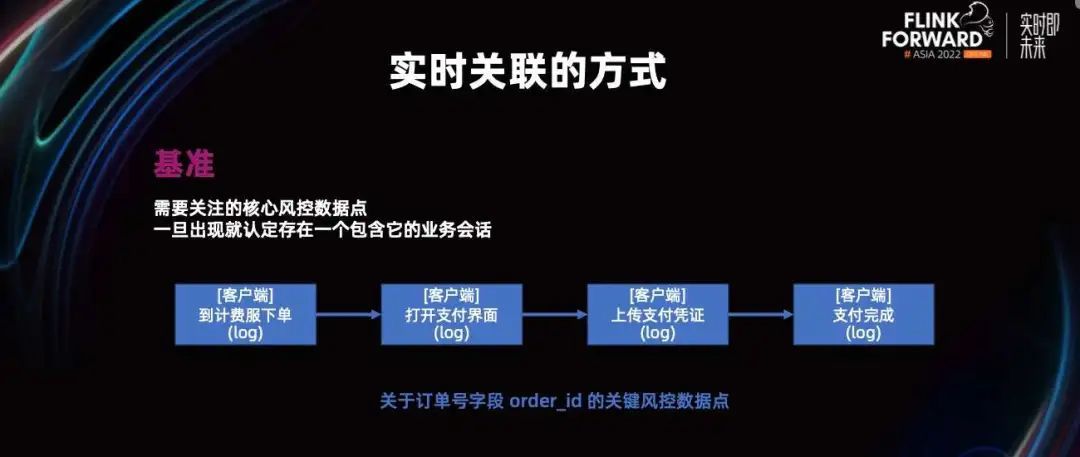
基准是业务会话中最关键的步骤,它通常是公共携带的某种标志步骤。比如以计费下单为场景,客户端的下单,打开支付界面、上传凭证、支付完成是四个最为关键的步骤。他们都打上了执行这些步骤的订单号,这四个步骤就可以作为整个业务规划的核心步骤,也就是基准。因为数据是不按顺序到达的,所以出现这是个步骤中的任意一个我们都可以开启业务会话。
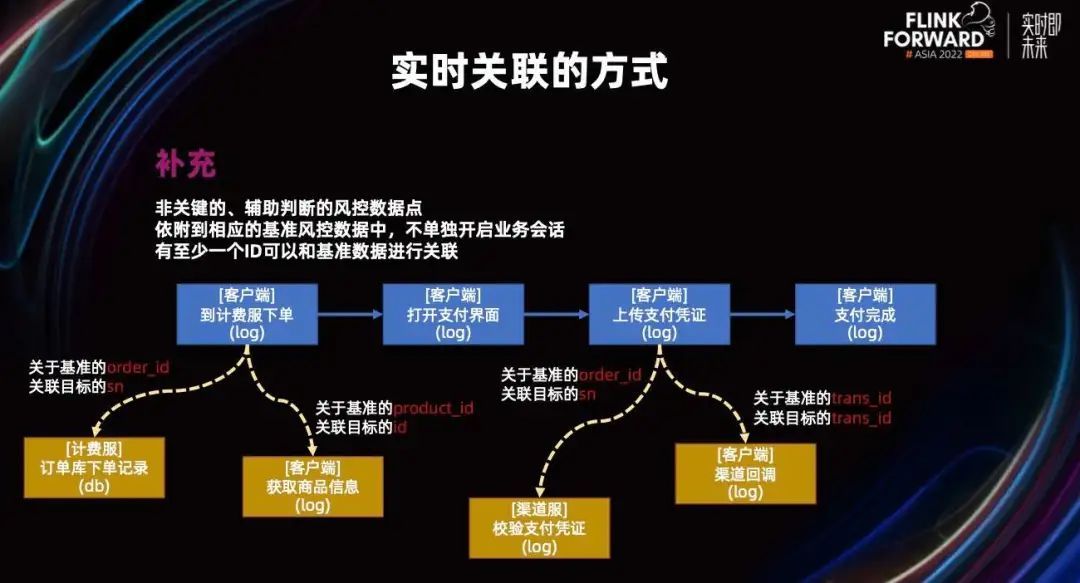
而下单记录、商品详情、渠道回调记录等等一些辅助性的数据,他们对问题定位起不了关键作用,而且它们可能没有基准中订单号的字段,所以就没有资格被选为基准。
但它们中也有一些字段可以和基准中的字段进行关联。比如渠道回调日志,渠道商在一些辅助性的数据上打了 trans_id 字段。它虽然没有 order_id,但它可以通过 trans_id 与基准中的 trans_id 建立一一映射的关系,也就是我们可以通过 trans_id 关联起这份数据与基准簇的关系。
所以通过基准+补充,我们就可以解决目前线上系统,无法为所有数据打上统一 ID 埋点的痛点。
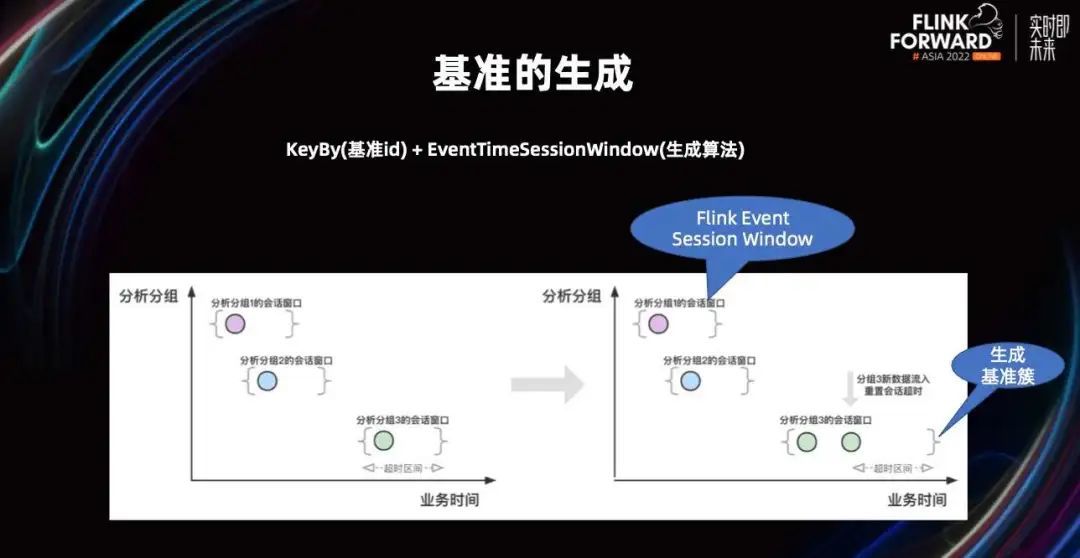
在 Stream API 中基准关联的实现,我们使用的是 Session Window。它是 Flink 提供给我们的标准时间窗口之一,可以在有数据流入的时候进行窗口时间超时的重置。除此之外,如果整条流的业务水位线,越过了整个超时时间的边界,它就会触发窗口计算。这种结果就非常适合由用户触发的会话窗口,也适合我们基准数据构造的逻辑。
但用户引起的这种行为,往往时间是不固定的,所以带有属性的会话窗口就非常适配这种特性。比如风控业务会话的还原,和浏览商品到最终下单支付的整个支付应用轨迹的追踪,都非常适合用这种模式来进行窗口计算。
这里的 Flink Session Window 其实就是前文提到的构造完毕的基准簇,它包含了所有被关联进来的原始数据,以及按照一定规则处理好的二级字段。至于它怎么在关联的时候进行字段抽取呢,后续再来讨论这个规则,此处就先认为,在窗口完成的时候就把簇计算出来了,并完成了所需字段计算和抽取。

一般用户的支付意愿窗口往往在 10~20 分钟,如果我们直接使用 Event Time Session Window 来进行计算,就会发现如果用户很快完成了下单,但系统仍然需要等待 10~20 分钟,才能使会话窗口进行计算,这就大大降低了数据的时效性。
对此 Flink 也为我们提供了一口入口,我们可以自定义窗口的 Trigger 来设置窗口触发的时机和业务会话提前结束的判定。
举个例子,一些数据量极少的场景,它的水位线可能一直没有向前推动,这种情况我们就可以加上 Process Timeout 和 FIRE & UPDATE 语义。这就可以让业务会话在水位线没有推进的情况下,先进行计算,往后发送。然后在下游进行保证,即当上游重复 fire 的时候,可以进行 update 的语义。
再举个例子,我们可以在风控的分析模板中配置一下。当业务会话满足某些条件的时候,就不用再等待超时了。比如当所有的节点都被关联上时,如果继续等待也不会等到任何节点,这个时候就无需等待超时时间,可以立即 fire 出结果。
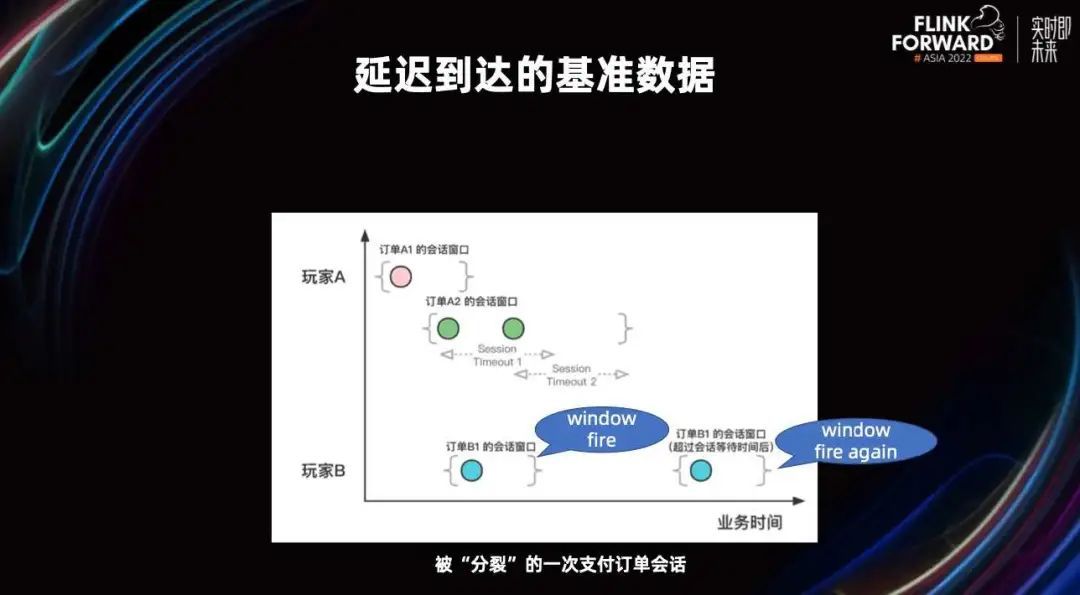
当业务会话存在一些特殊且极端的情况,比如客户端支付到一半崩溃了,等了非常久才起来,这个时候很可能就会被拆分为两个业务会话,因为前一个业务会话已经超时了。这种时候我们会选择把两个被分裂的会话 fire 出来,然后由运维人员进行合并或者保持原样。
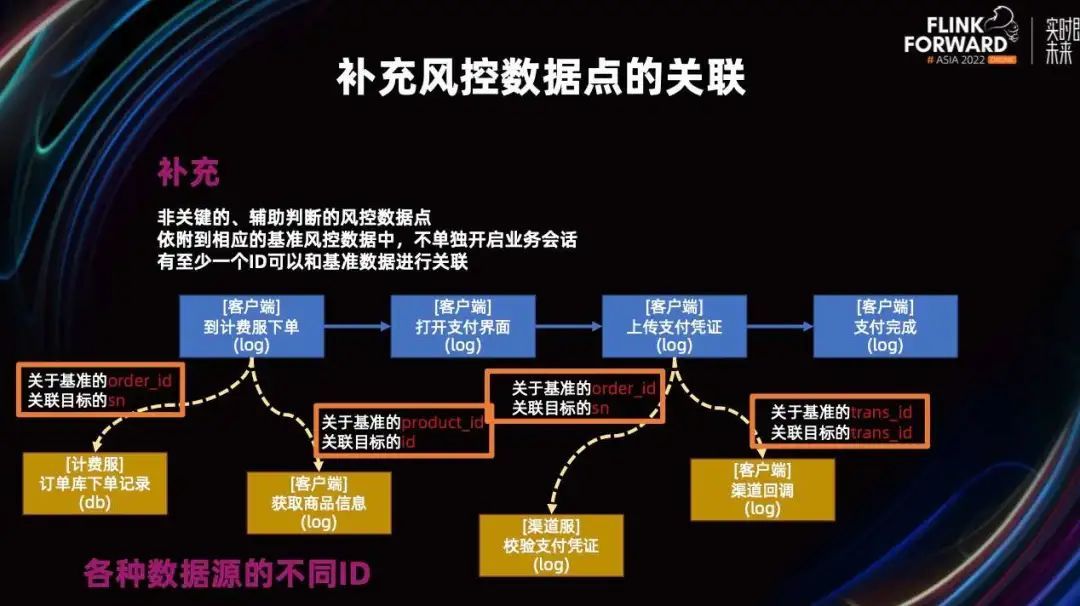
接下来我们来讨论一下,对于补充的数据我们又是如何构造的。基准数据拥有公共 ID,所以它们可以被 Key By 到数据窗口里进行计算。但是补充数据点往往是各自用各自不同的 ID 进行关联,所以这个时候我们就可以类比数据库里的多表 join 了。不同的补充数据就类似于一张不同的表,通过不同的字段与基准数据簇进行 join 操作。

这就是我们遇到的挑战,它不仅关联字段不同,水位线的推进速度也很可能不一样,这都是无法把它们两者放到同时间窗口中计算的关键因素。
那么如何去解决这个问题呢?如何基于扩展的基准先进知识,关联回没有公共 ID 的补充数据呢?这正是整个解决没有公共 trans_id 还能形成会话的关键所在。
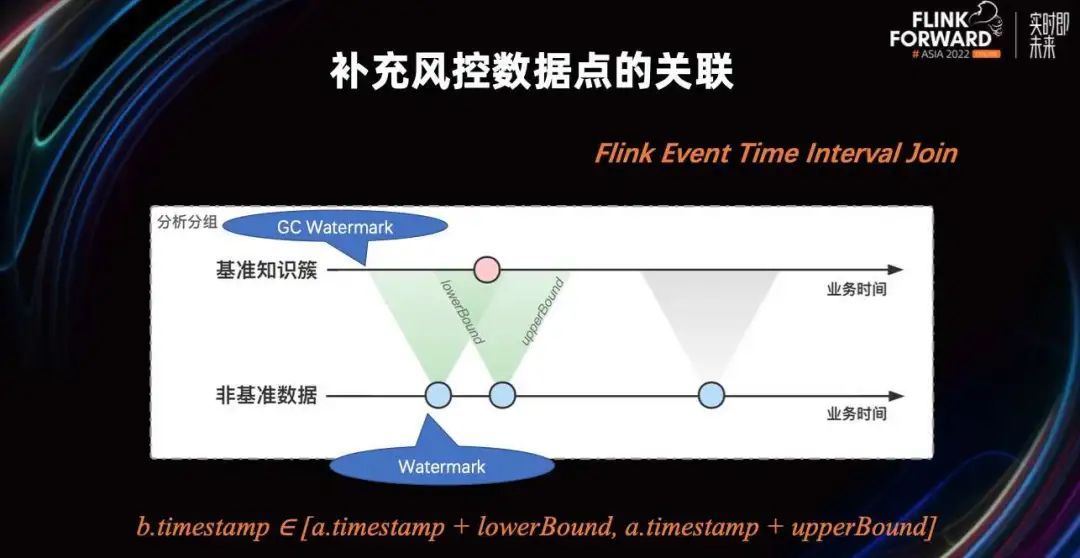
类比 join 操作,Flink 已经为我们提供了非常好用的算子,叫做 Interval Join。即两种输入数据分别取自己的特定字段作为 key,然后通过这个 key 把他们分到同一分组上,进行时间区间内的 join。
Flink Event Time Interval Join 是把当前流和对手输入流里,指定上下边界的区间内数据进行 join,这种特性就非常适用于我们这种场景,因为当我们从基准数据簇中取一个字段,和从非基准的补充中取一个字段,如果它们等值,那就意味着它们属于同业务会话,它们应该进行关联。
这个时候就可以用 Interval Join 算子进行关联,而且 Interval Join 不会打开时间窗口,因为每条流的 GC Watermark 是根据对手流加上我们提前配置的边界时间区间来进行的,这种结构就非常适合两种数据流时间水位线推动不一致的情况。
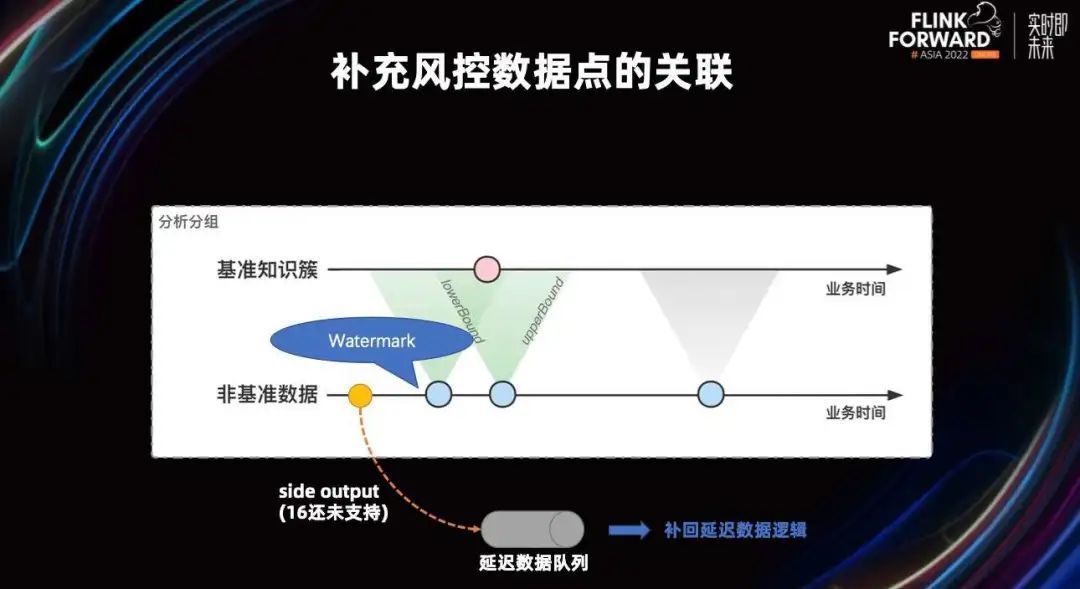
但是还有另外一种情况,就是当某一条数据来源有延迟的情况下,这笔数据会被丢失,这是 Flink 1.16 正式版之前的情况。在 Flink 1.17 版本中,社区的小伙伴已经把这个代码合并进去了,后续很期待在新版本中使用这个功能。
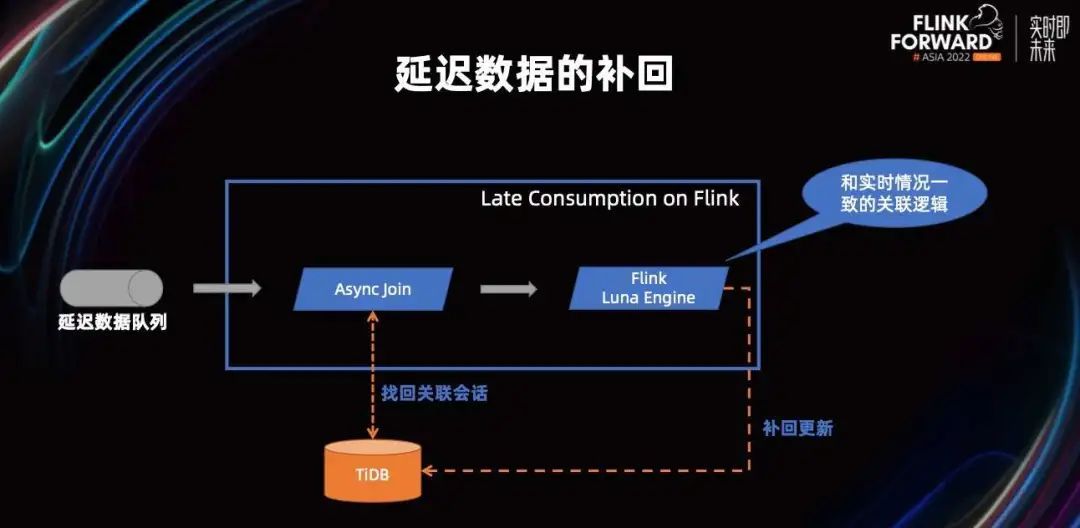
当数据延迟进行补回的时候,我们的处理方式是,把延迟数据和当时关联的上下文,放到消息队列里,通过流重新消费出来,并根据当时关联的上下文,重新从数据存储里把写进去的会话查回来,然后用同样的逻辑重新把这笔数据补回更新,写回数据库。
这样整个过程中无论是实时关联,还是延迟数据的补回,用的逻辑都是完全一样的,保证了我们处理逻辑的简洁和一致性。
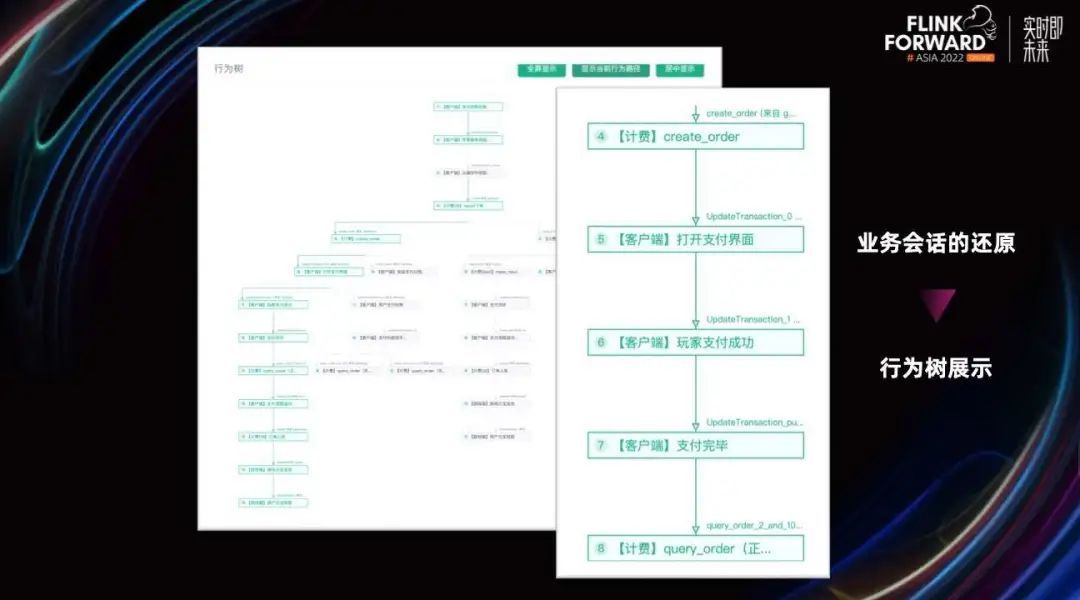
最终我们用 Flink 实时关联出来的业务会话会被存储起来以供检索,并通过 Luna 平台以行为树的形式进行展示。
HTAP 风控平台建设
当我们完成了算法可行性测试,并使用 Flink 实现了技术原型后。接下来就是如何把这一整套框架平台化,使其成为便捷、准确、丰富的风控平台。

风控平台需要做到以下这些功能。
支持微观排障,可以具体查询某一笔订单、业务会话当时的业务场景,把它还原出来;支持从宏观上统计整个环境的各种数据量。且配置和查询都需要是自助、向导式的。
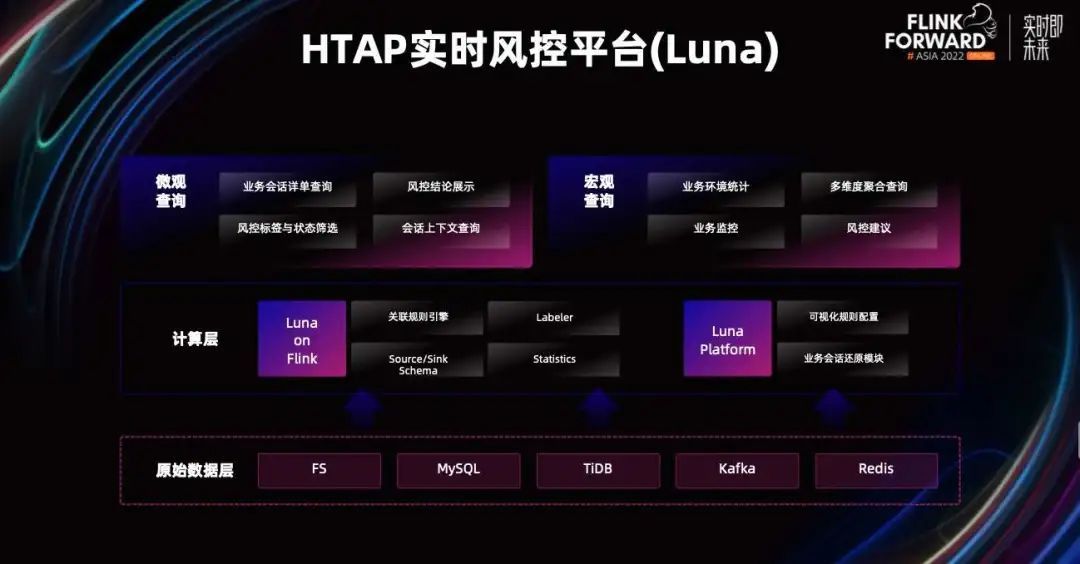
基于以上的考虑,我们设计了 HTAP 实时风控平台 Luna。基于这个平台,用户就可以自己从各种异构数据源中选择,配置业务行为树和分析模板。然后平台会根据配置好的模板,起 Flink 流算出业务会话的结果,形成会话结果存到存储层。且支持用户从平台上进行条件检索,进行多维度的聚合。
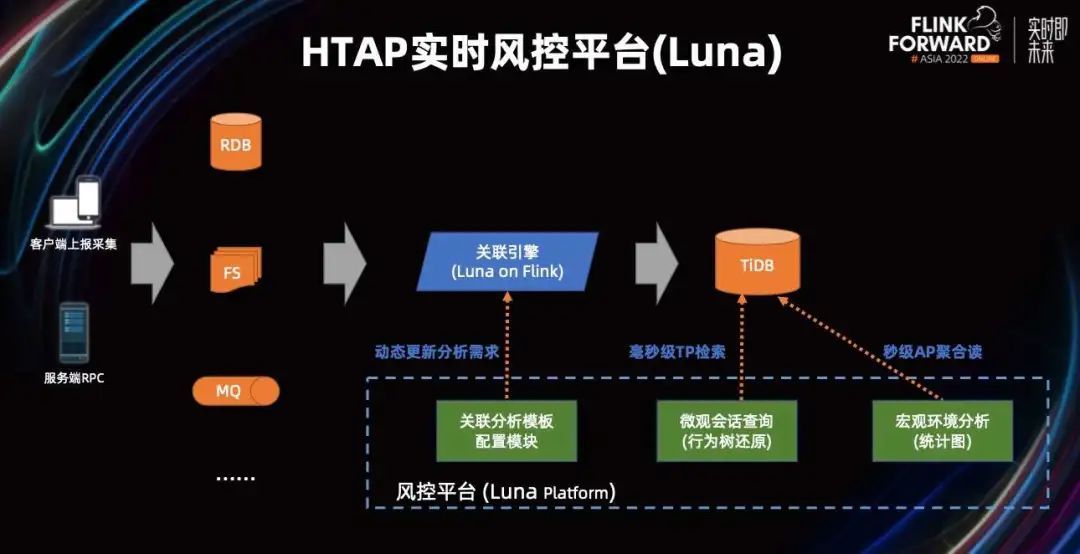
分析模板的配置我们是做了自动更新,也就是所有平台上的更新都无需人工运维。
从上图中可以看到,核心组件是计算层的 Flink,加上存储层的 TiDB,加上我们自己基于 JavaScript 的平台服务系统。目前可以达到微观查询是毫秒级,多维度的风控聚合结果在年级别都可以做到秒级查询。

我们的平台支持,用户从不同的数据源中选出,需要参与这一次关联分析的数据和关注抽取的字段进行配置。配置好后,Flink 会根据这些配置,自动生成出 Flink 的 Source 和 Sink。
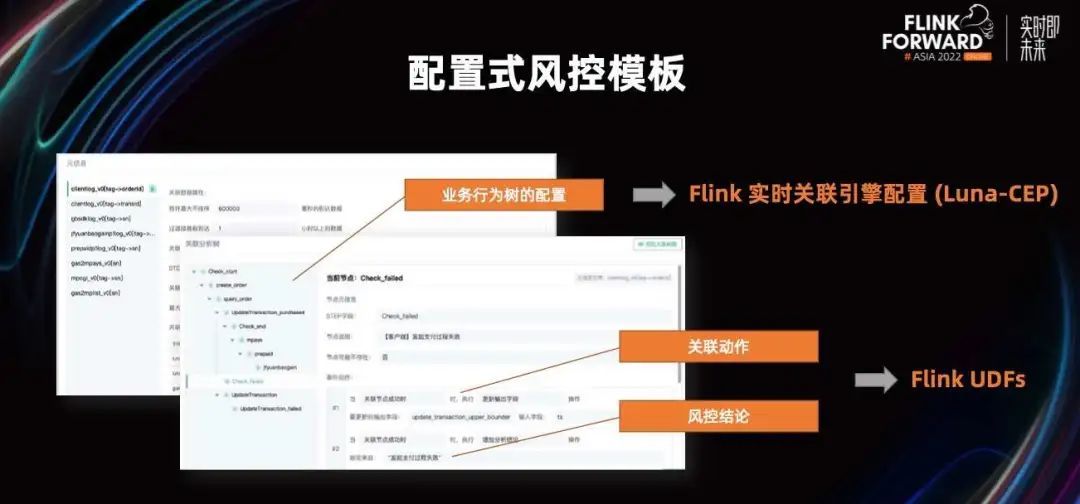
然后进行行为树的定义。定义整个业务行为会发生的动作,本质就是用人力运维排障方法论进行沉淀和泛化,将配置的形式固化下来。之后这些配置模板就会用于生成 Flink 流的 UDF 配置,并被实时同步到运行中的 Flink 流中。
除此之外,配置界面还提供了预览功能,即可以一边配置一边预览整个行为树。
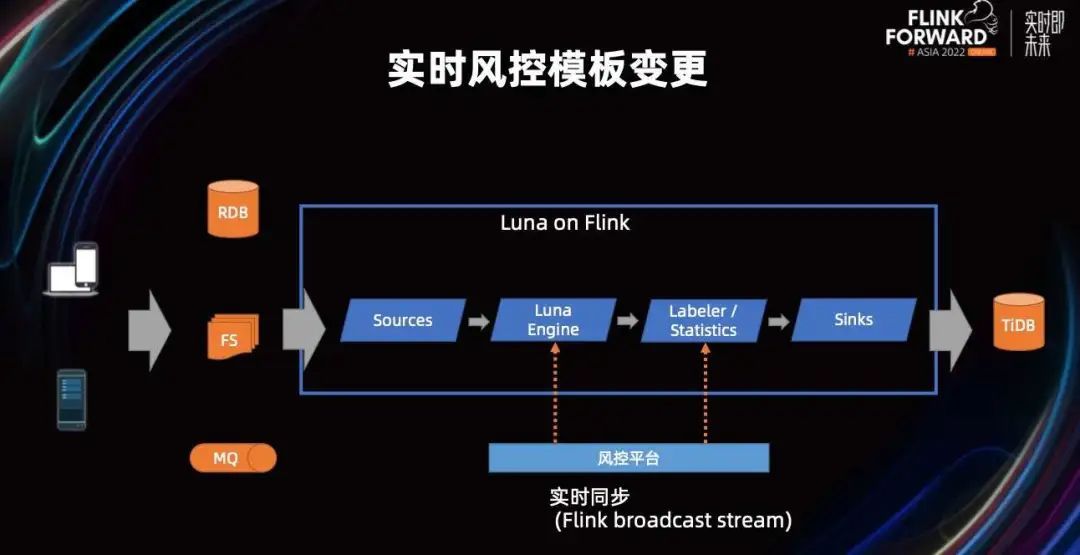
风控场景上的分析模板修改后,如果不涉及数据源的增减,我们的流可以通过 broadcast stream 的特性进行自动同步和变更。

从架构图中可以看出,我们选择了 TiDB 作为关联结果的存储层。那么我们是如何考虑的呢?
- 数据结果需要灵活可拓展,且适配索引。这样用户就能快速的自由配置抽取字段。
- 频繁的更新操作。因为我们的计算逻辑决定了我们会构造基准数据,再构造补充数据,以一种异步的形式写到数据库,所以需要频繁更新。
- 完备的聚合函数。因为宏观统计需要做各种各样的聚合,以满足我们数据分析统计的需求。
- 满足业务需求的写入/读取速度。
这样就可以使用列转行的结构,存储到我们的关系数据库里了。
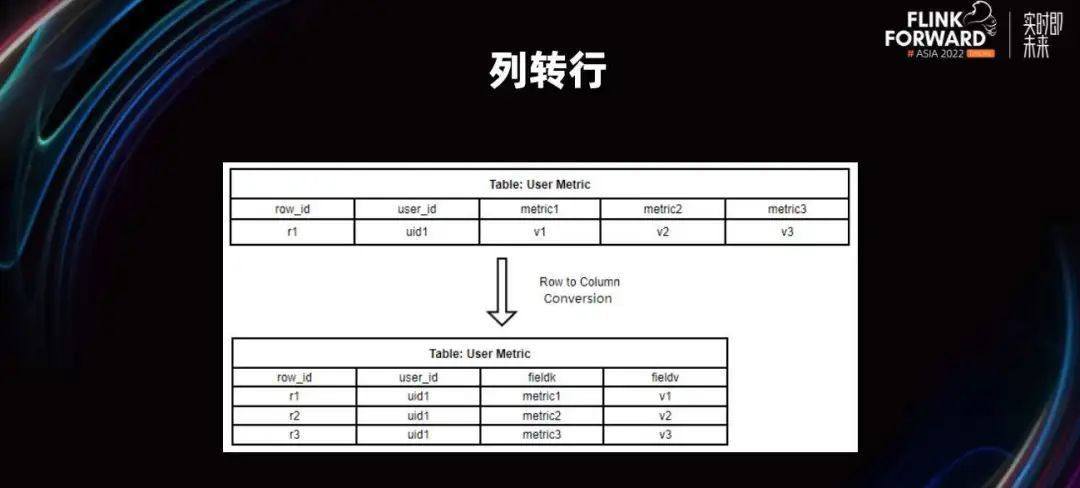
列转行是把会频繁发生增减字段的 DDL 转化为 DML,就可以支持我们灵活的数据结构。

每个字段都需要索引这样的特性,这在数据量持续增大的表上,就有着非常优秀的特性。
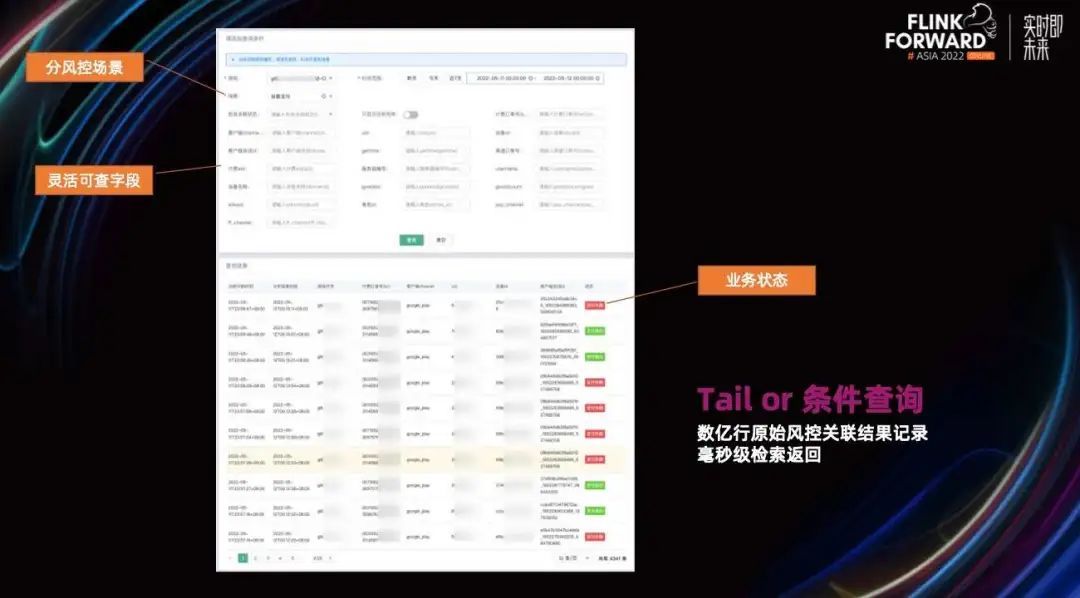
在这样一种存储结构上,我们的微观业务会话查询就可以做到毫秒级,灵活结合多种条件进行检索,以帮助运维人员快速查看线上风险和可能发生的故障原因。
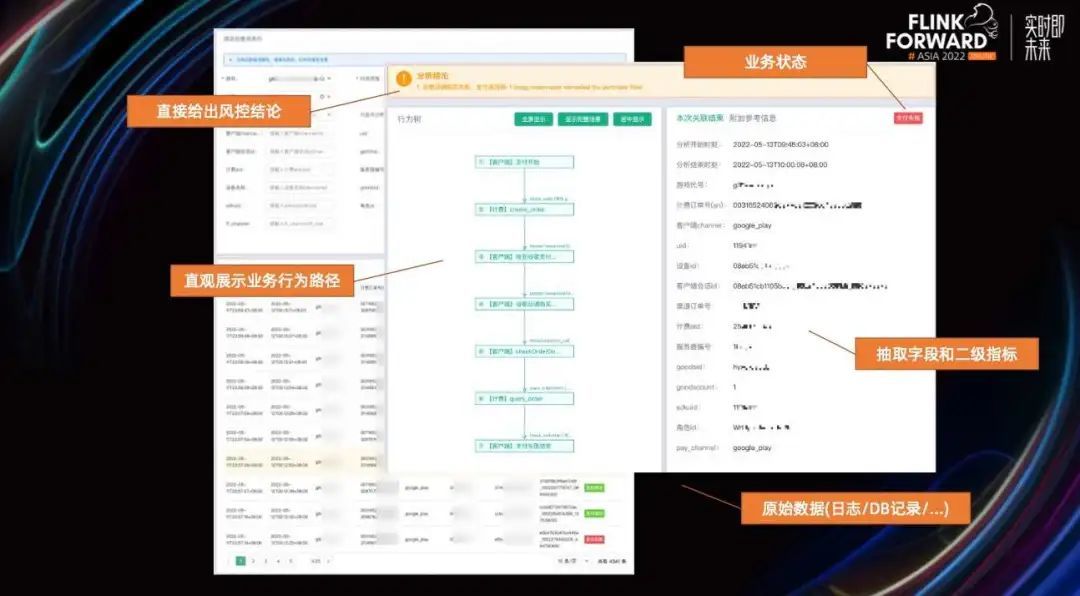
当我们点击查看任何具体的业务会话时,公共平台就会展示出当前这个业务会话的业务行为树,并抽取出有助于排障的一些关键字段和二级指标,极大方便了我们的运维人员排查具体问题的场景。对于常见的问题,我们甚至还会用结论模型直接给出风控结论,让我们的运维人员进去就能马上看出问题所在。
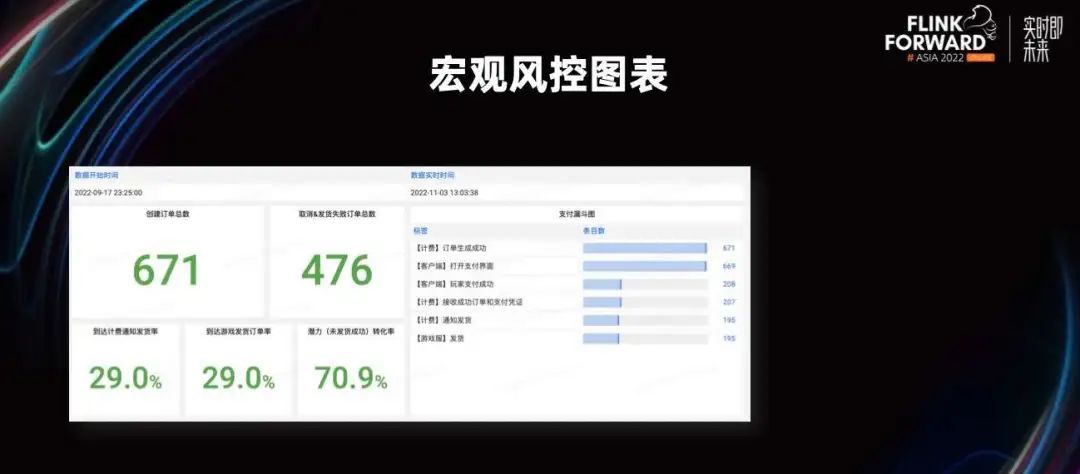
对于宏观统计,大家肯定也想到可以使用 SQL 作用在上面来进行统计了,毕竟我们把数据存在了关系型数据库 TiDB 里,但这里还存在着一些坑点。

当我们的数据量超过 10 亿的时候,我们的数据聚合时间会出现一些变化。比如当粒度是一小时,聚合时间是一天的时候,我们数秒可以完成。但当我们把时间拉到 60 天,几乎就出不来了。
在查看数据存储层的时候会发现,TiKV 已经 IO 满了,而且 CPU 飙升,因为我们做的数据量实在是太大了。
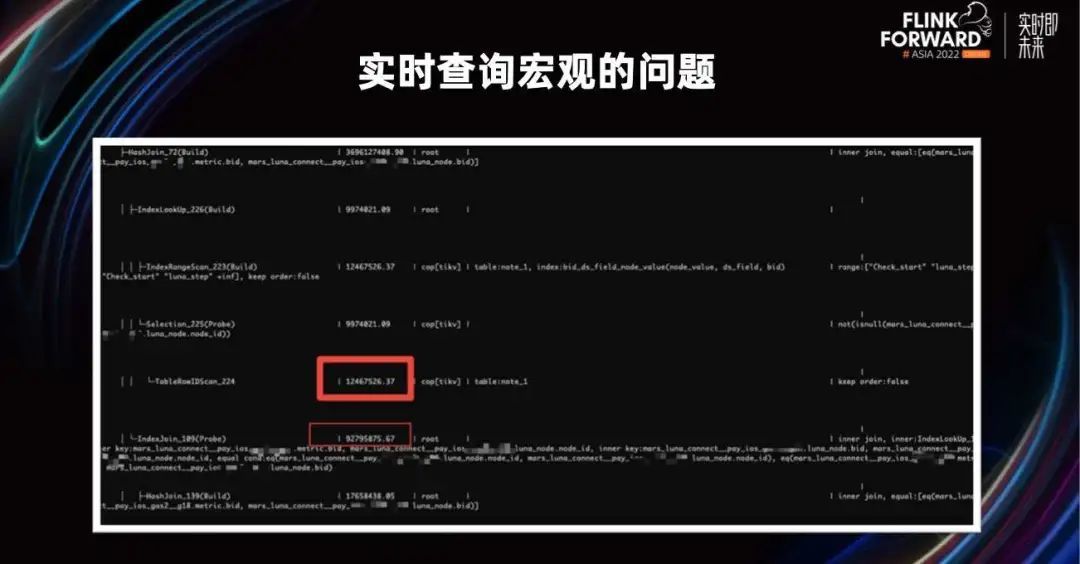
通过分析整个执行计划可以看到,TiKV 使用常规的模式进行 SQL 把所有数据捞到 TiDB 层进行聚合计算。这样做获取的数据函数会非常多,随着我们时间区间的增大会越来越缓慢,这样我们肯定是不能接受的。

那么我们来回看一下风控的 AP 需求,我们需要读取大量实时的关联的数据点;支持有复杂的聚合函数,且我们的查询不应该影响到 Flink 流进行 TP 写入。
这个时候就会想到,TiDB 有一个叫 TiFlash 的组件,它可以完成 TiDB 的 HTAP 特性。也就是 AP 和 TP 同样用 SQL 来完成,且它是物理隔离的,这就非常的适用于这样的场景。
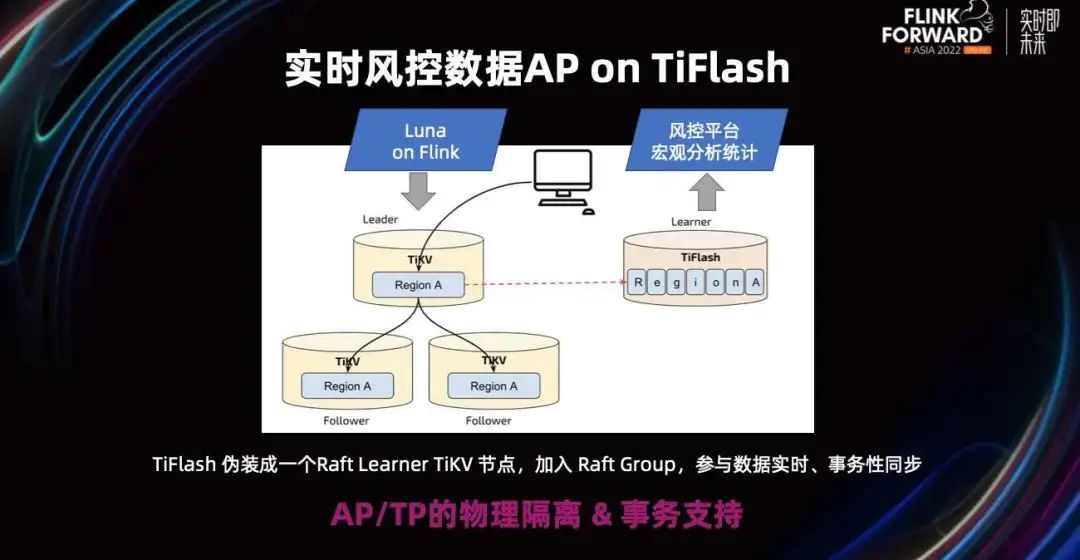
TiFlash 伪装成一个 Raft Learner TiKV 节点,加入 Raft Group,参与数据实时、事务性同步。这样就可以做到 AP 和 TP 的物理隔离,并且它还支持事物,这样就可以在执行 SQL 的时候无感进行 HTAP 了。

在进行这样的优化后我们可以看到,当我们的查询包含多层 join,甚至有分位数计算的时候,90 天聚合时间,粒度查询可以在十秒内返回和完成,这可以说是一次质的飞跃。
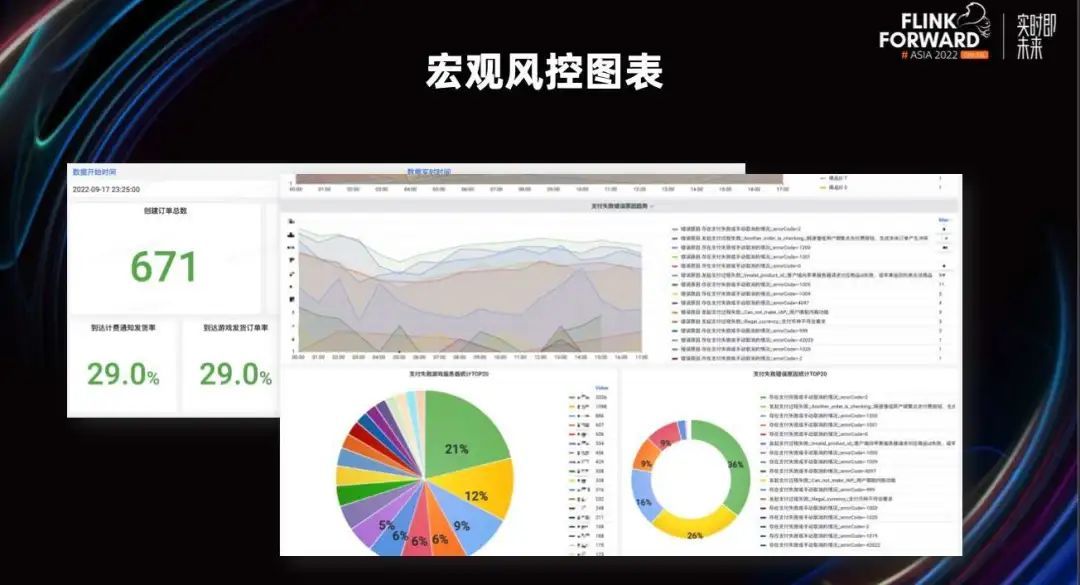
最后,我们把宏观统计提供给用户。在 TiFlash 的助力下,我们的平台可以做到秒级的 AP 多维度聚合查询。这种聚合查询出来的结果可以让我们的数据分析人员,从更高层次对整个业务环境的风险进行识别。
提升风控结果数据能效
当我们可以实时产生业务会话的结果,并在平台上展示的时候,接下来我们将通过以下几点提高数据效能。
- 风控结论生成:节约重复人力成本
- 标签和统计:将详情数据归类统计为宏观数据
- 数据打宽:增加分析维度
- 可视化展示:挖掘数据规律
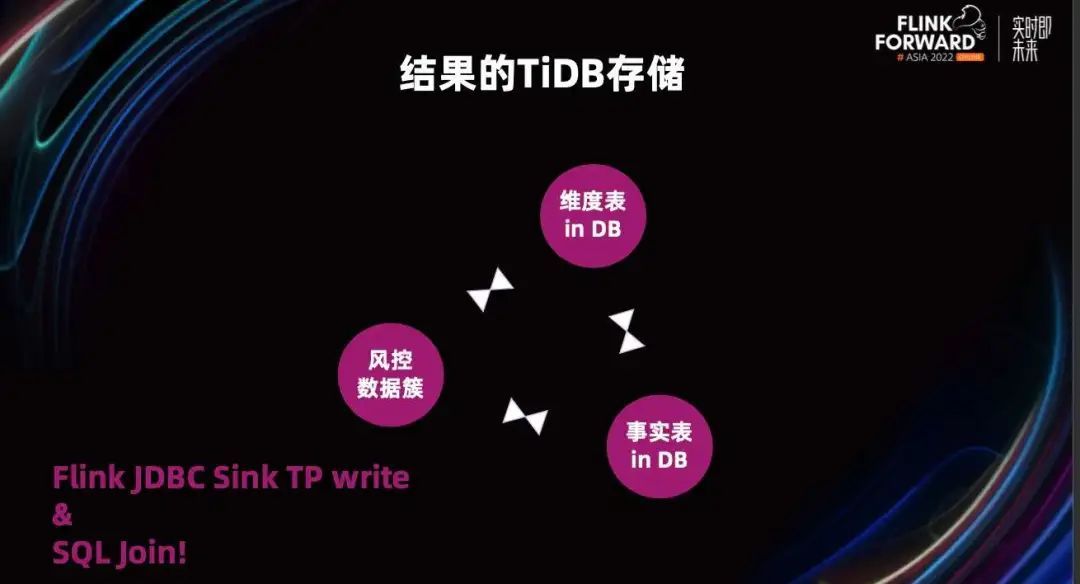
那么我们为什么把数据存储在 TiDB 这样的一种关系型数据库里呢?
因为 TiDB 作为一个分布式数据库,被我们广泛存储各项业务的事实和维度数据了。如果我们把风控数据簇也放在这里面,通过简单的专业操作我们就可以完成数据的拓宽,丰富我们的数据报表。
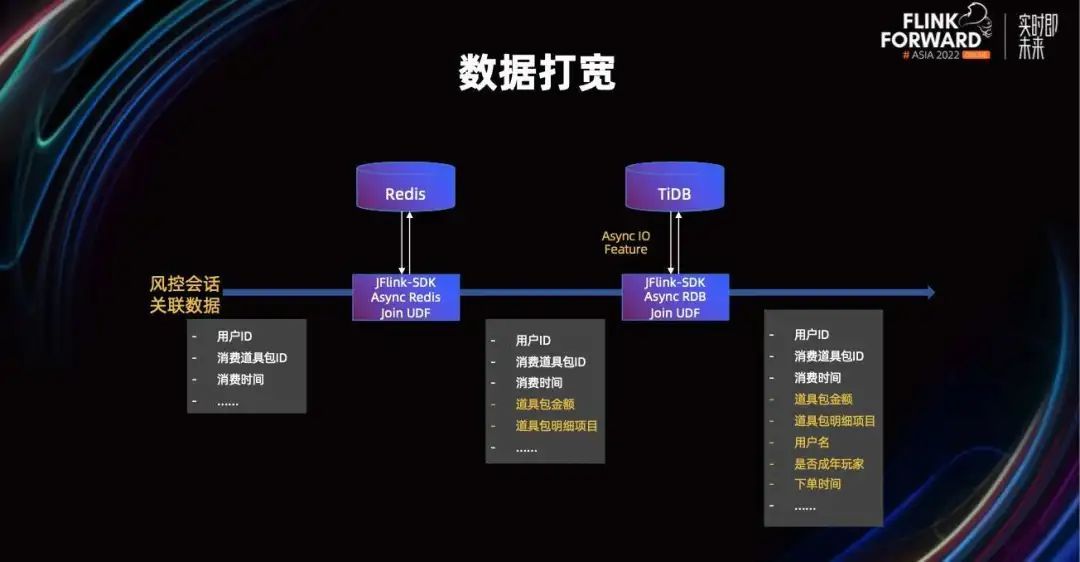
不仅是产生离线报表的时候可以这么方便的转,我们在实时计算的时候,也进行了 Async Join,通过 Async Join 转 UDF 进行实时数据打宽,同时我们支持多种存储介质。
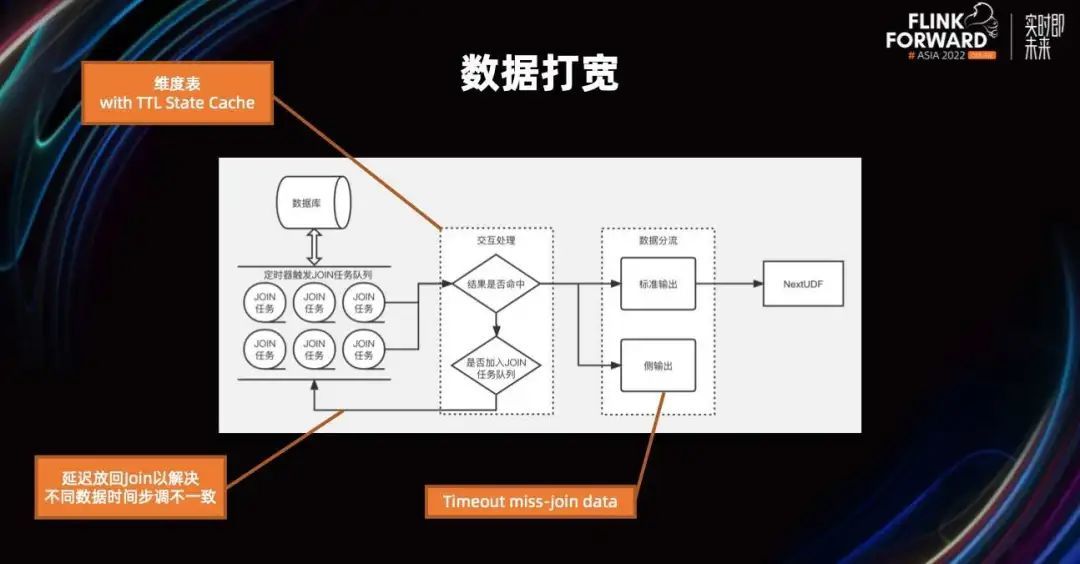
对于这种 Async Join,我们利用了 Flink 的 Async IO 的特性,并在 join 的时候进行了一些优化。比如进行批的 join,不同时间水位线的缓存 join 以及 timeup 数据的侧输出等等,这些都为数据的准确性提供了保障。
通过数据打宽后,我们的风控统计分析维度就可以更上一层楼了。之前通过 ID 无法做到的特殊聚合,现在把数据打宽,都可以进行可视化的一些分析和展示了。


除此之外,对于常见问题,我们支持预先配置结论模型。当运维人员实时查询微观会话时,直接为他们给出结论。

得到结论后,我们就可以从更高的角度,观察和统计整个业务环境的宏观情况了,甚至可以进行实时的业务环境监控。从而提高故障的发现率、预警率、预警的准确率以及整个运维人力的能效。并且通过可视化的展示可以使我们的风控平台更准确的提供服务。
发展历程与展望未来
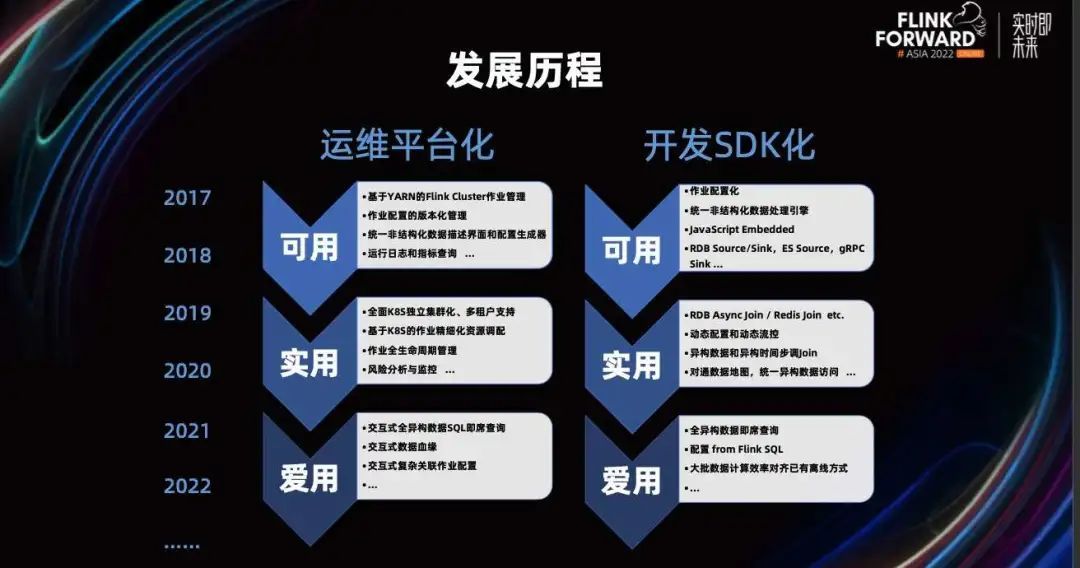
早在 2017 年我们就对实时计算开始调研了,并在 2018 年形成了双向发展的规划,分别是平台化和 SDK 手脚架的改造,经过多层的迭代,最终形成我们的一站式运维平台。
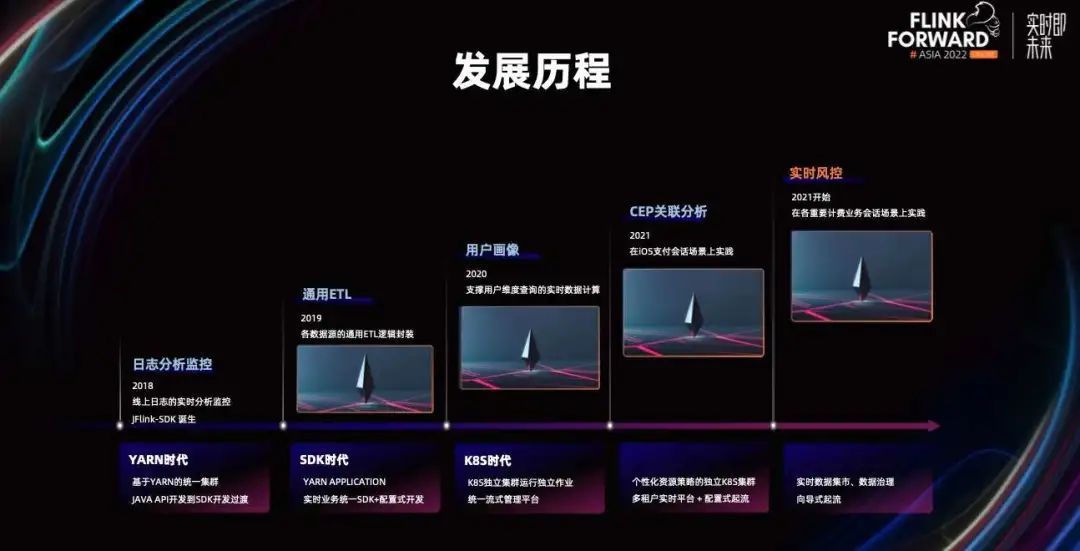
随着平台和 SDK 的发展,我们的实时业务线也越来越广泛。比如从最早的日志分析监控,到通用的解析 ETL,到用户画像,到复杂的关联分析,再到如今的实时风控平台,我们也是在实时领域越走越远,这都是 Flink 给我们带来的变革。
未来我们希望,可以实时风控平台可以支持更多的功能。比如我们希望支持用 Flink-SQL 即席查询风控结果;用户反馈驱动的风控模型修正;结合 Flink-ML 挖掘更深层次数据价值。
目录