
在现代数据库管理系统中,统计信息扮演着至关重要的角色。无论是查询优化、资源分配还是系统性能监控,统计信息都为其提供了坚实的数据基础。特别是在分布式数据库如 TiDB 中,统计信息的准确性和及时性更是直接影响到系统的性能和稳定性。
统计信息通常包括表的行数、列的数据分布、索引的选择性等。这些数据帮助查询优化器在执行 SQL 语句时做出最优的执行计划,从而最大限度地减少查询时间和资源消耗。此外,统计信息还能帮助数据库管理员识别性能瓶颈,进行有效的系统调优和资源管理。
在 TiDB 中,统计信息的维护尤为重要。由于 TiDB 的分布式特性和高并发访问场景,统计信息的失准可能导致查询计划选择错误,从而影响系统的整体性能。因此,定期更新和维护统计信息是确保 TiDB 高效运行的关键步骤。
而 TiDB 内部为了保证统计信息的正确性,也做了大量的工作,提供了许多可以调整的参数,以便根据您的负载情况来优化其性能。所以一个可以显著影响您的 TiDB 性能的关键就是正确配置和调整统计信息参数。
在本指南中,我们将带您了解各种统计信息的参数,解释它们对 TiDB 性能的影响,并提供关于如何优化这些参数的最佳实践。
统计信息模块组成
TiDB 的统计信息管理主要分为两个关键部分:统计信息收集(Analyze)和统计信息同步。
统计信息收集:TiDB 通过后台的 Auto Analyze 功能自动收集统计信息,确保集群中的统计信息保持准确。
统计信息同步:这一部分确保所有节点上的统计信息保持一致,并能够及时反映最新的变动。它进一步细分为两个子部分:
- Init Stats:负责在集群启动时初始化 TiDB 的统计信息。
- Sync Load:负责将统计信息的变更同步到所有相关节点。
通过这两个部分的协同工作,TiDB 能够维护一个准确且最新的统计信息库,这对于优化 SQL 查询性能和提高系统稳定性至关重要。
统计信息版本
历史上,TiDB 拥有两套统计信息管理系统,分别标记为 v1 和 v2。自 v5.2 版本引入 v2 以来,我们不断对其进行改进。目前,v1 已经不再维护,并且从 v6.5 版本开始,TiDB 默认的统计信息版本已经切换到 v2。我们强烈推荐用户迁移到 v2 版本。
系统变量 tidb_analyze_version 用于控制 TiDB 使用的统计信息版本。Version 2 在大数据量场景下提升了统计信息收集的准确性。与 Version 1 相比,Version 2 在估算谓词选择率时无需收集 Count-Min Sketch 统计信息,并且支持仅自动收集选定列的统计信息,从而提高了收集效率。
v2 的优化点包括:
- 更准确的估算:stats v2 相较于 v1 提供了更准确的估算结果,特别是在处理大表和数据倾斜场景时。例如,它改善了谓词越界场景(常见于点查询或日期列范围查询中的谓词越界)的处理。
- 更快的 Analyze 速度:analyze v2 的速度更快,减轻了对 TiKV 的压力。这是因为 analyze v2 在扫描表时只需进行一次采样,即可同时获得索引的采样数据;而 analyze v1 需要分别扫描表和所有索引。
- 内存优化:v2 允许指定收集部分列的统计信息,这减少了 TiDB 和 TiKV 之间的网络流量。如果面临 TiDB 内存压力,可以通过调整
samplerate来降低内存使用。
升级统计信息版本
为了确保统计信息的一致性和准确性,建议对所有表、索引(以及分区)统一使用相同版本的统计信息收集功能,推荐选择 Version 2。在版本切换过程中,可能会有一段时间统计信息不可用,直到所有表都更新为新版本的统计信息。缺乏统计信息可能会影响优化器的查询计划选择。
为顺利切换统计信息版本并准备执行 ANALYZE,根据实际情况,可以采取以下步骤:
手动执行 ANALYZE:如果您通常手动执行 ANALYZE 语句,请逐一统计并分析每张需要更新统计信息的表。这包括对每个表执行 ANALYZE 命令,以确保它们都使用 v2 的统计信息收集功能:
SELECT DISTINCT(CONCAT('ANALYZE TABLE ', table_schema, '.', table_name, ';'))
FROM information_schema.tables JOIN mysql.stats_histograms
ON table_id = tidb_table_id
WHERE stats_ver = 2;如果您的 TiDB 环境配置为自动执行 ANALYZE(即自动更新统计信息),您可以通过执行特定的 SQL 语句来生成 DROP STATS 命令,以便为统计信息版本的切换做好准备:
SELECT DISTINCT(CONCAT('DROP STATS ', table_schema, '.', table_name, ';'))
FROM information_schema.tables ON mysql.stats_histograms
ON table_id = tidb_table_id
WHERE stats_ver = 2;也可以将结果导出到临时文件后,再执行:
SELECT DISTINCT ... INTO OUTFILE '/tmp/sql.txt';
mysql -h ${TiDB_IP} -u user -P ${TIDB_PORT} ... < '/tmp/sql.txt'统计信息常见问题诊断与优化调整建议
Sync Load
从 TiDB 版本 v5.4.0 开始,引入了一个新特性,即统计信息同步加载。这项特性允许在执行 SQL 语句的同时,将直方图、TopN、CMSketch 等较大体积的统计信息同步加载到内存中,目的是提升 SQL 语句优化过程中统计信息的完整性。若要启用这一特性,你需要设置系统变量 tidb_stats_load_sync_wait,其值应为 SQL 优化过程中可以等待同步加载完整列统计信息的最大超时时间(以毫秒为单位)。该变量的默认设置为100,这表示默认情况下统计信息同步加载功能是开启的。
诊断与优化
在后续的开发过程中,我们注意到早期版本的 sync load 性能存在不足,并伴随着一些 bug。这些问题可能导致超时和统计信息无法成功加载。为了检测同步加载是否存在问题,你可以打开监控 tidb cluster -> Statistics,查看 Sync Load QPS 指标,如果发现有大量的超时(timeout)事件,这通常意味着同步加载功能可能遇到了问题。
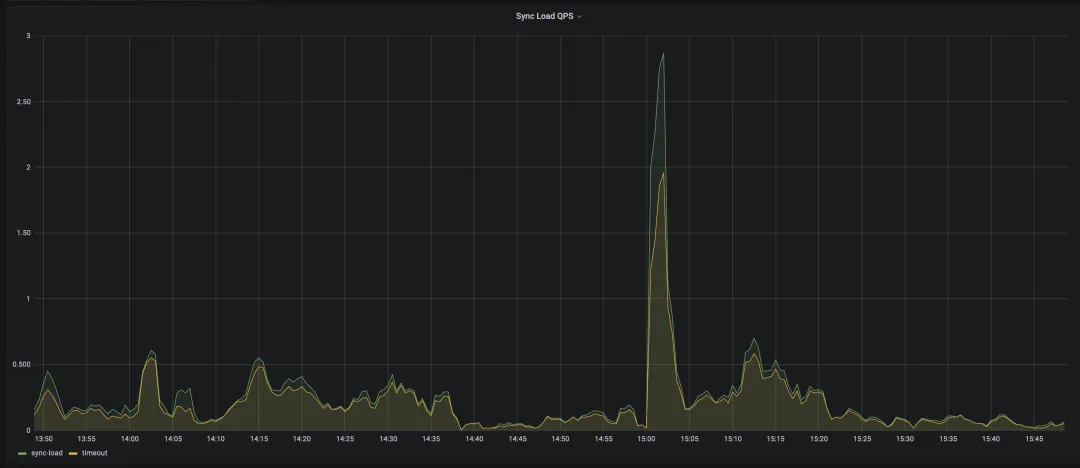
查看 TiDB version
已知问题在 v6.5.10, v7.1.6, v7.5.2, v8.1.0 中得到了修复,所以如果本地版本低于此版本,且有上述问题的,建议通过升级来解决。
调整 sync load 的并发与超时
如果发现所用 TiDB 版本已经修复了这方面的问题,但是依然存在 timeout 问题,可以调整 sync load 的并发与超时
- 如果发现 timeout 比较零散,可以先调整
tidb_stats_load_sync_wait - 如果发现 timeout 比较多,要考虑是否是并发过低,导致 load 任务处理不够及时。需要调整
stats-load-concurrency
❗️v8.2 之上的版本:
stats-load-concurrency=0支持自适应并发,TiDB 会根据机器的 CPU core 自适应调整并发数,所以在此版本上,如果有 timeout,建议调整tidb_stats_load_sync_wait,否则建议调整机器的规格。
Init Stats
Init stats 是 TiDB 在启动阶段用于初始化统计信息的功能。
- 在 v7.1 之前的版本中,TiDB 会将所有统计信息加载到内存中,这在表数量众多的情况下会导致统计信息加载过程缓慢。
- 为了改善这一点,我们在 v7.1 版本中引入了
lite-init-stats功能,它首先只加载统计信息的元数据,然后通过异步的 sync load 机制加载完整的统计信息。但我们后来发现,在启动过程中,如果统计信息加载未完成,可能会影响初期的 SQL 执行性能。 - 因此,在 v6.5.7 和 v7.1 版本中,我们增加了
force-init-stats选项,确保在统计信息完全初始化后才对外提供服务。
尽管如此,在处理大量表的情况下,加载速度仍然不尽人意。
- 为了进一步提升性能,我们在 v7.1.2 和 v8.1 版本中引入了
concurrently-init-stats功能,该功能允许并发初始化统计信息,显著提高了启动速度。
启动后执行计划跳变
在早期版本中,启动后的执行计划跳变,和 sync load 的加载有密切的关系,在 v6.5.10, v7.1.6, v7.5.2, v8.1.0 中已经修复,建议通过升级来解决,或参考上一篇的 sync load 优化来解决。
Auto Analyze
Auto Analyze 的过程可以通过排队论来构建相应的数学模型,具体如下:
- 任务到达率:指的是集群中表的统计信息从健康状态(health)转变为不健康状态(unhealth)的速率,以下简称为“健康度下降速率”。
- 服务时间分布:指的是监控中 Auto Analyze 任务耗时的统计分布。
我们的目标是使 Auto Analyze 的处理速度至少与健康度下降速率相匹配,以确保集群的统计信息能够及时更新。如果现有资源能够满足当前 Auto Analyze 任务的需求,我们可以通过调整触发 Analyze 的配置参数,让更多的表能够尽早启动 Auto Analyze,从而及时更新统计信息,减少因统计信息偏差导致的性能问题的风险。
集群初始化后参数优化
目前,TiDB 的默认参数设置较为保守,以避免对集群造成不利影响。由于我们无法提前准确预测集群的压力状态和流量的峰谷变化,因此在集群初始化之后,我们可以根据具体的业务需求和特性,对 TiDB 进行针对性的性能优化。
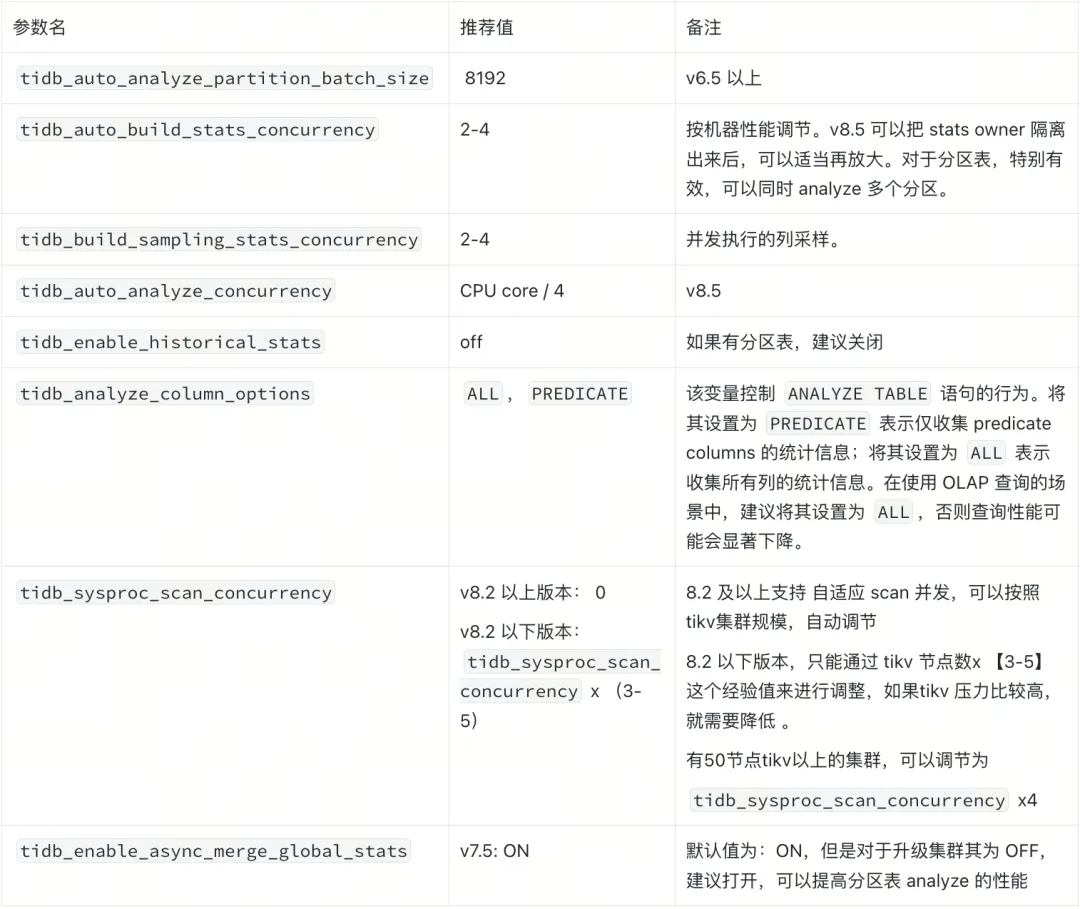
❗️tidb_auto_build_stats_concurrency 和 tidb_build_sampling_stats_concurrency 两个参数之间存在乘积关系,实际的并发度是这两个参数值的乘积。因此,建议根据具体场景进行调整,以确保 Analyze 的速度至少与统计信息变化的速率相匹配。以下是具体的调整建议:
- 分区表较多时:建议优先增加 tidb_auto_build_stats_concurrency 的值,以提高处理分区表的并发度。
- 表的列较多时:建议优先增加 tidb_build_sampling_stats_concurrency 的值,以提高采样统计的并发度。
- 并发度限制:tidb_auto_build_stats_concurrency 与 tidb_build_sampling_stats_concurrency 的乘积不应超过 CPU 核心数,以避免过度消耗 CPU 资源。
- v8.5 及以上版本:tidb_auto_build_stats_concurrency、tidb_build_sampling_stats_concurrency 与 tidb_auto_analyze_concurrency 三个参数的乘积不应超过 CPU 核心数,以保持系统的稳定运行。通过合理调整这些参数,可以优化 TiDB 的统计信息构建和采样过程,提高 Analyze 任务的效率,同时确保不会过度占用系统资源。
❗️在扩缩容后,务必调整tidb_sysproc_scan_concurrency的值。
集群运行时调优
💡 建议将下述检查,作为日常巡视项目,确保不会有大量处于 unhealth 状态的表等待分析。
1.检查集群 auto analyze 状态
观察集群的 analyze 的 P95 的耗时,如果发现 P95 耗时比较高,需要对 TiDB 的 analyze 参数进行调整。
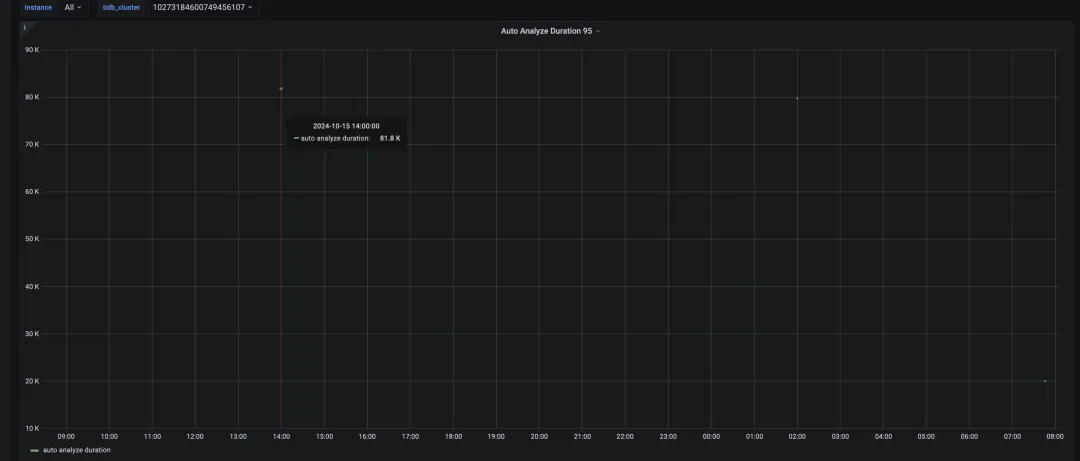
在进行性能优化之前,P95 耗时为 22 小时。以下是优化步骤:
- 调整
tidb_sysproc_scan_concurrency参数:根据 TiKV 节点的数量,将其值乘以 2 进行调整。这样可以提高系统扫描的并发度,从而可能减少耗时。 - 观察 TiDB 的 CPU 使用情况:由于 TiDB 的
analyze参数默认是针对 8 个 CPU 核心设置的,而tidb_auto_build_stats_concurrency的默认值是 1,因此可以根据实际的 CPU 核心数适当增加这个参数的值。这样做可以提高自动构建统计信息的并发度,进一步优化性能。
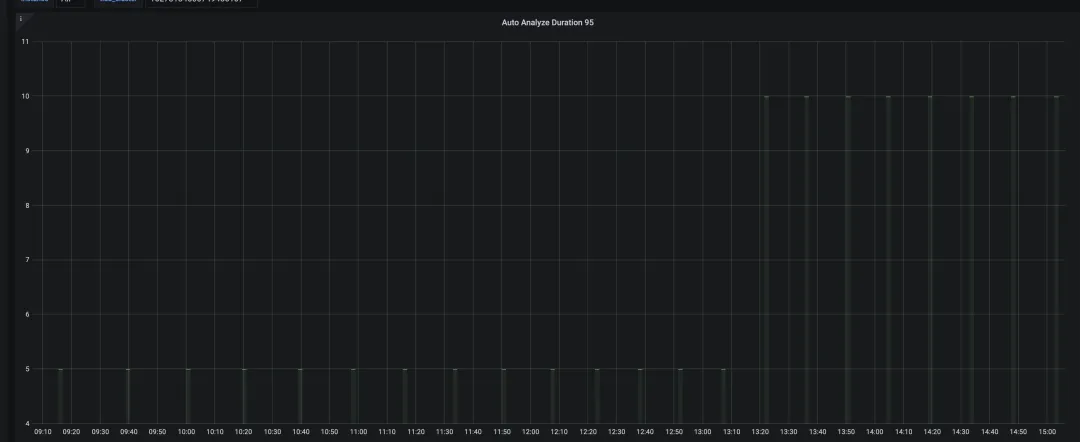
调整后,P95 为 10s。
2.依据集群状态调优
Auto Analyze 的核心目的是维持统计信息(stats)的健康状态,防止其退化为不健康(unhealth)状态。通过监控统计信息健康度在 [0, 50) 范围内的变化趋势,如果曲线能够保持相对平直,这表明当前的 Analyze 处理速度与统计信息恶化的速度相匹配,能够有效地抵消统计信息质量的下降。
在后续的小版本更新中,我们对监控面板进行了改进,能够识别并排除那些无法触发 Auto Analyze 的表,并对其进行单独计数,标记为“无需分析”(unneeded analyze)。如果在这个范围内的曲线显示为 0,这进一步证实了当前的 Analyze 速度足以抵消统计信息质量的下降,保持了统计信息的健康度。这样的改进有助于更精确地管理和优化数据库的性能。
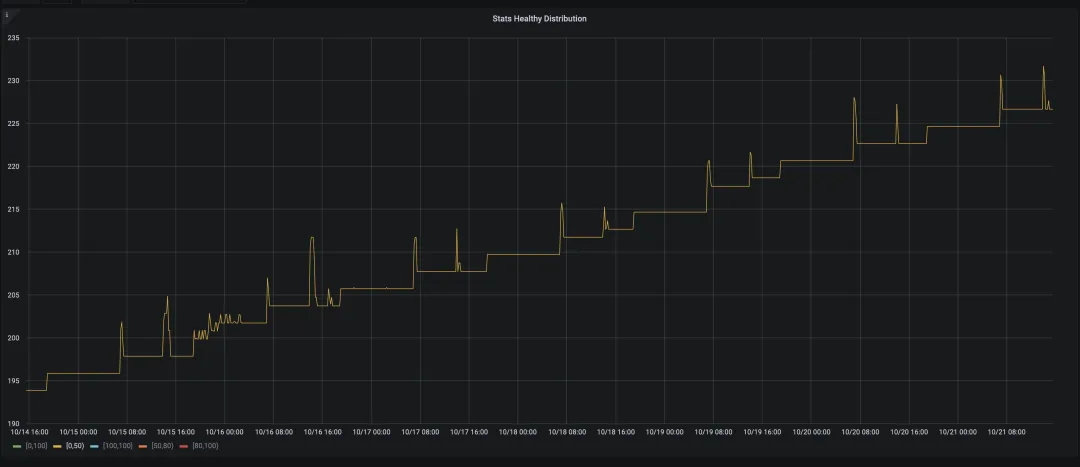
如果 Analyze 的处理速度跟不上统计信息(stats)恶化的速度,那么统计信息健康度在 [0, 50) 范围内的曲线就会变得波动较大。在初步优化 Auto Analyze 后,如果仍然无法有效控制统计信息健康度曲线的形状,我们就需要评估当前 TiDB 服务器的配置以及 TiKV 的负载,以确定它们是否能够应对当前统计信息变化的需求。
从 v7.5 版本开始,TiDB 引入了资源控制(resource control)功能,这有助于减轻 Auto Analyze 在 TiKV 层面对业务操作的影响,确保数据库性能的稳定性。通过合理配置资源控制,可以在不干扰业务流量的前提下,更有效地管理 Auto Analyze 任务,从而维持统计信息的健康度。
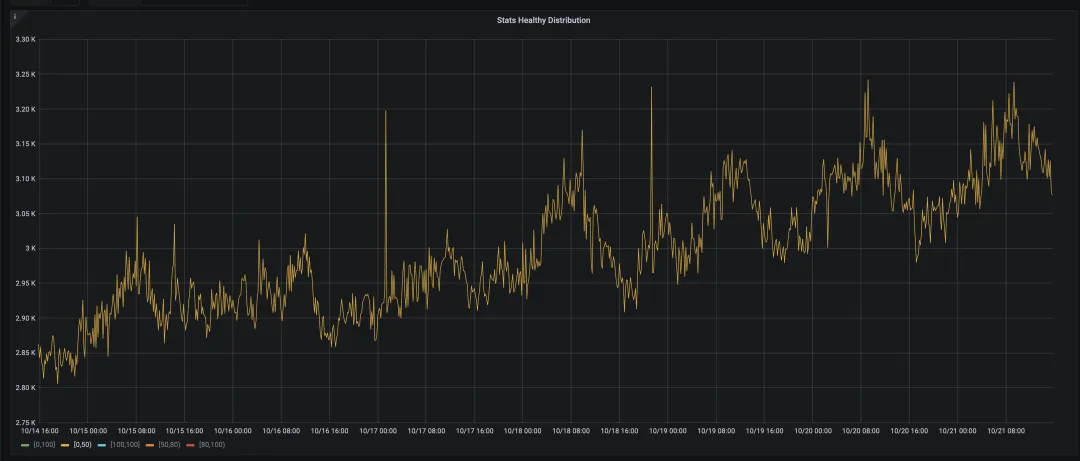
检查 TiDB 的 CPU 使用情况
在 CPU 负载较轻的情况下,可以考虑进一步增加 tidb_auto_build_stats_concurrency 参数的值,以提升统计信息构建的并发度。如果您担心这可能会影响 TiDB 上的业务操作,并且您使用的是 TiDB v8.5 或更高版本,您可以将 Analyze 任务定向到特定的 TiDB 节点上,实现隔离执行。(关于 v8.5 版本的调整,可以参考官方文档。)
TiDB v8.5 版本支持并发执行 Auto Analyze,您可以通过增加 tidb_auto_analyze_concurrency 参数的值来同时执行更多的 Analyze 任务,从而提高 Analyze 的吞吐量。
对于低于 v8.5 版本的 TiDB,您可能需要自行编写脚本来实现 Analyze 任务的并发执行,以优化统计信息的更新过程。
检查 TiDB 的 memory 使用情况
监控 TiDB 的内存使用情况是至关重要的。如果在执行 Analyze 阶段遇到内存溢出(OOM)或内存使用突然激增的情况,可能的原因及解决方案如下:
- 分区表引发的 OOM:在 TiDB v7.5 及以上版本中,可以通过启用
tidb_enable_async_merge_global_stats参数来解决。在旧版本中,TiDB 会将所有统计信息加载到内存中,这很容易导致 OOM。新版本中,TiDB 能够边加载边合并全局统计信息,有效避免了 OOM 的发生。 - 历史统计信息引发的 OOM:在 v7.1、v7.5 和 v8.1 版本中,默认会开启
tidb_enable_historical_stats,但其实现存在问题,会尝试将所有统计信息加载到内存中,并转换为 JSON 格式。对于分区表等统计信息较多的表,这可能导致 OOM。因此,在 v8.5 版本中,我们将此参数默认设置为关闭。 - 大字段类型列引发的 OOM:对于某些大字段类型,如 text、blob 等,由于其本身体积较大,且统计信息对这些类型的列作用有限,后续版本引入了
tidb_analyze_skip_column_types参数。此参数允许 json、blob、mediumblob、longblob、text、mediumtext、longtext 等类型的列跳过 Analyze 过程,从而避免 OOM 的发生。
通过这些措施,可以有效地减少 Analyze 过程中的内存溢出风险,并确保 TiDB 的稳定运行。
3.调整 Auto Analyze 触发阈值
在大多数情况下,TiDB 的自动分析(Auto Analyze)触发频率相对较低,主要原因是 tidb_auto_analyze_ratio 的默认设置为 0.5,意味着只有当表中一半的数据发生变化时,才会触发自动分析。因此,对于数据量较大的表来说,触发自动分析的难度更大。
在以下条件下,我们可以考虑降低 tidb_auto_analyze_ratio 的值:
- Auto Analyze 的 P95 耗时较短:确保在两次自动分析之间有足够的时间来执行其他任务。
- 监控统计信息健康度的变化:观察统计信息健康度的其他区间变化速率,确保调整后统计信息健康度的恶化速度不会超过自动分析的执行速度。
- 集群资源充足:确认 TiKV 和 TiDB 有足够的资源冗余,以支持更频繁的自动分析操作。
通过调整 tidb_auto_analyze_ratio,可以更灵活地控制自动分析的触发频率,以适应不同表的数据变化情况,同时确保统计信息的健康度得到及时更新,优化查询性能。
总结
通过在部署、启动和运行阶段对统计信息的收集和加载进行细致优化,我们可以显著提高统计信息的准确性和实时性。这不仅能够保障 TiDB SQL 查询的性能和稳定性,还能减少资源消耗。最终,这些优化措施有助于降低 TiDB 所需的部署硬件成本。
TiDB 优化器新特性性能提升预告(v8.1-v8.4)
Instance Plan Cache 特性:使用全局统一的实例级内存缓存更多 Session 间共享 SQL 的执行计划,大幅提升全局 SQL 执行计划命中率,进一步降低 CPU 的消耗,大幅提升数据库整体稳定性和性能。
TiDB Predicate Analyze 特性:通过参数开关控制收集 SQL 中 predicate columns 的行为,在表统计信息收集时只针对 predicate columns 进行收集,达到大幅降低收集统计信息对 CPU 和内存资源的消耗,以及大幅缩短单个表的统计信息时间,确保在有限的统计信息收集窗口完成更多的表的统计信息收集,为 SQL 执行计划生成提供更加准确的环境,最终实现整体数据库的稳定性和 SQL 的性能更进一步的提升。
Concurrently init stats 特性: 在 TiDB Server 启动时通过多任务并发的方式,快速将所有统计信息数据快速装载到 TiDB Server 内存中,有效避免和解决了因统计信息加载时延过长,导致生成错误的 SQL 执行计划,从而引起的性能问题,或者直接产生错误 SQL 执行计划导致消耗大量内存,CPU,网络资源,引起的数据库不稳定的问题,进一步提高了数据库的可用性。
目录