
作者介绍:曹鹏,WPS 云平台运维 Leader;肖尚武,WPS 云平台 DBA;庾俊,WPS 云文档研发
一、背景
TiDB 在 WPS 使用算是国内较早的一批用户,WPS 分享业务就是在 TiDB-v2.x 稳定运行了几年。直到 2020 远程办公爆发式增长,数据量巨大,为提高稳定性和性能,同时考虑到数据安全等方面因素,规避单机房故障导致的业务不可用风险,多机房建设及稳定性提升已然成为 WPS IT 建设中的重要指标。经过 TiDB 在近几年内的快速迭代,v2.x 已是很古老的版本,新版本的特性升级在建设双机房的过程中显得更加容易落地。
业务使用场景
在工作和生活中我们常需要传输各种各样的文件。普通的传输方式传输时间久低效,无权限控制不安全,而分享协作它会将文件以分享方式发送给他人,减少了因文件过大带来的传输时间。还可以设置好友编辑权限、有效期、自定义关闭文件的分享权限,大大提高了文件传输的安全性。WPS 分享业务在数据库结构上有个特殊的服务,它需要在单表上使用多个维度的索引,一个表需要分别通过多字段组合来查询,而且数据量巨大,目前单表最大规模约几十亿条数据。如果用传统的分库分表来设计,虽然也可以解决问题,但是会面临很多麻烦,比如代码逻辑复杂,数据冗余,数据不一致等问题,而使用 TiDB 分布式数据库就能轻松应对这些问题。
数据库对比选型的思考
TiDB 高度兼容 MySQL 协议,基本可以当成 MySQL 使用;天然的分布式存储与计算分离的架构的设计,让多副本保存数据无需考虑单点问题;同时能够动态在线扩容缩容,对应用透明不影响业务,操作也相对简单。除此之外,TiDB 官方社区活跃,文档很齐全,遇到问题时官方的响应也很及时。
二、环境现状
2.1 现有架构
TiDB 版本:TiDB-v2.x
架构规模:7 台服务器,tikv 3 台高配[32C 256G 3T SSD],montior 1 台低配 [8C 64G 500G] ,pd/db 3 台中配[32C 128G 3T SSD]
地区区域:IDC1 机房
2.2 双 IDC 架构
TiDB 版本:TiDB-v4.x
架构规模:14 台服务器(7 台服务器,tikv 3 台高配[32C256G3TSSD],montior 1 台低配[8C64G500G] ,pd/db 3 台中配[32C128G3TSSD])*2
地区区域:IDC1(主) + IDC2(从)
硬件选型:
| 组件 | CPU | 内存 | 硬盘类型 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| TiDB|PD | 32 核 | 128 GB | 3T SSD | 万兆网卡 | 6 |
| TiKV | 32 核 | 256 GB | 3T SSD | 万兆网卡 | 6 |
| 监控 | 8 核 | 64 GB | 500G SAS | 千兆网卡 | 2 |
线上稳定运行一套数据库,硬件配置犹为重要。按官方推荐的配置,一套生产 TiDB 集群最低配置至少要 7 个节点[DB|PD 混部],KV 存储设备官方建议使用 NVMe 协议的 SSD,不超过 2T,我们基于 QPS、数据量的增长及现有的资源,直接拉满配置,当 Region 过多产生热点问题也可在 KV 节点快速扩容,服务器、交换机均采用万兆网卡。
2.3 环境说明
因为现有架构的 TiDB 版本是 2.x 版本 ,不支持 TiDB CDC 同步数据到另一个 IDC 集群,所以需要先升级版本;利用 TiDB 滚动开启 binlog,配置 Drainer 再增量同步到 TiDB-v4.x。
三、架构演变
3.1 同步架构
- TiDB-v2 开启 binlog,设置 gc-time 720h,Dumpling 全量备份;
- Lightning 导入 TiDB-v4,配置 TiCDC 同步;
- TiDB-v2 配置 Drainer 增量同步至 TiDB-v4。
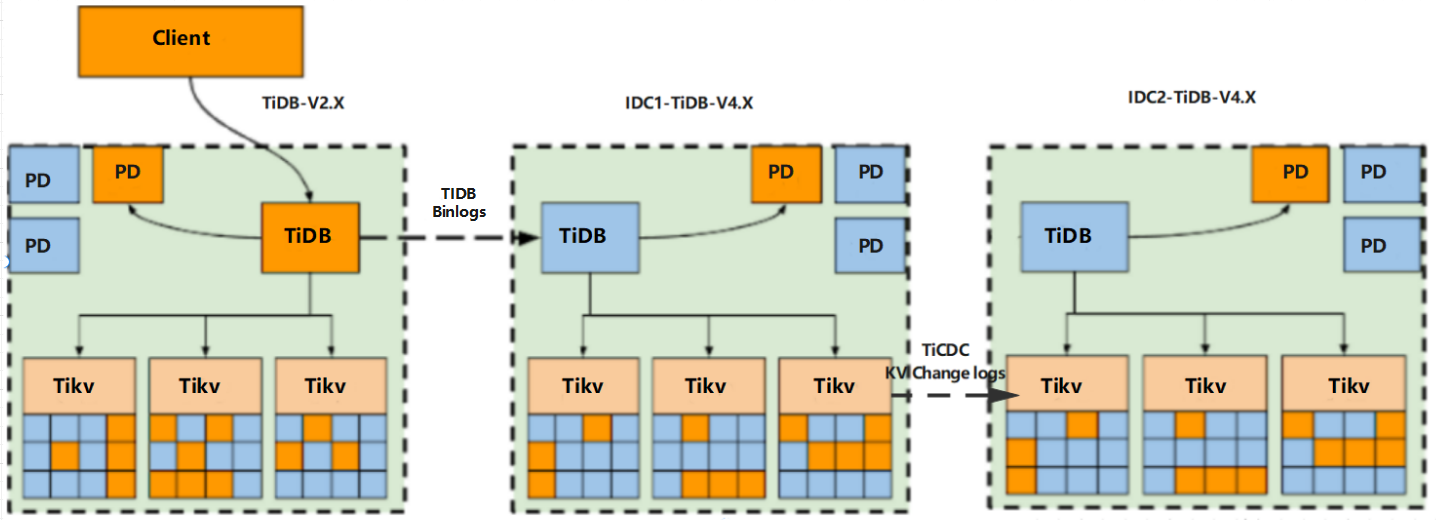
3.2 双机房高可用架构
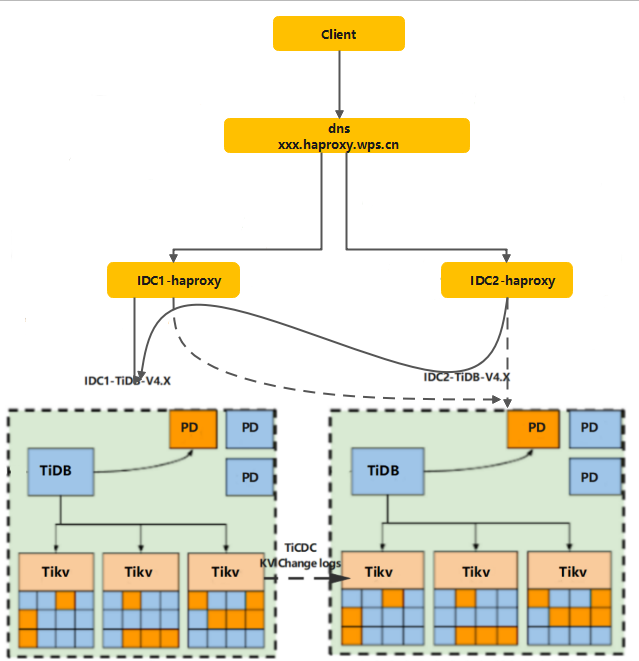
- 配置内部 DNS 域名指向 HAProxy 代理,两个 HAProxy 同时解析到 IDC1-TiDB 集群,当 IDC1 不可用,切至 IDC2-TiDB 集群;
- 数据核验,包括定时核对,滚动核对;
- 应用切换连接域名。
四、实施步骤
4.1 流程简述
- TiDB-v2.x 滚动开启 binlog;
- TiDB-v2.x 备份导出数据库,恢复到 IDC1-TiDB-v4.0 集群、IDC2-TiDB-v4.0 集群;配置 TiCDC,IDC1 增量同步数据到 IDC2-TiDB-v4.0 集群;
- TiDB-v2.x 配置 Drainer 增量同步到 TiDB-v4.x;
- 业务设置只读,检查数据一致性,指定时间核对表数据,sync-diff-inspector 滚动校验,停止 Drainer 同步,应用连接地址切换到域名:"xxxx";
- 测试检验业务功能模块是否正常。
4.2 实施步骤
4.2.1 TiDB-v2.x 滚动开启 binlog
修改 tidb-ansible/inventory.ini 文件设置 enable_binlog = True,表示 TiDB 集群开启 binlog。
## binlog trigger
enable_binlog = True
## Binlog Part
[pump_servers]
pump1 ansible_host=ip1 deploy_dir=/disk/ssd/tidb/pump
pump2 ansible_host=ip2 deploy_dir=/disk/ssd/tidb/pump
pump3 ansible_host=ip3 deploy_dir=/disk/ssd/tidb/pump部署 pump
ansible-playbook deploy.yml --tags=pump -l ${pump1_ip},${pump2_ip},${pump3_ip}启动 pump_servers
ansible-playbook start.yml --tags=pump更新并重启 TiDB_servers
ansible-playbook rolling_update.yml --tags=tidb更新监控信息 如果部署了 Drainer 监控无信息,需要再次更新监控信息
ansible-playbook rolling_update_monitor.yml --tags=prometheus查看 Pump 服务状态,登录到 TiDB 查看 ,结果 State 为 online 表示 Pump 启动成功。
show pump status; 4.2.2 备份导入
备份 TiDB 时限制内存的大小,并且指定导出的行数,防止 TiDB OOM
./dumpling -h xxx.xxx.xxx.xxx -P 4000 -u root -pxxxxxx -r 200000 --tidb-mem-quota-query 536870912 -t 1 -F 128MB -B shared_link -o $bakdir完成备份,以 local 模式分别导入 TiDB-v4.0 IDC1 IDC2 机房集群,修改 tidb-lightning.toml
nohup /opt/tidb-toolkit-v4.x-linux-amd64/bin/tidb-lightning -config tidb-lightning.toml > nohup.out &4.2.3 TiDB-v2.x 配置 Drainer 增量同步到 TiDB-v4.x
initial_commit_ts 可以在导出目录中找到 metadata 文件,其中的 pos 字段值即全量备份的时间戳
修改 tidb-ansible/inventory.ini 文件为 drainer_servers 主机组添加部署机器 IP
[drainer_servers]
drainer_tidb ansible_host=ip1 initial_commit_ts="xxxx"配置增量同步到下游 wq 集群 TiDB-v4.x
cd /srv/tidb-ansible/conf
cp drainer.toml drainer_tidb_drainer.toml
detect-interval = 10
[syncer]
ignore-schemas = "INFORMATION_SCHEMA,PERFORMANCE_SCHEMA,mysql,test"
txn-batch = 20
worker-count = 16
disable-dispatch = false
safe-mode = false
db-type = "TiDB"
replicate-do-db = ["xxxx"] #只同步需要迁移的db
[syncer.to]
host = "xxx.xxx.xxx.xxx"
user = "root"
password = "xxxxxx"
port = 4000部署 Drainer
ansible-playbook deploy_drainer.yml启动 Drainer
ansible-playbook start_drainer.yml更新监控信息,再次更新监控信息
ansible-playbook rolling_update_monitor.yml --tags=prometheus4.2.4 数据校验
数据同步配置好下一步就是核验数据的一致性,TiDB 不像 MySQL 可对比 binlog+pos 点确认数据一致性,对比两个 TiDB 集群的数据也没有太多的经验,开始我们采用比较原始的方法,写脚本对比表的数据量,业务空闲时定期去跑,指定 TSO 点去统计校验,也不好拿到一致性,从统计的数据看或多或少有些差异。后来换一种思路,TiDB 上游设置只读快速去核对,但翻了下官档没有找到;官网提供的 sync-diff-inspector 有些限制,不支持在线,滚动只支持表 range,具体参考:https://docs.pingcap.com/zh/tidb/stable/sync-diff-inspector-overview
切换的时候我们研发开发了应用可设置只读的方式,采用了核心表的范围校验 sync-diff-inspector + 脚本统计数据核对,这套组合下来没有问题,我们认为数据是一致性的。
五、TiDB-CDC 双机房实践
5.1 配置 CDC 同步
TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,这边主要用于 IDC1-TiDB 集群实时同步数据至 IDC2-TiDB 集群
tiup ctl cdc changefeed create --pd=http://ip1:2379 --sink-uri="TiDB://root:xxxxx@xxx.xxx.xxx.xxx:4000/?worker-count=16&max-txn-row=20000" --changefeed-id="simple-replication-task" #创建同步
tiup ctl cdc changefeed list --pd=http://ip1:2379 #查看同步ID
tiup ctl cdc changefeed query -s --pd=http://ip1:2379 --changefeed-id=simple-replication-task #查看同步状态
tiup ctl cdc changefeed query --pd=http://ip1:2379 --changefeed-id=simple-replication-task #查看详细配置5.2 TiDB-CDC 测试场景
TiDB 4.0 开启 CDC 同步后,压测脚本持续写入数据到主节点
- cdc 重启
- 反复 kill cdc 进程
- 脚本持续写入更新 停 cdc 进程一小时,
- 重启 tidb follower
- tidb follower 停机一小时
- 重启 tidb master
- iptable 断网
结论:TiCDC 无大事务,数据同步的延迟基本在秒级别,同步结束后检查数据一致性。
5.3 HAProxy代理
部署配置参考官方:https://cn.pingcap.com/blog/best-practice-haproxy
下面简述下 HAProxy 冷切、热切的方式:
- 冷切换代理至 IDC2 机房 TiDB 集群,修改配置直接重启 HAProxy
unlink haproxy.cfg
ln -s hw-haproxy.cfg haproxy.cfg重启 HAProxy
systemctl stop haproxy.service
systemctl start haproxy.service - 热切:修改好配置文件先重启 IDC2 的 HAPoxry 热加载配置文件
- 修改 HAProxy 的代理端口
- 重启 IDC2 的 HAProxy 生效 pkill haproxy
haproxy -f /etc/haproxy/haproxy.cfg -p /var/run/haproxy.pid -sf $(cat /var/run/haproxy.pid)3. 在 IDC1 节点 pkill haproxy ,修改配置文件一致性,再启动
六、总结
遇到的问题
1.导出大规模数据时的注意配置 TiDB GC,Dumpling 备份大表 TiDB OOM
处理方式:备份前设置 GC 时间:
update mysql.tidb set VARIABLE_VALUE = '720h' where VARIABLE_NAME = 'tikv_gc_life_time';导入后同步数据追上,再修改回默认的 10m
Dumpling 导出大表强烈建议设置 -r xxx -f xxx 参数否则 TiDB OOM 的概率很高;参考:https://docs.pingcap.com/zh/tidb/stable/dumpling-overview/
Dumpling 设置 -r xxx -f xxx 参数 导出 MySQL 联合主键 [int,varchar] 类型大表很慢,长时间无法完成导出;反馈官方 PingCAP 老师,目前已经解决参考 PR:https://github.com/pingcap/tidb/issues/29386
2.TiDB-v2.x 开启 binlog,gc 导致磁盘空间占满,pump 卡住导致 TiDB 挂死
处理方式:binlog 配置 GC 时间,重启 TiDB 生效,不配置默认保留 7 天;开启,关闭 binlog 建议参考:https://asktug.com/t/topic/33170
3.DM迁移 MySQL 表排序规则问题
MySQL 建表时没有显示指定 COLLATE=utf8_general_ci,因 MySQL 默认 Collation: utf8mb4_general_ci,TiDB 默认的 utf8mb4_bin,DM 也没有找到可设置下游的排序规则参数;这边业务也需保持排序规则一致。
目前是这样处理的:在初始化 TiDB 集群先配置 new_collations_enabled_on_first_bootstrap 改为 true,然后在 TiDB 显示指定 COLLATE=utf8_general_ci 建表进行迁移;
其它小问题
TiCDC 同步数据大事务容易夯住,处理方式:避免大事务操作,拆分小事务,批量导入数据等;
强烈建议不使用 MySQL 保留关键字,历史原因业务在 TiDB-v2.x 使用了 MySQL 保留关键字没报错,在升级到 TiDB-v4.x 报错,建议规范还是得严格执行,否则出问题排查修复也需要时间;

TiDB 升级及双机房落地收益
按照线上业务监控的 QPS,相同的配置业务访问延时更低,在数据量不断增加性能不减,为分享业务提供高性能的服务。
新版本的 Dashboard 提供的图形化界面,可用于监控及诊断 TiDB 集群,快速定位 SQL 语句性能缓慢及发生性能抖动的原因。
最大收益还是双机房高可用,在成本允许的情况下,TiCDC 实现主机房向备机房同步数据,延迟小维护简单,在验收环节模拟机房灾难性断网演练,可快速切到备用机房,真正实现机房级别容灾。
七、感谢
WPS 分享业务得以顺利升级 TiDB-v4 版本、数据迁移、双机房落地实施,感谢 PingCAP 工程师们的帮助和支持,及时地响应解决我们测试过程中所遇到的问题,让 TiDB 在 WPS 业务组推广更顺畅,有更多的业务使用场景。
目录